안녕하세요 한대찬 연구원입니다. 이번에 가져온 논문은 Monocular 3D object detection 관련 논문입니다.
저는 지속적으로 Self-supervised monocular depth estimation과 관련된 논문을 서베이와 연구를 진행하고 있습니다. 제가 진행하고 있는 이 연구는 카메라 하나로부터 픽셀 당 깊이를 추정하는 연구입니다. 기존 LiDAR를 이용해 깊이 GT를 얻는 과정에서 LiDAR와 RGB 카메라 간의 동기화를 맞추는 문제와 LiDAR 센서 자체가 굉장히 비싸다는 문제 등등 다양한 문제가 있어서 LiDAR를 대체해서 깊이 GT 정보를 얻을 수 있는 연구가 활발이 진행되고 있으며 Monocular Depth Estimation은 그 중 가장 활발히 진행되고 있는 연구 중 하나 입니다.
Monocular Depth Estimation과 관련된 연구가 활발히 진행되면서 카메라 한대로부터 예측해낸 Depth Map을 이용해 기존 LiDAR 데이터 에서 진해됐던 테스크를 진행할 수 있게 되었고 관련 연구 또한 많은 성능 향상을 이뤄왔습니다. 그 중 가장 유명한 것이 Pseudo-LiDAR입니다. 이 Pseudo-LidAR는 아래 그림처럼 단일 영상 혹은 Stereo 영상들로 부터 Depth Map을 추정한 후 이 Depth Map을 Point cloud로 변경해서 LiDAR를 대체하며 이 point cloud에서 3D Detection 하는 framework를 제안했습니다. 이 pseudo-LiDAR는 제가 Self-supervised monocular depth estimation 연구가 가야할 최종 목표이자 평가 방법론으로 생각하고 있습니다.

Pseudo-LiDAR가 제안된 이후 Monocular 3D Detection 은 Pseudo-LiDAR와 같이 2 Stage로 진행되었으며, 이러한 framework를 따르는 방법론들은 end 2 end 방법론들보다 오버피팅이 심하며 LiDAR 기반의 방법론들과의 성능차이가 많이 난다는 문제가 존재했습니다. 물론 Pseudo-lidar 방법 외에 다른 Monocular 3D depth estimation 방법론이 존재 하며 좋은 대안이 될 수 있지만 그 방법론들은 unsupervised의 장점인 scalability를 갖고 있지 않습니다.
제가 소개하는 이 논문에서는 이러한 2 stage 기반의 방법론의 문제를 해결하는 monocular 3D object detector, DD3D를 제안합니다.
(Pseudo-lidar 관련된 최근 work를 서베이하다가 제목을 보고 끌려서 고른 이 논문은 악연인지 인연잊니 Toyota research 의 논문이더군요… 심지어 저에게는 심적으로 굉장한 친구인 Vitor가 2저자로 참여했더군요…허허 뭔가 Toyota가 참 이쪽 연구는 잘하고 있다는 생각이 들며 지속적으로 하는거 보니 Tesla 보다 오히려 Pseudo lidar에 진심인거 같습니다. ㅎㅎ )
Contribution
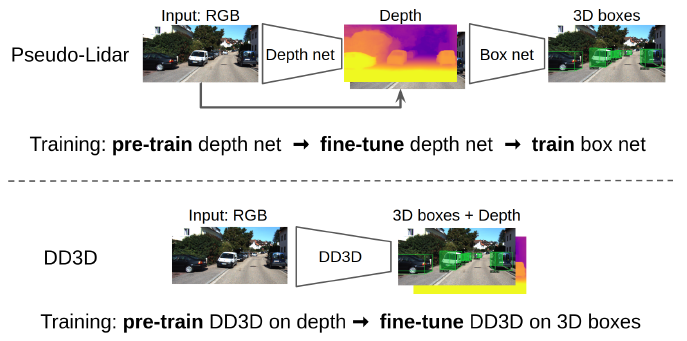
이 논문은 pseudo-lidar의 scalebility 와 기존 end-to-end 방식의 3D detection 방법론의 간편성과 성능을 다 잡는 것을 목표로 하는 framework를 제안하며 이 framework가 포함하는 contribution은 다음과 같습니다.
- 위 그림과 같이 Depth pretrain model을 활용할 수 있는 3D detector DD3D를 제안함
- 이런 Depth pretrain 모델을 사용하는 방식이 COCO 같은 대규모 2D detection 모델에서 pretrain된 모델을 사용하는 것 보다 좋음을 증명함
Method
- Architecture
이 논문에서 제안하는 DD3D의 아키텍쳐는 2D detection 방법론들중 single stage 방법론으로 핫한 FCOS[1] 기반으로 만들었다고 합니다.

