소개 [arXiv]
Self-supervised learning은 collapsing solution 해결책으로 수렴하는 문제를 가지고 있습니다. collapsing solution의 발생 경위는 다음과 같습니다. 데이터 x를 모델의 입력으로 하여 이에 적합하게 라벨링 된 y를 예측하도록 학습하는 supervised learning과 다르게, self-supervised의 경우 데이터를 통해 스스로 학습해야 합니다. 라벨이 없는 데이터에서 쉽게 얻을 수 있는 정보는 자기 자신입니다. x가 x와 같다는 사실을 통해 데이터는 x를 변형한 입력과 x가 동일한 정보를 갖는다고 학습하게 되는 것이지요. (이러한 가설을 모델링하기 위해 siamese networks 구조가 많이 이용됩니다.)
이러한 학습과정을 통해 모델이 배울 수 있는 가장 쉬운 솔루션은 모든 입력에 대해 같은 출력을 갖게 하는 것입니다. 이러한 솔루션을 collapsing solution이라고 합니다. 많은 논문들이 다양한 방법으로 모델이 collapsing solution으로 학습하지 않도록 합니다. 예를 들어 negative pair를 생성해서 positive와 negative의 출력 값이 서로 달라지도록 학습하여, 단 하나의 constance solution을 막고자 한다던가, output cluster를 지정하여 결과값이 k개의 cluster로 수렴하게 하여 이러한 문제를 해결합니다. 또 최근에는 모델 최적화 방식(학습 방식)을 통해 collapsing solution을 해결하곤 합니다.
본 논문 또한 collapsing solution을 해결하고자 합니다. 본 논문은 기존에 필요로 했던 large-batch(negative pair approaches에서는 대표성 있는 negative를 얻기 위해 batchsize가 중요했음)와 asymmetry between the network(the siamese network based approaches에서는 브랜치 간의 차이를 주어 collapsing solution을 예방하고자 함)를 사용하지 않고 output 간의 거리를 측정하는 새로운 loss를 도입하여 collapse 문제(=trivial constance solutions)를 해결합니다.
Method
논문에서 feature representation을 위해 중점을 둔 것은 redundancy-reduction입니다. redundancy-reduction이란, neuroscience 분야에서 발표된 것인데, sensory processing의 목표가 redundant한 입력을 independent components로 구성된 표현으로 변환하는 것인데, 이때 redundancy-reduction을 통해 sensory processing을 할 수 있다는 것입니다. 이처럼 redundancy-reduction를 모델링 하기위해 본 논문은 distorted image를 jointly 하게 임베딩 하고 그 관계를 이용하는 matrix 형식의 loss를 이용하여 components(이미지) 간의 redundancy를 줄입니다.
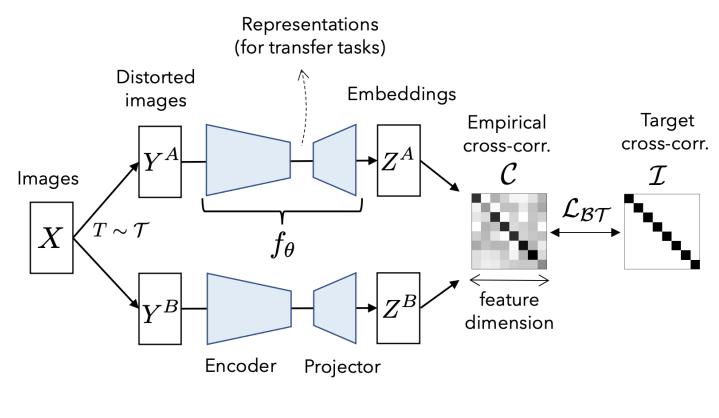
방법론에 대한 이론적인 설명은 위와 같고, 조금 더 실질적인 구조에 대해 소개해보겠습니다. 우선 모델의 아키텍쳐 구조는 [그림 1]과 같고, 수도 코드 형식으로 제공된 방법론의 알고리즘은 [그림 2]와 같습니다. 그 외에도 implementation details이 논문에 자세하게 포함되어있으니 참고하시면 좋을 것 같습니다. 본 논문은 아키텍쳐 그림과 pseudo code에 나온 그대로입니다. 먼저 입력 이미지 집합인 배치 x에 대해 T로 data augmentation을 진행하여 distorted 된 두가지 view 쌍인 Y^A와 Y^B를 생성합니다. 이를 동일한 모델을 통해 Z^A, Z^B로 임베딩합니다. 이 임베딩한 벡터에 대해 cross-correlation matrix를 계산해, diagonal 성분은 1이되고 off-diagnal 성분이 0이 되도록, 즉, [그림1]의 가장 왼쪽과 같은 단위행렬(identity matrix)이 되도록 loss를 구성합니다. 이로서 같은 의미를 갖지 않는 서로 다른 이미지간의 유사도는 0이 되고 distorted 된 자기 자신에 대한 유사도는 1이 되게 하여 각 componets가 독립적으로 임베딩되도록 학습합니다.

