안녕하세요. 지난번에 unsupervised video summarization에 이어서 이번에는 supervised video summarization 논문을 들고왔습니다.
Introduction
Video summarization에 대한 설명은 지난번 리뷰에 있으니 넘어가고, 이 논문에서 제안하는 “multiscale hierarchical attention method”에 대한 설명을 해봅시다.
왜 attention이 필요할까요? 사실 그 내막을 정확히 알기 위해서는 이 video summarization의 발전사를 알아야 하는데… 결론만 요약하면… video summarization을 효율적으로 하기 위해서는 좋은 representation을 가져야하는데, 그러기 위해서 많은 방법론들이 발전되어 왔고 transformer가 등장한 시점에서 temporal한 정보를 잘 보기 위해서 이런 방법론들이 사용되기 시작했다고 합니다. 물론 단순히 attention을 주게되면 발생하는 문제점들이 있고, 이 문제점들을 해결하기 위해 multiscale hierarchical이라는 구조가 붙게 되는 것이라고 생각하면 될 것 같습니다.
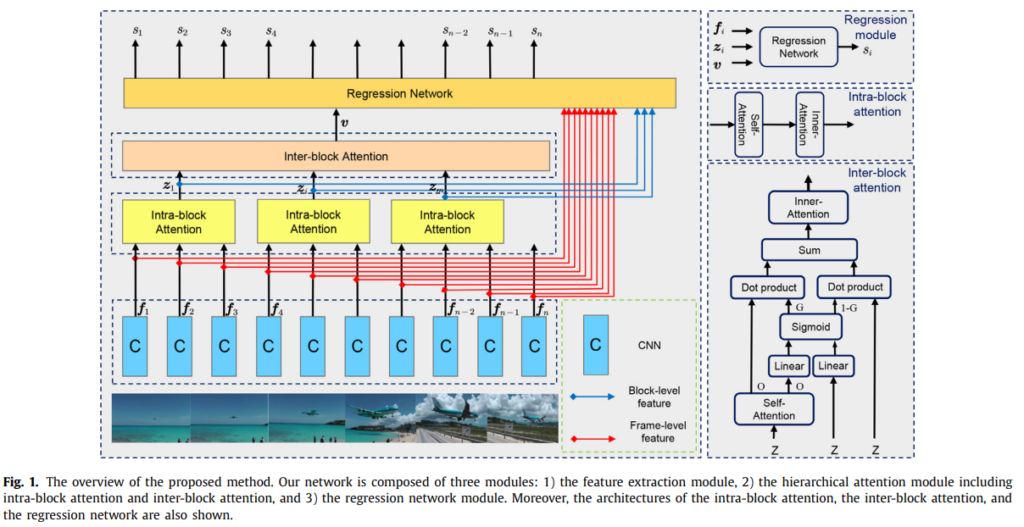
아무튼 그래서 제안된 이 방법론은 위의 그림과 같이 3개의 모듈(feature extraction module, hierarchical attention module, regression network module)로 구성되어 있습니다.
기본적으로 이 video summarization이 frame-level importance score를 예측해서 요약을 하기 때문에 이를 예측하는 것이 목표입니다. 이 논문에서는 “hierarchical attention module”을 바탕으로 multiscale feature를 뽑는 것에 상당한 공을 들였습니다.
Approach
일단 요약해야하는 video sequence X = [x_1, x_2 ... x_n]이 주어졌을 때, frame-level importance score y = [y_1, y_2...y_n]을 이용해서 요약을 수행하는 것이 목표입니다. 즉, 프레임마다 frame-level importance score가 라벨링 되어있고, 우리의 목표도 이 frame-level importance score를 예측하는 것이 목표입니다.
Overview
간단한 설명을 하고 시작을 하자면, Feature extracion module은 GoogLeNet을 백본으로 사용해서, frame 단위 feature를 추출합니다. 그런 다음에 이 feature를 고정된 길이 s를 가진 m개의 블록으로 분할합니다. 이렇게 하면 frame-level feature도 가지고 있지만, block-level feature도 가질 수 있습니다. (위의 그림을 보고 오시면 이해가 빠릅니다) Hierarchical attention module에서는 frame-level, block-level, video-level representation순으로 올라가면서 이 모듈을 통해 multiscale representation을 만드는 것이 목표입니다. 이를 위해 attention이라는 단어가 이름에 들어가 있듯이, attention 기법을 엄청 사용합니다. Regression network module에서는 최종 목표인 frame-level importance score를 예측하는 것입니다. 그럼 세부 설명으로 넘어가봅시다.
