이번에 소개해드릴 논문은 impact factor 10정도 되는 IEEE 저널인 Transactions on Industrial Informatics에 2022년에 실린 논문입니다.
해당 논문은 FLIR v2 데이터셋에 존재하는 unpaired 상황을 다룰만한 좋은 아이디어가 없을까 찾던 도중에 발견하여 읽어보게 되었습니다. 결과론적으로 FLIR V2에 사용하기에 적합한 방법론은 아니지만 흥미로운 논문이었습니다. 방법론 자체는 나쁘지않은데 너무 notation이 많고 그러한 notation을 설명에서 계속 언급하며 설명하여 불필요하게 복잡하고, 그림이 혼동되게 그려져서 이해하는데 애를 좀 먹었지만 전체적으로 나쁘지 않은 퀄리티의 논문이었습니다.
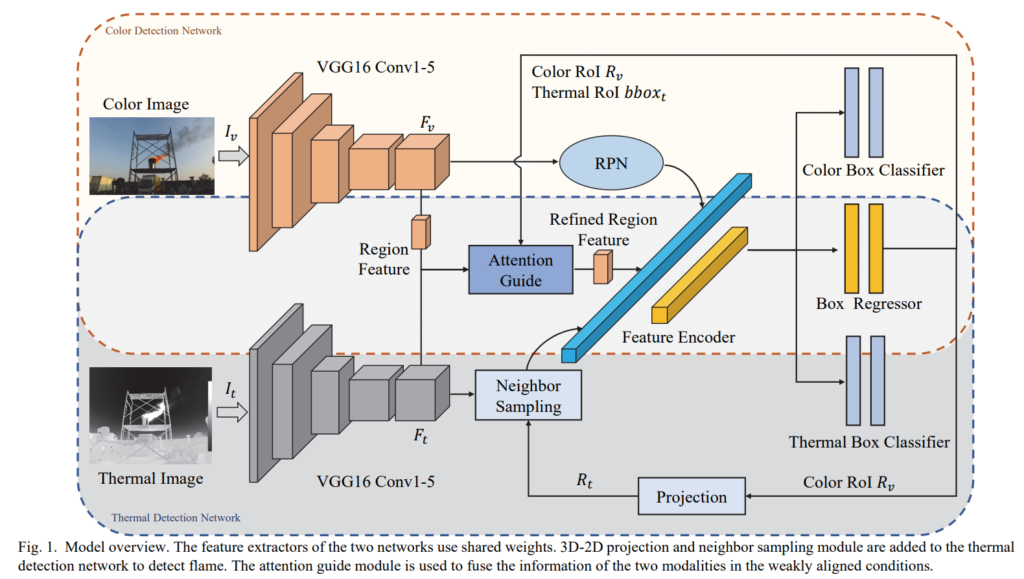
먼저, 해당 논문에서 제안하는 파이프라인입니다. 보이는 것처럼 멀티스펙트럴 영상을 사용해서 Flame을 검출하는게 최종 목표입니다. 그런데 RGB영상과 Thermal영상을 사용하면 다들 아시다시피 mis-alignment문제가 항상 발생하게 됩니다. mis-alignment의 원인은 다양하지만, 주로 센서간의 동기화가 정확하지 않거나, 센서간의 거리(baseline)이 넓다거나 FOV차이에 의해서 발생합니다. 해당 논문에서는 이러한 mis-alignment가 존재하는 경우에도 flame을 잘 찾는것을 목표로 해당 파이프라인을 설계하였습니다.
결론부터 말씀드리면 해당 파이프라인으로는 severely-misaligned 인 경우는 잘 다룰 수 없습니다. 그러므로 제가 현재 진행중인 연구에 사용되는 데이터셋인 FLIR V2에는 사용할 수 없습니다. 이에 추가적으로 FLIR V2에 사용할 수 없는 이유가 몇가지 더 있습니다. 소개시켜드리는 논문에서는 RGB영상 stereo 를 이용해서 depth를 구하여서 사용하지만, FLIR 데이터셋에는 RGB stereo 영상이 존재하지 않습니다. FLIR V2에 적용못하는 한가지 이유가 더 있는데 이는 방법론에 대한 이해가 되어야 이해할 수 있으므로 일단 논문에대한 설명부터 하겠습니다.
