논문 소개하기전
안녕하세요. 제가 이번에 소개해드릴 논문은 PP-YOLO라고 불리는 논문입니다. 중국의 유명회사인 바이두에서 공개한 논문이고, 제목이 PP-YOLO인 이유도 바이두에서 사용하는 딥러닝 플랫폼인 PaddlePaddle로 implementation 하였기 때문이라고 하네요.
논문을 본격적으로 소개하기 전에 해당 논문을 왜 읽게 되었는지 먼저 말씀드리겠습니다. 먼저, 아시다시피 다음주에는 튜토리얼 급의 발표가 있는 날입니다. 튜토리얼급 발표로 무엇을하는게 좋을까 고민을 하였었는데 제가 가장 잘 알고, 현재 계속 연구중인 분야가 좋을거 같다고 생각하여 욜로기반의 2D Object Detection으로 정하였습니다. 그래서 YOLO시리즈를 한 번 총정리 느낌으로 쭉 훑어보기 위하여 YOLO관련 서베이논문을 2편을 읽었는데 영… 논문 퀄리티가 맘에들지 않아서 YOLO기반 메인스트림 방법론중에 안읽는 논문이 있나 살펴보던 중에 발견하게된 논문입니다.
앞에 영 마음에 안들던 논문 2편을 보고 읽은 논문이라 그런지 모르겠지만, 제가 소개시켜드릴 PP-YOLO라는 논문은 아주 좋은 논문이라고 하기에는 다소 미흡하나 꽤 괜찮게 쓰여진 논문입니다. 글의 전개가 논리적이고 군더더기없이 핵심만을 서술하며, 목표하고자하는 바가 명확한편 입니다. 그런데 YOLOV1~V4 까지에 대한 사전지식이 없으면 이해하기 힘들 수도 있으니 만약 YOLO에 대해서 전혀 모르신다고 하시면 이전에 제가 작성했던 리뷰를 찾아 읽어보시길 추천드립니다. (아마 욜로에 대해서 모르고 계셔도 전체적인 흐름을 이해하는데는 지장이 없을거 같으나 받아들이는 depth가 많이 다를겁니다.)
논문소개
YOLOv1~v3 까지는 원저자인 Redmon이 1저자로 발표한 논문으로 현재 YOLO기반의 방법론들은 대부분 YOLOv3를 기반으로 하고 있습니다. Redmon이 컴퓨터비전에서 은퇴한 후, 다른 학자들이 YOLOv4, YOLOv5, YOLOX, PP-YOLO, TPH-YOLOv5, YOLO-FIRI 등 다양한 버전들을 발표하였으며, 이번 소개시켜드릴 논문인 PP-YOLO는 메인스트림중 한개라고 생각합니다.
논문의 motivation은 YOLOv4와 상당히 유사하며, 논문저자도 이러한 점을 논문에서도 직설적으로 이야기 하고 있습니다. 기억나실지 모르겠는데 YOLOv4에서는 최적의 YOLO아키텍쳐 조합을 찾는걸 목표로 하였습니다. Augmentation, Loss term, regularization 과 같은 inference time이 거의 증가하지 않는 방법들의 조합인 “Bag of freebies”와, backbone, SPP, CSPNet 등 inference time이 증가하나 performance면에서 이점을 가지고 갈 수 있는 방법들의 조합인 “Bag of specials”로 나누어서 실험을 진행하였습니다. 이렇게 나눈 조합을 기반으로 아주 광범위한 실험을하여서 YOLOv4에서는 inference time과 accuracy를 동시에 고려할때 어떠한 조합이 가장 좋은지 실험적으로 증명하였습니다. 이러한 컨셉과 비슷하게 해당논문에서는 YOLOv3를 기반으로 몇가지 trick들을 적용하였을때 inference time 대비 성능이 오름을 실험적으로 입증합니다.
