°•°• 요약 •°•°
siamese network의 collapsing solution 수렴을 막는 요인은 stop-gradient 다.
°•°• 소개 •°•°
많은 self-learning 방법이 siamese network를 이용한다. 그리고 이러한 방법론은 주로 같은 컨텐츠를 갖는 positive pair에 대한 예측 간의 거리를 가깝게 하는 방향으로 진행된다. 즉, 이미지 x 에 대한 augmented data인 x_1 와 x_2 를 siamease network의 양쪽 브랜치에 입력하였을 때 브랜치의 출력 값이 같도록 학습한다. 이를 목적함수로 구현해 학습하였을 때, 모든 입력의 출력값을 하나의 상수로 고정 시키는 쉬운 솔루션인 “collapsing solution”으로 수렴하는 문제가 있다. 다양한 연구에서는 이러한 collapsing 현상을 막기 위하여 negative pair를 도입해 모든 입력이 하나로 수렴하는 것을 막거나, 처음부터 clustering을 도입해 하나의 상수가 아닌, cluster로 수렴하도록 한다. 그 중, negative pair를 도입해 이를 해결하는 것이 가장 일반적인 접근법인데, 이러한 접근법은 negative pair가 학습에 큰 영향을 미치기 때문에 이를 잘 구성하는 것이 self-supervised 분야에서 하나의 관점이였다[MoCo, SimCLR]. 비교적 최근에는 negative pair에 의존하지 않기 위한 연구가 진행되고 있다. 대표적인 연구가 지난주 리뷰했던 BYOL 이다. 해당 연구 또한 이러한 관점의 연구로 negative pair에 의존하지 않는 self-supervised 방법을 설명한다. 지난주에 BYOL은 collapsing solution 수렴 현상을 (1) prediction 구조와 (2) slow-moving average network( momentum encoder ) 를 이용해 해결했다고 주장한다. 본 논문을 다시한번 쉽게 요약하면 BYOL이 사실은 다른것이 아닌 momentum encoder가 업데이트 과정 중 사용하는 stop-gradient가 collapsing 문제를 해결한다는 것이다. 본 논문은 이에 대한 다양한 실험을 진행하였으며, 아쉽게도 해당 과정이 어떻게 collapsing으로 수렴하는 것을 막는지에 대한 이유는 제공하지 못했다.
°•°• method •°•°
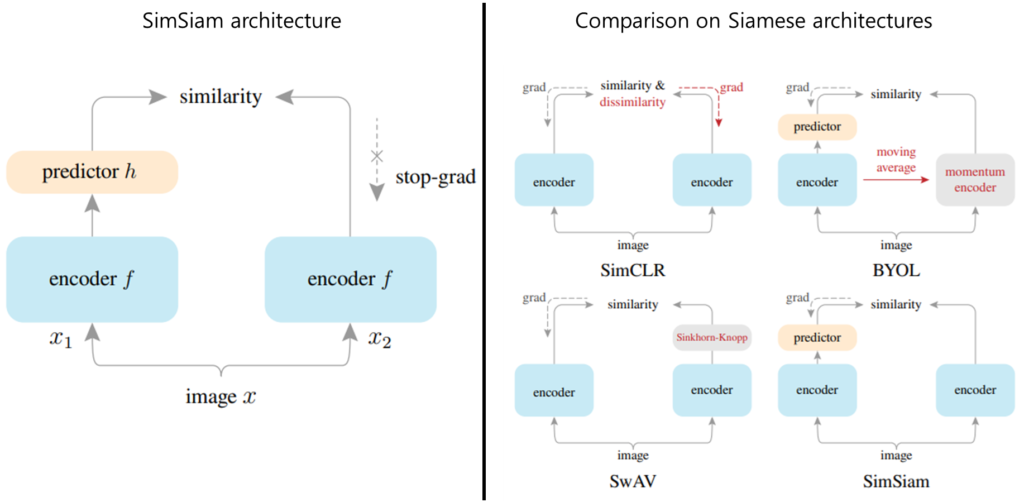
아키텍처는 매우 간단하게 [그림 1]의 좌측과 같다. 간단한 siamese 구조이다. 학습 순서는 다음과 같다. (1) 입력 이미지 x를 2개의 서로 다른 view로 augmentations하여 x_1 와 x_2 를 생성한다. (2) 각 augmented image를 model branch의 입력으로 하여 latency space로 임베딩한다. (3) 이 결과값이 최종적으로 같아지게 한다. 이처럼 학습 순서는 siamese 구조를 통해 이미지의 의미적 표현을 자가 학습하기 위한 기존 수많은 연구와 같다.
해당 논문은 (3)과 같은 loss 를 통해 모델이 collapsing solution으로 수렴하는것을 막기 위해 두 브랜치의 학습을 동시에 하지 않도록 stop-gradient를 적용하였다. 적용 방법은 다음과 같다. 기존의 positive pair간의 거리를 최소화하기 위한 벙법과 같이 모델의 prediction output간의 거리를 통해 loss를 구성한다.