어찌됐든, 제가 읽은 목적에 부합하지 않아서 조금 실망했지만, 방법론 자체는 괜찮았던거 같습니다. 이제 그 방법론에 대해서 좀 더 자세히 설명해드리겠습니다.
해당 파이프라인은 Faster-RCNN을 기반으로 설계되었으며, VGG16 백본을 이용해서 피쳐를 뽑아냅니다. 그리고 해당 RGB피쳐를 이용해서 RGB영상에서의 RoI를 뽑아냅니다. 그리고 RGB영상으로 구한 RoI와 RGB-stereo depth를 이용해서 RGB RoI를 3D로 올렸다가 Thermal로 다시 projection합니다. Thermal로 projection할때는 R|t관계와 intrinsic parameters가 사용됩니다. Thermal로 Project된 RoI를 기준으로 Flame을 Detection을 하려면 가장 나이브한 방법으로는 해당 Thermal RoI를 바로 regressor에 태우는 것 일 겁니다. 그러나 Thermal로 Projection 시킨 RoI는 캘리브레이션 에러, FOV차이 등등의 원인으로 RGB RoI에 비해서 에러가 더 큰 상태입니다. 그래서 해당 논문에서는 바로 regressor에 태우지 않고 해당 Thermal RoI 주변에 앵커박스를 만들고 regression하여 RoI를 추출합니다.

위의 그림은 Thermal RoI 주변을 샘플링하여 앵커박스를 생성 하였을때의 예시입니다. 즉, 예를들어 주변에 8개의 point로 부터 앵커박스를 만든다고 한다면 그중에 1개 set의 예시입니다.
이러한 방식으로 뽑힌 RoI들에서 피쳐를 뽑아서 regressor/classifier에 태워서 flame인지에 대한 classification과 offset에 대해서 regression합니다.
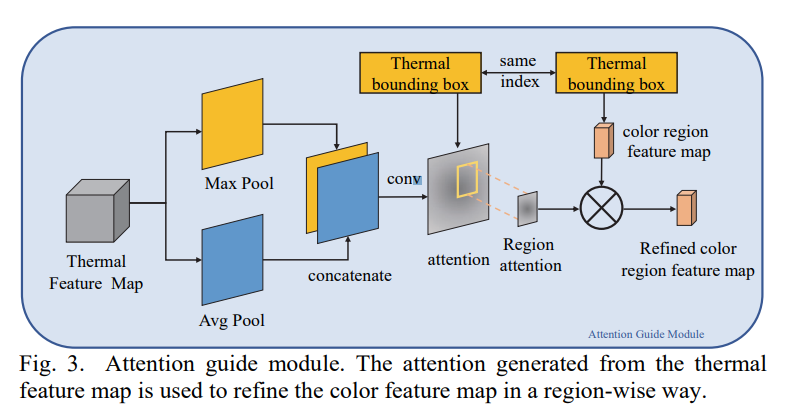
이와 더불어 weakly-aligned에서 좀 더 효율적으로 학습/추론 하기위해 attention guide module을 사용합니다. 해당 모듈에서는 Thermal feature를 인풋으로하여 Max pool / Avg pool로 global pooling해주고, channel방향으로 concat해줍니다. 그리고 1개의 CNN블록을 태워서 나온 attention map을 0~1.5 사이의 스케일로 바꾸어주고, 해당 attention map에서 Thermal RoI에 해당하는 부분만 추출하여 RGB region feature에 region attention으로 사용합니다. 이때, thermal과 rgb의 Region 크기차이는 depth정보가 있으니 3D로 올렸다가 다시 re-projection 시키는 방식으로 맞추어줍니다.
