Abstract
- Multi-modal 분야의 Video-Text Retrieval 을 위한 CLIP4Clip 이라는 end-to-end 모델을 제안합니다.
- 본 논문의 메인 아이디어는, 기존의 image-language pretraining 모델인 CLIP 을 video-language 분야로 knowledge transfer 한 것입니다.
- similarity calculator 를 세 가지 타입으로 디자인했고, 여러 실험을 통해 분석합니다.
- 추가로, 당시에 CLIP4Clip 모델은 여러 video-text retriveal datasets (MSR-VTT, MSVC, LSMDC, ActivityNet, DiDeMo) 에서 SOTA 를 달성했었다고 합니다. (지금은 CLIP2TV, CaMoE 등의 모델이 SOTA 입니다.)
연구 배경 : 기존의 방법론들
우선 Video-text retrieval 의 방법론은 모델의 input 에 따라 크게 2가지로 나뉠 수 있습니다.
- Pixel-level approach
- Raw video 를 input 으로 이용함
- 데이터셋의 video-text 쌍으로부터 적절한 video feature extractor 를 학습할 수 있음
- Feature-level approach
- Frozen 된 video feature extractor 로부터 뽑은 Video feature 를 input 으로 이용함
- 어떤 extractor 를 사용하느냐에 따라 성능이 달라지므로, extractor 에 대한 의존성이 매우 크다는 단점이 있음
Pretrain model 은 주로 Feature-level approach 을 사용해왔습니다. 당연하게도 cost 측면에서는 생각해보면, 원본 비디오를 그대로 사용하는 것보다 용량을 줄인 feature 를 input으로 사용하는 것이 더 효율적일 것입니다. 그럼 정보량이 떨어지니까 성능이 더 떨어지는 거 아닌가? 싶겠지만, 정보가 손실되더라도 (Pixel-level approach 에서는 cost 문제 때문에 사용하기 힘든) 대규모 데이터셋을 사용할 수 있었기 때문에 feature-level 의 pretrain 모델들은 video-text retrieval 문제에서 꽤나 좋은 성능을 얻어왔다고 합니다.
최근에는 Pixel-level approach 를 사용하는 Pretrain model 들도 제안되고 있습니다. 앞서 언급했듯이 video input 의 높은 computational overload를 줄이는 것이 가장 큰 문제였는데, 아래의 방법론들은 이런 방식으로 해당 문제를 해결했다고 합니다.
ClipBERT (2021)
- 하나의 비디오로부터 하나의 clip 또는 여러 개의 short clips 를 sampling 하여 input 으로 사용함
Frozen (2021)
- 커리큘럼 학습 방식을 사용해서, 쉬운 데이터인 싱글 프레임부터 어려운 데이터인 멀티 프레임까지 input 으로 사용함
그러나, 본 논문은 방금 언급한 두 모델들처럼 video-text 데이터셋으로 pretrain 시킨 새로운 모델을 제안하려는 것이 아닙니다.
본 논문의 핵심 아이디어는, image-text retrieval 을 위해 학습된 CLIP 모델을 video-text retrieval 로 knowledge transfer 하려는 것입니다.
이 아이디어를 채택해서 제안한 모델이 Contrastive Language-Image Pretraining For video Clip, CLIP4Clip 입니다. 논문 읽는 내내 생각한 건데 이름 되게 멋있게 지은 것 같습니다…! 이 다음에는 CLIP 논문에 대한 리뷰도 해볼 생각입니다. 우선 해당 모델의 프레임워크부터 살펴보겠습니다.
Framework of CLIP4clip
주어진 데이터
- a set of videos (or video clips) : \mathcal{V} = \{v_1, v_2, ..., v_N\}
- v_i = \{v^1_i, v^2_i, ... , v^{|v_i|}_i \} (이 때, v_i 는 a sequence of frames)
- a set of captions : \mathcal{T} = \{t_1, t_2, ..., t_N\}
모델의 학습 목표
- 주어지는 데이터를 이용하여 videos 와 captions 간의 similarity function s(v_i, t_j) 를 학습하는 것
- 이때 similarity score 는 relevant 한 video-text pairs 면 높게, irrelevant 한 pairs 면 낮게 나와야 함
- 이를 이용하여 query 가 주어졌을 때 references 와의 similarity 를 계산하여, score 에 따라 references 의 rank 를 매기는 video-to-text retrieval, text-to-video retrieval 문제를 풀 수 있음
CLIP4Clip 모델은 이를 위해 text encoder, video encoder, similarity calcuatior 로 구성되어 있습니다.
