이번에 리뷰할 논문은 Stereo Depth Estimation 입니다. 최근에 backbone관련 논문들만 리뷰하는 것 같아서 다른 분야 논문도 좀 보고 분야를 넓혀서 다시 쭉 리뷰하고자 합니다.
2018년도에 출시된 논문이라 사실 막 새롭거나 놀랍다 하는 방법론은 없지만, stereo depth estimation 분야들이 feature map을 volume 형식으로 만들어서 3D 컨볼루션을 활용하는 듯 하여 이쪽 분야 논문을 쭉 보고자 합니다.
Intro
먼저 제가 예전부터 리뷰해온 논문들은 대부분 단일 영상 이미지를 입력으로 하는 Self-supervised monocular depth estimation이었습니다. 반면 해당 논문은 입력 자체를 stereo image를 넣는 Stereo Depth Estimation이며, 실제 학습 과정도 좌측 이미지를 우측으로 warping하거나 그 반대의 과정을 거친 뒤 source & target 영상 간에 photometric loss로 학습하는 self-supervised 방법론이 아닌 GT를 바로 regression하는 supervised 학습 방식입니다.
아무튼 이러한 stereo depth estimation 역시도 self-supervised monocular depth estimation과 유사한 문제들이 있는 것 같은데, 가장 대표적인 것이 바로 ill-posed region이라고 합니다. ill-posed region이란 textureless하거나 patter이 반복되거나, occlusion이 발생한 영역들을 의미하며 이러한 영역들은 좌우 이미지간에 대응점을 모델이 학습하기 어려워 학습의 방해요소로 꼽힙니다.
또한 저자가 주장하는 기존의 주요 문제 중 다른 하나는 바로 context information을 어떻게하면 더 분명하게 정의할 것인가입니다. 이를 해결하기 위한 방법 중 하나로 기존 연구에서는 Cost volume 또는 Disparity Volume 기법을 사용했다고 합니다.
Volume에 대해서 모르시는 분들을 위해 간략히 설명드리면, 저희가 일반적으로 사용하는 CNN은 입력을 2D로 넣기 때문에 feature map 역시 H,W로 이루어진 2D 데이터를 채널축으로 쌓아서 3D Tensor 형식으로 유지하는 것입니다.
하지만 3D detection과 같이 3차원 데이터를 활용하는 부분에서는 다루는 데이터가 3차원이기 때문에 Feature map 역시 3차원 축을 가지는 데이터 형식을 유지할 것이며, 해당 데이터에 채널축이라는 개념이 생기면 4차원의 Tensor형식으로 데이터 연산이 이루어지게 됩니다.
이 때 4D Tensor를 Volume이라고 표현하며, 채널축을 고려하지 않을 때는 데이터 분포가 3D라고 보시면 좋을 것 같습니다. 아무튼 해당 논문도 기존의 연구를 계승하여 Disparity Volume을 통해 Depth Estimation을 수행하는 방법론이라고 이해하시면 좋을 듯 합니다.
저자가 하고자 하는 방법을 요약하면 아래와 같습니다.
- 저자는 어떠한 후처리 과정 없이 스테레오 매칭을 위한 end-to-end learning framework를 제안합니다. (저도 stereo depth estimation 분야는 논문을 읽어본 경험이 거의 없어 잘 모르지만, 예전 방법론들 중에 disparity map을 후처리하는 방법론들도 종종 있는 듯 합니다.)
- 또한 저자는 pyramid pooling module을 통해 영상 feature들의 global context information을 통합합니다. (사실 이것 역시 해당 논문에서 처음 제안한게 아닌, 기존의 classification과 semantic segmentation에서 활용된 방법을 그냥 가져다 사용할 뿐인데… 2018년 논문이라 좋게 봐준 듯 합니다.)
- 마지막으로 저자는 3D CNN을 multiple hourglass 형식으로 설계하여 cost volume의 context information를 보충하기 위한 잔차값을 계산하였습니다.
