이번에 소개드릴 논문은 역시나 Self-supervised monocular depth estimation 관련 논문입니다. 최근까지 나온 논문들을 뿌셔보자 주의로 가장 최근 열린 3DV의 논문을 탐구하고 있습니다.
이 논문은 self-supervised monocular depth estimation를 학습할때 가장 큰 문제중 하나로 뽑히는 moving object를 제거하는 방식에 관한 논문입니다. monodepth2에서 moving-object를 없애기 위해서 auto-masking을 제안한 이후 정말 다양 방식에 제안되었고, 그 중에는 segmentation 정보를 활용해 object를 제거하는 방식들 또한 많이 제안되었습니다. 하지만 그러한 방식은 label 이 필요했으며 이건 GT를 구하는데 매우 큰 어려움이 존재합니다. 이와 같은 문제를 해결하기 위한 decomposition mask 방식을 제안하며 이 decomposition mask를 이용해 아래 그림 속 bottom 과 같이 moving-object에 대한 예측 성능을 향상 시킵니다.

contribution 을 정리하면 다음과 같습니다.:
- self-supervised depth estimation 에 decomposition 예측하는 framework 제안
- 보다 정확한 깊이 추정을 위해 독립적으로 움직이는 각각의 물체의 움직임을 추정
- DDAD와 KITTI에서 성능향상을 확인
Decomposition
decomposition을 사용하는 이유는 영상 속에서 의미있는 물체 부분을 파악하고 mask 씌우기 위함이며, 이것과 관련된 기존 논문들이 없다는게 살짝 아쉬운 부분이지만, 관련 논문이 정말 아예 없다면 deep learning에 이 방식을 적용한 것이 처음이라 굉장히 대단한 논문이라는 생각이 듭니다만 찾아보니 Depth 쪽에 아직 없던 것이지 다른 곳에서는 사용하고 있는 것 같습니다. 이러한 논문들을 related work에 설명할 법한데 하나도 없는게 아쉽네요.
- METHOD
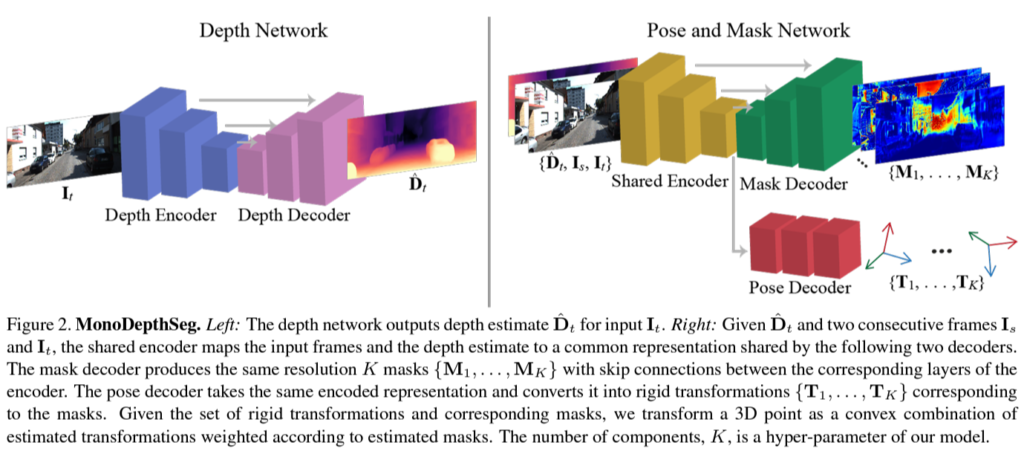
그림 1 속에 이 논문에서 가장 중요한 decomposition map을 뽑는 모델이 표현되어 있습니다. 인접 프레임들간에 pose를 구하는 posenet과 encoder를 share 하는 형식을 취하고 있습니다. 또한 pose network와 decomposition network은 share network를 통해 각각 K의 output을 갖습니다. 이러한 output는 기존에 posenet을 통해 하나의 pose만을 예측하는 것과 다른 것을 볼 수 있습니다.
이렇게 pose를 분리한 이유는 scene 속에서 움직이는 물체는 다른 pose를 가질 것이며 그에 따라 영상 속 다른 pose 를 가질 것 같은 pixel을 예측한 후 각각 다른 pose 값을 적용해주기 위해서 K개의 decomposition mask와 pose를 구하는 것입니다.
Scene Decomposition
Decomposition을 사용한 이유는 위에서 설명한 것과 같이 각 픽셀 별로 다른 pose를 가질 수 있으며 그것을 예측해야 정확한 image wraping이 가능하기 때문입니다. 각 픽셀별로 다른 pose 값을 예측하기 위해서 그림 1과 같이 K 개의 pose와 mask를 예측합니다. 그리고 이 마스크는 아래 식과 같이 각 요소를 더했을 때 1이 되는 확률 값으로 예측되며 이는 각 weight를 더헀을때 1이 되도록 설계됐습니다.