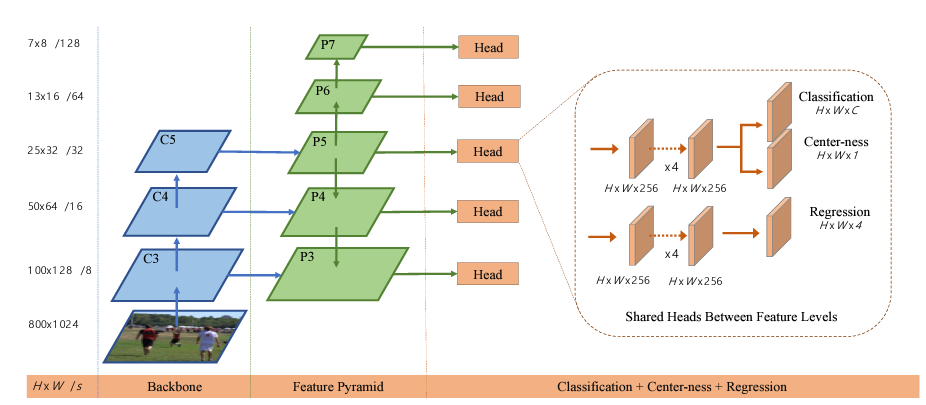
위 그림1은 FCOS의 학습 특징이며, 그림 2는 FCOS의 아키택쳐입니다. 보셔야할 부분은 FCOS는 center 점과 offset을 예측하며 아키택쳐는 FPN으로 구성되며 Center와 offset, classification을 예측하기 위한 head로 구성되어 있다는 것입니다. 이 FCOS를 보시고 아래 DD3D의 아키택쳐를 보시면 어느 부분이 변경됐는지 보이실 것입니다.
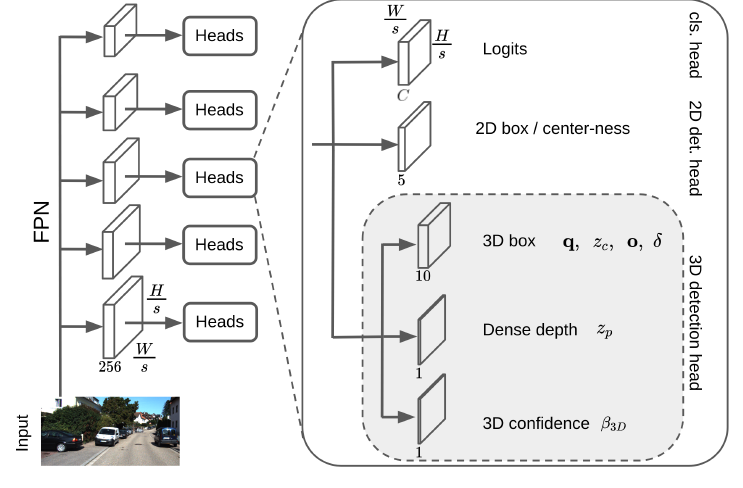
FCOS속 class, center-ness, regressing 부분과 DD3D에서 3개의 head 부분이 살짝 다르긴 하지만 아웃풋은 동일하니 넘어가고, FCOS 와 동일한 저 2D object를 예측하는 output들은 FCOS와 동일한 방식으로 학습을 하니 그것을 참고 하시길 바랍니다. ( 논문에도 동일하게 써있음.. 그 방식이 중요한게 아님)
DD3D 가 FCOS와 다른 나머지 3개 head의 부분의 output 은 다음과 같습니다.
- q = quaternion ( qw,qx,qy,qz) 으로 예측한 box의 회전과 방향을 뜻합니다. 3자유도를 갖습니다.
- zc= object center의 깊이, zp는 픽셀의 깊이. 즉 zp를 통해서 입력 image의 dense depth를 예측하고 zc를 통해서 box의 깊이 값을 예측합니다. 그리고 camera awareness 한 깊이를 예측하며 학습에 안정성을 부여하기 위해서 아래 식과 같이 예측한 깊이 값을 변경합니다.
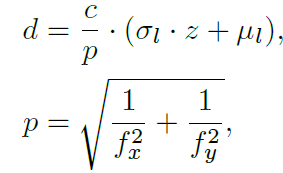
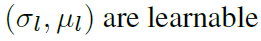
p= pixel size, fx,fy= focal lengths, c= 상수
위와 같이 pixel size를 입력으로 같이 넣어줘서 예측된 깊이 값이 실제 scale과 동일해지도록 학습합니다.
