오늘 리뷰할 논문은 AAAI 2021에 accept된 “Enhancing Unsupervised Video Representation Learning by Decoupling the Scene and the Motion” 이라는 논문 입니다. 최근 video representation을 목적으로한 여러 연구들에서 motion 정보를 활용하고자하는 방향들이 많이 보이곤 합니다. 해당 논문도 이러한 방향과 마찬가지로, 비디오 내의 scene과 motion을 decoupling 하는 DSM (Decouple the Scene and the Motion)을 제안하여, motion에 좀 더 초점을 맞출 수 있도록 하였습니다.
1. Method
1.1 Motivation
현재 image representation learning에서 self-supervised learning 기반 방법론들은 supervised learning 기반 방법론들의 성능을 우회하고 있습니다. 그러나, 아직 video representation learning에서는 그러지 못하고 있으며, 이에 대한 이유는 프레임이 많아 좀더 복잡하거나 혹은 리소스를 많이 먹어 상대적으로 느리게 발전하고 있다 등등 여러 가지 존재합니다. 또한, 그 중 하나의 이유로는 image 데이터 셋들이 object-dominated 한 반면, 많은 video 데이터 셋들은 scene-dominated 하다는 것도 있습니다. 주로 image 데이터 셋들은 한 장의 image 내에 object가 표현되어 있기에 object가 차지하는 비율이 높은 반면, video 데이터 셋에서는 한 video 내에 object가 없는 경우도 있고 object 전체의 움직임을 표현하기 위해 object가 작아 scene의 비율이 높은 경향을 나타냅니다.
실제로 이와 같은 scene bias한 문제들을 풀기 위해서, SlowFast나 혹은 지난번 소개드렸던 MCL과 같은 방법론이 제안되어 왔고, 본 저자도 이를 해결하기 위해 DSM을 제안하였습니다. DSM은 모델의 구조를 바꾸지 않고, 두 종류의 disturbance를 통해 anchor positive negative pair를 만들어 scene bias를 막고자한 방법론 입니다. 자세한 내용은 아래서 설명하도록 하겠습니다.
1.2 DSM – Spatial Local Disturbance
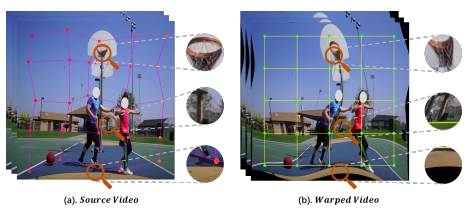
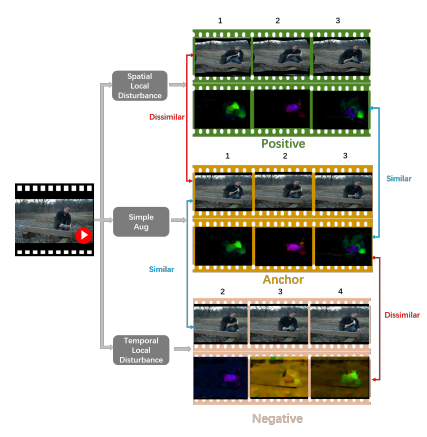
DSM을 구성하는 첫번째 disturbance는 Spatial Local Disturbance 입니다. 이 과정에서는 비디오 내 프레임 간의 motion semantic 한 정보는 유지하되, scene에 의한 local context 정보는 제거할 수 있는 positive 비디오를 생성합니다. 이러한 비디오를 생성하기 위해서는 프레임 내의 spatial한 영역에 변환이 필요하되, 매 프레임 마다 동일한 변환을 취해 temporal context를 유지할 수 있어야합니다. 이것을 목적으로 본 논문에서는 OCR 분야에서 text region을 retify하기 위해 사용된 Thin-Plate-Spline(TPS)를 도입하였습니다. 한 프레임 내에서 N개의 source point를 선정하고, 여기에 x축과 y축으로 랜덤하게 offset을 주어 destination point를 생성합니다. 그리고 각 source point와 destination point를 TPS의 입력으로 Fig 3과 같이 warping 시킵니다. 변환된 것을 보았을 때, 프레임 내 local한 영역 마다 변환이 이루어져 local context가 깨진 것을 확인할 수 있습니다. 그러나 매 프레임 마다 동일한 변환을 적용하기 때문에 motion context는 유지 되게 됩니다.
