Backgoround
이번 논문은 실내 기반 3D object detection 논문입니다. 이전 논문 리뷰로 실외(e.g. KITTI)에서의 3D object detection을 소개 드린 적이 있습니다. 아시는 연구원분들은 아시겠지만, 실내와 실외 환경에서의 3차원 공간을 다루는 문제는 서로 꽤나 큰 간극이 있습니다. 특히, 3차원 정보를 입력으로 사용하는 3D object detection인 경우에는 실내/외 특성으로 인해 사용하는 센서의 차이로 간극이 더욱 커집니다.
실외 환경에서는 실내 환경보다 넓은 환경과 물체간 거리가 멀리 떨어져 있기에 실측 거리가 긴 LiDAR를 이용하여 3차원 위치를 인지합니다. 하지만 LiDAR의 특성 상, 밀집도가 떨어지고 빛을 흡수하는 물체(e.g. 검은색 물체), 빛을 반사하는 물체(e.g. 거울)에서는 정확한 측정이 어렵다는 문제가 있습니다.
반면 실내 환경에서는 실외에 비해 작은 환경과 물체간 거리가 작기 때문에 실측 거리가 짧은 RGBD 센서를 이용합니다. RGBD 센서는 realsense, kinetic 등이 있으며, 패시브 형식의 적외선 센서로 3차원 위치를 인지하고 스테레오 카메라를 이용한 깊이 추정으로 보완하는 방법을 이용합니다. (혹은 김지원 연구원이 빌려온 solid 방식의 LiDAR를 이용한 RGBD 센서도 있습니다.) 이러한 특징으로 RGBD 센서는 영상 해상도와 비슷한 깊이 정보의 밀집도를 가집니다. 하지만 LiDAR에 비해 FoV가 작고, 실측 거리가 1~3.5m로 먼 거리에 위치한 위치 정보들을 습득하기에 부적절하다는 단점이 있습니다.
LiDAR와 RGBD 센서는 상이한 깊이 측정 방법으로 환경에 따라 선택되어져 사용되어져 왔습니다. 그렇기에 실내/외 환경에서의 3D object detection 또한 주로 집중하는 문제도 달라집니다. 우선 LiDAR를 이용하는 3D object detection에서 주로 LiDAR의 sparse한 특징과 먼거리의 물체의 구분력을 기르는 연구들이 주로 이루고 있습니다. RGBD를 이용하는 3D object detection에서는 물체를 구성하는 표면 정보들을 해당하는 물체에 어떻게하면 잘 샘플링하여 군집 시킬지에 대한 연구들이 주를 이루고 있습니다.
앞서 이야기 드린 바와 같이 이번 리뷰는 실내 기반의 3D object detection으로 포인트 클라우드가 풍부한 상황에서 물체 검출을 수행합니다. 이러한 특성 상, 수많은 포인트 클라우드 정보를 직접 모델의 입력으로 사용하면 높은 계산량과 느린 연산 속도이 발생한다는 문제가 있습니다. 이로 인해 실시간이 보장 되야 하는 태스크나 모바일 플랫폼에 탑재되기에는 부적절한 면이 있습니다. 해당 논문에서는 이러한 문제를 해소하는 방법을 제시하며, 적은 연산량과 빠른 연산 속도를 가질 뿐만이 아니라 성능도 SOTA를 달성한 결과를 보여줍니다.
