이번 논문도 video summarization입니다. 이 논문은 RNN과 LSTM을 많이 사용하던 video summarization에 long-range dependence를 보존하기 위해 attention mechanism을 처음으로 적용한 논문입니다. 코드도 공개하고 있는데, 간단하긴 한데… 논문 그림이랑 안맞네요… 씁…
사실 최근 video summarization에 대해, 너무 주관적인 태스크다! 데이터셋에 너무 따라간다! 등의 질문을 받는데, 당당하게 아닌것같다고 대답은 했지만… 좀 고민을 해보다가 이 논문을 골랐습니다. 계속 점점 과거 논문으로 가고 있는데, 비디오 요약에 대한 설명이 많아져서 이해가 늘었습니다. 아무튼… 리뷰 시작하겠습니다.
Introduction
비디오 요약에 대한 개략적인 설명은 넘어가고… 이번 논문을 통해 알아낸 새로운 사실에 대해 다뤄봅시다. 논문 저자는 이 비디오 요약이 꽤나 주관적인 의견을 담고 있다고 생각합니다. 데이터셋에서 GT가 사람마다 개별적으로 제공되기도 하고, 논문에서 공개하고 있기 때문에 이를 바탕으로 라벨러간의 Fb-score를 계산해보면… 놀랍게도 평균 0.34가 나옵니다. (뒤에 human performace로 변환한 값도 나옵니다.) 이 말은 비지도학습으로 이 문제를 풀기 어렵다는 것을 뜻하기 때문에 논문 저자들은 지도학습으로 이 문제를 해결하고자 했다고 합니다.
이러한 상황에서 이 논문은 두가지의 Contribution을 가집니다.
- 최초로 soft, self-attention 방법론을 적용한 비디오 요약 논문
- 그리고 이 방법론이 가능하다는 것에 대한 증명
그래서 정리를 해보면 “attention을 적용하기 위해 기존의 LSTM encoder-decoder network를 soft-attention으로 대체했다.”로 contribution을 정리할 수 있습니다.
일단 왜 대체했는지를 생각해봅시다. 보통 Sequence data를 처리할 때, RNN을 제일 처음 사용했고, LSTM을 사용하는 추세에서 그 다음으로 넘어간 방법이 Seq2Seq입니다. 이렇게 넘어가는 이유가 결국은 gradient vanishing 문제와 long-range dependence 때문입니다. 하지만 Seq2Seq도 이 두 문제를 해결하지 못했고, 이를 보완할 수 있는 attention 방법론이 등장하면서 넘어가게 된것입니다.
Model Architecture
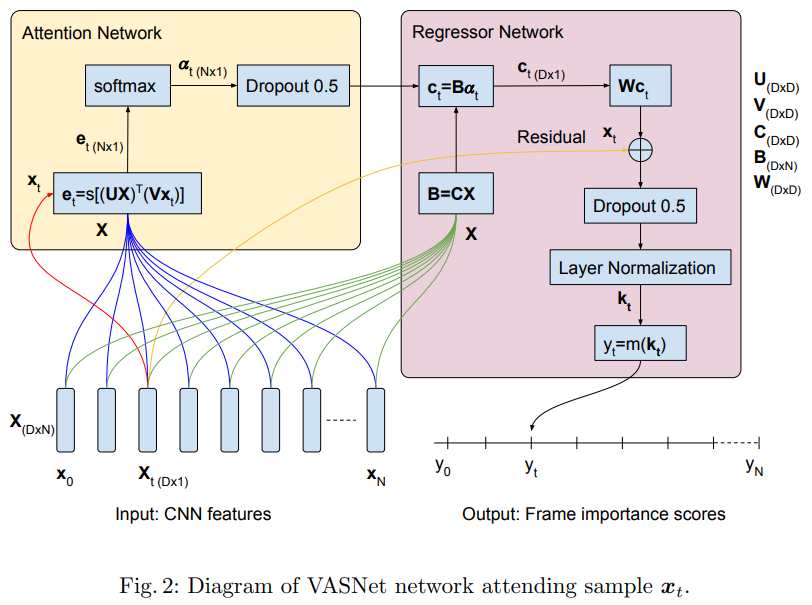
위의 구조가 끝입니다…! 지난번에 소개드렸던 논문은 되게 복잡하게 feature를 뽑아야 했는데, 그 논문이랑 성능이 그렇게 차이가 나지 않는 다는 점을 고려하면… attention-mechanism 자체가 이 작업에 적합한 것 같습니다. 일단 기본적으로 CNN feature를 사용하고 있는데, 여기서는 GoogLeNet을 사용하고 있습니다.
