이번에 제가 리뷰할 논문은 2017년 ICCV에 나온 논문으로 SSD-6D라고 불립니다. 제목에서 보시면 아시겠지만, 해당논문은 2D 객체검출분야에서 많이 사용되는 SSD아키텍쳐를 응용해서 6D Pose Estimation에 활용한 논문입니다. 이번에 가동원전 서베이를하며 주로 RGB-D 입력영상 기반의 6D Pose Estimation에 대해서 학습을 했었는데 그 과정에서 발견하게된 페이퍼이며, SSD의 컨셉을 어떤식으로 가지고왔을까? 라는 궁금증에 읽어보게 되었습니다. 일단 성능적으로는 아무래도 2017년 페이퍼이다보니 최신방법론에 뒤지지않을까 싶기는한데, 컨셉적인면에서 보면 배울 수 있는점들이 있지 않을까 싶습니다.
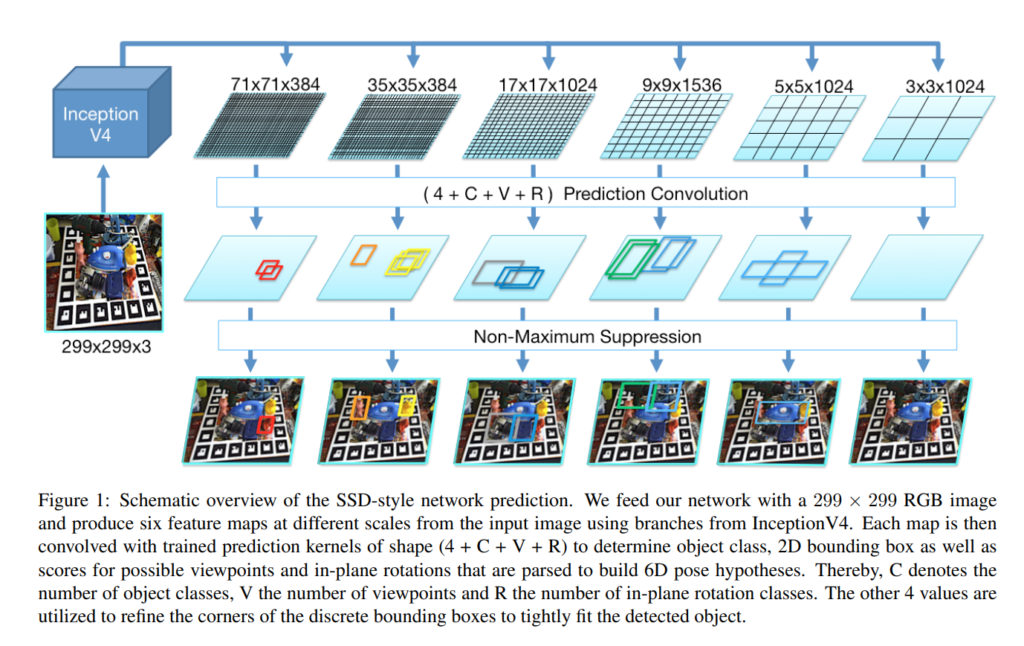
먼저, 해당 논문은 RGB기반이며 Depth정보를 optional하게 사용할 수 있습니다. 그렇다면 RGB영상과 SSD-like 아키텍쳐를 이용해서 어떻게 6D pose를 구했는지 알아보겠습니다. 위의 논문에서 처음으로 등장하는 피규어입니다. 해당 피규어를 보면 SSD에서 사용하는 핵심적인 컨셉들이 포함되어 있는 것을 알 수 있습니다. 우리가 자주보던 NMS도 있고, 입력영상으로부터 피쳐를 추출하는 부분도 동일해보입니다. 그리고 Prior box를 정의하고, 해당 prior box에서 offset을 regression하는 것도 동일합니다.
그렇다면 무엇이 다를까요? 먼저 그림을 보시면 (4+C+V+R) 이라는 정보가 보일것 입니다. 먼저 그 정보가 무엇을 의미하는지 설명드리겠습니다. 해당 논문에서 제안하는 아키텍쳐를 보시면 일단 SSD와 동일하게 입력영상으로 부터 피쳐를 추출하고 서로다른 스케일의 피쳐맵을 활용하여 task를 수행합니다. 기존 SSD에서는 그 task가 객체검출 이었다면, 해당논문에서는 해당 테스크가 6차원 자세검출이 됩니다. 즉, 피쳐를 추출하는 과정에는 SSD와 비슷하나 이후의 과정이 달라지는 것 입니다.
피쳐를 추출하는 부분까지는 SSD와 동일하니 설명을 생략하겠습니다. 추출한 멀티스케일의 6개의 피쳐위에 존재하는 각각의 그리드셀은 (4+ C+V+R) 가지고 있으며 해당 모델에서는 (4 + C+ V+ R)정보를 예측하는 방향으로 학습을 진행합니다. 각각이 의미하는바는 아래와 같습니다.
- 4: 4개의 bbox 코너값 offset
- C: Class에 대한 confidence score
- V: Viewpoint에 대한 classification
- R: Rotation에 대한 regression
1번은 bbox의 코너에 대한 offset 값으로 prior box를 물체가 있는 위치로 조절해나가는 방향으로 학습하는데 사용됩니다.
2번은 해당 RoI안에 각 물체에 대한 confidence score값으로 SSD에서와 컨셉이 동일합니다.
3번부터가 특이한 점인데요, 해당 논문에서는 view point classifcation이라는 개념을 사용합니다. 저는 개인적으로 처음본 개념이라 생소했는데 해당 내용은 view point를 discrete하게 나누어서 classification 한다는 의미입니다. 좀 더 자세한 설명은 뒤에서 이어서 하겠습니다.