Hierarchical attention module
본격적으로 이 논문의 제일 많은 내용을 차지하는 모듈을 알아봅시다.
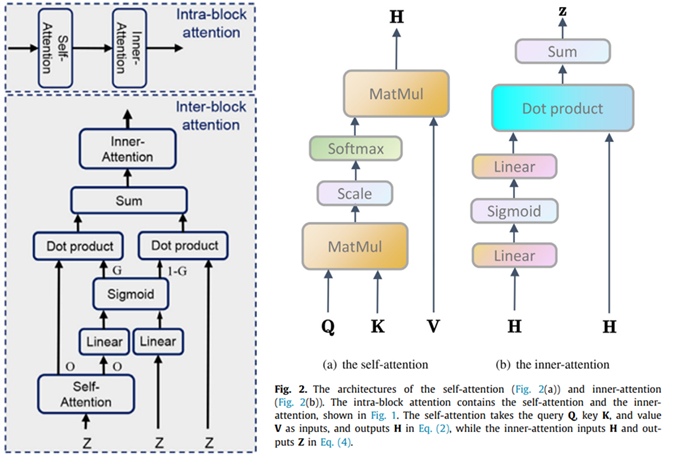
일단 이 그림을 잘 봅시다. 같은 attention으로 부르지만, Intra-block attention은 frame-level attention을 통해 block-level feature를 만들어내는 모듈이고, inter-block attention은 block-level attention을 통해 video-level feature를 만들어내는 모듈입니다. 그리고 그 attention 모듈 하위로 self-attention과 inner-attention 연산이 있습니다.
그럼 왜 frame-level attention과 block-level attention을 따로 주는가에 대한 궁금증이 생기겠죠? 비디오는 프레임으로 같은 사건으로 구성되어 있지만, 한편으로는 서로 다른 정보들을 구성하고 있는 요소라는 점에서 착안하여, video-level representation과 block-level representation을 학습할 수 있는 hierarchical attention module을 만들었다고 합니다. (프레임 자체의 정보도 있지만, 프레임들이 모인 블록에서는 temporal한 정보도 있고 video summarization에서는 이벤트를 요약하는 것이기 때문에 이러한 정보들이 중요하다는 것으로 생각됩니다.)
이런 구조라는 점에서 착안해서 frame-level, block-level, video-level representation의 multiscale representation을 사용한다고 설명드렸는데요. frame-level representation은 frame에서 feature를 뽑은걸로 끝이므로… 나머지 두개를 차례로 설명해봅시다.
3.3.1. Block-level representation
Intra-block attention이 frame-level attention이라고 위에 설명드렸는데, 이 모듈은 그림과 같이 self-attention과 inner-attention으로 구성됩니다.
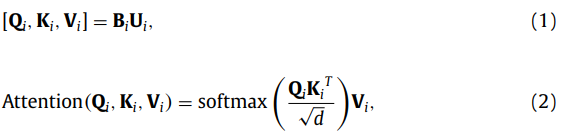
이러한 self-attention 수식을 바탕으로 나온 값이 H_i=[h_{x<em>i+1}, h_{x</em>i+2}...h_{x*i+s}]라고 합니다. (i는 블럭의 순번)
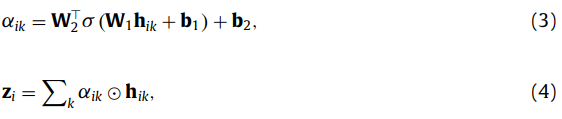
그럼 block-level representation z_i를 만들기 위해, inner-attention(3번 수식)을 거치고, 4번 수식과 같이 self-attention의 결과와 inner-attention의 결과를 dot 연산 해줘서 block-level representation을 만듭니다. 이렇게 개별적인 attention을 통해서 논문 저자가 주장한 대로 프레임과 블록의 서로 다른 정보를 잘 살리려고 노력한 것 같습니다.