또한 FPN 의 특성상 달라지는 feature 크기에 맞춰 focal length 를 바꿔주며 그 식은 아래와 같습니다.
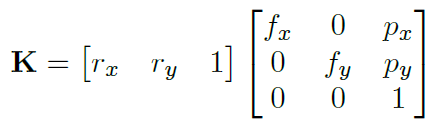
- o=피쳐 위치에서 카메라 평면에 투영된 3D 경계 상자 중심까지의 오프셋을 나타냅니다.
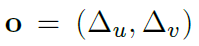
아래식을 통해서 3D 공간상으로 unprojection 시킵니다.
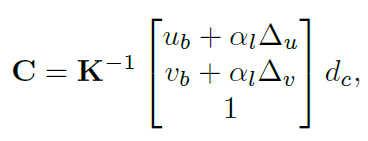
ub,vb는 pixel의 위치를 뜻하며 a는 learnable parameter 이며 FPN feature 각각 다르게 가지고 있습니다. dc는 위 에서 설명한 object box의 depth 를 scale 변경한 값입니다.
- 다음은 클래스별 3D box 크기의 편차를 뜻합니다.
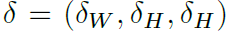
파라미터는 위와 같으며 아래와 같은 식을 통해 box 크기가 조정됩니다.
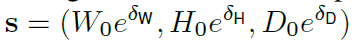
(W0;H0;D0)은 각 클래스의 box 크기이며 평균 크기로 훈련 데이터에서 미리 계산됩니다.
마지막은 예측한 box의 confidence입니다.
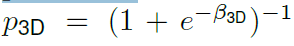
confidence는 위 식으로 변경 되며 classification head 에서 예측한 2D boxs의 confidence에 곱해주며, 2D box의 신뢰도에 대한 상대적 신뢰도를 뜻하게 됩니다.
Loss Function
2D box에 대한 loss는 FCOS와 동일하게 하며 자세한 내용은 FCOS를 참고하시길 바랍니다.
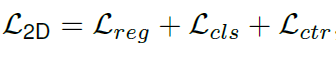
그리고 3D bounding box에 대한 loss는 아래와 같습니다.
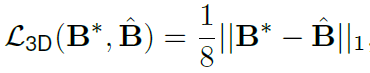
B는 bounding box의 8개 선을 뜻합니다.
Depth pretraining
네트워크의 아웃풋인 depth map을 pretrain 시키기 위한 과정입니다. 사실 이과정이 있으므로 2-stage 인 것 같은데…흠
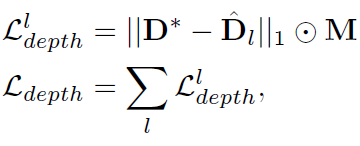
이부분또한 매우 간단합니다. 위 loss 식은 이용해 모델을 pretrain 시킨다는 것 같습니다.
근데 사실 이 부분이 이 논문에 알파이자 오메가 인 것 같습니다. 기존에는 depth net하나 따로 두고 detection 네트워크 하나두고 해서 두 네트워크를 따로따로 두기 때문에 학습이 오래걸리고 각자 overfitting 이 되었는데 이걸 하나의 네트워크로 해결하고 성능을 끌어올렸다는 부분이 이 논문의 키포인트입니다. 이 사전학습 과정을 통해서 3D box 예측할때는 camera intrinsic parameter에 따라 scale 을 전해주기만 하면 매우 정확한 depth 를 예측할 수 있어서 더욱 정확한 box를 예측할 수 있도록 도와준다고합니다.