결론적으로 말씀드리자면, 각종 테크니컬한 기법들을 적용하는 실험을 하였으며, 성능을 대량 5퍼센트 정도 많이 끌어올렸습니다. 사실 최종적인 성능을 논하는게 큰 의미는 없는 논문이긴 합니다만, 다양한 기법들을 적용했을때 성능이 올랐다 정도로 해석하시면 될거같습니다. 성능을 논하는게 큰 의미가 없는 이유는 해당 논문의 목표가 다양한 trick들을 적용했을때 성능이 오르는지에 대한 실험논문이기 때문입니다. 논문에서는 더 좋은 backbone들을 놔두고 ResNet50만을 사용합니다. 마찬가지로 더 좋은 augmentation 기법들을 놔두고 mixup만을 사용합니다. 그 이유는 애초에 backbone이나 augmentation은 일반적으로 independent하게 성능을 올릴 수 있는 요소이며, 본 논문에서의 메인 타겟이 아니기 때문에 일단 general한 방법들로 고정해두고 실험을 진행하였다고 합니다. 또한, ResNet과 같이 일반적인 backbone을 사용하면 기존 DarkNet53 백본 대비 호환성면에서 이점이 있습니다. ResNet은 TensorFlow와 PyTorch와 같은 딥러닝 프레임워크에서 거의 무저건 지원하고, 특히나 TensorRT와 같은 최적화툴에서 DarkNet과같은 비주류 백본보다 더 최적화가 잘된다는 장점이 있다고 합니다.(실제로도 꽤나 큰 차이가 났다고 하네요.)
이야기가 좀 길어진거 같은데, 요약하자면 결국 해당 논문은 성능을 무저건 끌어올리는거 보다는 “다양한 테크니컬한 trick들을 욜로모델에 적용했을때 성능이 어느정도 오를까?”에 대한 실험을 진행하는 논문이라고 생각하시면 됩니다.
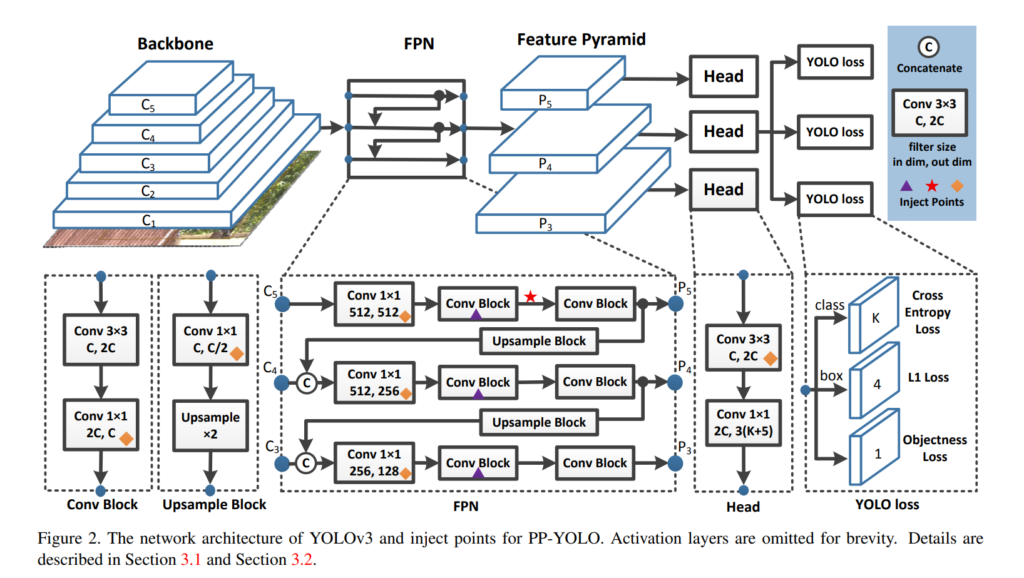
해당 논문에서는 위와같이 아키텍쳐를 설계합니다. YOLOv4와 마찬가지로 아키텍쳐를 Feature extraction, Neck, Head로 나누어서 설명하고 있습니다. 백본은 ResNet50을 사용하였으며 이유는 위에서 설명드렸습니다. 다른 욜로모델과 마찬가지로 3개의 grid map을 뽑으며, 이는 위의 그림에서 C5, C4, C3로 노테이션 되어있습니다. 결국에 각 grid map마다 detection head에서 bbox에 대한 class probabilty와 objectness score, coordinate offsets를 구하는 것이 최종 목표입니다. detection head에서는 1×1 커널사이즈의 convolution을 통해서 채널수를 조정하며, 채널수는 위의 그림에서 보이는 것처럼 3(K+5)가 됩니다. 여기서 K는 the number of classes 가 되며 각각 class에 대한 probability입니다. 5가 의미하는 것은 x, y, w, h에 대한 offset값이며 나머지 1개는 objectness score입니다. 3이 의미하는 것은 각각의 grid cell 마다 3개의 anchor를 사용하겠다는 의미입니다. 이러한 부분들은 기존 YOLO와 아주 큰 차이가 없는거 같은데 그렇다면 위에서 계속 언급하였던 Trick들은 도대체 무엇일까요? 좀 많긴한데 하나씩 이해해 봅시다.