3.3.2. Video-level representation
Inter-block attention이 여기서 쓰입니다. 모듈 그림을 보고오면 같은 block-level representation z에 대해 다양한 연산을 준 값과 주지 않은 값에 대한 dot product를 수행하는데요. 이 값들에 Adaptive gating mechanism이라고 부르는 방법론을 도입해서 모델의 information flow를 조절했다고 합니다. (Video-level representation을 만들때, block-level representation에 중요도가 낮더라도 video summarization에서는 temporal한 정보도 중요하기 때문에 이를 비교적 보존하면서 가져가기 위함으로 보입니다)

수식으로는 위와 같은데, G라는 gated matrix를 통해서 fused representation \hat{Z}를 만들어 냅니다.
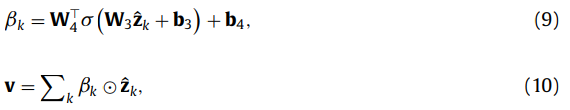
그런 다음 inner-attention을 적용해줘서, video-level representation을 얻습니다. 이렇게 단계적으로 representation을 얻어가서 최종적으로는 \hat{f_i} = [f_i, z_i, v]와 같이 3가지 feature가 concat되어진 multiscale representation을 얻을 수 있습니다.
사실 self-attention 연산, inner-attention 연산 모두 attention에 관심 있으신 분들은 다 보셨을 것이라고 생각합니다. 수식을 고치거나 한 부분은 없어서, 여기서 집중해서 볼 부분은 계층적으로 frame 부터, block을 거쳐 video까지 단계적으로 뽑은 freature를 사용한다에 집중하면 될 것 같습니다.
3.3.3. Frame-level importance score prediction
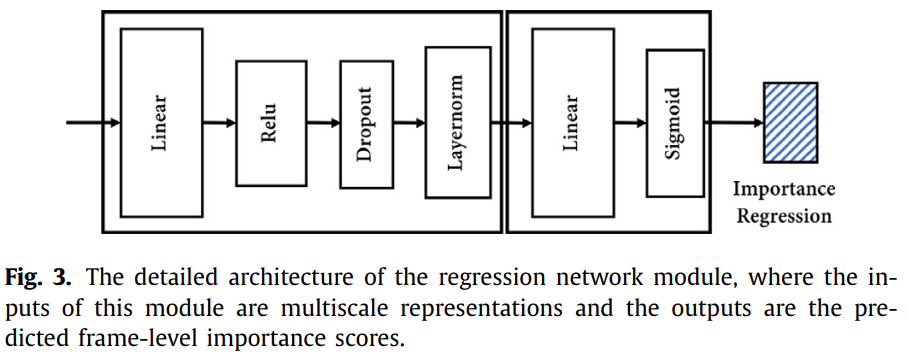
이 단계에서느 Regression network module을 이용해서 Frame-level importance score를 예측합니다. 모델 구조는 위 그림과 같은데요. 데이터셋에 frame-level importance score가 라벨링 되어 있기 때문에 이것을 바탕으로 학습한다고 하네요.
3.4. Key shot selection
자 그럼 frame-level importance score을 가지고 어떻게 key shot을 고르는지 알아봅시다. 전통적으로 video summarization에서 시각적인 정보들의 변화를 이용해서 scene 변화를 탐지할 때 사용하던, Kernel temporal segmentation을 이용해서 shot bounday detection을 탐지했다고 합니다. 이를 바탕으로 shot을 분할하고, 분할된 영역안에서 frame-level importance score를 평균을 취해서 shot-level importance score을 얻었다고 합니다.
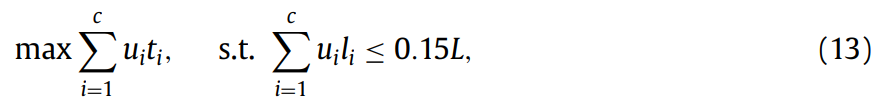
추가적으로 이 논문에서는 한가지 제약 조건이 더 있습니다. 위의 수식에서 u는 i번째 샷이 선택되었는지를 나타내는 binary 값이고, t는 shot-level importance score. 그리고 l은 shot의 길이를 뜻합니다. 그러니까 정리하면 요약된 비디오의 길이는 원본 비디오의 길이의 15%를 넘지 못하도록 하는 선에서 shot-level importance score는 최대가 되도록 하는 것입니다. 이는 본질적으로 이 문제가 NP-hard 문제라 알고리즘적으로 해결할 방법이 필요했다고 하는데… 이건 잘 모르겠습니다. 그래도 생각해보자면 shot-level importance score가 높으면 그만큼 요약 비디오의 퀄리티가 높아지면서도, 모든 shot의 importance score가 높아지도록 학습하면 요약의 의미가 없어지므로 설정한 조건 같습니다.