Intro
앞선 글에서 RGBD 센서를 이용한 실내 기반 3D 물체 검출에 대한 전반적인 틀에서 어떠한 특성이 있는지 다뤘습니다. 그럼 세부적인 관점에서 실내 기반 3D 물체 검출들은 어떤 연구들이 진행되고 있을까요? 이 또한 앞서서 이야기한 바와 같이 풍부한 포인트 클라우드로부터 물체의 표면을 잘 샘플링하여 해당 물체에 정확하게 군집되도록 하여 구분하는 연구가 진행되어진다고 했습니다. 그렇기에 이전 연구에서는 수많은 포인트 클라우드로부터 물체 표면을 샘플링하기 위해 RGB의 영상으로부터 물체의 segmentation 혹은 2D detection을 수행하여 영상 레벨에서의 물체의 위치를 파악한 후, 해당 위치의 포인트 클라우드 샘플링하여 물체의 위치와 클래스 구분 짓는 방법을 사용하거나, PointNet과 같은 물체 관점에서 의미있는 포인트 클라우드를 샘플링하여 3차원 위치 xyz + 특징값 C를 추출하는 포인트 클라우드 기반의 특징 추출기를 이용하여 포인트 클라우드로부터 직접적으로 정보를 추출하는 방법을 사용하기도 합니다. 즉, 3차원 정보를 샘플링 하기 위해 영상 기반의 물체 검출을 추가로 수행하거나 포인트 클라우드를 직접 연산에 사용한다는 단점이 있으며, SOTA를 달성했더라도 ~10FPS의 느린 속도를 보이기에 실시간 성이 보장되야하는 모바일 플랫폼에서 탑재되기에는 어려움이 있습니다.
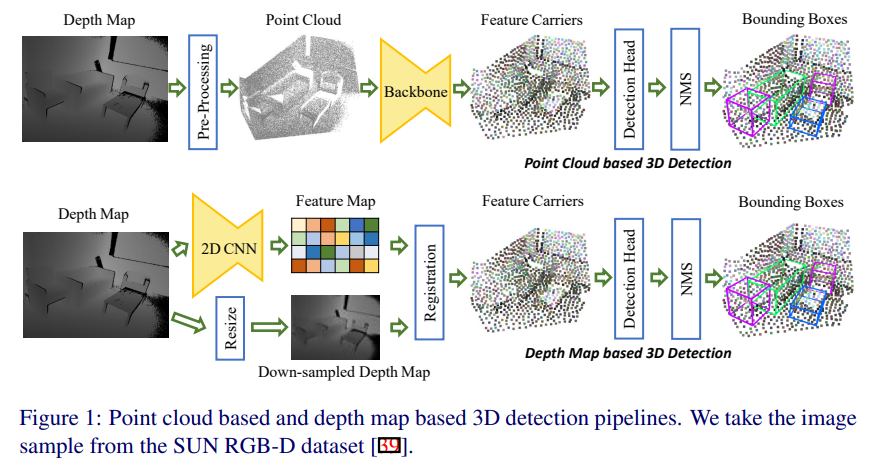
저자는 이러한 한계를 극복하기 위해 Fig 1의 아래에 위치한 파이프라인과 같이 포인트 클라우드를 샘플링에 있어 depth map을 사용할 것을 제안합니다. 간략하게 파이프라인에 대해 설명하자면 3차원 정보를 가진 depth map에서 기존 CNN에 저자가 제안하는 Relative Depth Convolution(RDConv)를 추가하여 기하학적인 관점에서도 고려된 물체의 위치를 샘플링이 가능한 feature map을 생성하여, 이를 feature map 크기에 맞춰 resize된 depth map을 이용하여 포인트 클라우드를 생성합니다. 이를 통해 유의미한 포인트만 남게되며, 이를 이용하여 3D 물체 검출을 수행합니다. 이를 통해 효율적인 연산과 빠른 추론 속도를 얻을 수 있게 됩니다. 보다 자세한 내용은 아래 섹션에서 자세히 다루도록 하겠습니다.
++RGBD 센서는 raw한 출력 값으로 Depth map을 출력하며, 이를 실제 세계의 3차원 정보를 가진 포인트 클라우드를 추출하기 위해 외부 카메라 파라미터로 추가적인 연산을 수행하여 획득합니다.