- Larger Batch Size
먼저 첫번째 트릭입니다. 말그대로 larger batch size인데요. 이전에 YOLOv4에서는 해당 논문과 오히려 batch size를 낮춰도 성능이 잘 나오는 모델을 설계하기위해 노력하였고, 그를 contribution이라고 주장을 하는데요. 이 논문에서는 자랑스럽게 Larger Batch Size를 사용하고 learning rate와 scheduler를 사용해서 학습의 stability를 증가시켰다고 얘기하고 있네요. 전체적으로 잘 쓰여진 논문이라고 생각하지만, 개인적인 생각으로 이 부분에서는 마이너스 인거 같습니다. 결국엔 관점차이인거 같은데 저는 larger batch size로 성능을 높인건 contribtuion이 될 수 없다고 생각합니다.
- EMA
EMA는 Exponential Moving Average의 약자로 성능이 항상 마지막 epoch에 좋은게 아니라 이전에 더좋게 나올 수 있기 때문에 WEMA = λWEMA + (1 − λ)W와 같은 수식에서 λ=0.9998을 적용해서 사용했다고 합니다. 즉, 새로운 값을 조금 보수적으로 받아들이겠다는 의미라고 생각하시면 됩니다. 기존의 값에 0.9998을 곱하고 거기에 0.0002 만큼만 새로운값으로 업데이트하겠다는 의미기 때문입니다.
- DropBlock
일반적으로 Dropout은 많이 알려진 개념인데 Dropblock은 낯서신 분들이 계실거라고 생각합니다. Dropout은 어떠한 neuron에 연결된 node를 제거하는 방식이라면 dropblock은 뭉태기로 제거하는 방식입니다. Dropout은 잘 아시다시피 오버피팅을 방지하기위해 사용합니다. Dropblock도 같은 목적으로 사용되며, 해당 논문에서는 dropout대신 dropblock을 사용해야한다고 주장합니다. 그 이유는 dropout은 부분부분적으로 node를 제거하여 semantic한 정보를 날림으로써 오버피팅을 어느정도 예방할 수 있지만, 일부 node만을 제거하기 때문에 제거되지 않은 주변 node들로 부터 제거된 영역의 node가 가지는 semantic한 정보를 유추할 수 있기 때문입니다. 이를 보완하기위해 dropblock에서는 node들을 뭉태기로 제거하는 작전을 사용합니다. 즉, dropblock이 적용된 곳은 semantic한 정보가 다 날라가기 때문에 오버피팅을 방지하는데 더 효과적이라고 합니다.