3.5. Extension to a two-stream framework
이건 최근 흐름에 따른 확장인데요. 비디오는 공간정보와 시간정보로 분해될 수 있다는 연구 흐름에 따라서 two-stream framework를 통해 시간 정보(모션 정보)를 보존해보려고 했다고 합니다. 마침 비디오 요약에서 모션 정보가 무시되는 경향이 있었다고 하네요.
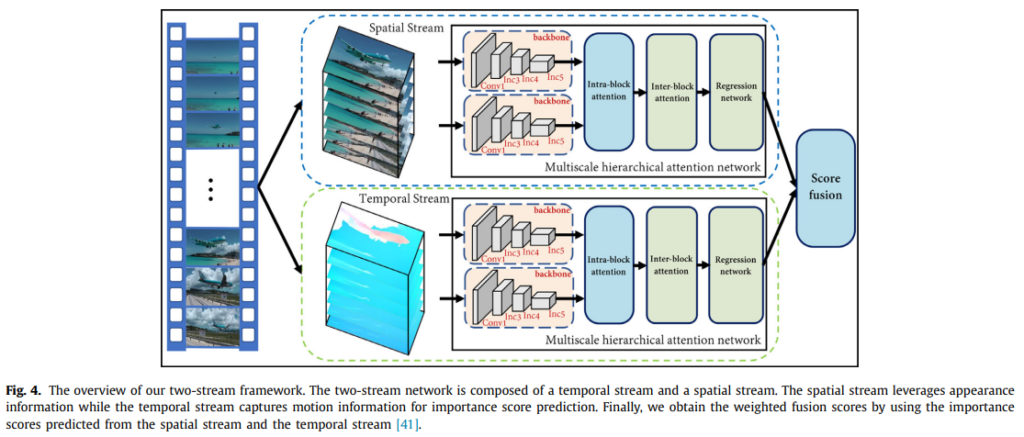
그래서 기존의 모델에 FlowNet을 이용하여 모션 정보를 보존한 two-stream framework을 구성했다고 합니다. 이렇게 되면 모델이 2배가 된 셈인데, 비디오 요약에서 기존에 사용하던 RNN 방법과는 달리 병렬처리가 가등하다는 점과 multi-scale representaion의 효율성 때문에 연산 문제는 없다고 합니다. 시간복잡도도 계산해서 증명해주는데… 리뷰에는 넘어가겠습니다.
4. Experiments
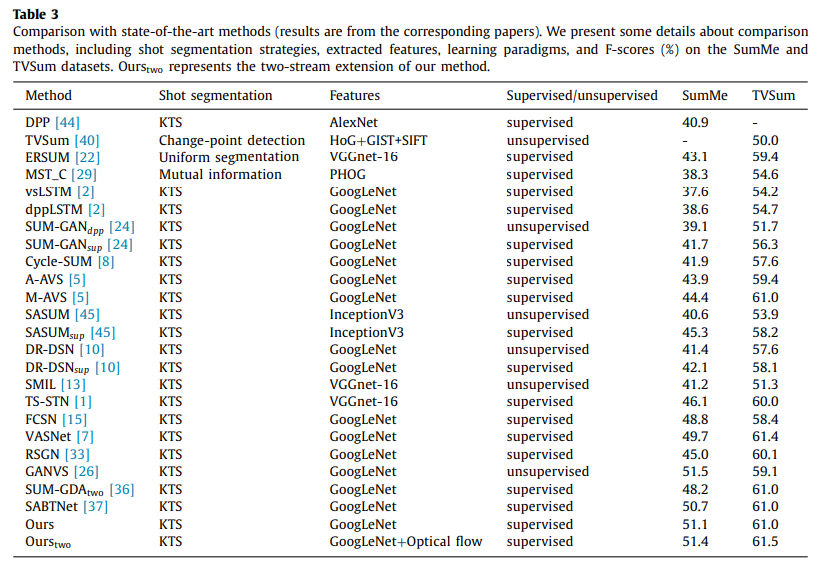
이전 논문에서 리뷰했던 unsupervised video summarization 방법론의 성능이 SumMe에서 47.5, TVSum에서 55.6이라는 점을 감안하면 전반적으로 성능이 높은 편에 속합니다. VASNet이 논문의 방법론보다 성능이 좋은 데이터셋이 있는데 이는 TVSum 데이터셋의 성능이 전반적으로 좋은 이유는 이 데이터셋에서 이벤트들이 비교적 긴 편에 속해서 이런 부분에서 손해를 봤다고 합니다. (이유가 명확하게 적혀있지는 않지만, 아마 15% 길이 제한 때문 같습니다.)
