이번에 리뷰할 논문은 나온지 열흘 조금 넘은 따끈따끈한 backbone 논문입니다. 백본 분야 논문을 자주 읽고 리뷰하다보니 자꾸 익숙한 분야로 리뷰가 손이 가네요.. 다양한 분야의 논문을 읽어야될 필요성이 있다고 생각되는 요즘입니다.
아무튼 해당 논문은 아직 아카이브에만 올라왔음에도 불구하고 star가 벌써 300이 넘은 방법론이며, 실제로 읽어보니 내용도 좋고 컨셉 자체도 간단해서 한번쯤은 보면 좋을 것 같아 가져왔습니다.
Intro
이 논문에서 주장하고자 하는 핵심을 요약하면 아래 표와 같습니다.
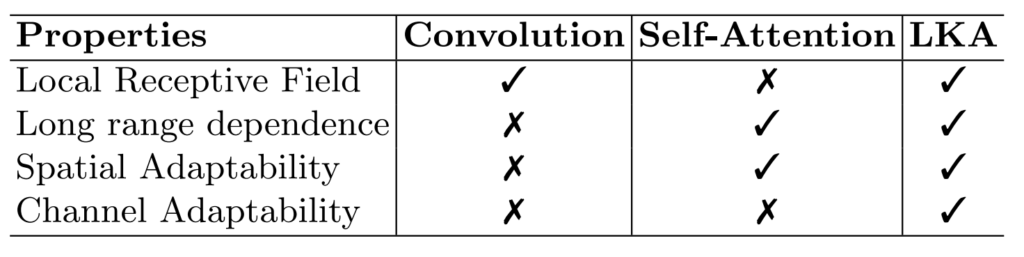
컨볼루션은 보통 3×3 작은 커널 사이즈를 통한 local receptive field를 가지고 있어서 세부적인 디테일들을 보기에는 좋습니다. 하지만 그 의미는 바꾸어 말하면 long range dependence를 모델링하기에는 취약하다는 것이죠.
반대로 Self-attention은 ViT 기준으로 전체 feature map에 대하여 서로의 유사도 스코어를 계산하는 과정을 거치기 때문에 global receptive field를 가진다고 볼 수 있습니다. 이러한 점에서 long-range dependence를 잘 볼 수는 있지만, 반대로 local한 부분은 놓칠 수 있습니다.
이번엔 Spatial&Channel Adaptability 관점으로 접근해볼까요? 컨볼루션은 고정된 weight를 가지는 필터를 통해 feature map 전체를 다 살펴보게 됩니다. 즉 특정 영역에 대해 능동적인 weight를 적용하지 못하므로 Spatial Adaptability를 가지지는 못합니다. 물론 채널축에 대해서도 따로 weight를 능동적으로 주는 연산은 없기에 Channel Adaptability도 없다고 볼 수 있습니다.
반면 Self-Attention의 경우 local patch들간의 중요도 score를 계산하여 value map에다가 곱해주는 방식을 수행하기 때문에, Spatial Adaptability는 존재하고 있지만, 마찬가지로 채널축에 대해서는 따로 어떠한 연산을 취해주고 있지 않기 때문에, Channel Adaptability는 없다고 볼 수 있겠습니다.
위의 표에는 없지만 Self-Attention의 단점들을 더 꼽아보자면 2가지가 더 존재합니다. 하나는 NLP분야에서 사용된 방법을 가져온 것이기에, 1D 방식의 attention 기법을 사용하지만 영상은 2D라는 점에서 구조적 특성들을 살리기 힘들다는 것이며, 나머지 하나는 2D 이미지 자체가 1D 보다 더 고해상도의 데이터이기 때문에 연산 복잡성이 매우 높아진다는 것입니다. 사실 이러한 단점은 Swin Transformer에서 먼저 다루긴 했었죠.
이러한 관점에서 해당 논문은 Convolution과 Self-Attention의 장단점, 그리고 이 두 연산들이 모두 가지지 못하는 특성(Channel Adaptability)까지를 모두 가질 수 있도록 새로운 구조의 backbone을 만드는데 이것이 바로 LKA입니다. Large Kernel Attention의 약자라고 하는데 이름은 확 와닿지는 않네요ㅎㅎ..