Results
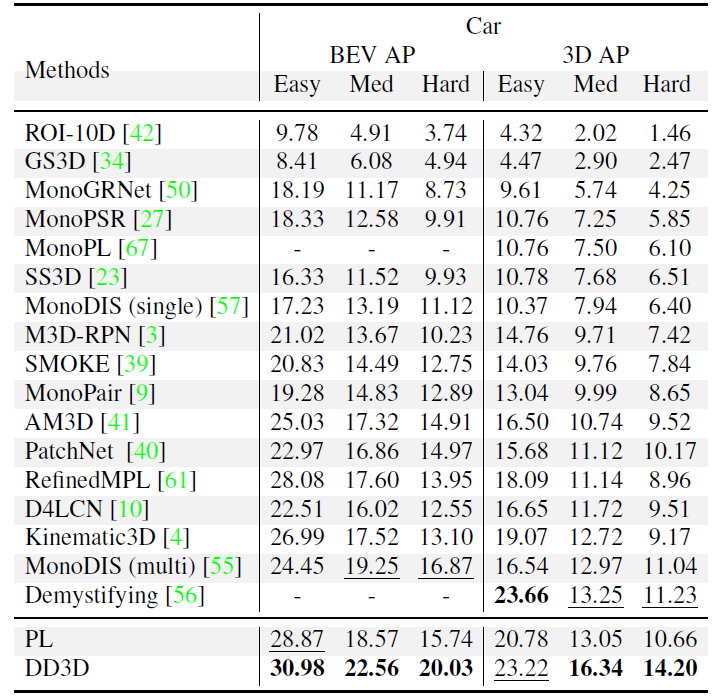
이 논문에서는 Pseudo-lidar와 비교를 위해서 Packnet을 이용한 Pseudo-Lidar(PL) 방식도 제안하고 구현했으며 그 PL 조차 다른 방법론들 보다 높은 성능을 보이지만 제안하는 DD3D 가 훨씬 좋은 성능을 보이는 것을 확인할 수 있습니다.
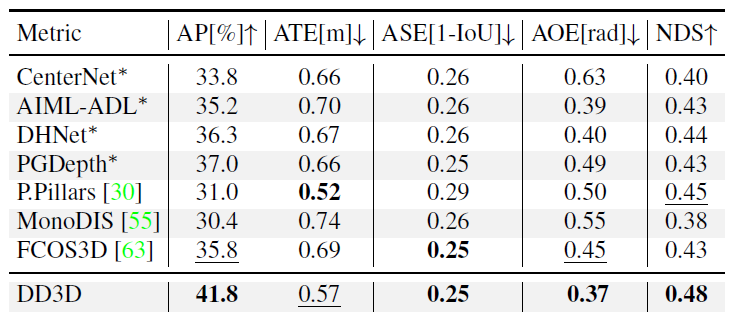
nuScenes에서 또한 동일한 결과를 볼 수 있습니다 . (여기엔 PL이 없는게 살짝 짜증나긴하는데 참도록 하겠습니다. )
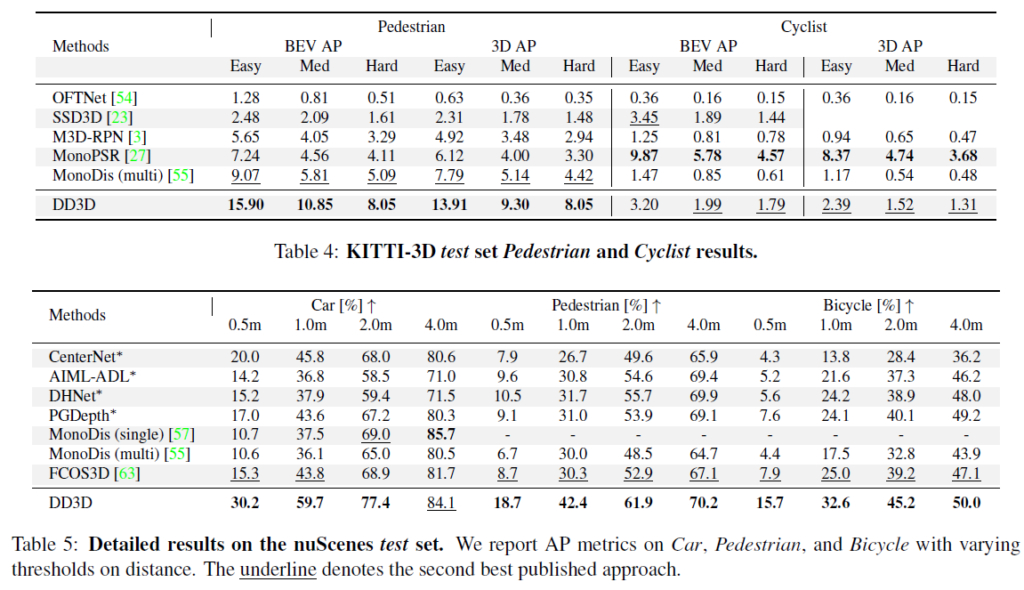
더 다양한 Class을 두 데이터 셋 에 따라 성능을 리포팅 한 것입니다. 얘도 PL은 없는게 살짝 그렇네요. 그래도 좋은 성능을 나타내는걸 볼 수 있습니다.