Method
그럼 본격적으로 방법론에 대해서 다뤄봅시다. 사실 방법론도 옛날 논문이라 그런지 네트워크 구조도 단순하고, 심지어 학습 방식도 supervised라서 매우 심플합니다.
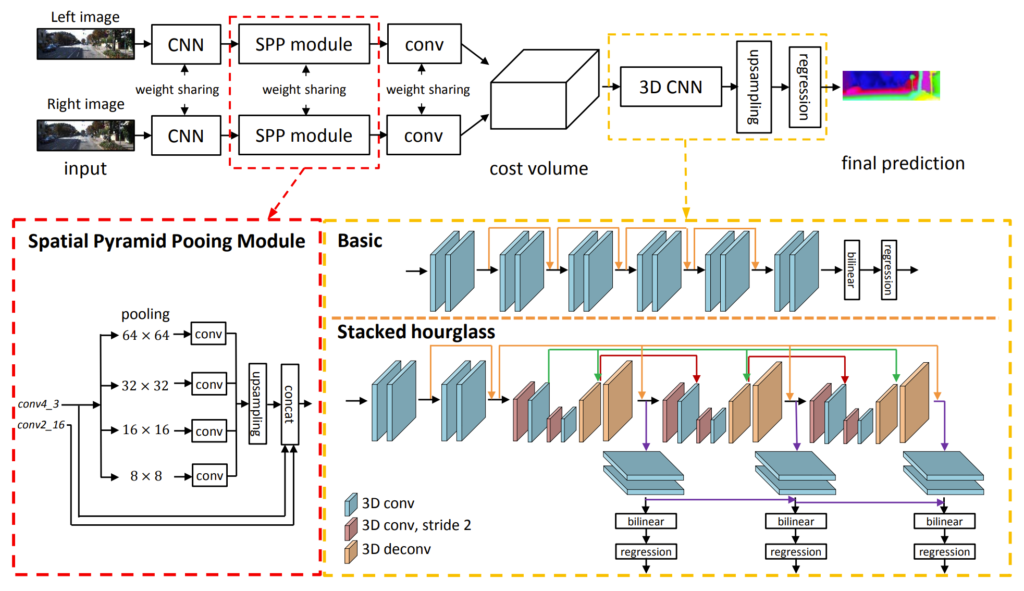
전체 과정은 그림1과 같습니다. 먼저 좌, 우 영상을 동일한 CNN 인코더에 태워서 feature map을 생성합니다. 그 후에 Spatial Pyramid Pooling module과 간단한 컨볼루션 블록을 통과하여 최종적인 image feature map을 생성합니다.
이렇게 생성된 좌, 우 feature map을 초기 disparity라고 지칭하며 해당 disparity 값들을 추출하여 새로운 차원에 concatenation 함으로써 cost volume을 생성합니다. 생성된 cost volume은 3D CNN을 통과하게 되며 3D CNN의 구조는 노란색 점선 박스에서 볼 수 있듯이, basic과 stacked hourglass 중 하나로 구성되어 있습니다. 참고로 논문에서는 쵲오적으로 stacked hourglass network를 사용했다고 합니다.
그럼 각 과정에 대해서 조금 더 세부적으로 살펴보도록 하겠습니다.
Backbone
먼저 2d feature map을 추출하는 encoder에 대해서 살펴보겠습니다.