[1단계] x_1 와 x_2 에 대한 모델의 output이 유사해지도록 한다.
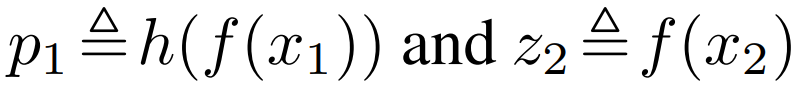
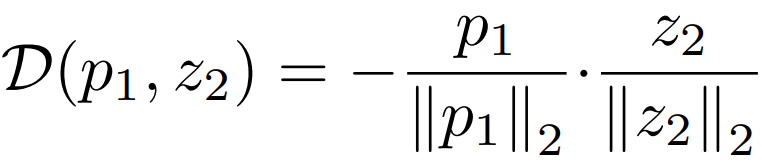
[2단계] 비대칭적인 구조를 갖는 SimSiam 구조의 대칭성을 보정하기 위해 symmetrized loss를 적용한다.
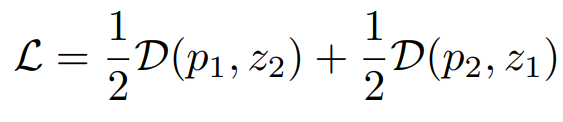
[3단계] 각 loss텀 을 계산할 때, 하나의 path에 gradient 업그레이드를 막는다.
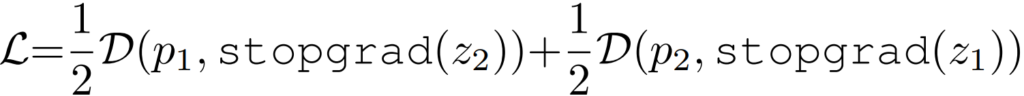
위의 3단계 중, 3번째 수식이 학습을 위한 최종 loss이다.
°•°• Experiment 1 •°•°

위 그림 [SimSiam with vs without stop-gradient]는 stop-gradient가 collapsing solution을 막기 위한 핵심적인 방법이라는 것을 잘 보여주는 실험 결과이다. 먼저 w/o stop-grad 케이스(주황)의 경우 loss가 매우 빠르게 수렴했다. 모델이 쉬운 답인 collapsing solution을 찾고 수렴한 것이다(Left). 이러한 현상이 정말 collapsing이 발생한 것인지 확인하기 위한 실험은 가운데 실험으로, validation data에 대한 output값을 l_2 -normalized 하였을 때 그 분산값을 리포팅한 것으로 w/o stop-grad의 경우 분산이 0에 수렴하는 현상, 즉 output이 하나로 고정되었음을 알 수 있다(Middle). 마지막으로 knn classifer의 예측정확도를 리포팅한 오른쪽 그래프의 의미는 다음과 같다. w/ stop-grad(파랑)의 경우 학습을 진행할 수록 knn classifer를 통한 예측 정확도가 높아지는 것으로 보아, feature의 representation이 향상되고 있음을 알 수 있다. 그러나 w/o stop-grad의 경우 전체 학습과정에서 개선이 진행되지 않는다(Right).
°•°• Experiment 2 •°•°
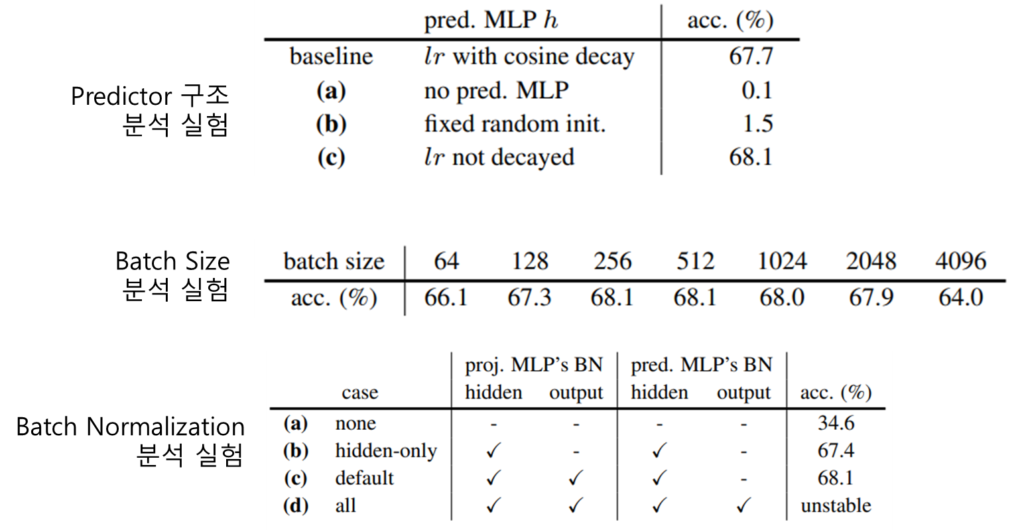
