이번에 소개드릴 논문은 CVPR2021 에서 발표된 Super resolution(SR)에 관한 논문입니다. 일단 이 논문을 찾게된 이유에 대해 먼저 말씀드리겠습니다. 전 현재 Thermal영상을 이용해서 Depth 를 생성하거나 RGB를 생성하는 연구를 지속적으로 진행하고 있고, 전부 Pixel level estimation을 하는 방법인 이 두가지 테스크에 Contrastive learning을 도입하고 싶었습니다. 따라서 전 최근에 pixel level estimation에서 contrastive learning 이 어떻게 사용되고 있나 서베이 하여 찾게 되었습니다. 물론 읽으면서 제가 찾던 방향과는 다른 방식과는 다르지만 그래도 SR의 최근 동향을 알게 되어 좋았던것 같습니다.
- Introduction
이 논문에서 다루고 있는 SR의 문제점은 degradation 입니다. 이 degradation은 SR에서 빼놓을 수 없는 문제입니다.(물론 저도 이 논문을 읽으며 알게 되었습니다…^^) CNN의 발달 이후 SR에서 또한 CNN을 사용하려는 움직임이 많았고 SR에 CNN을 적용한 많은 방법론이 나왔습니다. 하지만 CNN의 학습방식에는 입력과 입력에 해당하는 정답값이 있어야하는데, 이 SR에서는 pair가 맞는 두가지 정보를 얻는게 쉽지않았습니다. 처음에는 실제 영상의 크기를 bicubic interpolation으로 단순이 low resolution (LR) image로 만들어서 입력으로 사용했지만 이렇게 강제로 줄인 방식으로 학습된 모델은 실제 환경에서의 LR과의 갭이 커서 정상동작하지 않는 문제가 발생했습니다.
위와 같은 문제를 해결하기위해서 모델을 이용해 LR을 예측하는 방법론이나 LR과 SR을 동시에 예측해서 학습하는 방법, 그리고 iterative kernel correction 이라 해서 아래 그림 우하단과 같이 반복적으로 degradation의 kernal을 추정하며 성능을 올리는 방식이제안되었습니다.(이 IKC가 base 방법론 같습니다.)
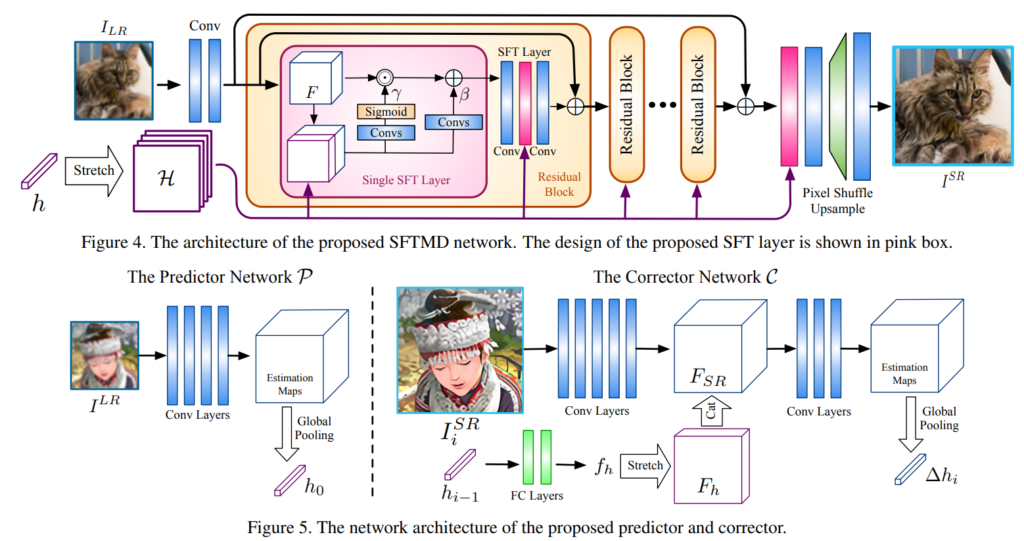
그림 1 가장 이해가 안갔던 부분이 분명 degradation은 HR 영상이 없어서 HR을 LR로 만드는 과정이라고 알고 있는데, 왜 같자기 LR에서 vector를 만들고 그걸 네트워크에 넣느냐 였으며 이글을 읽는 분 또한 그렇게 생각하실 것 같습니다. 그래서 열심히 찾아본 후 얕은 지식으로 유추해 봤습니다. 먼저 이 차이를 알려면 LR이 어떻게 정의됐는지를 아셔야합니다. LR은 HR에서 LR로 interpolation 되고 어떠한 미지의 blur가 있다고 가정합니다. 이 blur를 예측하면 정확한 LR이 생성되며 이 blur를 가 그림 1에서 1-D vector가 됩니다. 따라서 그림 1 속 degradation은 영상의 blur를 예측하는 서브 모델이라 생각하면 되지 않을까 유추하고 있습니다.