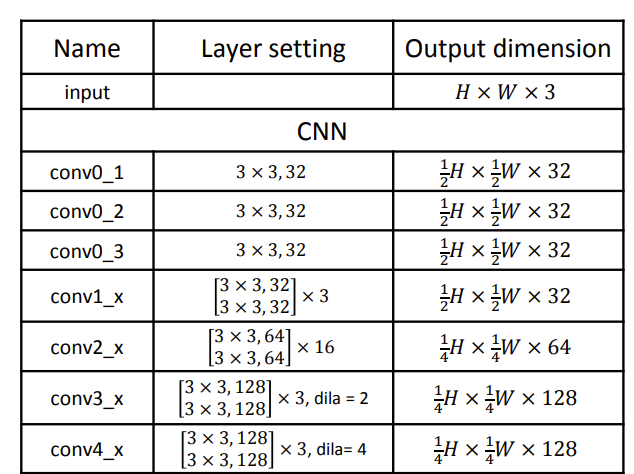
맨 앞에 백본은 그저 컨볼루션과 배치놈으로 구성된 단순한 블록으로 이루어져있습니다. 여기서 참고하실 점은, Conv3과 Conv4의 경우 dilated convolution을 사용한다는 점입니다. 이러한 이유는 receptive field를 넓힘으로써 global context modeling 능력을 조금 더 향상시키겠다는 의도겠죠.
앞서 SPP 모듈이 나온 것에서부터 짐작을 하셨겠지만 해당 논문은 Context modeling을 더 잘할 수 있기 위해 feature map을 volume 형식으로 설계하고, SPP, dilation 등의 기법을 사용하고 있습니다.
아무튼 해당 백본에서는 feature map을 원래의 입력 영상 해상도의 1/16, 1/32만큼의 사이즈로 줄이지 않고, 1/4배 다운샘플링을 하는 정도로만 연산을 수행합니다. 그렇게 연산을 하는 이유는 바로 뒤이어 나올 SPP 때문이죠.
Spatial Pyramid Pooling Module
Spatial Pyramid Pooling에 대해서는 많은 분들이 들어보셨을 거라고 생각합니다. 아마 명칭자체는 기억하지 못하더라도 컨셉과 과정에 대한 그림을 보시면 아마 쉽게 이해하실 것 같기도 합니다.
SPP는 예전에 제가 리뷰했던 segmentation 논문 리뷰에서도 나왔던 구조입니다. 사실 해당 글에서 리뷰한 논문에서도 제안한 것은 아니고 그냥 가져다 사용한 것이긴 하지만 해당 글에 제가 SPP의 구조와 역할에 대해 적어놨기 때문에 궁금하신 분들은 참고하셔도 좋습니다.
아무튼 SPP에 대하여 간략하게 설명하고 넘어가자면, 구조는 그림1의 붉은색 점선처럼 볼 수 있습니다. Conv4 feature map이 64×64, 32×32, 16×16, 8×8의 해상도의 output이 나오도록 adaptive average pooling을 수행하게 되며, 이렇게 다양한 해상도에 대하여 각각 1×1 컨볼루션을 통과해 채널수를 줄인 feature map을 생성함으로써 해상도가 다양한 spatial pyramid feature를 생성하게 됩니다.
그리고 각각의 feature map은 다시 conv4와 동일한 해상도로 upsapling이 된 후, concatenation 과정을 거치게 됩니다. 이때 저자는 Conv2_16의 feature map도 함께 concatenation을 한 다음 컨볼루션을 태웠다고 합니다.
Cost Volume
Cost volume은 인트로에서도 설명드렸다시피, 기존의 다양한 방법론에서 사용한 방법 중 하나입니다. 그리고 현재에 들어서도 다양한 논문들이 cost volume 형식으로 feature map을 표현하여 모델 학습에 사용하고 있습니다.
아무튼 저자의 경우 각각의 disparity level에 대하여 좌측 영상의 feature map과 우측 영상의 feature map을 concatenating함으로써 volume을 만들었다… 라고 주장하는데 이게 사실 글만 봐서는 쉽게 와닿지 않습니다.
단순히 생각하면 좌측 영상에서 추출한 feature map과 우측 영상에서 추출한 feature map을 채널축으로 concat 했다는 의미인가?라고 받아들일 수 있는데, 만약 채널축으로 concat을 했다면 그건 4D volume이 아닌 저희가 흔히 아는 3D tensor가 되겠죠.