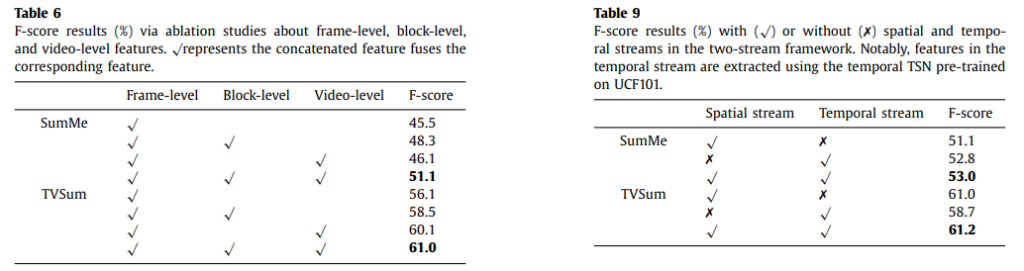
그리고 볼만한 ablation study를 하나 가져왔습니다. 왼쪽 표는 Multiscale representation에 따른 실험 결과인데요. Block-level이나 Video-level이 Frame-level representation과 결합되면서 성능이 오르는 것을 볼 수 잇습니다. 이건 논문 저자들이 생각한대로 frame-block-video level representation이 각각 담고있는 정보가 달라서 Multiscale representation이 성능이 좋다는 것을 보여줍니다.
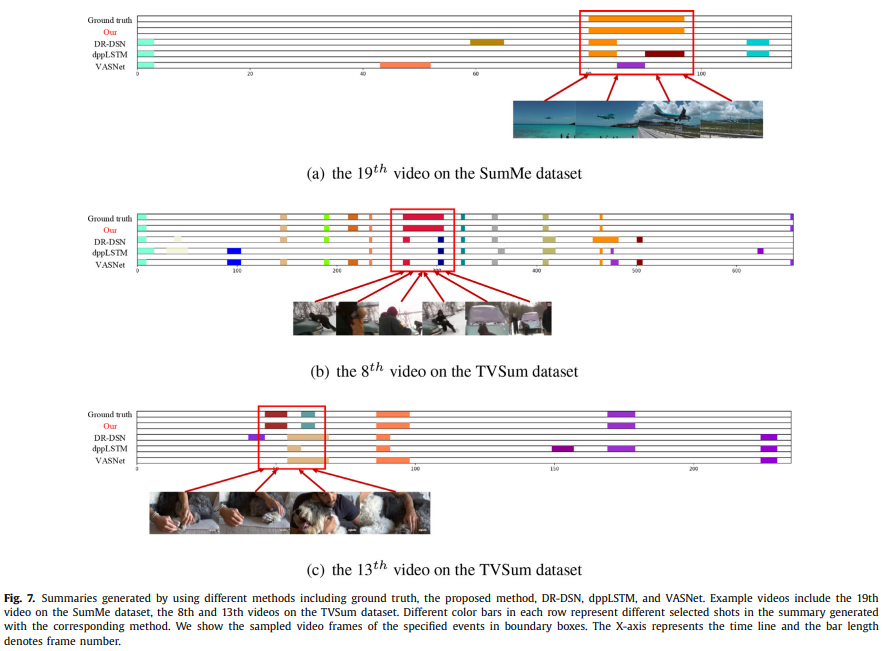
지난 video summarization논문에서는 정성적인 결과가 보기 어려웠는데 여기서는 보기 좋게 정리되어 있어 이해가 쉬웠습니다. 전반적으로 제안된 방법론이 GT와 유사하게 요약을 수행하는 것 처럼 보입니다.
