요약
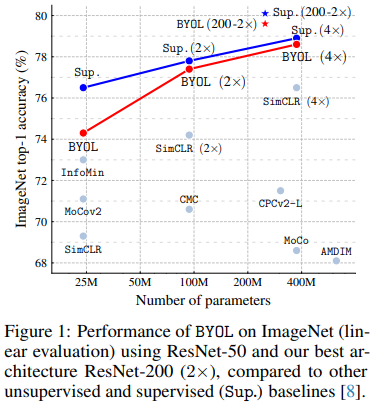
self-supervised image representation learning 을 위한 새로운 접근법으로 제안하는 Bootstrap Your Own Latent (BYOL) 를 소개하는 논문이다. Neural Information Processing Systems에 2020년 공개된 논문으로 당시에 ImageNet에서 기존의 unspervised 와 supervised 방법론에 비해 높은 classification 성능을 달성하였음을 그림1에서 확인할 수 있다.
배경지식 및 필요성
기존의 self-supervised 는 보통 positive pair와의 거리를 가깝게 하고 negative pair와의 거리를 멀게 하여 표현력을 학습한다. 이러한 방법은 주로 negative example의 중요도가 높다. 따라서 이러한 방법을 사용할 때 negative pair에서 batch size , memory banks, customized mining stategies 에 대한 의존도를 낮추고 언제나 좋은 표현력을 학습하기 위한 대표적인 negative sample을 선정하는 것이 중요하다. 저자들은 이러한 것들에 대한 의존도를 낮추고 robustness를 개선하기 위하여 directly bootstrap the representations을 제안한다. bootstrap이란 모델의 학습을 이용해 모델의 성능을 개선하는 것으로 대표적으로 pseudo-labels을 이용하는 방법이 있다. 해당 방법은 이전 x-review에서 여러번 등장하여 이해가 쉬울것이라 기대한다. (pseudo-labeling, self-training: 모델이 unlabeled data에 예측한 값 중 확신도가 높은 값을 pseudo-label로 하여 학습에 사용하는 기법) representation을 directly하게 bootstrap에 이용하기 위해 BYOL은 online networks와 target networks로 구성되는데, augmented 된 image에 대한 target의 예측을 online network가 학습하도록 하는 방식이다. 기존의 방식의 경우 변형된 동일 이미지에서 모델이 같은 정보를 임베딩할 수 있도록 representation space에서 output이 동일하도록 loss를 구성하였기 때문에 모든 이미지에서 동일한 output을 예측하는 collapsed problem이 발생할 가능성이 있었다. 그러나 BYOL에서는 collapsed problem이 발생하지 않음을 실험적으로 확인하였다. 그렇다면 왜 online network로 target network의 학습을 받아 재학습하는 것이 성능 향상에 도움이 될까? 이러한 가정을 세우기 위해 저자들은 다음과 같은 가설을 소개한다. (1) online networks에 변수를추가하고 (2) online network에 속한 parameters의 moving average를 이용하여 target network를 개선하면 collapsed 문제가 발생할 염려 없이 학습 과정 중 더 많은 정보를 학습할 수 있다는 것이다.
방법론
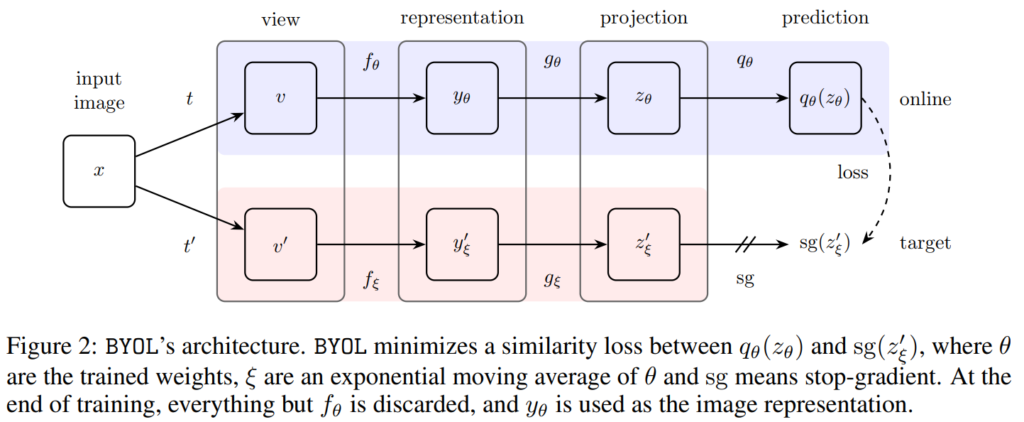
제안하는 방법론은 앞서 소개한것처럼 online network가 target network의 prediction을 예측하도록 하는 방법론이다. 이렇게 서로 다른 두 branch를 이용해 학습할 때 발생할 수있는 collapsed 문제를 피하기 위해 제안하는 방법은 random으로 초기화하여 parameter가 고정된 target 모델로 사용하는 것이다. 실제로 랜덤 초기화한 모델의 top1 acc가 1.4%인 반면 BOYL과 같은 bootstrap 방식을 사용하였을 때 18.8%를 달성하였다.