보다 이해를 쉽게 하기 위해서, 저자가 공개한 코드를 일부 살펴보도록 하겠습니다.
self.maxdisp = 192
refimg_fea = self.feature_extraction(left)
targetimg_fea = self.feature_extraction(right)
#matching
cost = Variable(torch.FloatTensor(refimg_fea.size()[0], refimg_fea.size()[1]*2, self.maxdisp//4, refimg_fea.size()[2], refimg_fea.size()[3]).zero_()).cuda()
for i in range(self.maxdisp//4):
if i > 0 :
cost[:, :refimg_fea.size()[1], i, :,i:] = refimg_fea[:,:,:,i:]
cost[:, refimg_fea.size()[1]:, i, :,i:] = targetimg_fea[:,:,:,:-i]
else:
cost[:, :refimg_fea.size()[1], i, :,:] = refimg_fea
cost[:, refimg_fea.size()[1]:, i, :,:] = targetimg_fea코드에 대해서 간략하게 설명드리자면 먼저 좌, 우 이미지에 대해 self.feature_extraction변수를 통해 feature map을 추천합니다. 참고로 feature_extraction에서는 SPP모듈까지 함께 들어있다고 보시면 됩니다.
그 후 torch.FloatTensor를 통해 4D Volume 형식의 zero tensor를 미리 생성해둡니다. 마지막으로 저희가 지정해놓은 maxdisp값의 4배 감소된 값만큼에 대하여 미리 생성한 zero volume에 좌측 feature map의 disparity 값부터 우측 feature map의 값을 차근차근 담아넣게 됩니다.
이 때 4배 나눠진 영역에 대해서 계산하는 이유는, 애초에 cost volume의 shape이 \frac{1}{4}D \times \frac{1}{4}H \times \frac{1}{4}W \times 64 이기 때문이죠. 즉 feature map 자체가 4배 다운샘플링된 값이므로 disparity 값 역시도 4배 감소된 값을 설정해줘야하며 maxdisp는 결국 입력 영상의 해상도라고 보시면 될 것 같습니다.
3D CNN
위에서 Cost Volume을 만들었으니 이젠 3D CNN에 대해서 알아보도록 하겠습니다.

일단 3D CNN의 구성도는 표2와 같습니다. 각 열이 무엇을 의미하는지는, 표1과 동일하니 참고하시길 바랍니다.
그림1에서 노란색 박스를 보셔도 사실 쉽게 알 수 있는데, 3D 컨볼루션 2개로 시작을 하다가, Stacked Hourglass 영역을 들어서면서부터는, stride 값 조정을 통해 채널 축을 제외한 각 축(Disparity, H, W)는 2배씩 감소하게 됩니다. 그렇게 4배 감소하여 1/16까지 감소했으면, 다시 deconv를 통해 원래의 해상도로 업샘플링 합니다.
이렇게 줄었다 늘어났다 하는 구조가 마치 모래시계같다 하여 hourglass 구조라고 부르게 되며 이는 human pose estimation에서 자주 사용하는 구조 중 하나입니다. 이러한 hourglass는 모델의 구조를 가볍게 하여 여러개 쌓는 것을 목표로 합니다.
해당 논문에서는 총 3개의 hourglass network를 사용하였으며, 각각의 output에 대해서도 regression loss를 계산하며 첫 결과가 다음 결과에 더해짐으로써 2번째 네트워크는 1번째 네트워크의 잔차를 계산하고, 3번째 네트워크는 2번째 네트워크에서 발생한 잔차를 계산하는 방식으로 학습이 진행된다고 이해하시면 좋을 것 같습니다.
Objective Function
마지막으로 loss function에 대해서 알아보겠습니다. 먼저 3D CNN을 통해 최종적인 disparity map을 구하는 과정에 알고 넘어가야하는데, 아래 수식처럼 진행이 됩니다.