요약하자면, 결국에는 우리가 흔히 알고있는 spatial attention을 준것인데, 그 attention을 region-wise로 주었다고 생각을 하시면되며, Thermal과 RGB상에 영상간 차이를 맞추는 작업인 registration을 하기 위해 regional attention맵을 3D에 올렸다가 projection하여서 사용한 것 입니다.
위의 방법론에 대한 설명을 이해하셨으면, 아래와 같은 궁금증이 드실 수 있습니다.
Q. Stereo 영상에서 depth가 없는 영역의 경우에 어떻게 3D로 올렸다가 projection 시킬 수 있을까?
A. 해당 방법론에서는 RGB RoI를 Thermal로 projection 시키는데 RGB-stereo depth정보를 사용하였습니다. 그러나 질문처럼 depth가 없는 경우에는 어디로 projection 시킬지 정확히 구할 수 없습니다. 그래서 저자는 dataset에서 RGB RoI와 Thermal RoI를 전부다 뽑은 후 shift차이가 가장 많이나는 X_max와 Y_max를 구하여서 해당 구간을 projection 시킬 영역으로 사용합니다. 즉, depth가 없으니 어디로 projection 시킬지 모르니 thermal에 projection 시킬 수 있는 max 구간을 설정하고, 해당 구간내에 RoI를 만드는 식으로 해결하였습니다.

위와 같이 robot을 구성해서 ROS로 implementation을 하였으며, calibration을 직접하였는데, 온풍기로 30분간 달구어서 열화상 영상에서도 잘 보이게 했다고 합니다.