- IoU Loss
YOLOv3에서는 bbox regression 과정에서 L1 loss만을 적용하고 있습니다. 그러나 AP 가 평가지표인 이상 로컬정보를 반영한 IoU를 잘 맞추는 것도 중요합니다. 이러한 이유로 YOLOv4에서는 IoU Loss에 대한 실험을 진행하였었는데 마찬가지로 해당 논문에서도 IoU loss를 추가적으로 고려합니다. CIoU, GIoU등 많은 종류가 존재하지만 해당 논문에서는 IoU loss 종류에 따라서 성능의 차이가 별로 존재하지 않았다고 이야기하며, 일반적인 IoU Loss를 적용했을때만을 리포팅합니다.
- IoU Aware
YOLOv3에서는 최종 detection confidence score로 class probability에 objectness score를 곱한 값을 사용합니다. 그러나 이렇게 그냥 class probability와 objectness score만을 곱하여 사용하는 것은 IoU에대한 고려를 할 수 없기 때문에 localization accuracy를 최적화 하는데 좋지 못하다고 합니다. 그래서 IoU를 aware하기 위해 confidence score에 IoU를 추가적으로 곱해서 사용하였다고 합니다. 음 제 생각으로 YOLOv3에서도 objectness score를 구할때 IoU를 곱하여서 사용하기 때문에 IoU를 추가적으로 한 번 더 고려하는게 큰 의미가 있을까 싶긴합니다. 그래도 실험적으로 성능이 오른거 같습니다.
- Grid Sensitive
Grid Sensitive는 개인적으로 생각하기에 해당 논문에서 제안하는 trick들 중에 가장 괜찮은 trick이라고 생각합니다. 나머지들은 다른 연구에서 제안한걸 가져다 쓴 느낌이 강한데 grid sensitive는 나름의 철학을 가지고 분석을 한 흔적이 보입니다.
![논문리뷰] YOLOv2, YOLOv3 리뷰](https://media.vlpt.us/images/minkyu4506/post/e45f1436-6925-4a1b-9b7e-4c9a92c97b39/%EC%8A%A4%ED%81%AC%EB%A6%B0%EC%83%B7%202022-02-25%20%EC%98%A4%ED%9B%84%203.44.54.png)
위의 그림은 YOLOv2 부터 사용된 offset에 대한 contraint입니다. 각 grid cell마다 center에 대한 offset을 0~1사이로 제한하기 위해 sigmoid를 사용하였습니다. 그러나 sigmoid는 항상 양수만을 output으로 내뱉으며 1을 넘길 수 없기 때문에 정확하게 0이나 1인 경우는 고려하기 힘듭니다. YOLO에서는 normalized된 scale에서 regression 이 이루어지기 때문에 미세한 차이가 결국에 성능저하를 일으킬 수 있습니다. 0과 1인 경우를 고려하기 위해서 해당 논문에서는 아래와 같은 수식 (1), (2)를 (3), (4)로 변형하여 사용합니다. 해당 수식은 욜로시리즈 소개할때 아주 자주 등장하는 수식인데 혹시 수식이 낯설다면 YOLOv2 논문 리뷰를 참고해주세요.
x = s · (gx + σ(px)) …………………………………………….(1)
y = s · (gy + σ(py)) …………………………………………….(2)
x = s · (gx + α · σ(px) − (α − 1)/2) …………………………………………….(3)
y = s · (gy + α · σ(py) − (α − 1)/2) …………………………………………….(4)
- Matrix NMS
Matrix NMS는 SoftNMS에서 영감을 받은 방법입니다. 먼저 SoftNMS는 단순하게 NMS처리단에서 hard하게 Suppress 하기 보다 soft하게 decay 시키는 방법입니다. 그런데 SoftNMS는 처리과정이 sequential하게 구성되어있어 처리속도가 느리다는 단점이 있었습니다. 사실 SoftNMS 자체가 속도가 아주 느리다고 보긴 어렵지만, prediction 결과가 많아지면 SoftNMS처리속도도 무시못할 요소가 됩니다. 이러한 연산과정을 병렬적으로 할 수 있게 한 것이 바로 Matrix NMS이며 해당 논문에서는 MatrixNMS를 사용하면 성능은 유지하되 속도가 빨라진다고 하고 있습니다.