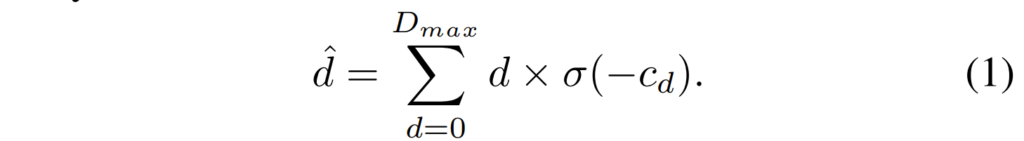
여기서 d는 disparity이며 c_{d}는 저희가 3D CNN을 통해 계산한 cost volume을 의미합니다. 여기서 c_{d} 의 shape은 표2에서 볼 수 있다시피 D x H x W 이며, softmax에 해당하는 \theta 를 곱해줌으로써 disparity map의 확률값으로 표현할 수 있게 됩니다.
그렇다면 저 disparity d는 어떻게 구하는 걸까요? 저 disparity는 그저 disparity 축으로 연속적인 값이 존재하는 vector로 cost volume 생성하는 코드에서 보셨던 self.maxdisp를 통해 생성한 것으로 보면 됩니다. 정확히는 아래 코드를 통해 연속적인 값을 가지는 one vector를 생성합니다.
self.disp = torch.Tensor(np.reshape(np.array(range(maxdisp)),[1, maxdisp,1,1])).cuda() # B, D, 1, 1저 값을 확률값인 volume에 곱해주게 되면 disparity range별로 확률값이 곱해지게 되기에 해당 픽셀이 어떤 range 구간의 값을 가지는지를 확률분포적으로 볼 수 있게 됩니다. 최종적인 disparity map은 이렇게 곱해진 disparity map에 대해 disparity 축에 대하여 모두 sum 해줌으로써 1xHxW의 어떠한 1채널짜리 disparity map을 생성하면 끝입니다.
생성된 최종 disparity \hat{d}는 GT disparity와 smoothL1 loss를 통해 계산됩니다.
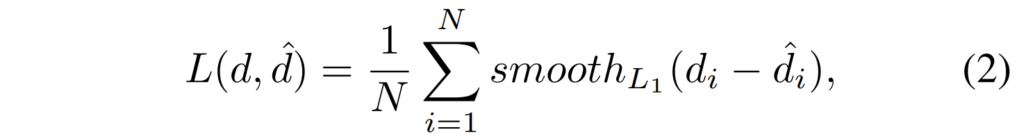
Experiments
지금까지 stereo depth estimation이라고 하였지만, 사실 좌우 영상에 대한 disparity를 구하는 task에 해당합니다. disparity를 잘 구했다면, 두 카메라가 좌우 alignment가 잘 맞았다라는 가정하에 focal과 baseline의 관계로 depth를 생성할 수 있으니깐요:)
그래서 해당 논문에서는 depth map에 대한 결과로 평가하는 것이 아닌, disparity가 과연 잘 맞추어졌는가에 대하여 마치 optical flow의 평가메트릭을 사용하게 됩니다. 데이터 셋 역시 Lidar point를 활용한 depth estimation 용 데이터 셋이 아닌, SceneFLow dataset 또는 KITTI 데이터 셋 중에서도 scene flow task를 위한 데이터 셋으로 평가하는 모습입니다.
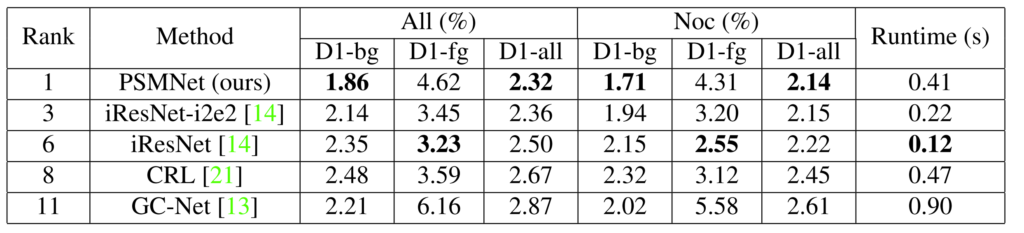
위의 결과는 KITTI 2015 dataset에 대한 결과로 먼저 All과 NoC로 구분이 되는데 ALL은 에러 측정을 할 때 모든 픽셀을 고려한 것을 의미하며, Noc의 경우 non-occluded region에 대해서만 계산한 것을 의미합니다.
