저의 Depth Estimation 논문 리뷰가 다시 돌아왔습니다. ㅎㅎ
RAL 논문을 작성하기 앞서 작년11월달 부터 지금까지 어떤 논문들이 나왔는지 서베이하던 도중에 그사이 3DV2021이 진행된 것을 알았고 그곳에서 발표된 논문을 follow up 하고 있는 중입니다. 다른 분들도 한번 쓱 보면 좋을 것 같습니다.
이 논문은 기존에 제가 들고왔던 Monocular depth estimation이랑은 입력이 multi frame이라는 점에서 살짝 다릅니다. 이렇게 multi frame을 이용해서 Depth 를 추정하는 것은 ManyDepth[1]에서 제안되어서 이제 새로운 Self-supervised depth estimation의 바람이 아닐까 생각이 됩니다. 이건 여담으로 ManyDepth를 만든 Niantic (이하 닌텐도) 에서는 Self-supervised depht estimation 관련 연구를 선두하고 있습니다. (monodepth-> Monodepth2-> ManyDepth 전부이 닌텐도…. AR을 씹어먹을 생각인가봅니다. 허허)
카메라 하나로 Depth추정하는 Monocular Depth Estimation with Self Supervised learing은 처음엔 Stereo 의 Geometry 관계를 이용했고(Monodepth) 그 다음 Squence 한 프레임들 간의 관계를 이용해서 학습하는 방식(Monodepth2)이 주요 task가 됐습니다. Monodepth2와 같이 Sequence한 관계를 이용해서 학습을 할경우 어차피 학습때는 카메라 한대로 부터온 세장의 영상을 사용하며 test에도 카메라 한대에서 촬영한 영상하나를 쓰기때문에 사용측면에서 Train과 Test전부 3장의 영상을 사용하는것은 문제 될게 없으며 오히려 Depth를 예측하는데 있어서 temporal 한 정보를 주기 때문에 좋습니다.
Manydepth가 temporal한 정보를 입력으로 하는 방식의 포문을 열긴했지만, 아직 성능에 한계가 있었다고 합니다. 따라서 이 논문에서는 temporal 입력을 사용한 depth estimation의 성능을 향상 시키위해서 Spatial-Temporal Attention을 제안했으며 이 Attention 방법론은 local 한 geometric information을 강화하며 전역 context 정보를 활용해 성능을 올렸다고 합니다. 추가적으로 Loss function과 Depth consistency를 평가하기 위한 새로운 평가 방식을 제안합니다.
이 논문의 contribution을 다시 정리하면 다음과 같습니다.
- spatial attention: boosting local geometry information
- temporal attention: ensures global consistency
- cycle consistency regularization: for geometric guidance(SA-TA attention)
- temporal consistency metric: to quantify depth consistency

Method
- Architecture
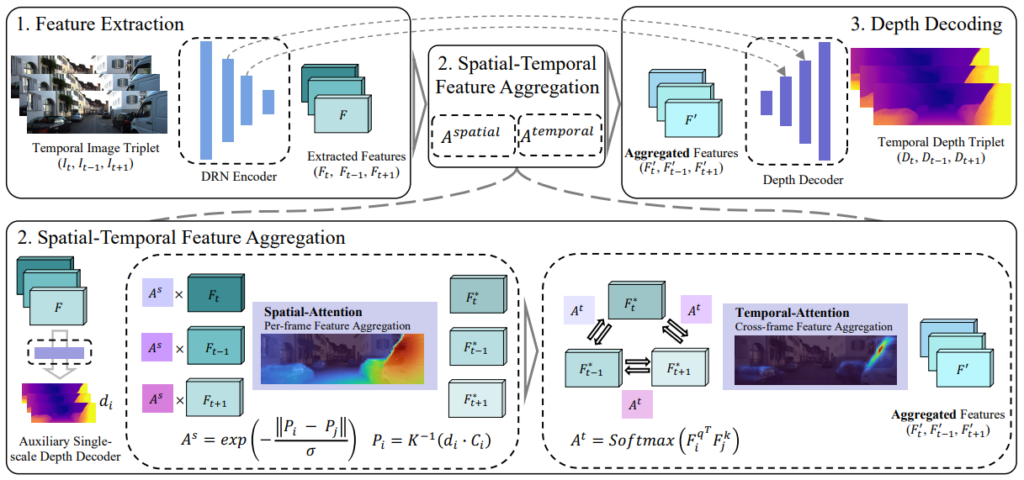
그림 2가 이 논문에서 제안하는 Depth Estimation용 네트워크인 Temporally consistent depth (TC-Depth)입니다. 이 네트워크는resnet을 encoder로 사용하는 기존 방법론들과 다르게 dilated convolutions로 구성된 네트워크( DRN)를 encoder로 사용했습니다. 그 이유는 중간에 Attention module에 입력으로 들어가는 feature의 해상도를 맞추기 위해서라고 합니다. 여기서 이제 모르겠는 부분이 DRN encoder로 영상이 3개가 들어가는 것인지 아니면 따로따로 encoder에 넣고 feature를 얻는 것인지 모르겠습니다… (제가 모르겠다고 한 부분들은 다 저자가 만든 git에 문의를 남겼으니 답변이 온다면 추가하도록하겠습니다. )
Encoder에서 feature를 추정한 후 Attention부분이 이 논문에서 제안하는 알파이자 오메가가 되겠습니다.
Attention 방식은 기존 VIT와 같은 Transformer의 성능 향상에 주목했으며 Query,Key Value를 사용하는 방식을 채택했다고 합니다. 하지만 단순히 feature를 dot product하는 것은 3D 장면에서 기하학적으로 멀리 떨어져 있는 부분에 도입할 수 있으며 이는 조밀한 깊이 회귀 작업에 바람직하지 않을 수 있기 때문에 다른 방식을 제안한다고 합니다. (단순히 dot product Ablation Study X)
1.1 Spatial Attention
그림 2 좌하단에 있는 Spatial Attention은 각 프레임의 local information을 향상 시키이 위해서 Spatial Attention 방법을 제안합니다. 이 Attention은 단순히 dot product하지 않기 위해서 새로운 방식을 제안하는데 그방법이 매우 특이 합니다. 먼저 예측된 세개의 feature( Ft,Ft+1,F-1)를 각각 depth decoder(DDV)에 태워서 Query depth와 key depth를 예측합니다. 그 후 예측된 depth를 3D 공간상으로 올린 후 3D 공간상에서 두 depth가 유사해지도록 하는 Attention 값을 구합니다.
식으로 보면 다음과 같습니다.