정성적 그림은 왜 다른 방법론들과 비교를 안했는지 모르겠지만 test 상황에서도 좋은 성능을 나타내는 것을 볼 수 있습니다.
제가 3D detection 관련한 논문을 많이 읽지 않아서 이 논문의 contribution이 얼마나 대단한건지는 모르겠지만… 그래도 성능하나는 괜찮아 보이는 논문 이였습니다. 또한 저는 처음에 teaser 만 보고 monocular depth estimation의 단계가 쓸모없어지는 건가 했는데, 다른 방식으로 model에 학습시키는걸 보고 살짝 안심..했습니다. 물론 self-supervised로 학습을 하면 어떤 성능이 나올까 궁금하긴합니다. 허허
Reference
[1] Tian, Zhi, et al. “Fcos: Fully convolutional one-stage object detection.” Proceedings of the IEEE/CVF international conference on computer vision. 2019.
예측한 bbox의 자유도가 3이 맞나요? 자동차와 사람의 경우 rolling pitching이 거의없고 yawing만 있어서 1자유도로 constraint를 걸어두지 않을까 싶은데 혹시 그러한 부분이 없나요? P.S 도요타의 Victor분을 연사로 RCV에 한번 초청해야하는거 아닌가 싶네요.
제가 3D detection 관련해서 background 가 많이 있는 것은 아니라 여러내용을 빠트리긴 했습니다. 일단 그 자유도가 3이라고 한건 맞는 것 같고, 클래스 별로 자유도를 다르게 한다는건 못 본 것 같습니다.
리뷰 잘 봤습니다. 질문이 하나 있는데, 리뷰 내용 중 3D 상에서 예측한 박스의 cls loss 를 계산하는 과정에서 “confidence는 위 식으로 변경 되며 classification head 에서 예측한 2D boxs의 confidence에 곱해주며, 2D box의 신뢰도에 대한 상대적 신뢰도를 뜻하게 됩니다.” 라는 말이 이해가 잘 안되네요.
2D box 계산할 때 cls도 같이 계산하게 되는거고, 3D 상에서도 p3D라는 변수명인 cls 값을 계산하여 그 둘을 곱해준다는건가요? 아니면 p3D라는 변수명이 2차원 cls값이 곱해진 변수명인가요? 게다가 상대적 신뢰도를 뜻한다는데 그게 무슨 의미이며 해당 리뷰에서 어떤 수식을 봐야 이해할 수 있는건가요?
먼저 좋은 논문을 리뷰 해주셔서 감사드립니다.
‘제가 3D detection 관련한 논문을 많이 읽지 않아서 이 논문의 contribution이 얼마나 대단한건지는 모르겠지만…’ 이 말이 마음에 걸려서 이에 대해 제 지식 수준에서의 제 생각을 먼저 전달해드리고자 합니다.
영상 기반의 3차원 물체 검출이 저조한 성능을 보이던 와중 2019년 Pusedo-Lidar가 등장하면서 영상 기반 3차원물체 검출의 가능성을 보여줬습니다. 이후에도 해당 기법을 이용한 확장 연구들이 등장하여 성능 향상을 보여줬습니다. 하지만 자율 주행 플랫폼의 특성상, 실시간성과 포터블한 모델이 필요하다는 제약이 발생합니다. 허나 PL 처럼 2 스테이지 기반의 방법론은 굵직한 방법론 2가지를 함께 써야함으로 앞서 이야기한 제약으로 인한 문제가 발생함으로, 커뮤니티에서는 PL을 장점을 가져가되 end-to-end(=실시간성과 포터블한 모델)가 가능한 방법론의 필요성이 대두되었습니다. 그러던 와중 해당 방법론이 등장한 거라 contribution을 인정 받았다고 생각합니다.
그리고 해당 논문이 두 태스크 모두 지식이 있어야 이해가 가능한 논문이었을텐데… 고생 좀 하셨을 것 같습니다. 그래서 그런지 수식들에 대한 설명이 아쉽네요ㅜ 등장한 수식들이 마무리가 되어야 이해가 되는데 중간에 끊어진 것 같아 아쉬웠습니다. 그래도 어려운 논문 읽으시느라 고생 많으셨습니다.
마지막으로 질문 하나 드리겠습니다.
해당 논문이 한대찬 연구원님이 하시고 싶은 멀티 태스크 러닝 방법론으로 보입니다.
리뷰 논문과 같이 두 태스크에 대한 깊은 이해도가 있어야 하는데, 깊이 추론 말고 어떤 태스크에 관심이 있으신지 궁금합니다.