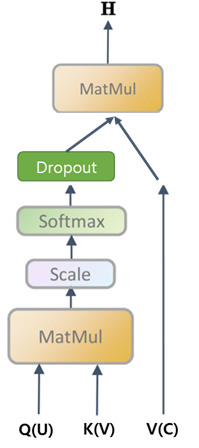
attention은 복잡하지 않습니다. 지난번에 리뷰할때 사용했던 그림을 수정해서 가져왔는데요. 위 그림처럼 self-attention에 dropout이 추가된 구조입니다. 괄호 안의 기호가 이 수식에서 지칭하는 용어니까 수식을 읽을 때 참고하시면 됩니다. (코드에서는 Q,K,V라고 쓰네요 또…)
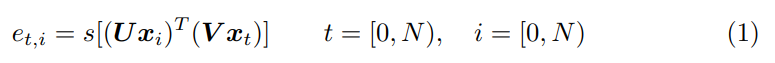
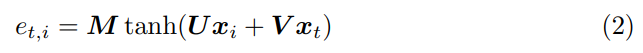
어쨋든 이 self-attention도 두가지 방법이 있다고 합니다. (1)과 (2)인데요. (2)는 병렬 처리가 어려워서 (1)로 수행을 했다고 합니다. (1)은 모든 입력 feautre x_i, x_t에 대해서 U와 V는 linear transformation입니다. 이때 두 값의 차이가 있기 때문에 scale을 조절하기 위해 s가 있습니다. 이렇게 구해진 attention vector e_t 에 softmax를 취해주면, attention weight α_t가 됩니다.
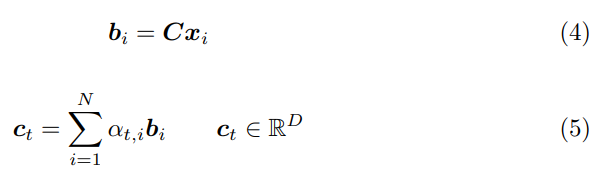
그런 다음에 입력 또 다른 linear transformation C를 입력 feature에 적용해주고, 이 값에 attention weight를 곱해줍니다. (곱해주기 전에 dropout을 적용해줍니다.) 그러면 c_t는 context vector가 됩니다.
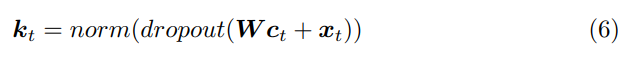
이렇게 구해진 context vector에 W(또다른 Linear layer)를 태우고, 입력 feature와 더해줍니다. 그리고 dropout과 normalization을 수행하면 frame-level importance score k_t가 됩니다.
# Attention Network
x = x.view(-1, m)
y, att_weights_ = self.att(x)
y = y + x
y = self.drop50(y)
y = self.layer_norm_y(y)
# Frame level importance score regression
# Two layer NN
y = self.ka(y) # nn.Linear
y = self.relu(y)
y = self.drop50(y)
y = self.layer_norm_ka(y)
y = self.kd(y) # nn.Linear
y = self.sig(y)
y = y.view(1, -1)
사실 그림에서는 m을 곱해주는데, 코드에도 없고… 수식에도 없어서 뭔지는 모르겠네요. 이 논문 저자들이 그림에서 말하는 B=CX에 해당하는 연산이 없습니다. (모델에는 선언해둔걸 보면, 실험하다가 성능 안나와서 뺀것같기도 하고요?) 그런 이유로 Regeressor Network 구조도 다른 것 같은데… 이상한 것 같긴 해도 방법론 자체는 간단하니까 넘어갑시다.
Frame Scores to KeyShot Summaries
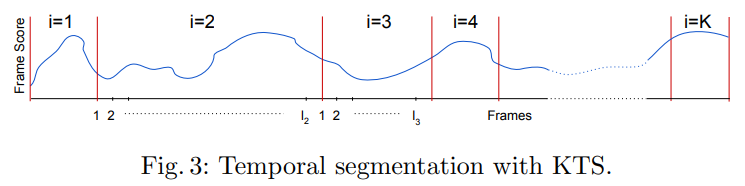
이렇게 frame-level score를 구했다면, shot-level score로 변환할 필요가 있습니다. 여기서도 KTS 알고리즘을 이용해서 scene 변화를 찾고, shot으로 나눕니다. 그런 다음 나눠진 shot을 바탕으로 frame-level importance score를 평균을 취해서 shot score를 구할 수 있습니다.
지난 논문에서는 별 말 없길래… 몰랐는데 사실 모든 요약 문제는 근본적으로 이 shot을 얼마나 골라서 요약 영역으로 정하는지의 문제이기 때문에, 근본적으로 배낭 알고리즘에 해당합니다! 단순히 성능을 부스팅 하기 위한 방법론인줄 알았는데 아니었던거죠. 그래서 결론은… 이 15% 제한도 이 배낭 문제를 해결하기 위해 GT를 바탕으로 TVsum 데이터셋에서 지정한 문제라, 무조건 있어야 한다고 합니다.