i와 j는 각각 하나의 feature로 부터 예측된 것들을 의미합니다. (이게 정확한지 모르겠습니다. key와 query에 관한 설명이 전무해서 읽으면서 살짝 답답하더라구요…ㅠ)
그렇게 구한 Attention값을 feature에 곱해주면 Spatial Attention이 완료됩니다.
1.2 Temporal Attention
Ft,Ft-1,Ft+1 각 feature들간의 상호보완관계를 통해 global information 을 강화하기 위해서 temporal attention을 제안하며 이건 그림 2 우하단에서 볼 수 있습니다. 그림과 같이 두 feature간의 product 를 해서 관계를 구한 후 softmax를 사용해 attention 값을 구합니다. ( 각 feature 당 몇번의 attention이 되는지 그게 어떠한 순서로 되는지는 논문에 나타나 있지 않습니다.)

spartial attention과 temporal attention을 각각 적용했을때 Attention 값을 본 것입니다. 보면 Spatial Attention은 객체의 가장자리와 같은 부분을 주목하며 Temporal Attention 과같은 경우 Spatial Attention 이 주목하지 않은 모델이 어려워 할 만한 부분을 주목해서 두 Attention 방법론이 상호보완 관계를 띈다 합니다. ( 흠… local과 global information 주목한다했는데 그게 맞는지 모르겠음) 그리고 마지막으로 뒤에서 설명할 geometric loss function을 적용하니 주용한 부분에 더욱 주목했다고 하는데 주목하는 부분이 너무 적어서 저게 좋은 결과 일까…합니다.
2. Loss function
loss function을 굉장히 다양하게 제안했습니다. 기존에 monodepth2가 제안한 Loss function은 모두 사용하며 아래 function이 새로 제안한 방법입니다.
Scale-invariant Consistent Depth Loss
모든 frame에서 예측된 depth 값이 동일한 scale을 가지도록 고안한 loss입니다. 이로스는 처음 나온 것이 아니고 기존에 [2] 에서 제안된 식을 조금 변형한 것 같습니다.
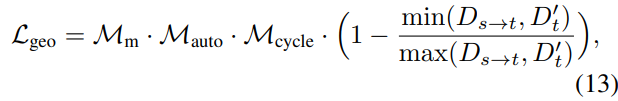
식은 위와 같습니다. source depth를 target depth 로 warping 한 후 위와 같이 비교합니다.
깊이 예측의 규모에 페널티를 주는 문제를 완화할 뿐만 아니라 Cycle loss을 활용하여 occlusions을 처리하는 프레임 간의 일관된 깊이 예측을 장려하기 위해 기하학적 손실로 설계됐습니다.
Cycle-Mask from Photometric Consistency
Occlusion된 물체되 실제 비교하는 두 프레임간에 겹치는 영역이 아닌 부분은 학습을 할때 방해가 됩니다. 이러한 문제를 해결하기 위해서 Monodepth2에서는 Automasking 방식을 제안했지만 이방법은 씬의 중요한 부분까지 제거하는 문제가 있다고 합니다. 인접 깊이 맵의 부정확한 변환으로 인해 불일치가 큰 영역이 될 수 있으며 따라서 monodepth2가 제안한 방법론은 장면의 넓은 영역을 마스킹할 수 있습니다. 이러한 문제를 해결하기 위해서 이 논문에서는 다음 식과 같이 Cyclic 하게 변환된 영상을 이용해 mask를 구하는 식을 제안합니다.