1.3 DSM – Temporal Local Disturbance
Positive를 구성하기 위해 적용되었던 Spatial Local Disturbance와는 달리, Temporal local Disturbance는 Negative를 생성하기 위해 anchor에 적용되는 방식입니다. 해당 방법론은 모델이 좀더 motion에 집중하도록 하는 것이 목적이기 때문에, anchor와 Negative가 다른 점은 motion pattern이어야하며 anchor로부터 다른 motion pattern을 만들기 위해 두 가지 과정을 거칩니다.
먼저 첫번째로 Optical-flow Scaling 과정을 거칩니다. 해당 과정에서는 우선 한 비디오 내에서 optical flow를 추출합니다. 그리고 optical flow 각각에 랜덤한 크기의 scale factor를 더해주는 간단한 과정으로 구성됩니다. 여기서 Optical flow가 의미하는 바가 얼마나 움직였는지라면, 여기에 scale factor를 더해줌으로써 움직인 정도를 바꿔주는 역할을 하게 됩니다.
그리고 두번째로 Temporal Shift 과정을 거치게 됩니다. 해당 과정에서는 한 비디오 내의 clip을 선택할 때 anchor가 뽑힌 인덱스로부터 일정 스텝만큼 shift된 위치에서 clip을 선택하게 됩니다. 이 과정 또한 간단하지만, 주로 비디오 내의 다른 위치는 다른 motion을 나타내기에 서로 다른 motion pattern을 얻을 수 있습니다.
1.4 DSM – Objective Function
해당 방법론은 기존 방법론에 더해져 사용되는 방식이기 때문에, 주로 Self-supervised learning 방법론들이 사용하는 Contrastive Learning Loss term과 제안된 Intra-video Triplet Learning Loss term으로 학습됩니다. Contrastive Learning Loss term은 많이 사용하는 InfoNCE 를 사용합니다. 해당 Loss term은 이전에 많이 소개드린 적있으니 설명은 건너뛰도록하겠습니다. 그리고 Intra-video Triplet Learning Loss term의 경우는 기존 자주 보았던 triplet margin loss의 형태를 띄게됩니다. 여기에 들어가는 positive는 앞선 Spatial Local Disturbance로부터 생성된 것이며, negative는 Temporal Local Disturbance로부터 생성된 것입니다. 이 두가지 Loss term이 결합된 형태로 학습을 하게 됩니다.
2. Experiments
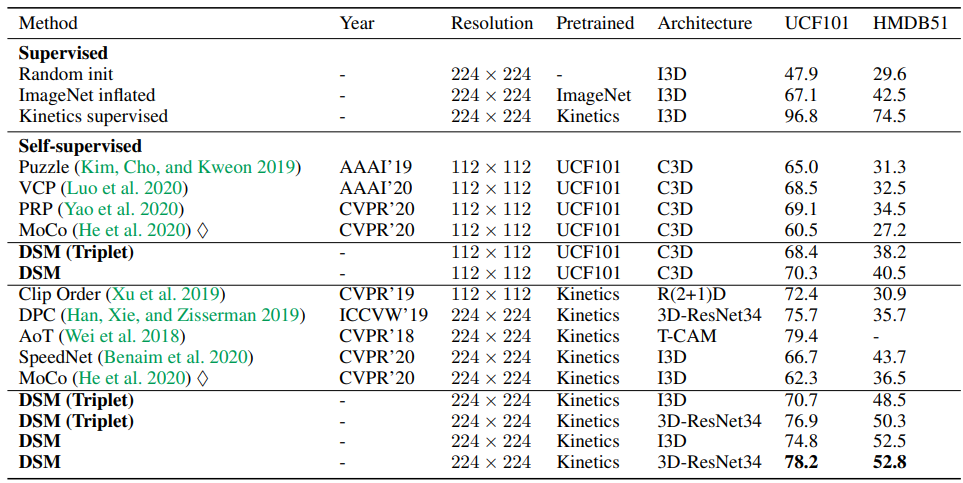