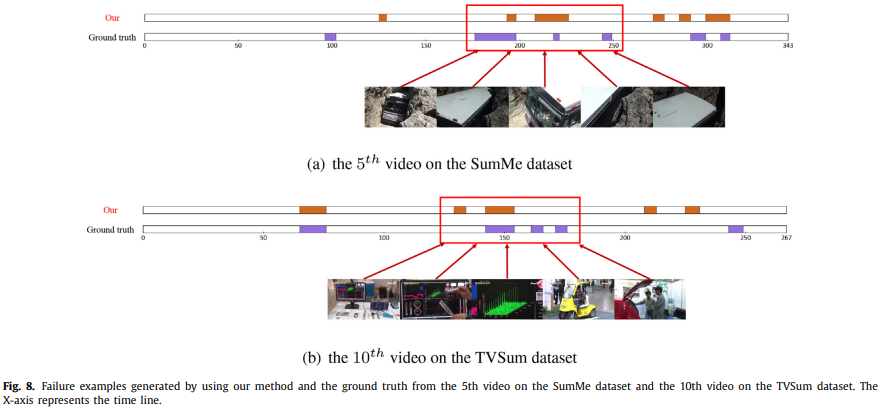
물론 이렇게 잘 못 잡는 경우도 생깁니다. 이런 경향이 생기는 이유는 결국은 데이터셋의 부족 때문으로 귀결되는 것 같습니다. (데이터셋이 25~50개의 비디오로 구성되어있을 정도로 크지 않음)
Conclusion
더 많은 실험이 있긴 한데, 중요해보이는 실험만 몇개 추려서 가져왔습니다. 관심 있으신 분들은 논문에 가셔서 확인해보면 좋을 것 같습니다. 사실 언뜻 논문을 처음 봤을때는 feature도 여러개 뽑고, attention도 엄청 많이 사용하길래 당연히 성능 좋은거 아니야? 라고 생각하면서 읽었는데 나름의 이유가 다 존재하고 연산량이나 속도 문제를 해결하기 위한 고민과 해결책도 있어서 좋았던 것 같습니다. 전반적으로 attention mechanism에 평소에 관심이 있었던 사람들은 엄청 쉽게 읽었을 것 같은데 저는 생소한 용어가 많아서 어려웠지만 좋은 논문이었던 것 같습니다.
기존의 방법론이 아닌, 해당 방법론에서 각각의 feature를 여러 조합으로 사용해 보고 세가지를 다 활용했을 때 좋은 성능임을 보인 것인지 궁금합니다.
또한 해당 논문에서 multiscale을 고려하는 방식이라 하였는 데, 비디오에서 multiscale이라는 표현이 일반적으로 video-frame-block과 같은 관계를 의미하는 지 궁금합니다.
Ablation study를 제가 첨부해두었는데, 그 부분을 확인해보시면 feature 조합에 따른 성능은 확인해보실 수 있습니다. Multiscale이 비디오에서 일반적으로 지칭하냐는 질문은 안타깝게도 저도 이런 표현을 이 논문에서 처음 봤기 때문에 일반적인지는 잘 모르겠습니다.
video summarization 쪽에서는 주로 평가를 할 때 F-score를 쓰는 것 같아 보이는데, 이를 구하기 위한 GT는 어떤 식으로 구성되나요? 사람마다 선호하는 요약 방식의 차이가 있듯이, GT를 선정하는 기준에도 주관적인 의견이 반영되나요? 혹은 다른 절대적인 기준이 따로 존재하나요
여기서 사용하는 데이터셋의 GT를 어떻게 만들었는지를 보면 다수의 라벨러들이 수행한 결과를 바탕으로 만들었다고 되어있습니다. 이 때문에 주관적인 의견이 반영되었다고 생각할 수 있고요. 실제로도 annotation 형태에 따라서 점수를 매기도록 한 데이터셋들이 있습니다. 이걸 취합해서 최종 점수를 매겨서 요약 점수로 사용하고요.