Experiments
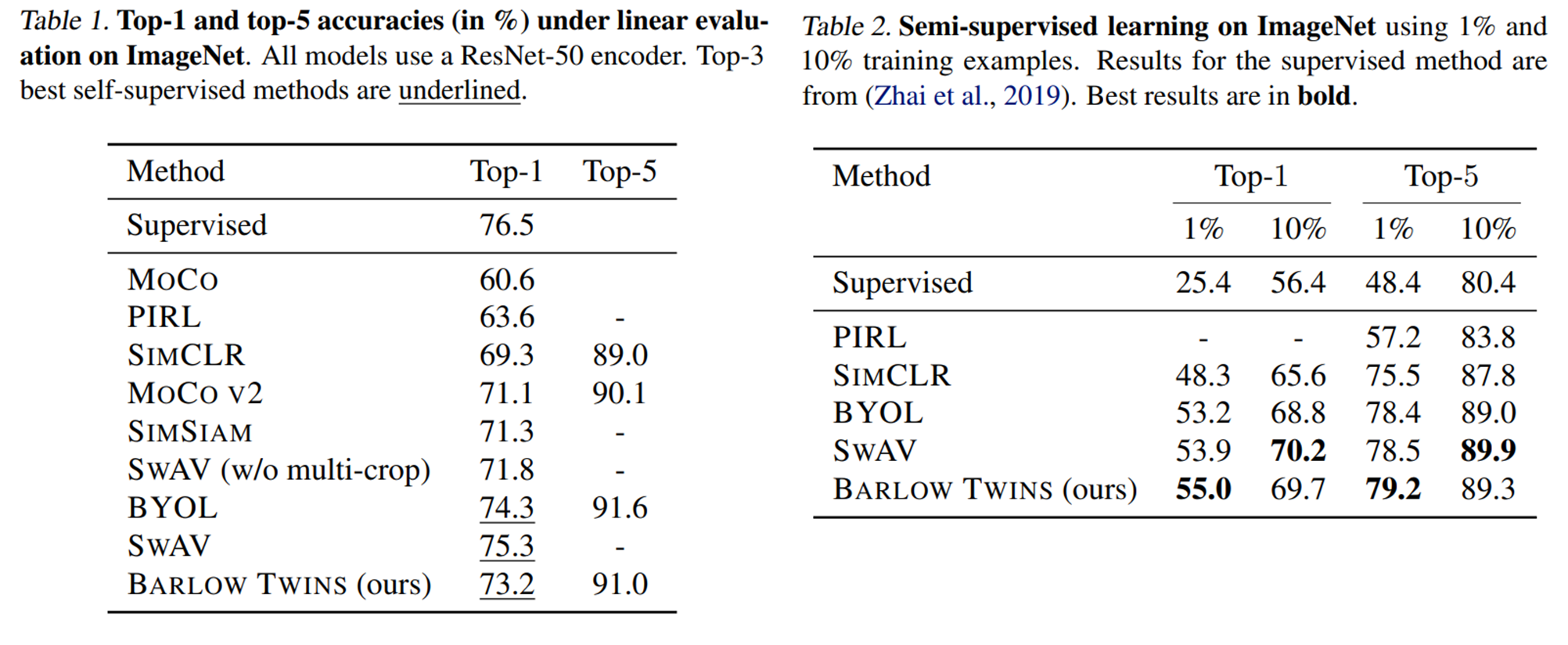
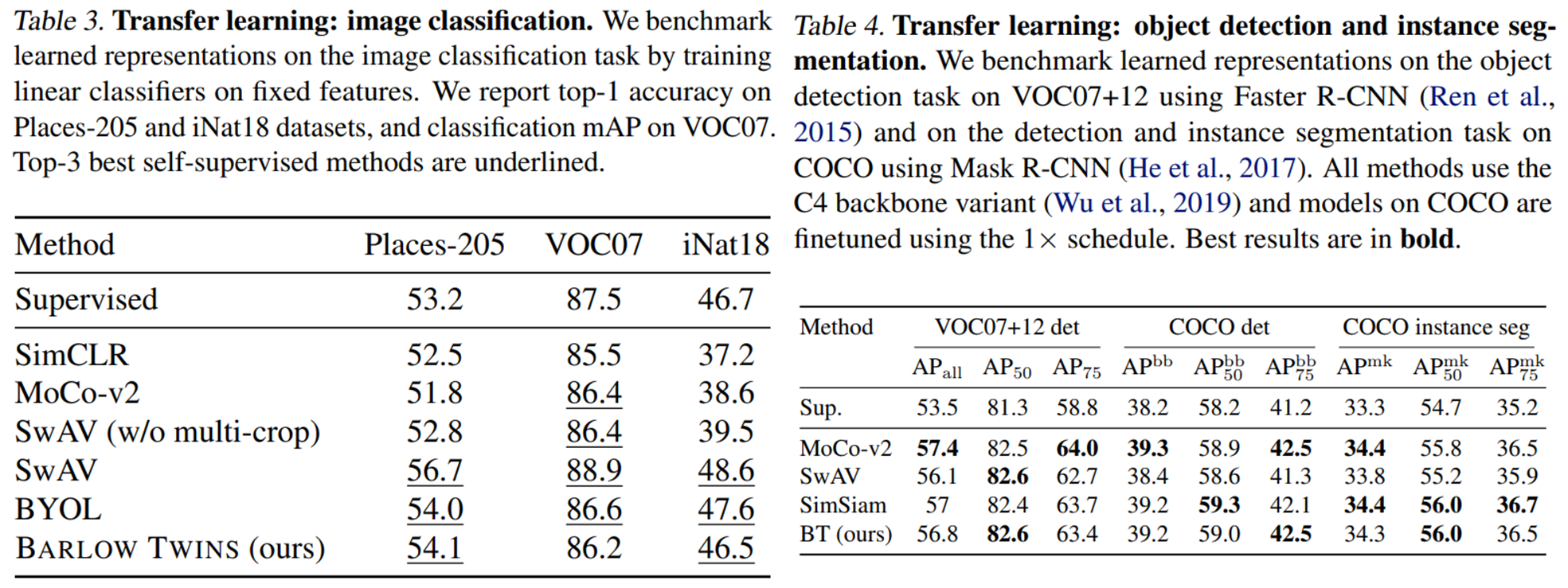
본 논문의 실험파트는 기존 방법론과 비교를 진행한 result와 self-evaluation을 포함한 ablations으로 구성되어있습니다. 먼저 기존 work과의 비교를 위해 self-supervised에서 많이 사용하는 linear evaluation와 semi-supervised evaluation을 ImageNet에서 수행하였으며, downstream task 확장을 위해 Image classification, object detection, instance segmentation tasks에 대한 실험을 리포팅하였습니다. 개인적으로 아쉬운점은 table1에 batch size에 대한 정보가 누락된 점과, table 4에만 포함된 simsiam입니다. simsiam은 BYOL 이후의 work으로 negative pair사용과 momantum encoder없이 학습하는 방법론으로 MoCo v2와 비슷하거나 더 좋은 성능을 냈던것으로 기억합니다. 따라서 MoCo v2와 임시적으로 비교를 하면 될 것이라고는 생각합니다. (다만 table 4에는 포함된 최신 방법론이 다른 테이블에 포함되지 않아 아쉬웠습니다.) 이외에도 다양한 ablations 파트에 실험이 존재합니다. 본 글에는 포함하지 않았지만 위의 아카이브 링크에서 논문을 확인하실 수 있습니다.