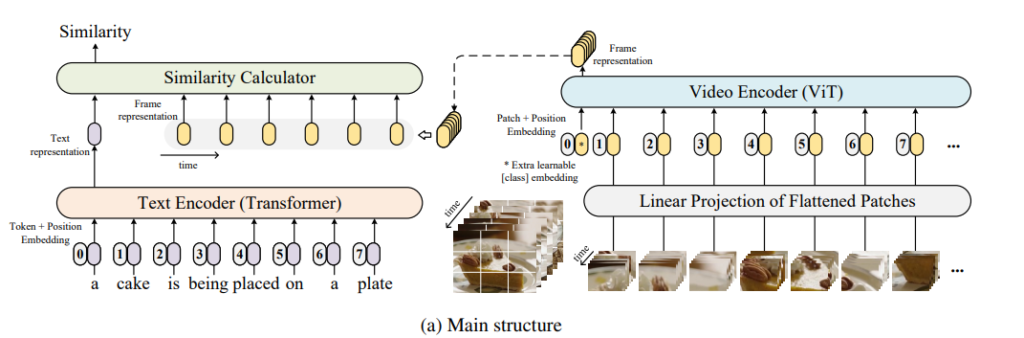
Video Encoder
CLIP4Clip 은 ViT-/32 를 Video encdoer 로 이용했습니다. 즉, pretrained CLIP(ViT-/32) 을 backbone 으로 사용하여 image representation 을 video representation 으로 transfer 한 것입니다.
- Video clip 으로부터 frames 를 extract 한다.
- Video Encoder 로 frames 를 encode 하여, a sequence of features 를 얻는다.
- ViT 는 frames 에서 9개의 non-overlapping image patches 를 extract 한 후, a linear projection 을 통해 1D tokens 로 만든다.
- 1D tokens으로 transformer 를 이용하여, 각 patch 간의 interaction 을 모델링하여 final representation 을 얻는다.
요약하자면, 아래와 같은 video representation 을 얻게 됩니다.
- input (a sequence of video frames) : v_i = \{v^1_i, v^2_i, ... , v^{|v_i|}_i \}
- output (generated representation) : Z_i = \{z^1_i, z^2_i, ... , z^{|v_i|}_i \}
이때 두 가지 종류의 projection (2D linear, 3D linear)를 사용하고 비교해보았는데, 2D 는 frames 간의 temporal information 을 무시하기 때문에 temporal feature extraction 을 enhance 시키기 위해 3D 를 도입했습니다.

Text Encoder
CLIP4Clip 은 text encoder 를 CLIP 에서 가져왔습니다. 즉, Transformer 의 구조를 살짝 바꿔서 사용합니다.
- input (a caption) : t_j \in \mathcal{T}
- output (generated representation) : w_j
Similarity Calculator
- Video representation (frames represenation) : Z_i = \{z^1_i, z^2_i, ... , z^{|v_i|}_i \}
- Caption representation : w_j
두 Encoder 로부터 Video-text representation 을 얻었습니다. 이에 대한 similarity function s(v_i, t_j) 을 학습하는 것이 모델의 목표였습니다.
CLIP 모델은 원래 pre-trained image-text model 입니다. 따라서 video-text 에 대한 similarity calculator module 을 위한 새로운 learnable weights 를 추가해야 합니다. 그래서 본 논문에서는 3가지 접근 방식을 디자인하고 비교했습니다.
Parameter-free approach
- 새로운 parameter 를 도입하지 않는 방식입니다.
- Video representation (frames representation) 을 mean pooling 을 이용해 aggregate 하여, average frame representation을 얻고, 이를 video representation 으로 사용합니다.
- \hat{z_i} = mean-pooling(z^1_i, z^2_i, ... z^{|v_i|}_i)
- similarity function 은 cosine similarity 를 이용합니다.
