1. Abstract
instance segmentation의 경우 (특히 대형 객체에 대해) down sampling 작업으로 인해 분할 마스크가 매우 거칠다. 해당 논문은 객체와 장면에 대해 고품질의 instance segmentation을 수행하기 위해 RefineMask라는 방식을 제안하였다. 전체 과정에서 여러 단계에 걸쳐 인스턴스별로 세분화된 특징들을 통합하여 마스크를 일관되게 개정할 수 있고, 이전 방식에서 지나치게 단순화되거나 휜 부분을 세분화하고 정확한 경계를 출력하였다. 해당 방법론은 COCO, LVIS, Cityscapes에서 mask r-cnn보다 2.6, 3.4, 3.8 AP 성능 향상일 이뤘다.
2. Introduction

Mask R-CNN은 figure 1의 (a)에서 확인할 수 있듯이 세부 정보를 놓치는 문제가 있다. 이는 여러 feature pyramid에서 pooling을 수행하기 때문에 고차원 feature의 해상도가 더 coarse해지고 따라서 디테일을 유지하지 못하므로 다시 고해상도의 입력 이미지로 예측을 매핑하기 어렵게 하기 때분이다. 또한, pooling은 해상도를 낮추므로 그 자체로 정보가 손실되기 때문이다.
figure 1의 (b)와같이 semantic segmentation은 각 인스턴스를 구별하지 않으므로 고차원의 feature가 필요하지 않아 객체의 경계를 잘 구분할 수 있다 하지만 instance segmentation의 경우 각 객체를 구별해야 하므로 고해상도의 특징(low-level feature)을 충분히 활용하지 못한다.
이 논문은 instance segmentation으로 인스턴스를 구별하고 놓친 세부사항을 fine-grained feature를 이용하여 보완하는 것이 주요 아이디어이다. 이를 위해 RefineMask라는 새로운 프레임 워크를 제안하였고, 이는 새로운 semantic head를 고해상도 feature map에 사용하여 fine-grained semantic feature를 생성한다. 이를 통해 figure 1의 (c)와같이 경계에 대해 높은 정확도를 갖는 모델을 학습할 수 있다.
3. RefineMask
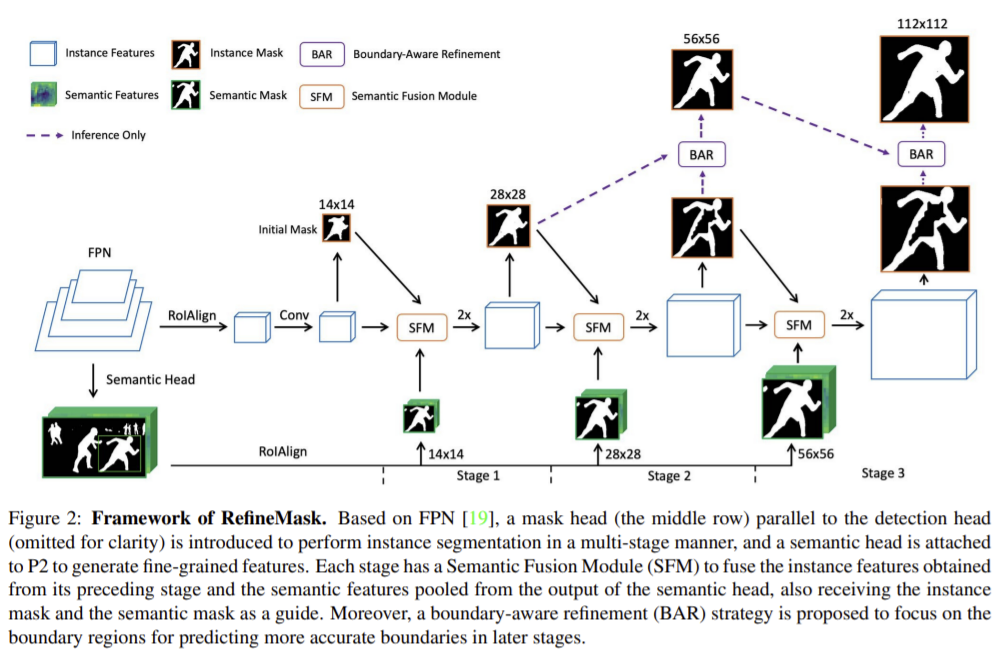
RefineMask는 크게 semantic head와 mask head로 구성된다.
3.1. Semantic Head
semantic head는 P2(feature pyramid network의 최고 해상도 feature map)에 fully convolutional NN를 붙였다. 네개의 convolution 레이어와 전경에 속하는 픽셀의 확률을 예측하는 이진분류기로 구성된다. cross entropy loss를 이용하여 고해상도 semantic mask를 예측한다. fine-grained feature는 semantic feature와 semantic mask의 결합으로 정의하고 이는 mask head가 놓친 세부 영역을 보완하는 데 사용된다.
3.2. Mask Head
fully convolutional instance segmentation branch로 14×14 RoIAlign 연산으로 추출한 특징들은 instance feature를 생성하기 위해 두 개의 3×3 conv 레이어로 공급된다. 이후 instance mask 예측을 위해 1×1 conv를 이용한다. 하지만 마스크의 크기는 14×14로 coarse하고, 이는 이후의 정제 단계를 초기화하는 마스크로 사용된다.