asymmetry between the network 대신 output간의 거리를 측정하는 loss를 제안하셨다고 하셨는데 그렇다면 기존 방식은 네트워크간의 차이가 있도록 일정한 차이를 주는 방식인가요??
그리고 collapsing solution을 해결하기 위해 새로 도입한 loss는 output이 서로 달라지도록 역할을 하는 것이 맞는지 궁금합니다!!
안녕하세요 좋은 리뷰 감사합니다.
본 논문이 제시하는 방법론은 곧 새로운 loss 를 사용하여 즉, 두 유사도 계산 방식에 cross-correlation matrix를 사용하여 성능을 올릴 수 잇었다는 것 같습니다.
음 그런데 결국 simCLR랑은 유사도 계산만 다른 것 같은데, 본 논문의 contribution이 무엇인가요? loss를 재설계하였다는 것인가요?
그리고 몇 가지 질문을 더 드리려고 합니다 .
먼저, redundancy-reduction이란 redundant한 입력을 independent components로 구성된 표현으로 변환하는 것이라고 하셨는데요…
조금 더 자세하게 서술해주실 수 있을까요? 제가 이 부분이 이해가 안되어서 서술 부탁드리겠습니다.
그리고 table을 보면.. 성능이 BYOL, SwAV보다 떨어지는 것 같은데요.. 이건 왜 떨어지는 지에 대한 분석이 있을까요?
SwAV는 어떤 방법론인지 아시는지요?