또한 D1-bg, fg, all은 각각 background, foreground, 둘다에 대한 pixel 오차를 의미합니다. 즉 disparity가 실제 GT disparity와 비교하였을 때 값이 얼마나 차이나는지에 대한 평균을 계산하는 것이죠.
결과를 살펴보시면 해당 방법론은 fg에서는 순위 6위에 해당하는 iResNet과 비교하여 성능이 꽤 큰 차이가 나는 모습입니다. 하지만 bg의 경우에는 기타 방법론보다 성능이 매우 좋은 모습을 볼 수 있네요. 아무래도 bg가 fg보다 영상에서 더 많은 영역을 차지하기 때문에 bg와 fg의 평균을 나타내는 all의 경우 가장 좋은 성능을 보이는 것 같으며, 이러한 이유로 leader board상에서 1등을 차지했다고 저자가 좋아하네요.
일단 왜 해당 방법론이 bg에서는 성능이 좋고 fg에서는 안좋은지에 대해서는 저자도 딱히 설명을 하지 않습니다… 아무래도 그 원인에 대해 시원하게 분석하지는 못하는 것이겠지요. 제 추측으로는 일단 기본적으로 cost volume 형식으로 feature 가공한 것 뿐만 아니라, SPP 모듈을 통해 더 넓은 receptive field를 생성하다보니 전체적으로 넓은 영역을 차지하는 bg에 대해 globally coherent depth map을 생성한 것이 아닐까 합니다.
반면 SPP와 dilation을 통해 global context만을 고려하다보니 local context에 대해서는 명시적으로 학습에 강조하거나 하지 않았기에 성능이 감소한 것이 아닐까라는게 제 추측입니다. 실제 GT와 비교하는 과정에서도 fg보다는 bg에 더 초점을 두고 학습하는 것이 모델 입장에서는 더 빠르게 수렴하는 것이니깐요.
Ablation
다음은 SPP와 dilated conv, stacked hourglass에 대한 ablation study입니다.
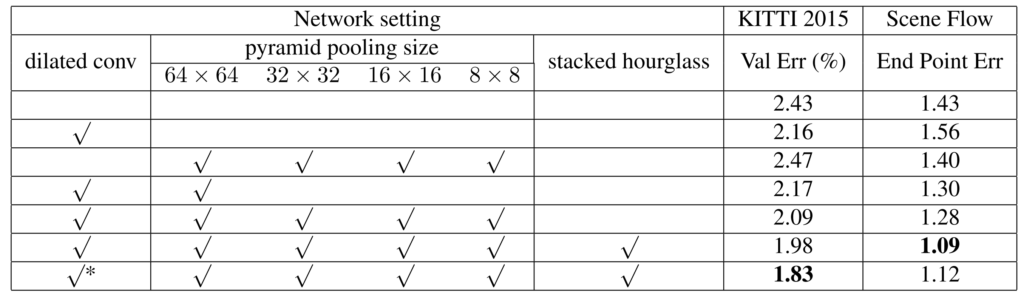
일단 제일 위에 있는 성능이 아무것도 적용하지 않은 모델로 baseline model이라고 볼 수 있겠네요.
여기서 dilation conv를 사용하게 될 경우 KITTI에서는 성능 향상이 있는 반면에 Scene Flow에서는 오히려 성능이 감소하는 모습입니다. 하지만 저자는 이악물고 해당 부분에 대해서는 무시합니다ㅋㅋ.
3번째에서는 pyramid pooling을 총 4개의 스케일을 적용하였을 때 결과이며 이때는 오히려 KITTI에서는 성능이 감소하고 Scene Flow에서 조금 좋아지는 모습입니다. 즉 pyramid pooling만을 적용하였을 때도 성능이 무조건 좋아지지는 않는다는 것이죠.