3.2.1 Multi-stage refinement
instance mask를 반복적으로 정제하기 위해 multi-stage refinement를 제안하였다. 각 단계의 입력은 이전 단계에서 얻은 instance feature과 instance mask, semantic head에서 얻은 semantic feature와 semantic mask로 구성된다. 이 네가지 입력을 통합하기 위해 SFM(Semantic Fusion Module)을 제안하여 feature들을 더 고해상도로 조정하며, 이 고장을 반복하여 최대 112×112 해상도의 instance mask를 출력한다. 이때 SFM으로 융합한 feature들은 1×1 conv를 이용하여 채널을 반으로 줄여 추가 연산량을 줄인다.
3.2.2 Semantic Fusion Module
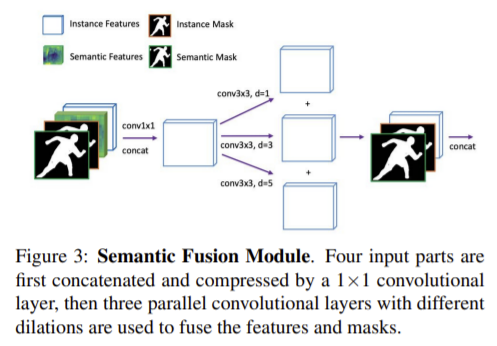
figure 3과같이 SFM 모듈은 각 단계마다 1×1 conv를 통해 채널을 줄이고 3가지 다른 dilation을 적용한 feature들은 local 디테일을 유지하며 주변 정보를융합하는데 사용된다. 이후 instance mask와 semantic mask는 다음의 예측을 위한 가이드로 fusion된 feature와 다시 연결된다.
3.3. Boundary-Aware Refinement
boundary region에서 정확하게 예측하기 위한 방식이다.
boundary region?
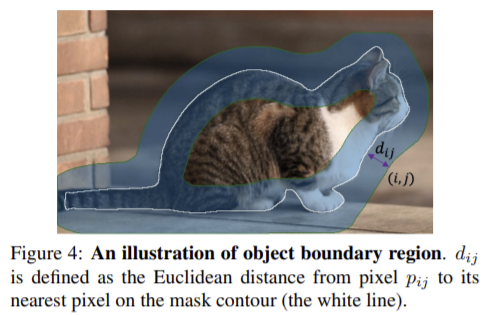
k단계의 이진 instance mask를 M^k (k=1,2,3)라 하면 해당 마스크의 크기는 14·2^{k}x14·2^{k}이다. M^k (k=1,2,3)의 boundary region은 figure 4의 파란색 영역과 같이, 윤곽 경계로부터 \hat{d} 이하의 거리를 가지는 픽셀들로 구성된 이진 마스크로 B^{k}로 나타내며 다음과 같이 공식화할 수 있다.
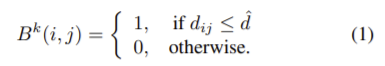
** i, j 는 픽셀p_{ij}의 위치(i,j)이고 d_{ij}는 픽셀p_{ij}로부터 윤곽까지 가장 가까운 유클리드 거리이다.
Training
각 단계로부터 순서대로 완전히 예측한 28×28, 불완전한 예측을 한 56×56과 112×112의 크기를 갖는 instnace mask를 만든다. 객체 영역은 이전 단계의 예측 마스크와 정답 마스크를 이용해 학습된다. 다음 식으로 나타낼 수 있으며, f_{up}은 크기가 2인 bilinear upsampling을 ∨는 두 영역의 합집합을 의미한다.
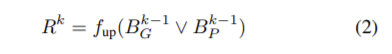
k단계의 학습 loss는 \mathcal{L}^{k}(k=2,3)다음과 같이 정의된다.
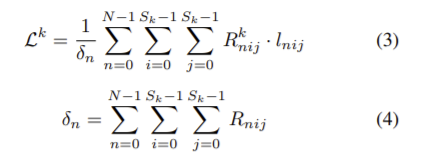
**k단계의 출력의 크기는S_k x S_k, N은 인스턴스의 수, I_{nij}는 인스턴스n에 대한 (i,j)위치에서의 이진 cross-entropy loss
Inference

inference에서 instance mask는 다음 수식과 같이 구할 수 있으며 이때 M’^{k}는 k단계에서 refinement를 거친 instnace mask를 의미하며, M’^{1} = M’^{1}이다. 수식으로 표현하면 다음과 같이 표현할 수 있다.