아무튼 위의 표를 다시보면 LKA는 local receptive field를 가지면서 동시에 Long-range dependence를 모델링할 수 있고 Spatial & Channel에 대하여 모두 adaptability를 가지게끔 설계되었다고 합니다.
Large Kernel Attention
인트로에서 LKA에 대한 설명을 드렸는데, LKA는 총 4가지의 특성을 다지니고 있기 때문에 모델 구조 역시 복잡하지 않을까 라는 생각을 하실 수 있습니다. 하지만 막상 구조는 그림1과 같이 매우 심플하고 단순합니다.
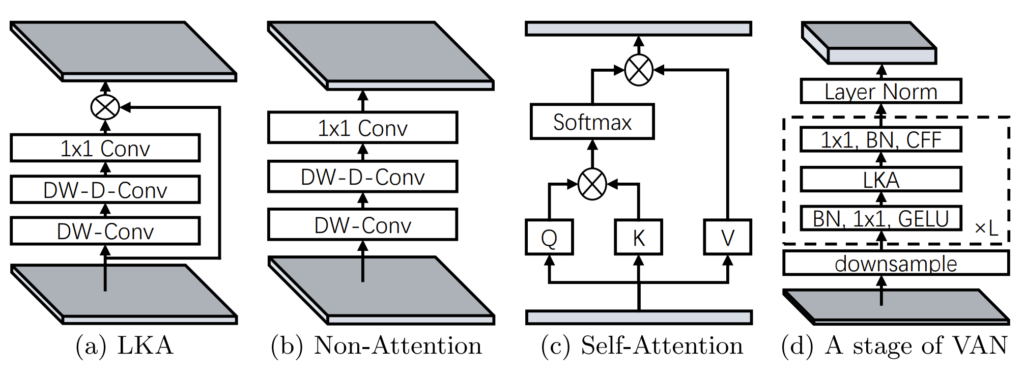
그림1-(a)를 살펴보시면 DW-Conv, DW-D-Conv는 각각 DepthWise Convolution과 DepthWise Distilated Convolution을 의미합니다. 저자가 말하길 DW-Conv는 Spatial Adaptability 특성을 살릴 수 있도록 하는 것인데, 제가 예전에 리뷰한 ConvNeXt 방법론에서도 DW-Conv의 효능?에 대해서 한번 다룬적이 있기에 해당 내용을 참고하시면 이쪽 부분을 이해하기 편할 듯 합니다.
그럼에도 일단 단순하게 말씀드리자면 DW-Conv는 각 feature map의 채널별로 서로 다른 weight를 가지는 filter로 연산을 수행하기 때문에 채널별로 feature map이 가지는 spatial 성분들이 서로 다릅니다. 그렇기 때문에 Spatial Adaptability를 가질 수 있다 라고 보시며 될 것 같습니다.
두번째로는 DW-D-Conv입니다. dilation convolution을 통해 최대한 연산량 및 파라미터 수는 유지한 체, 더 넓은 receptive field를 가짐으로써 long-range dependency를 살펴보려고 한 것 같습니다.
마지막으로 1×1 컨볼루션을 통해 채널축에 대하여 연산을 함으로써 Channel Adaptability을 가지게 된다고 합니다. 근데 이렇게 단순해도 되나..? 싶기도 하지만.. 아무튼 이러한 연산들을 조합함으로써 자신들의 LKA는 인트로에서 설명한 table의 4가지의 특성을 다 지닌다고 합니다.
이렇게 DW-Conv, DW-D-Conv, 1×1 Conv를 통과한 feature map은 일종의 attention map이라고 볼 수 있으며 이를 이전의 feature map과 element-wise multiplication을 거침으로써 최종적인 attention이 적용됐다고 볼 수 있습니다. 해당 과정을 수식으로 나타내면 아래와 같습니다.