Method
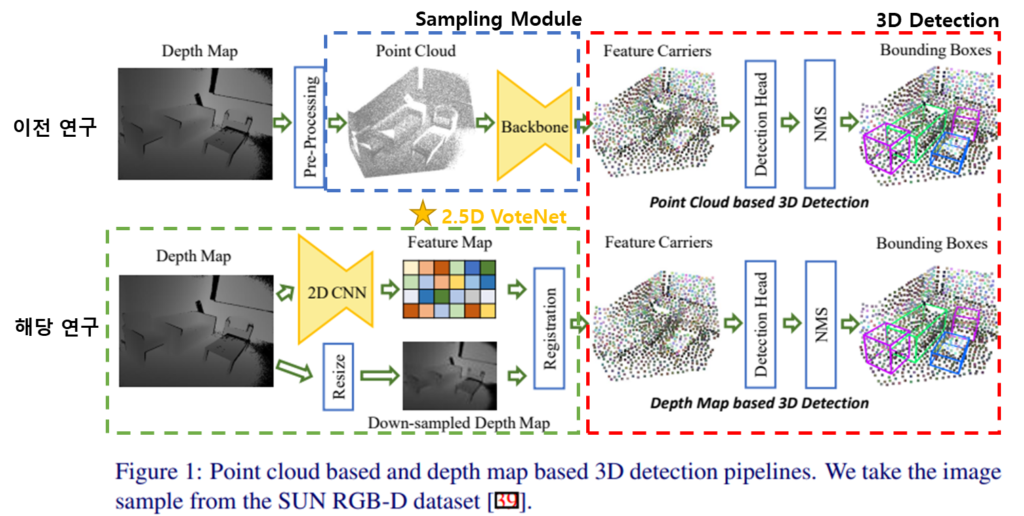
서론이 길었지만 사실 저자가 제안한 방법론은 매우 간단합니다. 위의 그림에서 초록색 점선 박스가 저자가 제안하는 방법론에 해당합니다. 즉, 기존 연구와 포인트 샘플링하는 방법을 제안한 것인데요. 샘플링 후, 빨간색 점선 박스에 해당하는 3D Detection에서는 기존의 방법론 중 VoteNet을 그대로 사용합니다.
방법론의 이름인 2.5D VoteNet의 어원도 여기서 이해할 수 있습니다. VoteNet을 그대로 사용했으며, 샘플링에 사용된 입력값은 3차원 포인트 클라우드가 아닌 3차원 정보를 2차원 형태에 담겨진 depth map을 이용했기에 2.5D를 명칭을 사용했다고 합니다.
자.. 그럼 파이프 라인에 대해 설명드리겠습니다.
1-(a). Depth map을 U-Net 구조의 2D-CNN에 태워 low-resolution을 가진 feature map을 생성합니다. (+ 옵션으로 RGB feature 사용)
1-(b). Depth map을 low-resolution feature map와 동일한 크기로 resize 해줍니다.
2. low-resolution Depth map을 포인트 클라우드로 변형하며, 이에 대응되는 low-resolution feature map을 등록해줍니다.
3. 3D Detection(VoteNet)을 통해 3차원 물체 검출을 수행합니다..
++ VoteNet에 대해서는 다음 리뷰를 참고하시기 바랍니다.
매우 간단하죠?
U-Net 구조의 2D-CNN
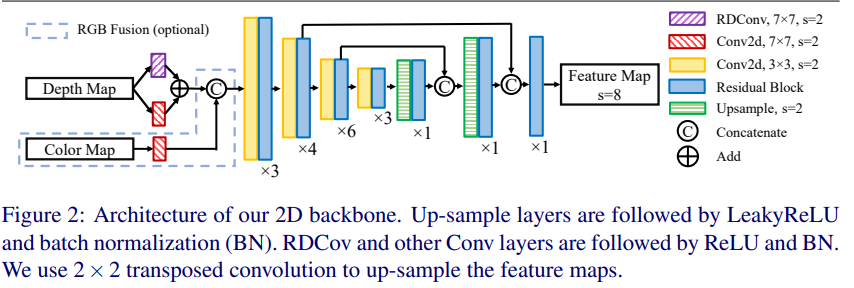
해당 구조도 매우 간단합니다. 아래에서 추가로 설명드릴 RDConv와 2d conv로부터 추론된 Depth map feature와, 2d conv로부터 추론된 Color feature의 concat된 feature는 ResNet 구조의 encoder에 태워져 2,3 stage와 동일한 크기의 upconv와 concat 되어져 1-(a)의 low-resolution feature map을 생성하게 됩니다.