위의 그림은 먼저 MS COCO데이터셋에서 SSD기반의 모델로 2D object를 검출하는 과정에서 bbox가 어떤식으로 생기는지 보여주기 위해서 논문에서 사용한 사진입니다. 아마 연구원 분들중에 대다수는 SSD작동원리에 익숙하실거 같으니 넘어가겠습니다.

해당 그림에서는 view point classificaiton의 컨셉을 잘 보여주고 있습니다. 먼저 6DoF 자세검출이 익숙하지 않으신 분들을 위해 배경지식으로 6D 자세검출에서는 데이터셋과 더불어 CAD모델링 정보가 제공이 됩니다. 해당 논문에서는 모델링 정보를 이용해서 viewpoint를 discrete하게 나누었습니다. 해당과정에서는 만약 물체가 좌우 대칭인 경우는 green포인트만을 사용합니다.

3D 모델링 정보가 있다는 것은 위와 같이 간단한 삼각비 계산으로 synthetic하게 3D 랜더링 작업을 할 수 있다는 의미가 되기도 합니다. 3D 모델정보를 이용해서 다양한 viewpoint에 대해서 classification 할 수 있도록 나누었고, 위와같이 3D 랜더링 작업을 통해서 기존 이미지에 다양한 모습의 형태로 물체를 합성해서 synthetic data를 만들었습니다. 그리고 해당 synthetic data만을 사용하여 모델을 학습합니다.

그렇게 했을때, synthetic 데이터에서는 bbox의 위치에대한 GT와 Pose에 대한 GT, viewpoint에 대한 GT가 존재하는 상태입니다. 이러한 정보는 위에서 말씀드린것처럼 3D 모델링정보를 통해서 구해집니다. 즉 해당 정보들을 synthetic하게 만들 수 있기 때문에 모델학습을 하기위한 정보를 synthetic하게 만들 수 있다는 소리입니다.