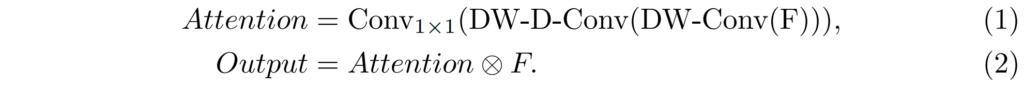
만약 attention을 적용하지 않을 경우에는 그림1-(b)와 같이 입력으로 넣은 feature map을 element-wise multiplication을 안해주면 됩니다.
아무튼 최종적으로 저자가 제안하는 네트워크 VAN(Visual Attention Network)는 그림1-(d)와 같은 구조를 가지고 있습니다. stage가 바뀌면 맨먼저 2배 downsampling 작업을 거친 뒤 BatchNorm, 1×1 conv, GELU로 이루어진 블록을 통과한 후 다시 LKA block과 1×1, Batchnorm, CFF로 이루어진 블록을 통과하고 이러한 과정을 L번 반복하게 됩니다.
여기서 CFF는 convolutional feed-forward network라고 저자는 말하는데, 정확히 무엇인지는 잘 모르겠네요? 그냥 컨볼루션 레이어가 연속적으로 이루어진 작은 네트워크를 말하는건지.. 설명은 따로 없고 참조만 되어있는 것으로 봐서는 이전에 CFF라는 것을 제안한 논문이 있는 듯 합니다.
네트워크의 자세한 구조 및 종류들은 아래 테이블을 통해 확인하실 수 있습니다.
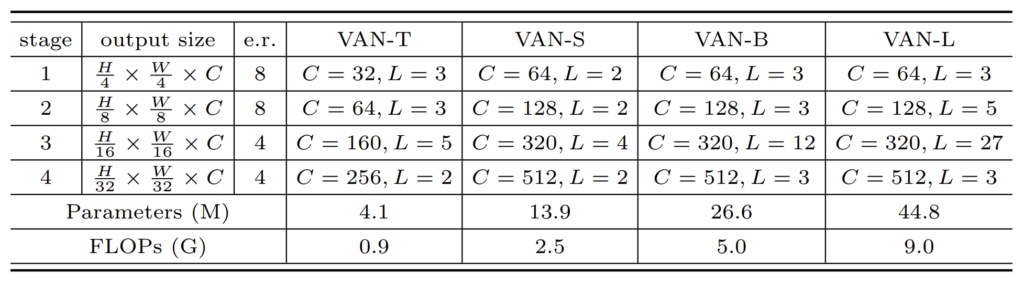
눈여겨보실 점은, 요새 Backbone들처럼 첫스테이지부터 4배 다운샘플링된 해상도의 feature map을 가지고 연산을 수행한다는 점입니다. 그리고 e.r.은 feed-forward network의 expansion ratio를 의미한다고 합니다.(흠 feed-forward network에 대해서 한번 알아봐야할 것 같기도 하네요.)
구현적인 측면에서 간략하게 설명드리면, LKA에서 DW-Conv는 5×5 커널 사이즈를 가지며, DW-D-Conv는 7×7 커널사이즈에 dilation값은 3을 가지게 됩니다. 그래서 최종적으로 21 x 21 커널사이즈를 가지는 컨볼루션과 유사하게 진행할 수 있다고 합니다. 조금 더 디테일한 구현은 논문을 참고하시면 좋을 듯 합니다.
Experiments
논문에서는 ImageNet, COCO object detection, ADE20K 데이터 셋에 대하여 실험을 보이고 있습니다.