반면 이 둘을 모두 사용하게 되는 경우 두 데이터 셋 모두 성능 향상 폭이 매우 크게 일어나게 됩니다. 이 후 stacked hourglass 구조를 통해 더 향상된 결과를 보이게 됩니다.
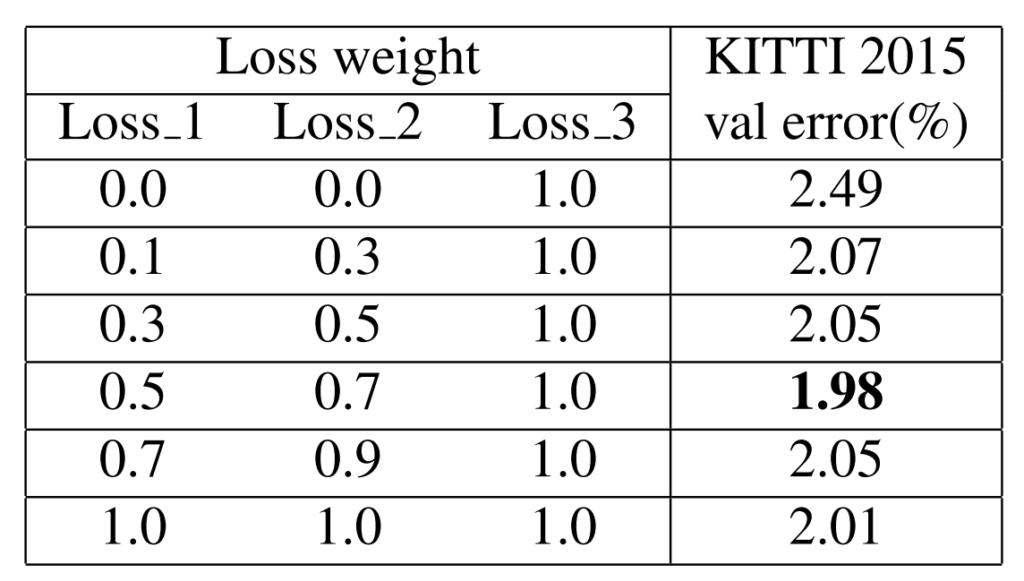
다음 표는 stacked hourglass에서 추출된 각각의 disparity map에 대하여 loss를 계산할 때 어떠한 비율로 계산한 것인지를 평가한 표입니다. 먼저 loss3만 사용하는 경우가 가장 성능이 좋지 못한 것을 보였으며, 최종적으로는 loss_1은 0.5, loss_2는 0.7, loss_3은 1일 때 가장 좋은 성능을 보였다고 합니다.
헌데 이 수치 차이가 모든 비율을 1로 하였을 때와 0.03정도밖에 차이 안나서… 랜덤성에 따른 결과가 아닐까 조용히 추측해봅니다.
결론
Cost Volume에 대해 제가 관심이 좀 생겨서 비교적 옛날논문부터 쭉 올라가면서 볼 예정이었는데, 해당 논문이 아무래도 2018년도 논문이라 그런지 컨셉 자체는 그리 흥미롭지 못하고 ablation 결과도 뭔가 통일성이 없는 아쉬움이 존재하였습니다. (어째서 이래도 CVPR…?)
하지만 Cost Volume에 대해 이러한 방법도 있다는 것에 대해서는 알게 됐다는 점에서 나름 소득도 있는 논문이며, 컨셉 자체가 저희에게 친숙하니 관심있는 분들은 가볍게 훑는 것도 좋을 듯 합니다.
리뷰 감사합니다. 3D CNN이 depth 분야에서도 사용이 되는군요 비디오에서는 시간축이 depth 분야에서는 깊이 정보에 대응이 되나 봅니다. 3D CNN을 deconv 하는 과정은 저희가 일반적으로 알고있는 transposed convolution을 사용하는 것이 맞나요?