요약
본 논문은 Vision Transformers의 특성을 self-supervised 학습 방식을 통해 보이며, 최종적으로 그들이 제안하는 새로운 self-supervised method인 self-distillation with no labels(DINO)를 소개하는 논문입니다.
introduction
본 논문은 기존 transformer 의 효용성 분석에 대한 한계를 우선 지적합니다. 논문이 말하길 NIP 에서 유입된 transformer는 pretrain 된 모델을 작은 데이터로 fine-tuning 하는 방법론으로 vision 분야에 들어와서 기존 convnets 보다 좋은 성능을 보인 것은 사실이지만 다음의 한계를 갖는다고 합니다.
- 더 많은 연산량
- 더 큰 데이터 필요도
- convnets과 비교하여 특이점이 없는 feature
논문은 이러한 미미한 성공이 혹시 NLP 분야의 transformer 구조를 잘못 도입한것이 아닐까 라는 접근으로 시작됩니다. NIP 분야의 경우 문장을 입력으로 받고 문장을 출력으로 하는 self-training 방식으로 학습을 하는 반면 vision transformer의 경우 supervised 방식으로 학습하며, 또한 vision 분야의 self-training 방식은 주로 nlp 분야처럼 입력 form과 유사한 text를 생성하는 것이 아닌 이미지를 약 1000개 중 하나의 라벨로 분류하여 feature 생성시 정보를 손실합니다. 이와 같은 차이점 때문에 vision transformer가 vision 분야에서 부진한 것이 아닐까 라는 분석으로 self-supervised vision transformers(이후 ViT)를 통해 실험을 진행하였으며 실험 결과 기존 supervised ViT 혹은 convnets 방식보다 semantic 한 정보가 있고 feature 간의 구별성이 있는 output을 생성한다고 합니다. 또한 이러한 분석을 이용하여 새롭고 간단한 self-supervised method인 DINO를 제안합니다.
self-supervised vision transformers

self-training 을 적용한 transformer는 위의 그림처럼 물체의 boundary 정보를 갖고있으며 class 정보를 잘 담고있어 학습하지 않고 knn classification을 적용하였을 때도 ImageNet 기존 78.3 accuracy(top1)을 보인다고 한다.
about DINO

DINO란 knowledge distillation 방법론에서 영감을 받아 개발된 self-supervised learning 방법론으로 구조는 생각보다 친숙하다. 위 그림처럼 teacher와 student의 학습 output 분포가 같아지도록 결과인 p에 cross-entropy loss를 적용하며, teacher에는 분포 정규화를 위해 centering(mean값을 맞추는)과 softmax를 적용한다. 업데이트시 teacher 모델은 freeze 하며 다음 iteration에 student 모델의 파라미터를 momentum ema 방식(기존 파라미터를 새로운 student의 파라미터로 업데이트하는데 이때 무조건적으로 새 파라미터로 변하지 않고 가중치를 주어 천천히 새로운 파라미터와 같아지게 하는 방식)으로 받아오면서 teacher 모델을 업데이트 한다.
실험
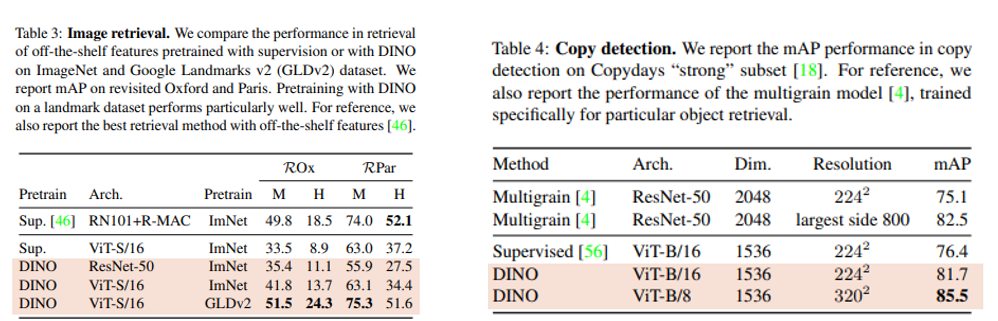
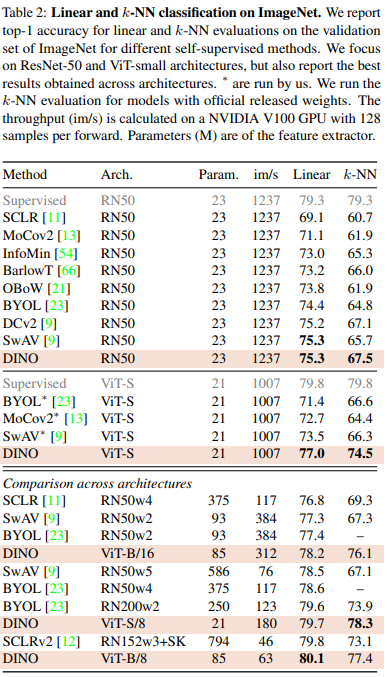
기존의 supervised vit나 convnets 방법론보다 좋은 성능을 보임을 알 수 있다.

추가
boundary를 살리기 위한 depth 팀이 transformer를 사용할때 참고해보면 어떨까 한다. 코드는 있으며 ImageNet 기준 8개의 GPU로 3일간 학습을 필요로 한다고 한다.
리뷰해주신 논문이 Self-supervised 에 transformer의 대표적인 방법론인 vit를 응용한 방법론인 것 같습니다.
다만 기존 supervised vit 와 본 논문에서 제안하는 DINO는 knowledge distillation 을 사용하였다는 것 말고는 다른 차이가 없나요? 모델에 대한 부분이 빠진 것 같아 질문드립니다. 그리고 두번째 질문은 이 self-learning 방식은 Fixmatch와는 어떤 차이가 있길래 experiment에서는 비교 실험을 하지 않는지 아시나요? 마지막으로 본 논문의 contribution을 정리한다면 무엇인지도 질문드리고 싶습니다. 리뷰 감사합니다