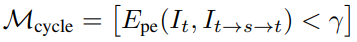
Epe는 photometric loss이며 r은 전체 에러의 70%되는 값으로 설정했습니다.
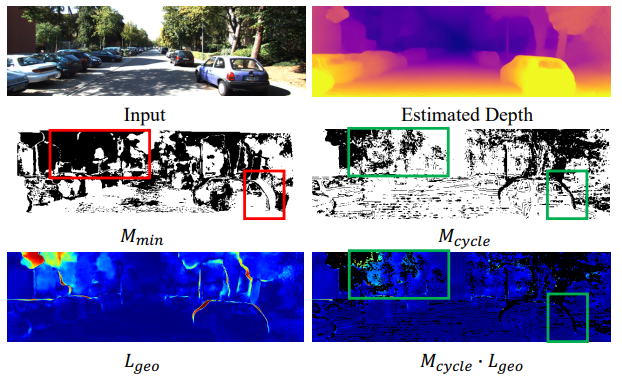
기존 방법과 Cycle 방법론을 비교한 그림 입니다. 확실히 디테일한 영역을 제거한 것을 볼 수 있습니다.
Motion Consistency Loss Lm
학습 초기에 학습을 guide하기 위한 knowledge distillation을 제안합니다. Monodepth2 pretrained model을 teacher model로 사용하며 다음 식을 통해 moving object의 영역을 제거할 mask를 구합니다.
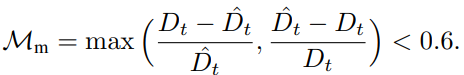
그 다음 아래 식으로 loss를 구합니다.
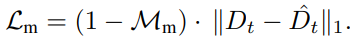
Reference Loss Lref
마지막 loss는 spartial attention에 사용되는 DDV를 학습하기 위한 loss 입니다.
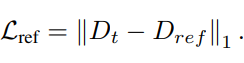
위와 같이 예측되고 있는 depth를 이용해 DDV를 학습합니다.
Experiment
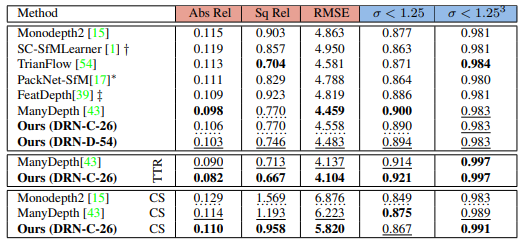
성능을 보면 KITTI에서는 TTR을 하기전에는 그렇게 높은 성능을 보여주지 못하지만 TTR을 통해 refinement하여 Manydepth 보다 높은 성능을 달성했다고 합니다.

이 논문에서는 끊김없는 depth 예측을 굉장히 중요하게 말하고 있습니다. 그랬을때 제안한 방법론이 위와 같이 제일 좋은 정성적 결과를 보입니다.
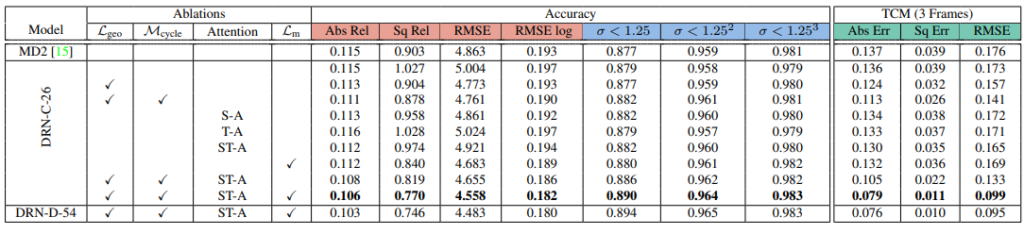
Ablation Study 결과입니다. 꽤 꼼꼼하게 한 것 같습니다.

정성적 결과입니다. 예측된 결과를 3D로 올렸을때 얼마나 object를 잘 표현했는지 보여줍니다.
방법론은 참신한거 같긴한데….모델이 굉장히 무거워보입니다. 하지만 모델 전체 크기에 관한 리포팅이 없어서 아쉽습니다. 사실 제일 아쉬운건 논문의 방법론 부분이 너무 많은걸 생략해서 제가 이해한 방식이 맞는지 모르겠다는 것입니다. 하지만 이 temporal 를 이용한 방법론이 추후 2년간은 논문이 나올 것 같으니 계속 follow up 해보겠습니다.
Reference
[1] The Temporal Opportunist: Self-Supervised Multi-Frame Monocular Depth
[2] Unsupervised Scale-consistent Depth and Ego-motion Learning from Monocular Video