figure 5는 second stage에서 M’^{2}를 구하는 과정을 도식화 한 것이다.
Experiments
- COCO 80 categories

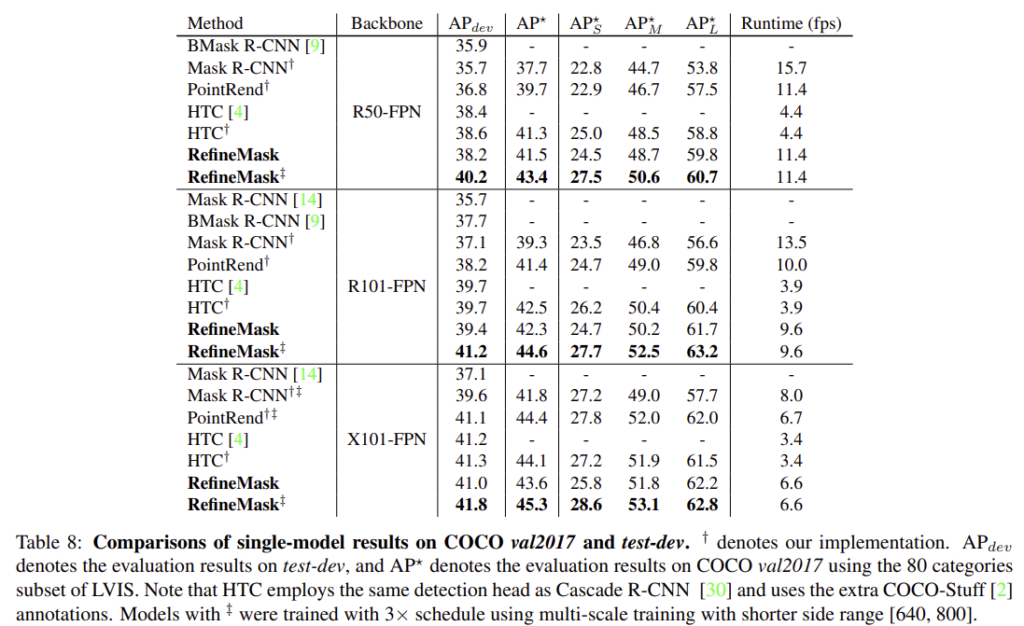
- SFM 모듈을 3가지 fusion 방식과 비교한 결과 제안한 SFM방식이 가장 좋은 성능을 보임

- fine-grained features를 사용할 경우 정확도가 상승한다.

- multi-stage refinement 유무에 따른 효과

- boundary-aware refinement의 유무에 따른 효과

- 정성적 결과

- LVIS
1203 categories, 200만 이미지 100k(training), 20k(validation), 20k(test)

