최근에는 비디오 정렬과 관련된 논문을 읽었습니다. 비디오 정렬도 논문을 검색해보면 크게 두가지로 나뉘어집니다. 영어로는 똑같은 alignment를 공유해서 사용하고는 있지만, Video Syncronization에 가까운 (비디오 프레임을 조정해서 시간적인 흐름을 정렬해주는 연구)와 지금 소개해드릴 연구와 나눠지는 것 같습니다. 아무튼 시작해보겠습니다.
Introduction
지금 소개해드릴 논문은 video partial copy detecion에서 쿼리 비디오와 데이터베이스 비디오가 있을 때, 쿼리 비디오의 어느 영역이 데이터베이스의 어느 영역과 일치하는지를 알려주는 태스크에 관한 논문입니다. 특이한 점은 End-to-End(라고 말은 하지만 실상은 아닌) 구조를 가지고 있고요.
기존의 SIFT 등으로 feature를 추출하는 방법론들을 바탕으로한 video alignment 연구는 꽤 있었습니다. 하지만 딥러닝 방법론에서는 연구가 없는 것도 그렇고, 성능이 그렇게 좋지 않았다고 합니다. 그래서 논문 저자는 novel space-time feature fusion framework를 제안합니다.
이 방법론은 쿼리 비디오와 데이터베이스 비디오의 CNN-based feature를 키프레임마다 추출해서 이걸 2차원 배열의 descriptor로 변환합니다. 그리고 이 배열을 이용해서 spatio-temporal relationship matrix를 계산하고, 이 matrix를 grey scale map으로 변환하여 여기에 간단한 detector를 붙여서 일치 영역을 탐지해내는 방법론입니다.
Our approach
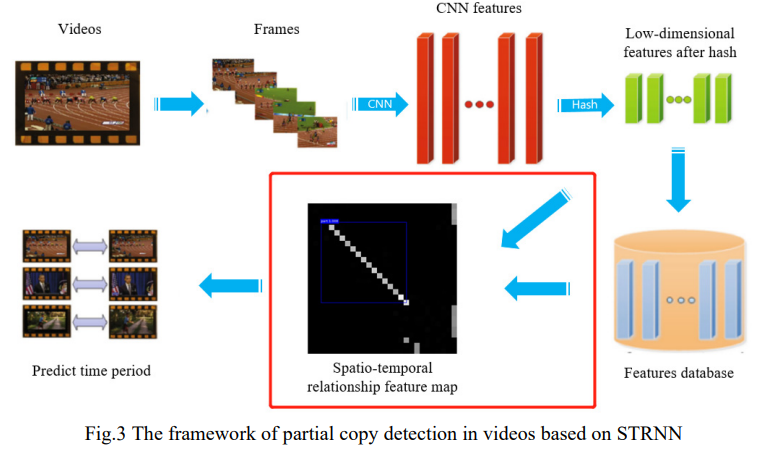
논문에서 제안하는 STRNN(spatio temporal relationship neural network)은 위 그림과 같은 구조를 가지고 있습니다. 비디오에서 프레임을 추출해서, 그 프레임의 feature를 추출하고, 효율을 위해 추출한 feature에 차원 축소를 적용합니다. 그리고 제일 중요한 alignment가 수행됩니다.
Feature extraction
대부분의 비디오 논문들이 그렇듯이, 특정한 간격을 가지고 프레임들을 고르고, 골라진 프레임들을 이용합니다. 역시 이 논문에서도 그렇게 하는데요. 여기서는 0.5초당 1프레임씩을 선정해서 프레임을 뽑습니다. 그리고 여기서는 이 프레임들을 Xecption이라는 모델로 feature를 추출하는데요.