기존의 Degradation을 예측하는 방법론이나 그림 1과 같은 방법론은 test time 에 굉장히 오랜 시간이 걸린다는 단점이 있다고 합니다. 따라서 이 논문에서는 기존에 degradation을 예측하는 방식과 아예 다르게 그림 2와 같이 contrastive learning을 활용했습니다.
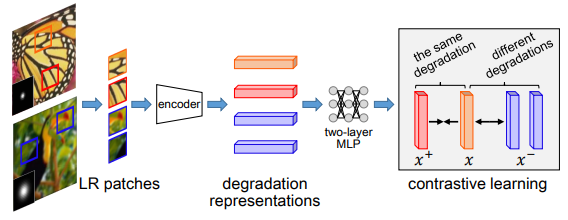
contrastive learning을 활용해서 degradation을 예측할 경우 이점이 두자기가 있는데 그 두가지는 다음과 같습니다.
- 추상적인 vector 공간에서 degradation을 비교하기 때문에 더욱 다양한 예측이 가증해지며, 이건 실제 test time에서도 이점으로 작용한다.
- Groundtruth degradation이 필요없다.
이렇게 이논문에서는 Degradation을 예측하는 새로운 방법을 제안하며, 예측된 degradation을 활용해 SR image를 에측하는 Degradation aware SR (DASR) network도 같이 제안하여 실제 환경에서도 강인하게 SR을 예측하는 전체 framework를 제안합니다.
2. Method
LR image는 다음과 같은 식으로 정의됩니다.
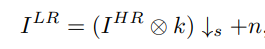
이 식에서 k(blur kernel)이 degradation을 통해 예측하는 값이며 이걸 예측해야 실제 LR과 같은 LR을 학습에 사용하는 효과를 얻을 수 있습니다.
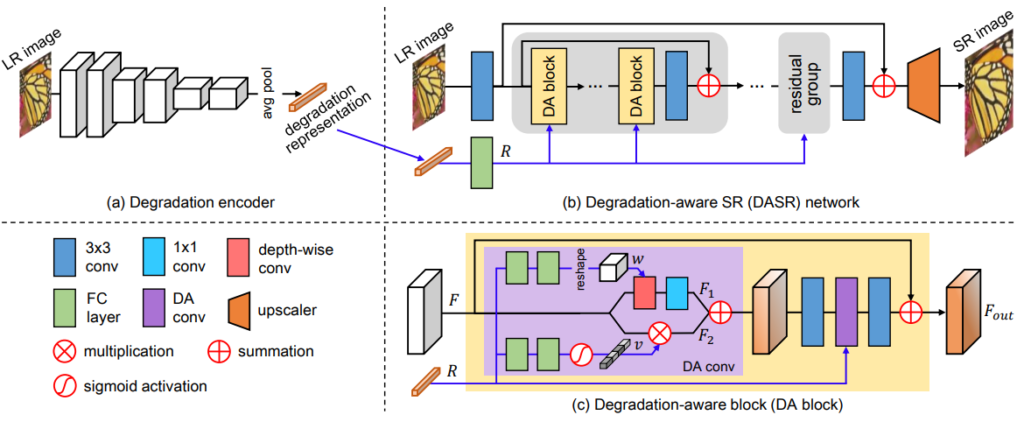
이 논문에서 제안하는 SR의 전체 framework는 그림 3과 같습니다. 먼저 (1)LR image로 부터 degradation을 예측하는 모델을 학습하며, (2)그 후에 예측된 degradation과 LR을 입력으로 SR image를 예측합니다. 그럼 두 가지 과정을 나눠서 살펴보도록 하겠습니다.