위와 같이 flame을 모사하여 데이터셋을 촬영하였습니다.
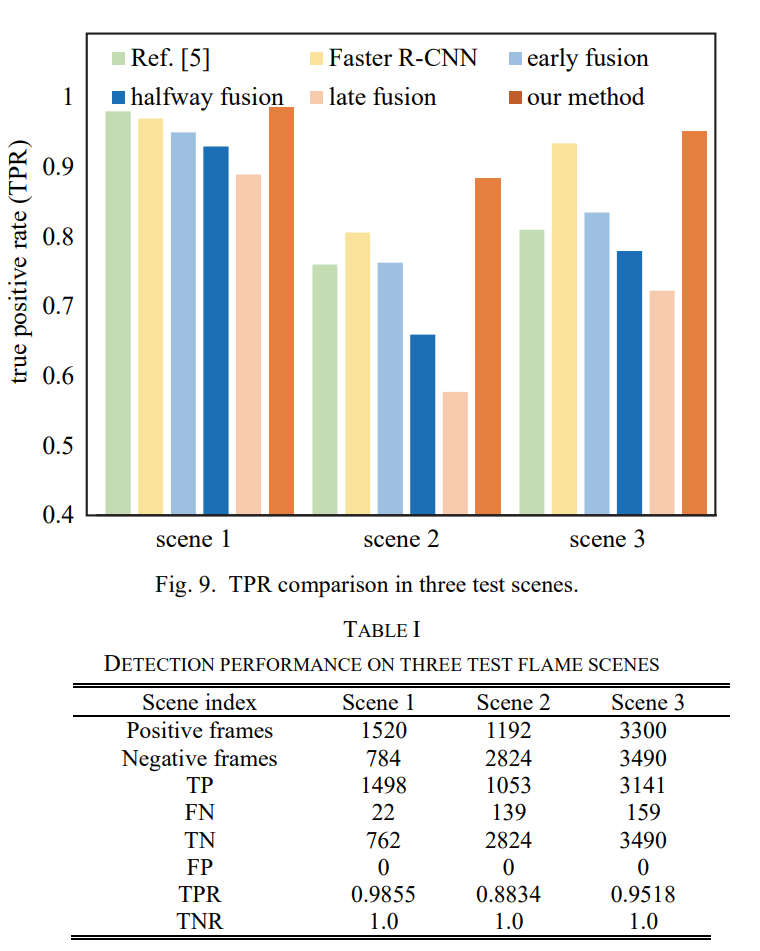
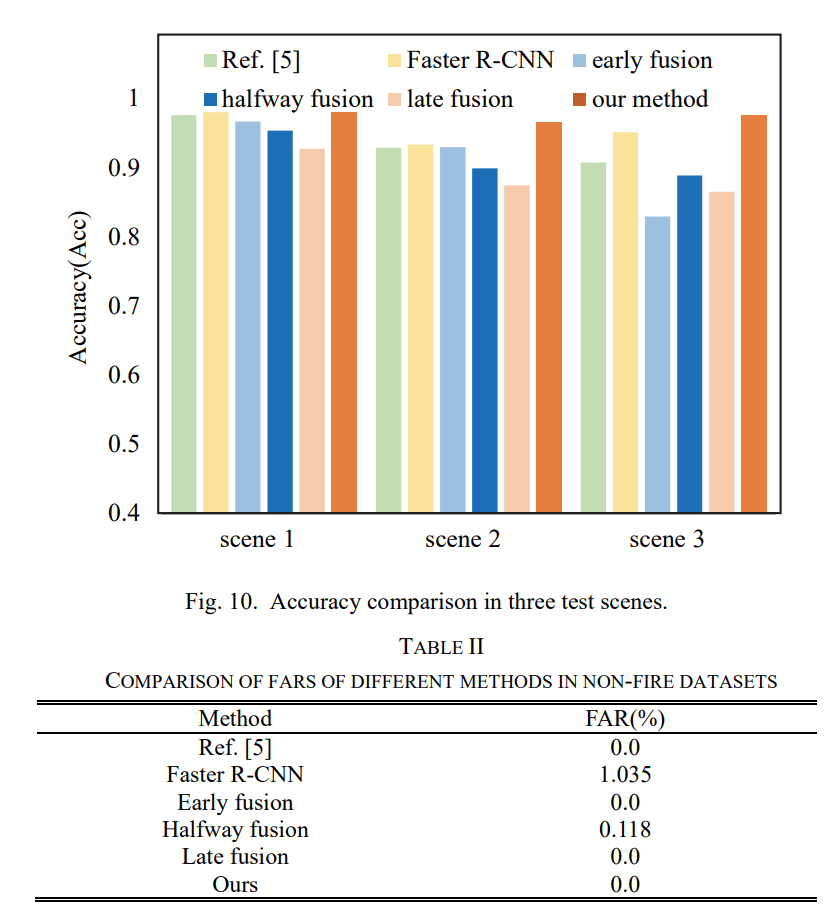

평가에서는 non-fire 데이터셋을 추가로 취득하여 fire가 없는 상황에서 False positive가 잡히진 않는지 실험을 하였습니다. 화재가 나지도 않았는데 flame으로 인식하면 그 또한 문제일 것 입니다. 이러한 문제가 없는지 확인하였고 정성/정량적 결과는 위와 같습니다.
마무리
결국에 해당 논문을 읽게된 계기는 FLIR V2에 적용할 아이디어를 도출하기 위해서였는데 기대에 부합하지 못한 논문이긴 했습니다만, 방법론적인면에서는 괜찮은 논문인거 같습니다. 이유는 아래와 같습니다.
- FLIR V2데이터셋은 RGB-stereo depth를 구할 수 없음
- FLIR V2데이터셋에 존재하는 misalignment는 본 논문에서 다룬 weak-alignment에 비해 심하며, 본 논문 저자도 alignment가 심한 경우에는 해당 논문에서 제안하는 방법론이 잘 안될거라고 말하고있음.
- FLIR V2데이터셋에서는 카메라 캘리브레이션 파라미터를 제공하고있지 않아서 3D에 올린 이후 projection 시킬 수 없음.
아무튼 이러한 이유로 활용하긴 힘들거 같지만 그래도 꽤 재밌게 읽은 논문이었습니다.