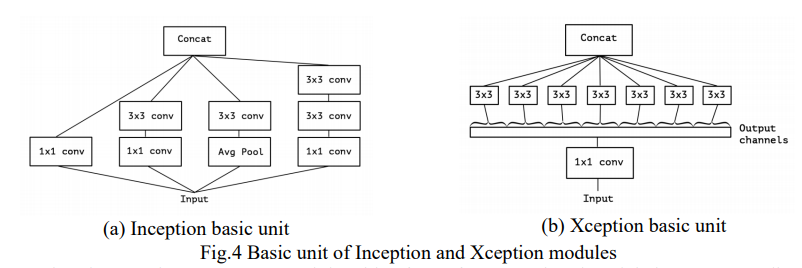
구글에서 Inception이라는 모델을 제안했는데, 해당 모델의 경량화된 버전이라고 합니다. 일단 이 구조는 spatial correlation과 channel correlation을 개별적으로 학습하는 모델을 경량화 했다고 합니다.
그러면 일반적으로 비디오 검색의 문제점 중에서 모델이 무겁기 때문에 연산 속도가 오래 걸리는 문제는 해결했고, 다음 문제가 feature 크기가 크다는 것입니다. 그 문제를 해결하기 위해 이 논문에서는 hash layer라는 레이어를 output layer와 Global Average Pooling 사이에 추가했습니다.
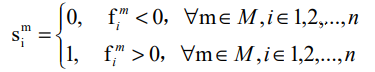
이 레이어는 위와 같은 연산을 수행하는데요. n이 비디오 프레임의 갯수이고, M이 hash layer의 뉴런 갯수이고, f가 hash layer의 출력값 일떄, S는 hash vector라는 값이 나오게 되는 연산 수식입니다. 위와 같은 수식을 통해 binary feature로 데이터베이스 비디오들의 feature를 저장해서 저장 공간과 연산 속도를 아낄 수 있습니다.
Index and Hamming Embedding
검색 속도는 inverted file structure를 통해 개선합니다. 그리고 Hamming embedding을 사용했습니다. 둘 다 visual search 관련 논문을 리뷰하면서 설명했던 적이 있는 것 같은데요. Hamming distance를 이용하면 지금 feature가 binary hash feature 이기 때문에 유사도를 쉽게 계산할 수 있습니다.
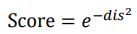
Hamming distance가 통제 가능한 범위 내에서 작동하기를 원했기 때문에 실제 유사도는 위와 같이 계산했다고 합니다.
Feature matching and time alignment
이 논문에서는 기존의 방법론들의 “match first and then align”을 버리고 동시에 수행해야 한다고 주장합니다. 그러기 위해서
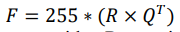
위와 같은 변환 공식을 통해 R(데이터베이스 비디오의 프레임)과 Q(쿼리 비디오의 프레임)을 cosine correlation matrix F로 변환을 합니다. 이렇게 하면 시계열 정보와 matching 정보가 복사된 비디오의 관계를 표현할 수 있다고 합니다.
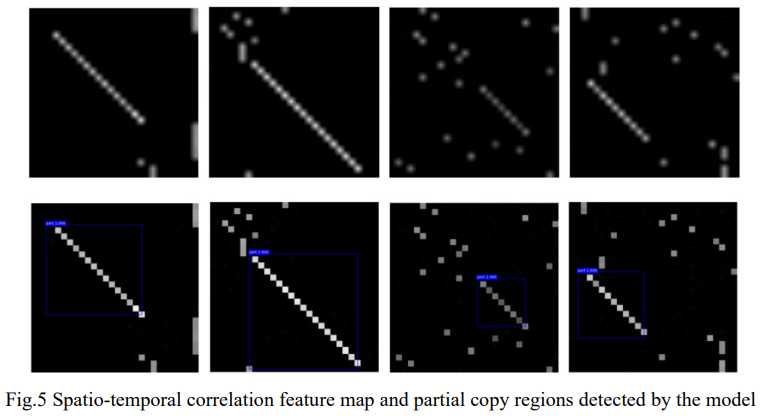
이 F 행렬의 원소들은 Q와 R에 의해 계산된 단위 벡터의 코사인 값들이므로, 각 값은 Q와 R의 해당 프레임의 유사도를 0부터 1까지로 나타내는 값이 됩니다. 위의 그림이 해당 F의 예시입니다. 이 F에서 대각선으로 길게 이어지는 흰색 부분이 Q와 R의 일치하는 영역입니다.