결론적으로 RGB영상에서 2D detection과 viewpoint classification, pose regression을 동시에 수행하여 6차원 자세를 검출하였고, 다른 6차원 자세검출 방법론과 마찬가지로 Depth센서를 추가활용하거나 refinement하는 과정에 대한 실험도 진행하였습니다.
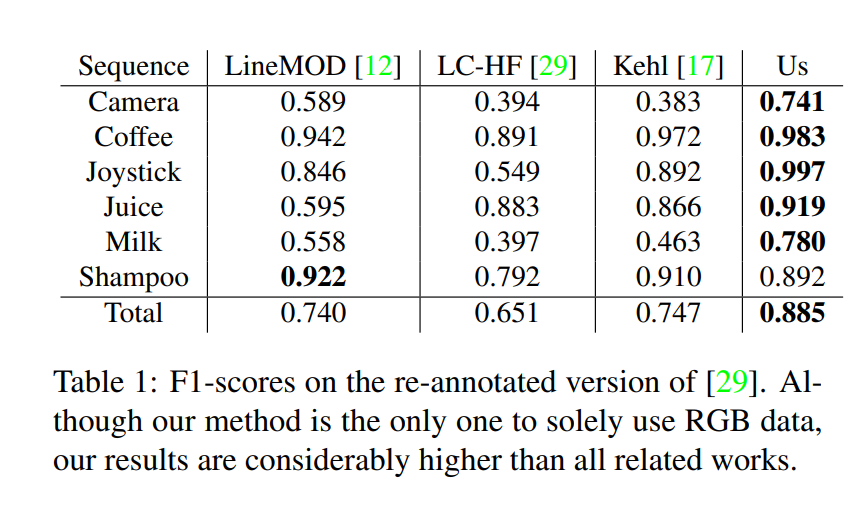
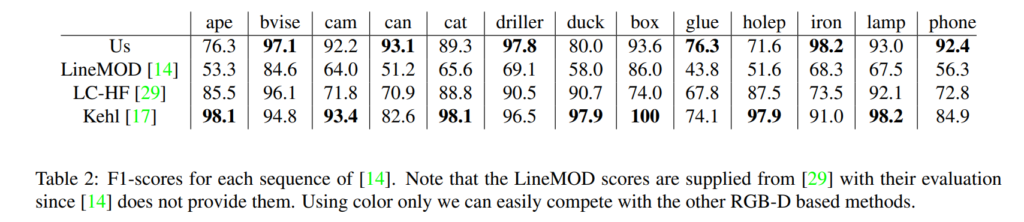
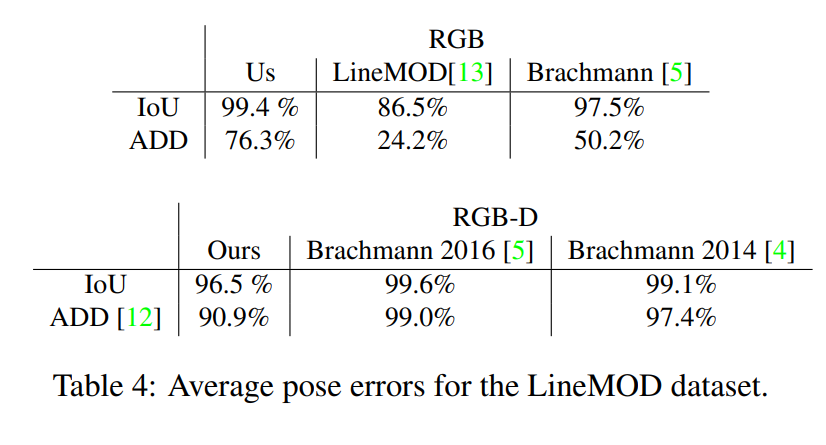
실험에 대한 결과이며 개인적으로 느끼기에는 synthetic data만을 사용하였음에도 불구하고 거의 성능차이가 없다고 느껴졌습니다.
이상 리뷰 마치겠습니다.
Depth 정보를 optional하게 사용할 수 있다는 의미가, 기존 RGB 기반 방법론에 Depth image를 fusion하여 사용할 수 있다는 의미일까요? 만약 그렇다면 RGB와 Depth image를 어떻게 합칠 수 있는지 궁금합니다. 그리고 본 연구에서는 결국 가상의 object를 만들고 그에서 얻어진 viewpoint, pose와 관려된 GT값을 이용하여 Supervised로 학습을 하는데, 그러면 데이터셋에 오버피팅 되지 않을까하는 생각이 듭니다. 혹시 해당 연구는 자신들의 방법론을 일반화 할 수 있음을 다른 보편적인 데이터셋에서 나타내고있는지 질문드립니다.
1. fusion과 같은 모델단에서 입력으로 사용되지 않고 refinement할때 verification하는 용도로 사용됩니다.
2. 3개의 데이터셋에서 실험을 진행하였으며, 오버피팅 이슈는 사실 6DoF Pose Estimation에서는 늘 있는 이슈라고 생각합니다. 애초에 정확하게 똑같은 물체를 배열/시점만 바꿔가며 촬영하였기 때문입니다. 정형화된 shape이 없는 물체를 다루는 경우는 category-level 6DoF Pose Estimation이라고 불리우며 방법론이나 성향이 매우 다릅니다.
심플한 솔루션이라 재밌는 방법론인 것 같습니다.
몇가지 궁금한 점이 있습니다.
synthetic 데이터를 얼마나 많이 사용했는지 궁금해지네요.
그리고 모델링의 rotation과 view point을 얼마나 세밀하게 나눠서 적용했는지 궁금합니다.
아ㅏ 하나 더 질문 드리자면 현재에도 해당 방법론이 제시한 방법을 적용하고 있나요? 그렇다면 왜 그런지에 대한 형준님의 생각이 궁금합니다.