(1) Degradation Representation Learning
이 부분이 이 논문의 알파이자 오메가라 할 수 있는 부분입니다. LR image로 부터 degradation을 예측하는 모델을 학습하는 것입니다. 학습 방식은 그림 2와 같이 contrastive learning을 도입하여 동일한 이미지 속 patch에서는 동일한 degradation vector를 만들어내며 다른 영상의 degradation vector와는 다르도록 학습합니다. 먼저 degradation 즉 영상의 blur 값은 영상의 모든 영역에서 동일해야하며 다른 영상의 blur와는 차별성이 뚜렷해야합니다. 이러한 degradation의 특성과 contrastive learing의 의 가깝게하고 싶은 건 가깝게하고 멀리하고 싶은 건 멀리한다는 학습 방식이 매우 잘 맞아떨어져서 contrastive learning을 선택했다 합니다.
그림 3-(a)와 같이 Conv layer6를 이용해서 degradation을 예측하며 MoCo v2[1] 에서 제안된대로 2개의 MLP를 태워서 patch level로 vector를 얻는다고 합니다. 그리고 학습에 사용된 contrastive learning loss는 MoCo[2]에서 제안된 InfoNCE loss를 사용했습니다. 따로 이걸 사용한 이유를 말하진 않아서 제가 MoCo가 뭔지 간단하게 찾아보았고 설명하면 다음과 같습니다.
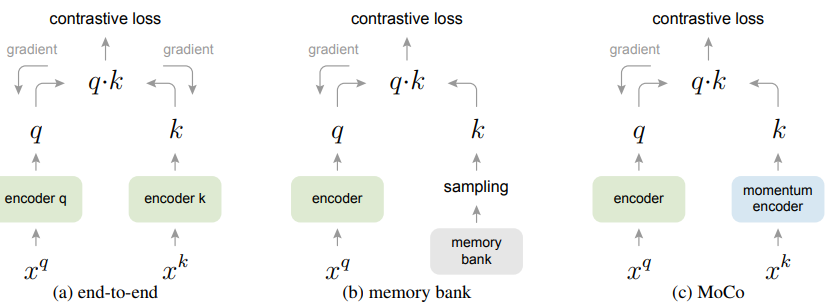
Contrastive loss를 최대한 활용하려면 많은 수의 negative sample가 필요하고 negative sample의 encoder는 query encoder과 consistent 해야 합니다.
end-to-end 방법은 mini-batch내에 존재하는 sample들을 negative sample로 활용하는데, 많은 negative sample을 사용하려면 computational limit가 발생합니다. memoty bank 방식은 많은 양의 negative sample을 활용할 수 있지만 encoder가 update 됨에 따라 encoded된 negetive sample은 갱신이 되지 않습니다. MoCo의 핵심아이디어는 (1) negative representation을 저장하는 queue, (2) key encoder의 mementum update 입니다.
이 논문에서 제안하는 Contrastive learning을 활용한 degradation 예측 방식은 pixel level로 degradation을 예측하는 기존 방식하고는 다르지만 성능이 매우 좋다는걸 뒤에서 입증했다고 합니다.
(2) Degradation-Aware SR Network
LR 영상에서 SR 영상을 생성하는 네트워크는 그림 3-b에 나타나있는데요. 요기서 중요한 것은 DA(degradation -aware ) block 입니다. 이 block을 통해서 domain gap차이가 있는 image feature와 degradation vector를 잘 융합할 수 있도록 만들었다고 합니다. DA 속에는 degradation vector와 합쳐지는 branch가 두개 존재하는데요. 이렇게 두가지로 나눈이유는 [3]에서 관측한 “convolutional kernels of models trained for different restoration levels share similar patterns but have different statistics” 때문이라하는데 아직 이해를 하지 못해서 이글을 읽는다면 저걸 이해하고 저에게 알려주시길 바랍니다…흐흐. 하나의 branch에서는 depth wise convolution으로 연산을 수행하며, 다른 한 branch에서는 channel-wise feature adaption을 수행해서 중요한 feature를 강조하게 됩니다.