모델은 그림2와 같이 online 과 target branch로 구성되고 target output을 online model 학습에 사용해 bootstrap 한다. 네트워크는 encoder(f)와 prejector(g), predictor(q)로 구성되어있으며 predictor network를 제외한 구조는 target network와 online network가 서로 같다. 이때, weight는 공유하지 않는다.
online network는 target network의 output을 regression 하도록 학습하고, target network의 parameter는 online networks의 parameters 평균과 같아지도록 변화하도록 학습이 진행된다. (이는 기존 리뷰에도 등장했던 momentum ema 방식과 같다.) 이는 기존에 많이 리뷰한 student의 지식을 반영한 teacher 모델을 갖는 지식 증류 모델 학습법과 같다.
위의 방법론을 보면 아마 앞선 Self-Supervised 리뷰에서 많이 보았던 접근 방식일것이다. 각 논문의 발표된 순서를 정리해보아야 알겠지만 이 방법론의 특이점은 그럼 무엇일까? 우선 기존 논문은 collapse를 막기 위해 negative sample을 선정해서 서로 다른 정보 간에 distance가 멀게 모델링 되도록 하였다. 해당 논문은 이러한 명시적인 collapse 예방적 차원의 설계를 하지 않고 동일한 정보에 대한 target과 online의 예측값이 같아지도록 설계되었다. .. exponential moving average를 통해 자신의 성능이 학습을 위해 사용될 수 있도록 업그레이드 하는 구조는 이러한 설계없이 collapse 현상을 막았음을 실험적으로 보였으며 더이상 negative sample에 얽매이지 않아도 된다는 실험 결과를 가져왔다. 기존 연구는 좋은 negative sample을 선정하려고 많은 어려움을 겪었었는데, 이러한 고찰없이 self-supervised가 가능함을 보인것이다.
실험

먼저 self-supervised 방식에서 evaluation을 위해 많이 사용하는 linear evaluation을 통한 실험결과는 실험1과 같으며 기존 self-supervised, semi-supervised 방법론 중 가장 좋은 feature 표현력을 지님을 확인하였다.
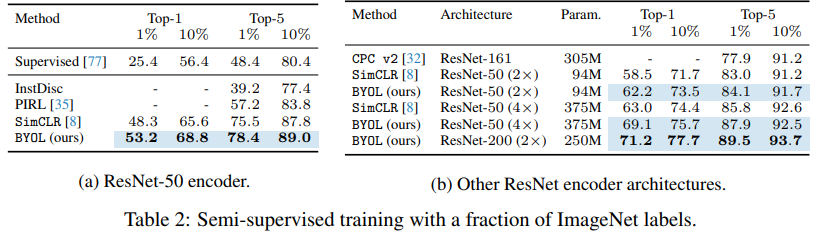
다음으로 semi-supervised 방법론에 대해서도 기존의 유명 방법론인 SimCLR과 견줄만한 성능을 보였다.
self-learning에서의 motivation은 언제나 참 논리적이고 간단하다 라는 생각이 드는 것 같습니다.
그런데 서론에서 collapsed problem이 꽤나 큰 문제이며 이를 실험적으로 증명하엿다고 하는데 해당 내용이 없어서 궁금해지네요. 저번 세미나에서도 이 이슈를 다룬 논문을 리뷰했던 것으로 기억하는데 이 문제가 성능 저하를 일으키는 이유를 실험적으로 어떻게 증명하였는지를 설명해주셨으면 좋을 것 같습니다!
그리고 batch size , memory banks, customized mining stategies 에 대한 의존도를 낮추고 robustness를 개선하기 위한 방법론을 제시하였다고 했는데요, 그렇다면 본 논문에서는 배치 사이즈는 몇으로 설정하였을까요? 해당 얘기만 들었을때 배치 사이즈를 작게해도 좋은 성능을 낼 것 같은데 테이블1에서의 설정값들이 궁금합니다.