여기에 저자는 depth map의 특성을 효율적으로 계산하기 위한 방법으로 RDConv을 제안합니다.
Relative Depth Convolution (RDConv)

RDConv는 위의 그림과 같이 3가지로 나눠 설명할 수 있습니다. 기존 2DConv와 동일하게 컨벌루션 연산을 수행하며는 weight w(), 측정이 불가능하거나 노이즈가 될 수 있는 depth 정보를 거르는 binary mask M() (depth map f()에 0을 임계값으로 설정한 이진 마스크), 마지막으로 상대적인 깊이 정보를 측정하는 relative depth 모듈로 구성되어집니다.
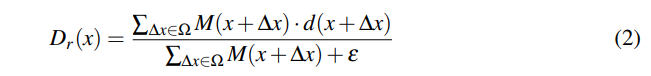
relative depth 모듈은 수식 2가 있어야 완성이 됩니다. 수식에 대해 풀어 설명하자면 오프셋~커널 관점에서 정규화를 수행하겠다는 이야기입니다. 정규화를 통해 상대적인 깊이 정보를 취하는 이유는 실질적으로 모델에게 유의미한 정보는 절대적인 좌표보다는 물체의 엣지와 코너등 특징정인 요소들에 있습니다. 그렇기에 절대적인 깊이 정보는 오히려 노이즈가 될 수 있기에 상대적인 좌표로 변화하는 연산을 수행합니다. 이를 통해 depth map의 특징을 고려한 conv 연산을 설계함으로써, 하나의 레이어를 추가하는 것만으로도 의미있는 feature를 구성할 수 있게 되었다고 합니다.
이에 대한 증거로 아래의 fig 3(supplementary)에서 볼 수 있듯이, RGB 영상 없이 deptph map만 입력으로 넣었음에도 물2번째 열에서 오브젝트에 높은 activation을 보이는 것을 볼 수 있습니다.

Experiments
실험에는 SUN RGBD와 ScanNet이 사용되어졌습니다.
++ ScanNet은 장소 단위로 평가하는 데이터 셋이기에 프레임 단위의 챌린지에 대해서는 정립된 구조가 없는 것으로 보입니다. 그렇기에 해당 저자는 베이스라인 모델인 VoteNet에서만 비교 평가를 수행 한 것으로 보입니다.
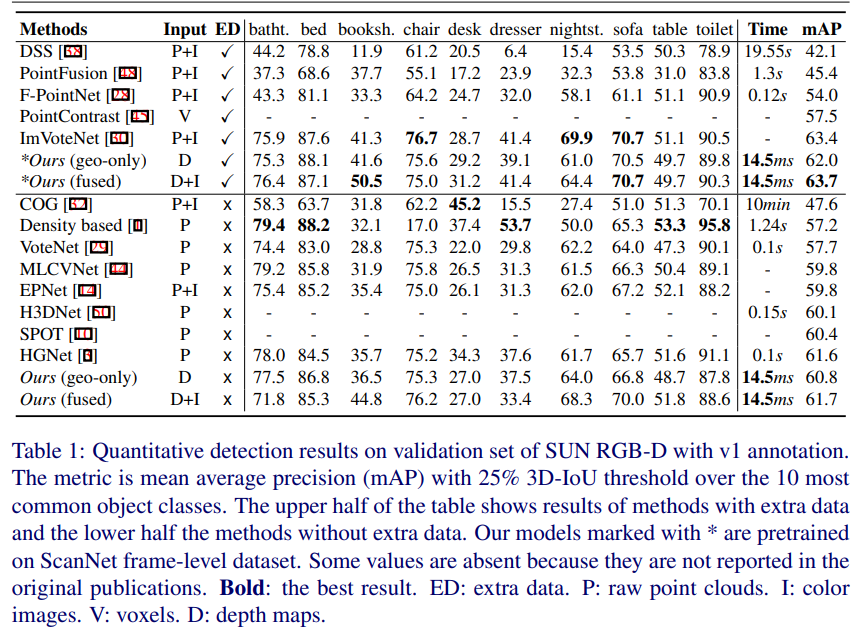
SUN RGBD에서의 정량적 평가 결과 입니다. SOTA 방법론들에 비해 높은 성능을 보여줌에도 불구하고 14.5ms라는 매우 빠른 추론 속도를 보여줍니다. 다른 방법론들이 0.1s을 보여주는 것에 비해 정말 빠른 속도입니다.