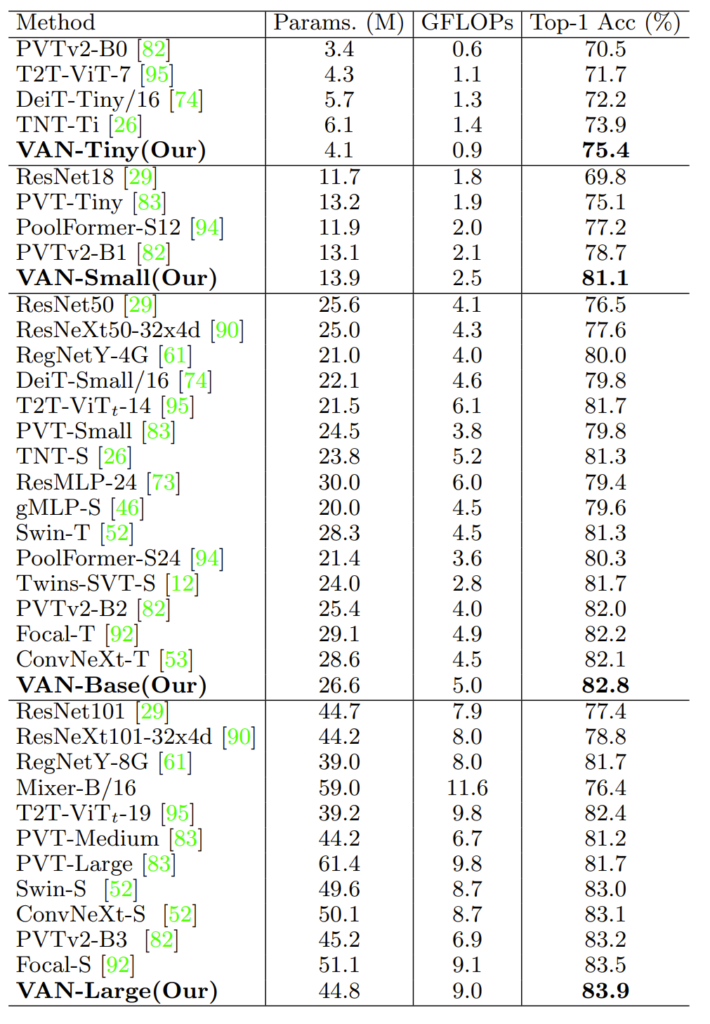
먼저 위에 표는 ImageNet-1K에 대한 결과입니다. 모델크기는 위에서 봤다시피 Tiny, Small, Base, Large 순으로 이루어져있으며, VAN-Large는 Swin-S과 ConvNeXt-S 모델의 크기와 얼추 비슷한 모습입니다. 하지만 성능적인 면에서는 Swin Transformer뿐만 아니라 최근에 나온 ConvNeXt보다도 더 좋은 모습을 보여주고 있네요.
다음은 ADE-20K에 대한 세그멘테이션 결과입니다.
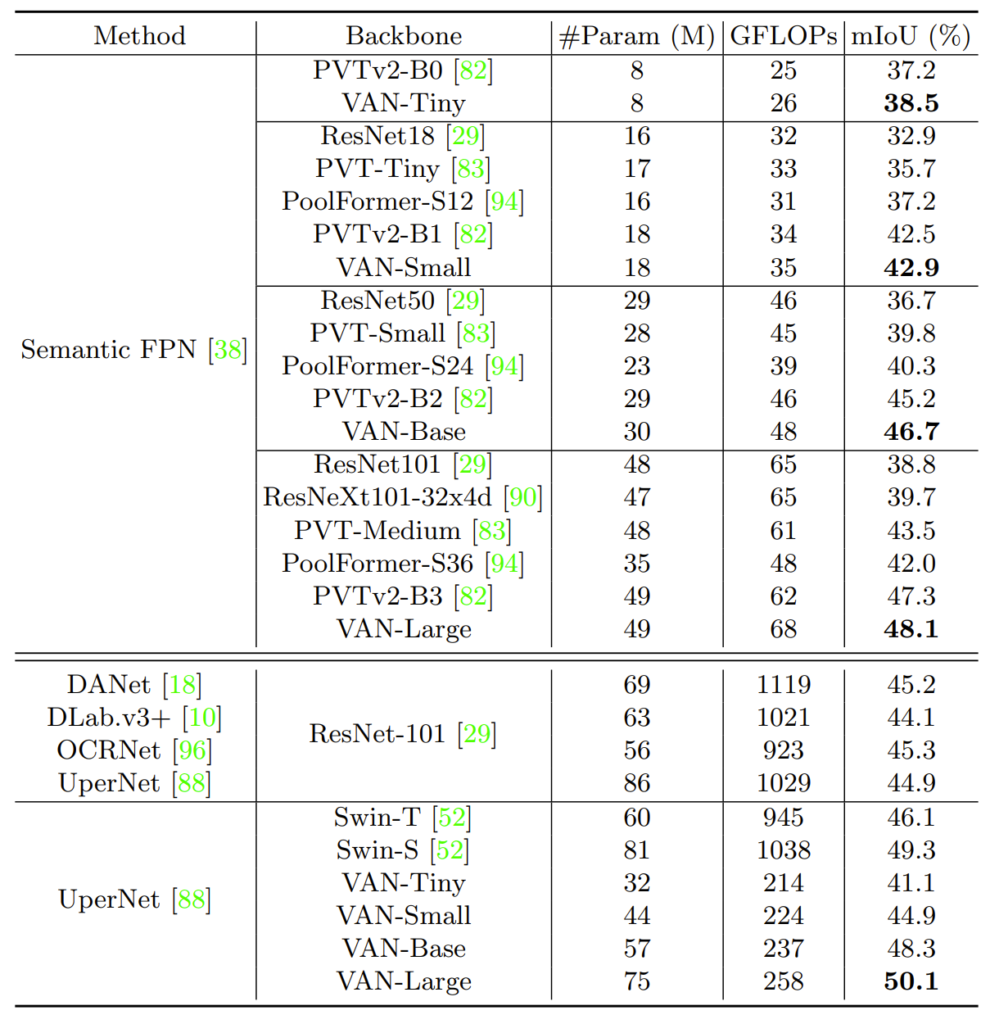
Segmentation의 경우 Decoder가 따로 필요한 task이기 때문에 어떤 decoder를 사용하느냐에 따라서 결과를 나눈 모습입니다. 가장 대표적으로는 FPN 구조 방법론을 사용하거나 가장 아래에 UperNet을 사용하는 방법으로 나눌 수 있습니다.