- CoordConv
CoordConv라는 개념은 coordinate transform problem에서 나온 개념입니다.
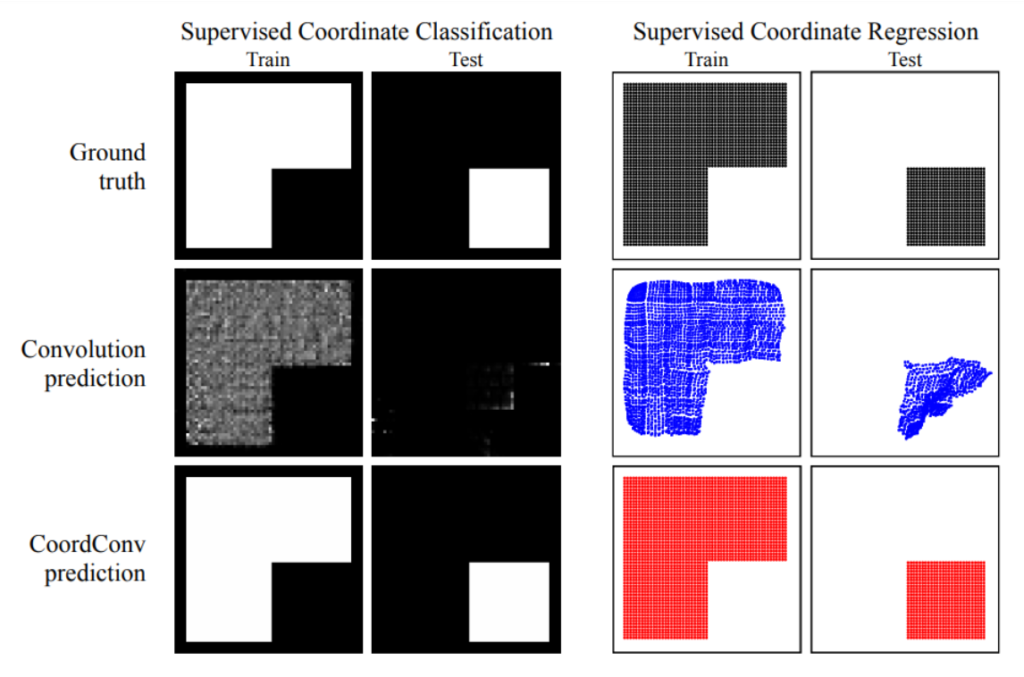
위의 그림에서 보시면 CoordConv가 Coordinate regression을 더 잘 수행한 것을 볼 수 있습니다. CoordConv에서는 간단하게 input level에 2개의 차원을 더 추가하여 Coordinate에 대한 정보를 입력으로 줍니다. 그렇게 했을때, coordinate에 대한 regression이 더 잘 되었음을 위의 그림처럼 정성적으로 확인하였습니다. 이러한 분석은 coordinate regression이 들어가는 object detection에서도 유효한 분석이라고 판단하여 해당 논문에서는 CoordConv를 사용하였습니다.
- SPP
해당 내용은 제가 리뷰한 내용이기도 한데요. SPP라는 컨셉은 2015년 Kaiming He에 의해서 제안된 방법입니다. 결국에 CNN에서 Scale invariant하게 output을 뽑겠다는게 핵심 컨셉입니다. SPP모듈이 없으면 H하고 W가 CNN파라미터 및 인풋해상도에 따라서 변하게되는데 SPP모듈에서는 Global pooling과 local level pooling 연산을 통해 fixed size의 피쳐맵을 뽑아냅니다. 제가 YOLOv4리뷰할때 자세하게 다룬적이 있으니 참고해보세요.