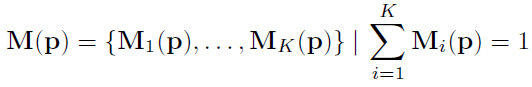
그리고 각 mask에 대한 정의는 [1] 이 논문에서 정의된 것을 사용한 것 같습니다. 이러한 정의는 mask에 순서를 매기기 위한 것으로 깊이에 따라서 mask가 정의 됐으면 하는 것 같습니다. mask 간의 순서를 매기며 다 합쳤을때 1이 되도록 하기 위해서 이 논문에서는 아래 식과 같이 각 마스크를 정의 했습니다.
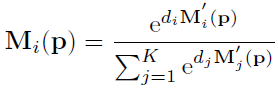
Pose Estimation
기존과 다른 방식으로 pose를 구하기 때문에 image wrapping 하는 방식 또한 기존 방식과 달라집니다. 기존에는 아래 식과 같은 방식으로 target image의 픽셀을 3D 공간 상으로 옳긴 다음
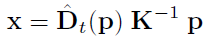
예측한 Pose 정보를 이용해 3D 공간상에서 옳긴다음 source image의 intrinsic paramter를 이용해 2D 공간상으로 내립니다.
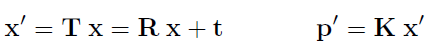
기존 방식은 위와 같고 이 논문은 pose를 pixel 별로 총 K개 예측하므로 다른 방식으로 해야합니다.
그방식을 아래 식과 같습니다.
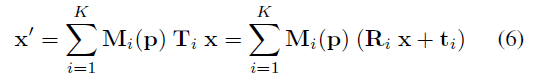
위 식을 보면 K 개 예측한 값들을 전부 사용하며 Mask 값을 곱해줘서 pose 마다 가중치를 다르게 사용합니다.
사실 왜 모든 가중치가 합쳐지는 방식을 사용했는지는 의문이 많지만 이곳에서 말한 걸로는 미분가능하게 하며 모든 K개의 요소가 영향을 줄 수 있도록 설계했다고 합니다.
Results
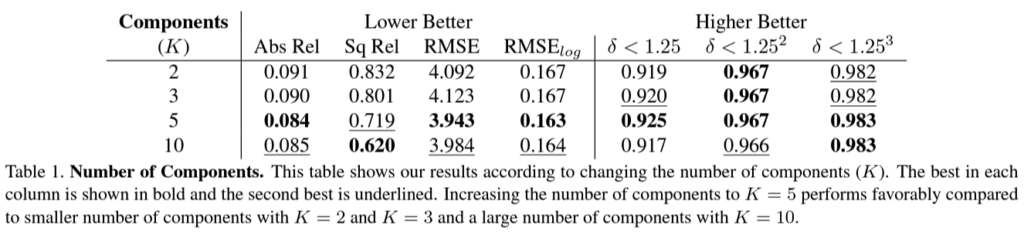
이 표의 성능을 보고 KITTI 성능이 왤케 높나 생각하고 봤는데 KITTI를 따로 validation을 구성하고 ablation study를 한 것 같습니다.
위 실험은 K값에 따른 성능 변화인데요. K 값이 적당해야 성능 향상에 이점이 있는 것 같습니다. K가 1일때 도 리포팅해줬으면 좋을 것 같은데 아쉬운 부분 같습니다.

다음으로 K 값을 구할때 depth 순서를 명시하는 depth ordering의 여부에 따른 성능 차이입니다. 이건 확실하게 성능 향상에 관여하는 걸 볼 수 있습니다.
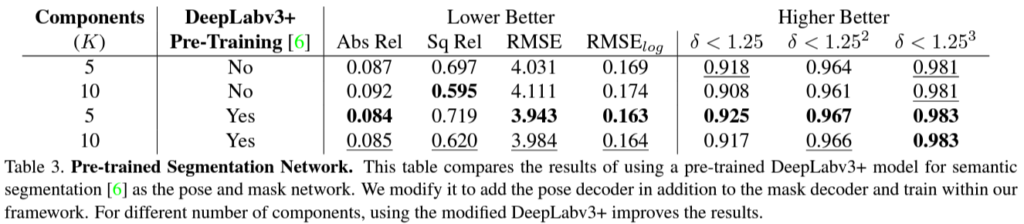
다음으로 decomposition map을 구하는 decoder 부분을 pretrained 모델을 사용하고 안하고 차이를 나타냈습니다. pretrain은 세그먼트 데이터 셋에서 했다고합니다.
pretrain을 해야 성능이 나오는 게 오히려 단점이 아닌가 생각이 드는데, 그래도 성능 부스팅을 위한 방법으로 발견을 한것이니 괜찮은 실험인 것 같습니다.