Experiments

Ablation study 및 기존 방법론과 속도차이입니다. 기존 방식(Kernal GAN)은 degradation을 예측하는데 매우 오랜 시간이 걸리는것을 볼 수 있으며 그것과 비교해서 oours는 매우 빠른 속도를 보입니다. (perdictor또한 굉장히 빠른데 이것에 대해서 찾는 중…)
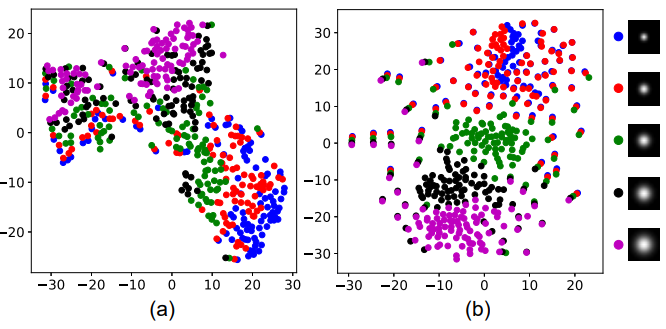
contrastive learning을 하고(b) 안하고(a)를 나타낸 사진 입니다. blur kernel에 따라서 확실히 contrastive learing을 한 것이 매우 유사한 feature를 보입니다.
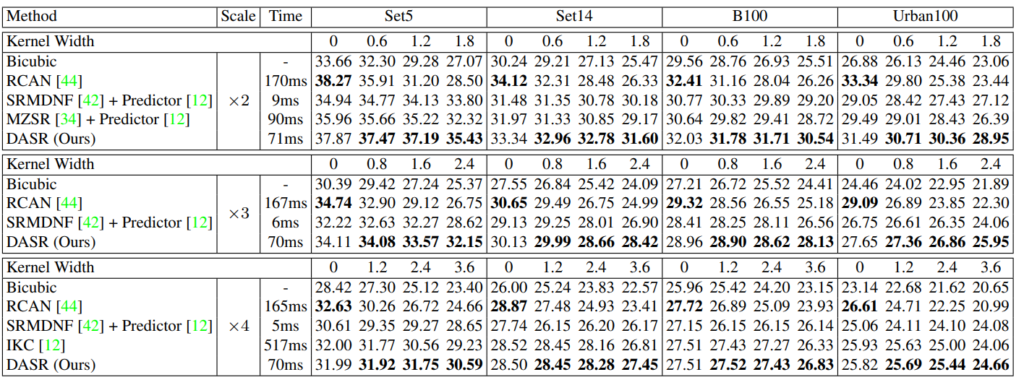
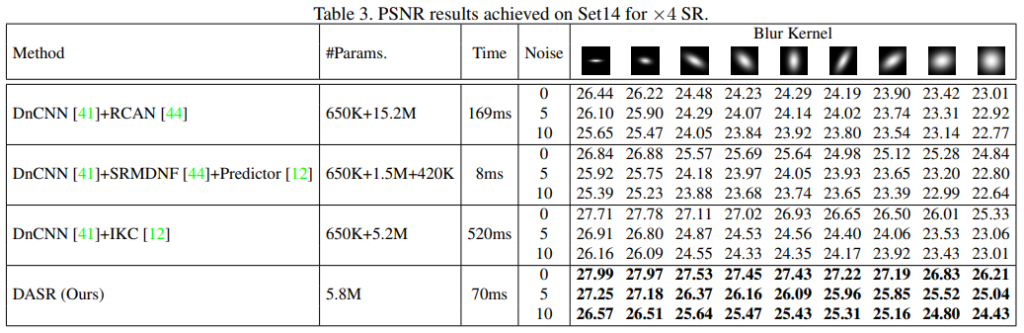
속도와 성능 모두 기존 방법론 대비 높은 성능 향상을 보이는 것을 알 수 있습니다.



정성적 결과 역시 기존 방법론 대비 높은 SR image를 만들어내는 것을 볼 수 있습니다.
Reference
[1] Xinlei Chen, Haoqi Fan, Ross Girshick and Kaiming He, Improved Baselines with Momentum Contrastive Learning
[2] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, Ross Girshick, Momentum Contrast for Unsupervised Visual Representation Learning
[3] Jingwen He, Chao Dong, and Yu Qiao. Modulating image restoration with continual levels via adaptive feature modification layers
재미있는 논문 소개 감사합니다.
그림 1의 일차원 벡터가 blur에 대한 예측값이라고 소개해주셨는데, 이미지 블러의 위치정보를 나타낼 수 있는 2D 벡터가 아닌 일차원 벡터를 이용하는 이유가 따로 있나요? 또한 그림 2의 degradation vector가 그림 1의 일차원 벡터와 같은 의미로 이해하면되나요?
convolutional kernels of models trained for different restoration levels share similar patterns but have different statistics 가 혹시 단순히 서로 다른 병렬 네트워크의 결과를 합쳐 더 큰 표현력을 지니기 위함이라고 해석될만한 여지가 없나요?