Experiments

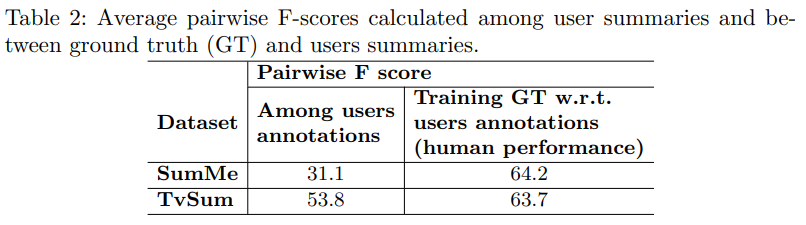
이 논문에서는 유저 라벨링 결과값을 바탕으로, 인간 성능(?)을 재계산해서 비교를 함께 수행하고 있습니다. 어떻게 계산을 하지??? 싶지만, 이 데이터셋의 GT는 여러 라벨러들이 라벨링을 한 결과값의 평균이기 때문에, 개별적인 라벨링 결과가 제공됩니다. 이를 바탕으로 역산을 하면 인간 성능을 계산할 수 있다고 합니다.
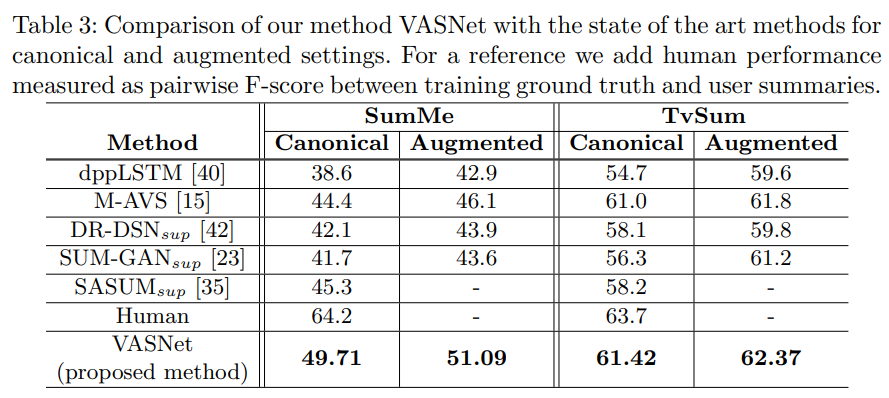
측정은 80%의 데이터셋을 학습하고, 나머지 20%는 평가에 사용하는 방법을 5번 진행해서 평균 성능을 측정한 결과입니다. (Table1에서 확인할 수 있지만, 20%라고 해도 각각 5개, 10개 비디오입니다.)
attention 방법론을 적용하면서 전반적으로 성능의 향상이 있었습니다.SumMe의 경우 비교적 모델이 GT와 유사한 영역에서 정보를 추출해서 성능이 크게 올랐고, 오히려 TvSum의 경우 SumMe에 비해 영상이 평균 70초 정도 더 길기 때문에, 이러한 긴 영상에 대한 global attention이 부정적인 영향을 미쳤다고 합니다.
그렇다고 하더라도 실험 결과를 보면, 사실 이미 TvSum은… 인간 성능에 도달했다고 볼 수 있기 때문에 성능 향상이 미미한 것도 고려를 해야하고, SumMe에서의 큰 성능 향상은 attention 방법론이 비디오 요약에서 효율적임을 보입니다.
Conclusion
논문 방법론은 attention을 최초로 적용한 논문이라 매우 간단하지만, 그 방법론 말고 인간 성능과의 비교와 video summarization에 대한 저자의 생각 등이 들어가 있어 볼만했습니다. 사실… 15% 제한이 없었다면, action proposal과 유사하게 중심 사건을 요약해주는 방향으로 변형해보려고 생각중이었는데… 이 15% 제한이 좀 큰 것 같습니다. 이런 부분들 때문에 좀 고민을 해봐야 할 것 같습니다.
TvSum과 SumMe라는 데이터 셋을 잘 몰라서 그런데, 어떤 종류의 콘텐츠를 담고 있나요?
그리고 보통 summarization 방법론들의 inference time은 얼마나 되나요?
비행기 착륙이라던가, 주방에서 요리하는 장면이라던가 눈에 빠진 차를 빼내는 사람 등과 같이, 한 비디오에 한 사건을 포함하고 있습니다. 그리고 이 논문은 아니고 “Learning multiscale hierarchical attention for video summarization'”에서 측정한 속도는 SumMe에서 27ms / TVSum에서 64.5ms 라고 합니다.