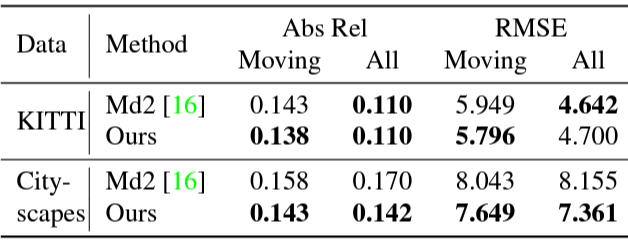
KITTI와 CITyscape 데이터 셋 에서 moving object가 있는 hard한 장면에서 성능 평가 결과와 일반적인 상황에서 결과 입니다. 이 논문이 moving object에서 장점이 있는 것이기 때문에 더욱 중요한 결과로 보입니다.
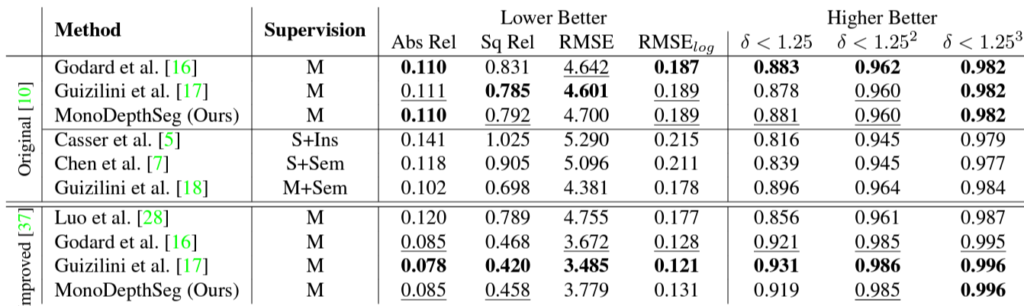
다른 방법론들과음 비교 또한 했는데 , 비교군이 너무 없는 것 같네요. 왜 DDV와 같은 방법론을 포함 안시켰는지가 의문 입니다. 그리고 moving object 에서는 성능 향상이 있었는데 전체 데이터로 봤을떄 성능 차이가 크게 줄어들지 않는 것을 보면 다른 씬에서는 오히려 성능 드랍이 있는 것으로 보입니다.

정성적 결과 입니다. 확실히 object에 대한 예측이 조금 더 나아진 것을 볼 수 있으며, 마지막 column의 decomposition map을 봤을때 object에 따라서 색깔이 다른 것으로 보아 원하는 방향대로 decomposition이 작동한 것을 알 수 있습니다.
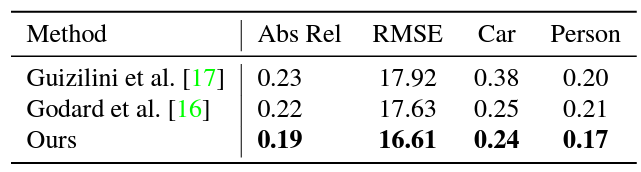
DDAD 에서 성능 평가 결과입니다. 사실 DDAD 데이터 셋에서 PackNet이 성능을 높게 안잡아 놔서 가뿐히 이긴걸로 보닙니다.
아이디어는 매우 참신하며 신기했지만 성능이 살짝 아쉬웠던 논문 같습니다.
References
[1] Shape Reconstruction using Differentiable Projections and Deep Priors
리뷰 잘 봤습니다.
한가지 궁금한 점이, 일정 영역별로 다른 pose를 적용해준다는 점은 이해를 하였는데, 이것이 결국 네트워크가 학습을 통해 알아서 특정 영역에 대한 pose 값과 mask를 구한다는 것인가요?
그렇다면 instance segmentation과 같은 느낌으로 동작한다고 이해하면 될까요?
넵 이해하신게 맞습니다.
물체의 pose는 몇자유도로 간주하고 처리하나요? 물체가 항상 땅에 붙어있다는 가정이 있으면 rotation이 1방향밖에 없지 않을까요? 경사가 있는 경우까지 고려하면 달라질 수도 있을거 같긴하네요.
제가 자유도에 대한 개념이 가물가물해서 정확하지는 않지만, 물체의 pose가 아니라 camera의 pose를 계산하는거라 자유도가 다 풀어져있을 거라 생각합니다.