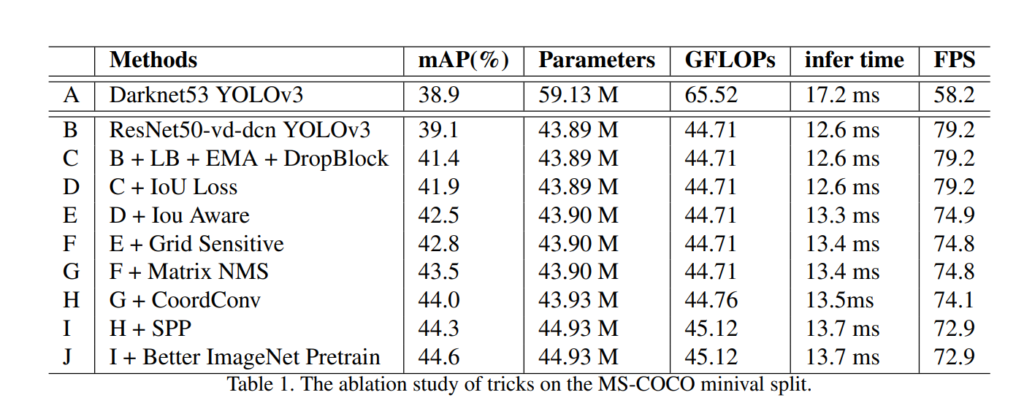
그리고 위에서 언급한 조합들을 추가하였을때 성능 및 파라미터변화, GFLOPs, 추론속도(FPS, ms)등을 비교하였습니다.
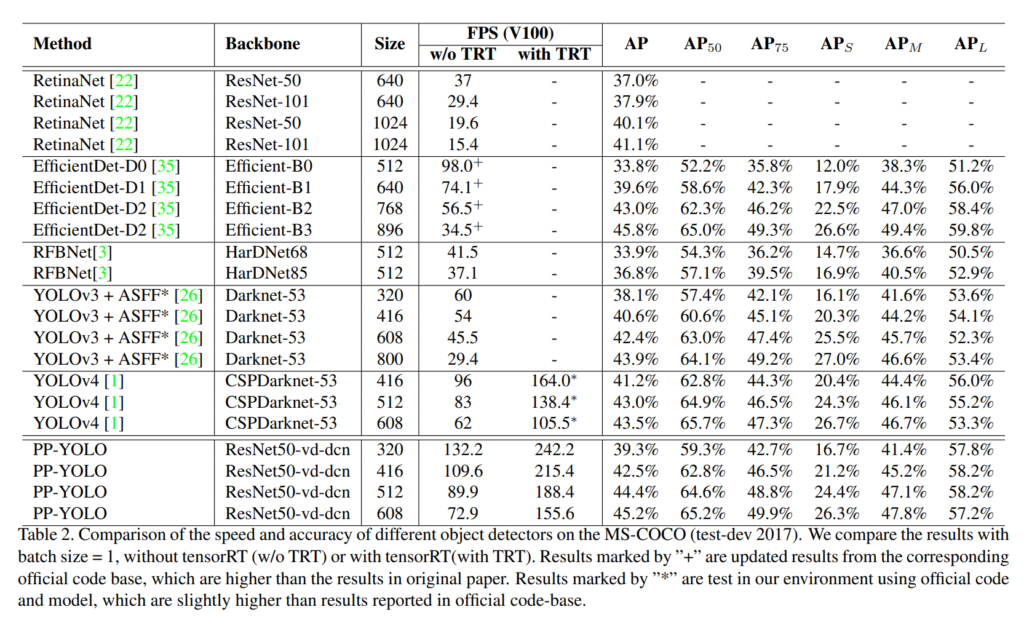
그리고 최종적인 조합으로 모델을 설계하였을때 위와같은 결과를 얻은것을 알 수 있습니다. 해당결과에서 백본을 더 좋은걸로 바꾸거나 Augmentation기법을 더 추가하면 성능향상폭이 더 클것으로 기대됩니다.
리뷰를 마치며
해당 논문은 YOLO에서의 끝판왕 논문인 YOLOV4의 mini version이란 느낌을 많이 받았습니다. V4가 워낙 masterpiece라서 좀 뭍히는 경향이 있긴한데 PP-YOLO도 좋은 논문이라는 생각에는 변함이 없습니다.