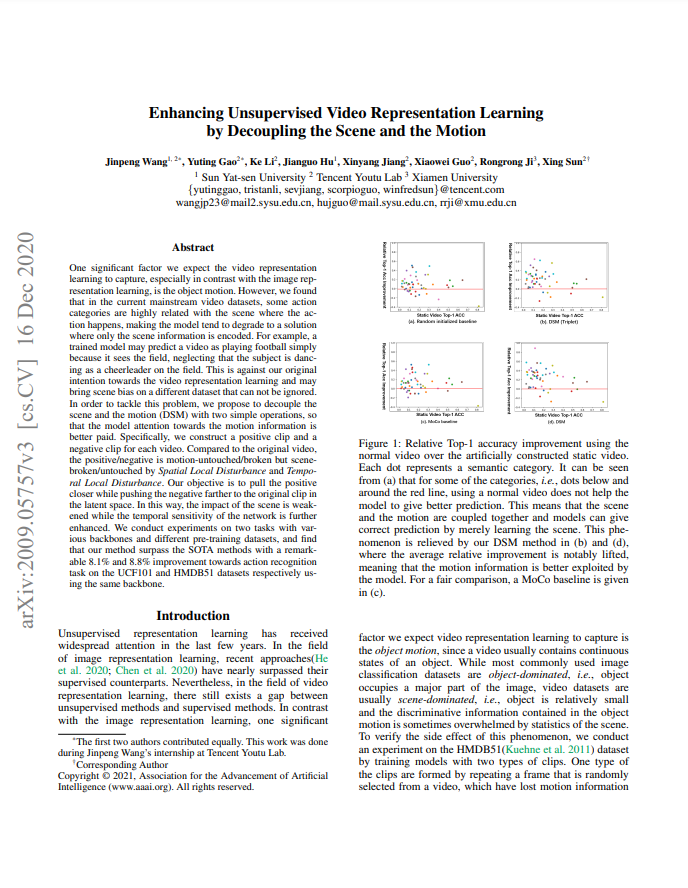
Table 1은 UCF101과 HMDB51에서의 self-supervised action recognition 성능입니다. (Triplet)이 써있는 경우 triplet loss로 학습된 것을 의미하며 DSM의 base network로는 MoCo가 사용되었습니다. 해당 방법론을 사용할 경우 기존 MoCo에서는 62.3의 정확도를 나타냈던 것과 달리, 최대 78.2까지 성능향상을 보이게 되었습니다.
Temporal Shift 과정에서 얼마만큼의 간격을 두고 sampling하는 지는 랜덤인가요? 아니면 고정인가요?
이게 데이터 셋마다 다른데, UCF101의 경우 [2,20]에서 랜덤, Kinetics400에서는 [4,30]에서 랜덤으로 설정하였다고 하네요
모션 정보에 집중하기 위해서, 모션 정보에 해당하는 영역의 시각정보는 와핑된 결과와 overview를 보면 너무 깨지는 것 같은데… 이러면 너무 모션 정보만 보게 되도록 학습하지 않나 생각이 듭니다. 궁극적으로 모션 정보만을 증가시키는 방향으로 학습이 되나요? 아니면 시각정보는 조금 손실이 되는 편인가요?
Spatial Local Disturbance과정을 통해 warped video를 만들어 원본 비디오와 positive 비디오를 만드는 과정은 scene bias한 문제를 해결할 수 있으나 모션정보에도 큰 변화를 주어 부정확한 모션 정보를 학습하게 되지는 않는 지 궁금합니다.
리뷰 잘 읽었습니다!
‘현재 image representation learning에서 self-supervised learning 기반 방법론들은 supervised learning 기반 방법론들의 성능을 우회하고 있습니다. ‘라는 표현에 대한 뜻이 궁금하여 질문 남깁니다.
– supervised 보다, self-supervised 의 성능이 좋지 못하다는 것을 우회한다고 표현한 것인가요? 우회한다는 것은 항상 성능이 더 떨어진다는 뜻이 있는건지 궁금합니다.
또한 ‘많은 video 데이터 셋들은 scene-dominated 하다’라는 것의 근거도 궁금합니다. 사람이나 물체 등을 중심으로 하는 데이터셋이 많다고 생각하고, ‘scene-based dataset’ 같은 건 본 적이 아직 없는데, 해당 논문에서 이에 대한 비교는 어떤식으로 한건가요?
우회 -> 상회, 오타가 났네요. 더 높은 성능을 내고 있다는 뜻 입니다.
그리고 아래 논문에서 비디오 데이터 셋 별 scene bias한 정도를 측정하였습니다. 아래를 참고해주시면 될 것 같습니다.
[ECCV2018] RESOUND Towards Action Recognition without Representation Bias