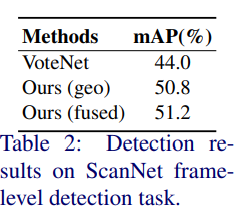
ScanNet에서의 정량적 결과이며, 베이스라인 모델인 VoteNet의 성능을 뛰어 넘은 것을 볼 수 있습니다.
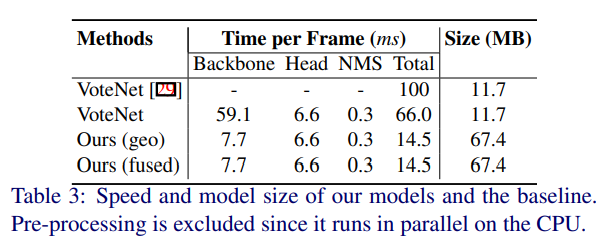
또한 제한한 백본 모델의 속도가 8~9배 이상 빠른 속도를 보여줍니다.

RGB와 Depth의 사용, fusion 여부, RDConv에 대한 ablation study를 진행한 결과 입니다.
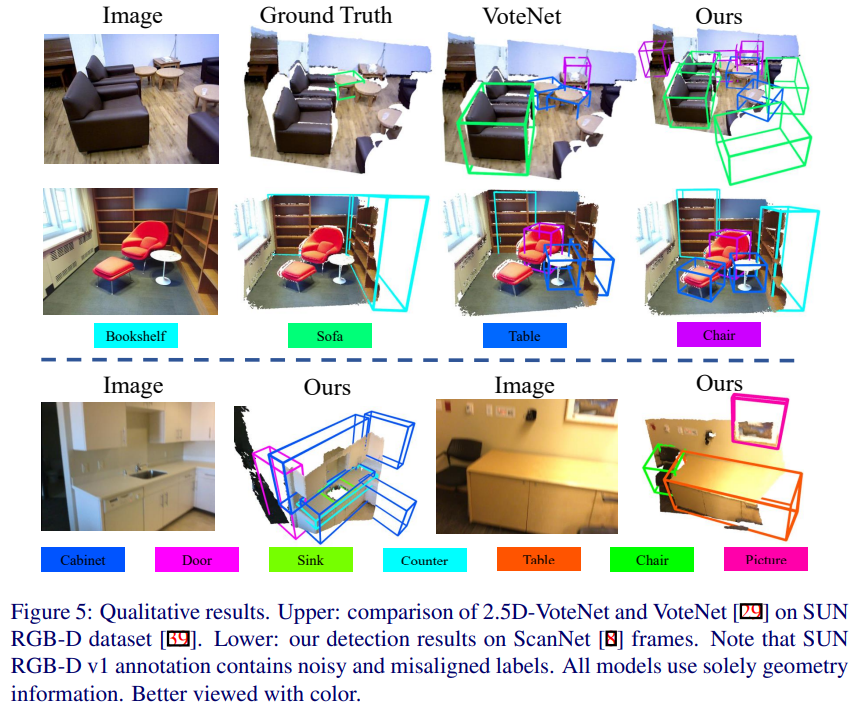
마지막으로 정량적 평가 결과이며, VoteNet과 공평한 비교를 위해 RGB 없이 추론한 결과라고 합니다.
+ fig 5. GT에 라벨이 없거나 잘못된 경우가 있다는 예시 라고 합니다. 근데 굳이 왜 이런 예시를 넣었는지는 납득이 안됩니다만… 감안하고 보시길 바랍니다.
===============================================================
해당 논문은 빠른 속도에도 불구하고 높은 성능을 보여준 방법론 입니다. 추후 해당 방법론이 트렌드로 구성 될 것이라고 예상하고 있어 주의 깊게 보고 있습니다.