표에서 볼 수 있다시피 어떠한 디코더 방법론을 적용한다하더라도 VAN backbone이 다른 backbone에 비해 성능이 더 좋은 것을 볼 수 있습니다. 뿐만 아니라 Swin Transformer와 비교하였을 때 GFLOP 값 역시도 매우 큰 차이가 나는 것을 볼 수 있는데, 아무래도 segmentation은 입력 해상도가 imagenet과 달리 512이상의 해상도를 사용하다보니 self-attention 연산이 아닌 DW Conv 연산을 통해 연산속도가 크게 줄어든 것이 아닌가 하는 생각입니다.
참고로 여기서는 ConvNeXt 백본이 없길래 성능이 더 높아서 안넣었나 봤더니 VAN보다 더 좋지는 않은 것 같습니다. 대충 Swin Transformer와 VAN 사이에 ConvNeXt 성능이 있다고 보시면 되겠습니다.
Ablation study
사실 해당 부분이 가장 메인이 아닐까싶습니다. LKA를 구성하는 요소들에 대하여 각각 어떠한 성능차이를 보이는지를 ablation합니다. 실험은 ImageNet-1K에 대하여 VAN-Tiny모델로 진행되었습니다. 아마 여러 실험을 빠르게 수행하기위해 가장 가벼운 모델로 학습하고자 한 것 같습니다.