글의 서두에 detector를 붙였다고 말씀드렸는데요. 그 detector가 RefledDet이고, VCDB에 있는 GT를 이용해서 이러한 일치 관계를 알아낼 수 있도록 학습했다고 합니다.
Experiments
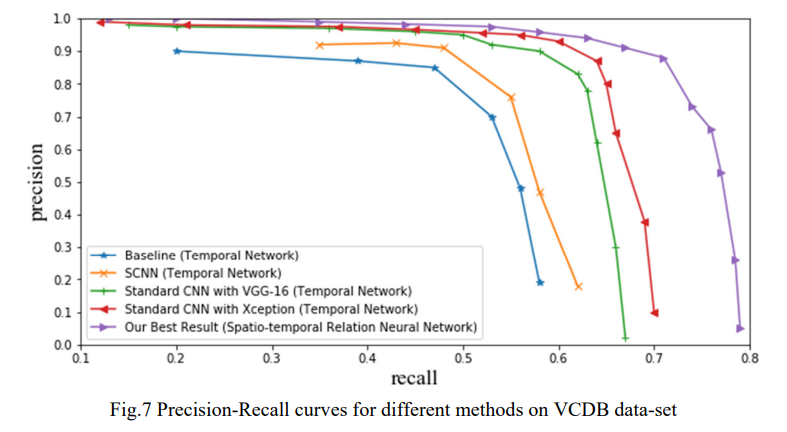
실험 결과는 위와 같습니다. 사실… 이러한 alignment 연구가 그리 활발한 편은 아니라 Temporal Network라는 방법론과의 비교만 있습니다. 전반적으로 논문 저자가 주장한 대로 딥러닝 방법론으로 alignment를 수행해도 성능이 만족스럽게 나온다는 것은 알 수 있지만 논문 자체가 그리 신뢰가 되지는 않네요.
Conclusion
평소에 쓰는 것 보다 리뷰가 엄청 짧게 끝났는데요. 내용들이 다 어디서 가져온 내용(모델 설명, detector 설명 등등)이라 짧게 끝났네요. 사실 이 논문은 “Learning Segment Similarity and Alignment in Large-Scale Content Based Video Retrieval”에서 이 논문의 정렬 방법론을 가져와 사용했기 때문에 제가 이번에 맡은 논문 작업에서 사용할 수 있지 않을까 해서 읽었습니다만… 논문에 오타도 있는걸 보니 그렇게 썩 신뢰가 가지는 않습니다. 그래도 Similarity Matrix를 잘 구한 다음, alignment 영역은 detector를 붙여서 찾는 방법론은 괜찮다고 생각하여 잘 써먹어보려고 합니다.
리뷰 잘 읽었습니다. binary feature 로 저장하는데 성능이 좋아서 신기했네요.
Xception 모델이 feature 를 추출할 때 temporal correlation 을 고려한다는 말은 없는 것 같은데, ‘temporal’ alignment 니까 temporal 정보까지 고려해서 feature 를 뽑으면 더 성능이 좋지 않을까? 라는 생각이 들어 질문 남깁니다. 해당 논문에서 temporal correlation 을 고려하는 다른 모델을 사용하지 않고, Xception 모델을 선택한 이유가 있을까요?
음… 결국 이 유사도가 frame by frame으로 비교하는 거라서, 프레임 끼리의 temporal correlation을 고려하더라도, 비디오 레벨 feature를 사용하는게 아니라면 딱히 큰 의미는 없지 않을까 싶습니다. 물론 프레임 내에서의 correlation은 고려합니다만, Xception은 모델 속도와 spatial correlation때문에 선택했다고 생각합니다.