또한 본 논문은 기존의 연구가 주장했던 collapsing 예방 방식이 사실은 stop-gradient 때문임을 보이기 위해 구조에 대한 분석실험을 진행하였다. 먼저 predictor 구조 분석 실험의 경우 predictor가 없을 때 성능이 0.1로 학습이 거의 진행되지 않았다. 그 외 predictor의 parameter를 고정했을 때도 성능이 좋지 않았으며 learning rate (lr)을 고정하였을때는 고정하지 않았을 때 보다 성능이 좋았다. 이 결과가 시사하는 바는 다음과 같다. siamese 구조에서 predictor를 제거하는 것은 [수식3]을 아래의 [수식4]와 같이 변경하는 효과를 내며, [수식4]는 [수식5]와 같으므로 이는 stop-gradient를 지운것과 같은 효과가 발생하기 때문이라는 것이다. (First)
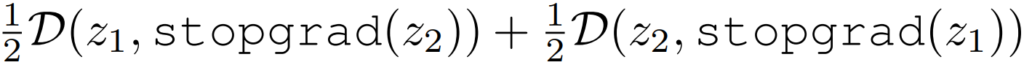
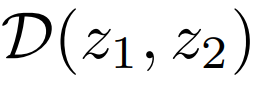
다음으로 제안하는 방식은 negative pair에 의존하지 않기 때문에 batch size에 의존적이지 않음을 batch size 분석 실험에서 보였다. (Second)
마지막으로 기존에 collapsing 예방을 위해 많이 도입되던 방법인 Batch Normalization(BN)을 predictor에 적용실험의 결과를 보였는데, 실험 결과 적용하지 않았을때 성능이 34.6으로 default 방식인 output과 hidden layer에 BN을 적용한 68.1보다는 낮은 정확도를 보였으나, 확인했을 때 이는 collapsing 때문이 아닌 학습 속도의 문제로 loss가 수렴하지 않았기 때문이라고 알렸다. 즉, collapsing 예방의 단독 해결책으로는 부족하다는 것이다.(third)
°•°• Experiment 3 •°•°
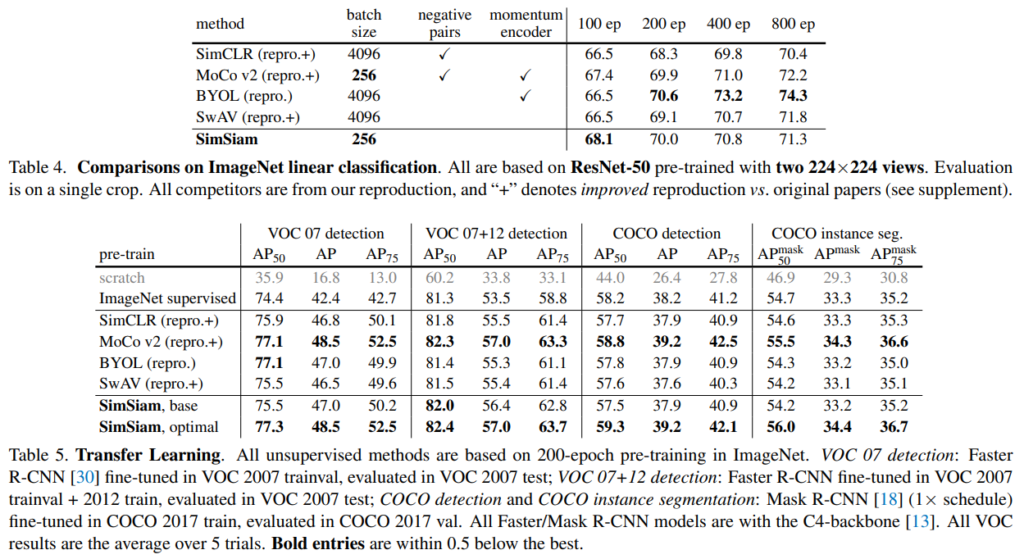
마지막으로 소개할 실험은 기존 방법론과의 비교를 통해 제안하는 SimSiam의 우월성을 보인 것으로 기존 SOTA알고리즘과 ImageNet데이터셋으로 비교한 결과는 위 실험 결과의 Table4와 같다. 다음으로 SimSiam으로 meaningful한 feature representation이 가능함을 보이기 위한 downstream task 적용실험은 Table5와 같다.
정말 좋은 리뷰 감사합니다.
제가 이해하기로 SimSiam은 결국 한 쪽 네트워크에는 gradient를 전달하지 않는다는 뜻인가요?? 한쪽 네트워크만 학습하는 것일까요?? 그럼 Downstream task 로는 학습한 네트워크만 사용하는 것인가요?
그리고 collapsing problem이 정확히 어떤 문제인지 헷갈리는데 이에 대해 설명해주시면 감사할 것 같습니다!