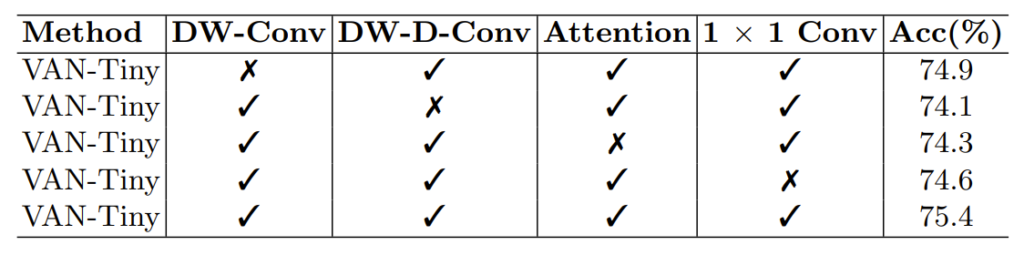
먼저 DW-Conv를 제거하였을 경우 기존 LKA 성능 기준 0.5% 수준으로 감소합니다(75.4% –> 74.9%) 저자는 이를 통해 DW-Conv가 structural information을 잘 포착하며 해당 정보를 잘 모델링하는 것이 중요하다고 주장합니다만, 생각보다 성능 감소 폭이 다른 요소들에 비하여 적은 것을 볼 수 있습니다.
제가 생각했을 때는 DW-D-Conv가 long-range dependency 뿐만 아니라 structural information을 어느정도 보완해주기에 DW-Conv가 없는 경우에서 성능 감소 폭이 그리 크지 않은 것이 아닐까 생각합니다.
반면 DW-D-Conv가 제거될 경우에는 성능 감소 폭이 1.3%로 가장 크게 발생하게 됩니다. 이를 통해 저자는 visual task에서 long-range dependence의 필요성에 대해 매우 큰 강조를 하게 됩니다.
세번째는 Attention 적용 여부에 따른 결과입니다. Attention 적용 여부는 위에서도 언급했다시피 그림1-(b)와 같은 상황을 의미합니다. 이때에도 역시나 성능 감소 폭이 2번째로 큰 것을 볼 수 있습니다.(75.4 –> 74.3) 이를 통해 저자는 attention 기법이 네트워크가 더 능동적으로 학습할 수 있도록 관여한다는 것을 증명한다고 주장합니다.
마지막으로는 1×1 컨볼루션의 여부에 따른 성능 차이입니다. 1×1 Conv는 channel dimension에서의 관계를 컨볼루션 연산을 통해 포착하는 역할을 수행한다고 말씀드렸으며, 해당 연산을 수행하지 않을 경우 성능 감소 폭이 0.8% 정도 발생하게 됩니다. 이를 통해 채널 축에 대한 adaptability도 필수적이다라고 저자는 주장합니다.
제가 생각했을 때는 저자의 의견이 틀리다고는 생각하지 않으나 살짝 애매한 부분이 존재합니다. DW 컨볼루션은 각 채널축에 대해 서로 다른 weight를 가지는 filter 연산을 수행하다보니 채널축에 대하여 각 feature map들끼리 어떠한 연산을 일절 수행하지 않습니다.
하지만 일반적인 컨볼루션 연산은 간략히 말하면 tensor 형식의 weight filter를 통해 채널축에 대해서도 연산 과정을 거치고 있기 때문에 이와 연산 과정을 동일하게 하도록 대부분의 DW Conv를 사용하는 방법론들은 DW-Conv 다음에 1×1 Conv를 이어서 사용하게 됩니다. 그렇기 때문에 1×1 conv의 중요성 필요성을 자신들이 발견하였다.. 라는 느낌이 들기에는 기존의 방법론들도 다 동일하게 사용하기 때문에 이 부분에 대해서는 그리 인상깊게 느껴지지는 않는다고 생각합니다.
결론
해당 방법론은 기존의 컨볼루션과 Transformer의 Self-Attention 방법론들의 장단점 및 특성을 명확히 집어내고, 이를 해결하기 위하여 새로운 구조의 backbone을 제안합니다. 해당 구조는 엄청 참신하다기보다는 기존의 구조들에서 조금 더 추가한 수준에 불구하지만, 성능은 Sota backbone들을 다 능가한다는 점에서 의미가 있다고 보이며, 이러한 특성들을 바탕으로 다음에 네트워크나 모듈을 설계할 일이 있으면 참고하시면 좋을 것 같습니다.
새로운 백본 모델을 알 수 있는 발표였습니다. Depth Wise Dilated Convolution에서 dilation rate는 각 단계의 feature마다 값이 최대가 되도록 설정하는건가요?