- Cityscapes
8 categories 2975(training), 500(validation), 1525(test)
방법론에 대해 차근차근 잘 이해가 가게 논문이 설명이 잘 되어있었습니다. 또한 실험이 다양해서 성능 향상에 도움이 된다는 것도 확인할 수 있었습니다. 그런데 Boundary-Aware Refinement를 수행할 때 기본 전제가 low-level에서의 예측 결과는 대체로 잘 만들어지고, high-level이 될 수로 중간 부분이 예측이 잘 안된다는 것에 대해서는 결과를 분석한 결과인지 설명이 되어있지 않아서 아쉬웠습니다. 그리고 그러한 전제를 벗어나는 예측 결과에 대해서는 어떤 결과가 나올 지 궁금해졌습니다. 그리고, 경계를 잘 예측하기 위한 방법론이라 하여 찾아보았는 데, 마지막에 4장의 정성적 결과를 제외하고는 윤곽에서의 예측 정확도가 얼마나 좋아졌는지를 확인하기 어려워서 아쉬웠습니다. 윤곽의 주변 픽셀에 대한 정확도를 따로 뽑아보면 어떤 결과가 나올 지 분석을 통해 semantic mask의 효과를 확인하고, 중심부의 예측 정확도를 따로 뽑아 Boundary-Aware Refinement의 성능을 확인하면 더 좋은 분석이 가능했을 것이라 생각됩니다.
리뷰 감사합니다. 본 논문은 더 local한 영역을 볼 수 있도록 semantic head와 mask head 사용하여 성능을 올린 instance segmentation 방법론인 것 같습니다.
다만 리뷰를 이해하는 데에 몇 가지 이해가 안되는 부분이 있어 질문남깁니다!
1. 그림 1과 함께 “instance segmentation의 경우 각 객체를 구별해야 하므로 고해상도의 특징(low-level feature)을 충분히 활용하지 못한다” 라고 서술해주셨는데요, 혹시 각 객체를 구별하는 것과 low-level feature를 활용하는 것이 어떤 관계가 있고 왜 충분히 활용하지 못하는지에 대해 추가 서술을 부탁드려도 괜찮을까요?
2. Training 의 내용 중 “완전히 예측한 28×28, 불완전한 예측을 한 56×56과 112×112의 크기를 갖는 instnace mask”에서 완전히 예측/불완전한 예측은 무엇을 의미하나요? 객체 영역을 f_up을 사용하여 정의하였다는데 loss를 포함하여 학습 과정에 대한 이해가 잘 가지 않아 이 점에 대한 추가 설명을 요청드리고 싶습니다
3. 마지막으로 실험 결과 리포팅 시 mask rcnn 말고 다른 instance segmentation 방법론에 대한 성능은 비교 안하나요..? 그리고 Inference 이후 테이블을 포함하여 많은 사진이 누락된 것 같아 확인이 필요할 듯합니다!
답변주시면 감사하겠습니다.
1. mask R-CNN의 경우 RoI(region of interest)를 통해 각 객체에 대한 구별을 한 후 각각에 대해 segmentation을 수행하는 데, RoI가 CNN모델을 거쳐 나온 high-levelfeature이기 때문에 low-level feature를 충분히 활용하지 못했다라는 의미입니다.
2. figure2에서 BAR을 거치기 전의 이미지를 보시면 28×28은 객체의 내부도 잘 예측한 결과이고 나머지 두 이미지는 이미지의 크기가 누락되었응나 56×56, 128×128의 마스크 예측 결과로 중심부분이 검정색으로 잘 예측이 안된 것을 확인하실 수 있습니다. 이러한 점에서 완전한 예측과 불완전한 예측이라 이해하시면 됩니다.
그리고 질문하신 내용은 boundary region에 대한 학습을 어떻게 하는지 질문하신 것 같습니다. 이에 대한 학습은 figure 5(제가 figure5을 누락했기 때문에 이해하기 어려우셨던 것 같습니다… 죄송합니다. 다시 첨부해두었으니 참고해주세요.)를 보시면 이해하는 데 도움이 되실것입니다.
설명을 드리자면, figure2의 BAR에서 입력으로 들어가는 이미지가 두 마스크가 들어가는 것을 확인하실 수 있을 것입니다. 이처럼 이전 stage의가 영향을 주는데요, R^k는 이전 stage의 예측 결과와 이전 stage의 boundary region에 대한 GT의 합집합 영역을 bilinear upsampling한 결과입니다. 이렇게 구한 영역이 1인 경우에 대한 cross-entropy loss로 학습을 한다고 이해하시면 될 것 같습니다.
3. 실험 결과 리포팅 시 mask rcnn 말고 다른 instance segmentation 방법론에 대해서도 리포팅을 합니다. 해당 내용을 추가해두었습니다.(figure 8을 확인해주세요.) 또한 테이블들이 누락된 것들을 다시 업데이트해두었습니다. 알려주셔서 감사합니다!!(notion에서 옮기다 inference 이후의 테이블이 누락된 것을 미처 발견하지 못했습니다…)
리뷰 잘 읽었습니다.
1. Training 단계에서, ‘객체 영역은 이전 단계의 예측 마스크와 정답 마스크를 이용해 결정된다.’ 라는 말은 정답 마스크를 이용해서 예측을 한다는 건가요…? Loss를 계산하기 위해 예측과 정답을 비교하는 게 아니라, 아예 정답을 통해서 예측을 하는 건 처음 봐서 여쭤봅니다! 혹시 이런 방법을 부르는 용어가 따로 있을까요?
2. Inference 부분에서 figure 5 이미지가 생략된 것 같습니다…! 혹시 빠진 게 맞다면, 넣어주시면 살펴보도록 하겠습니다 😀
1. 우선 위의 댓글에 대한 응답을 참고해주시면 감사하겠습니다! 그리고 정답마스크를 이용하여 예측을 진행한다는 의미가 아니라 학습에 활용한다는 것으로, 해당 내용은 제가 표현을 수정해두었습니다..
2. 제가 이해하는 데 어려움을 드렸네요… 알려주셔서 감사합니다.. 해당 그림과 나머지 누락된 이미지들도 다시 추가해두었습니다..