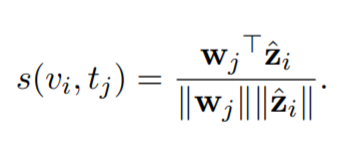
Sequential type
- 위와 같이 mean-pooling 을 하는 경우, frames 간의 temporal 정보를 잃게된다는 단점이 있었습니다.
- 따라서 Sequential feature 를 얻기 위해 2가지 방식을 사용하여 temporal 정보를 embed 하고, 그 이후에 mean-pooling 을 적용하여 video representation 을 얻습니다.
- LSTM : \hat{Z_i} = LSTM(Z_i)
- Transformer encoder (with position embedding P) : \hat{Z_i} = Transformer-Enc(Z_i + P)
- \hat{z_i} = mean-pooling(\hat{Z_i})
- similarity function 는 cosine similarity 입니다.
Tight type
- 이 방식은 video-caption 간의 multimodal interacion 을 위해 Transfomer Encoder 를 사용합니다.
- caption representation 과 frames representation 을 concat 한 fused feature 를 encode 한 후, a linear layer 를 이용해 similarity 를 predict 합니다.
- fused feature : U_i = [w_j, z^1_i, z^1_i, ... , z^{|v_i|}_i]
- \hat{U_i} = Transformer-Enc(U_i + P + T)
- P : position embedding
- T : type embedding (BERT 모델에서 도입. two types : caption embedding, video frames embedding)
- similarity function 은 아래와 같습니다. (이때, \hat{U_i[0, :]} 는 마지막 레이어의 첫번째 토큰 ouput)
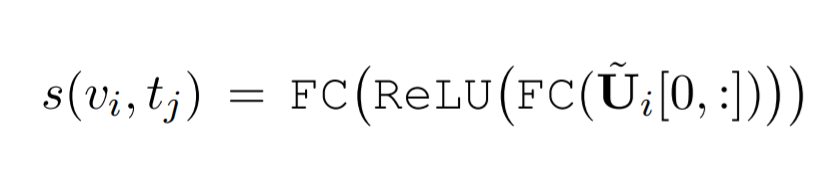
Training Strategy
Loss Function
(video, text) 또는 (video clip, text) 로 구성된 batch B 가 주어졌을 때, 모델은 B x B similarities 를 구하고 최적화해야합니다. CLIP4Clip 은 아래와 같은 symmetric cross entropy loss 를 사용하여 학습합니다. (video-to-text, text-to-video)
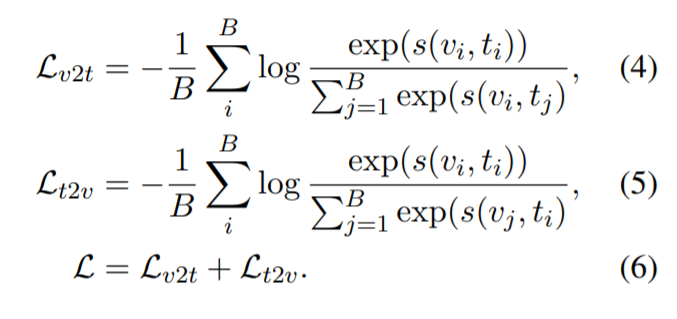
Frame Sampling
pixel-level approach 로 raw video 를 input으로 받아서 사용하니까, features 를 뽑을 때 사용할 frames 를 선택해야 합니다. information richness와 computational complexity 는 서로 trade off 관계 이므로, 어떤 샘플링 전략을 사용할지 정하는 것은 중요합니다. (관련 실험으로는 frame lengths 와 different extraction positions 에 대해 진행했습니다.)
CLIP4Clip 은 uniform frame sampling strategy 를 사용했고, sampling rate 은 1 fps 입니다.
Pretraining
CLIP4Clip 모델은 Howto100M dataset 으로 post-pretrained 되었습니다. 해당 video-text dataset 의 양이 매우 많기 때문에, 그 중 Food and Entertaining 카테고리에 대해서만 행하였습니다. 이 과정은 image 에서 visual concepts 를 잘 학습하는 CLIP 의 knowledge 를 video 쪽으로 transfer 하기 위함이었습니다.
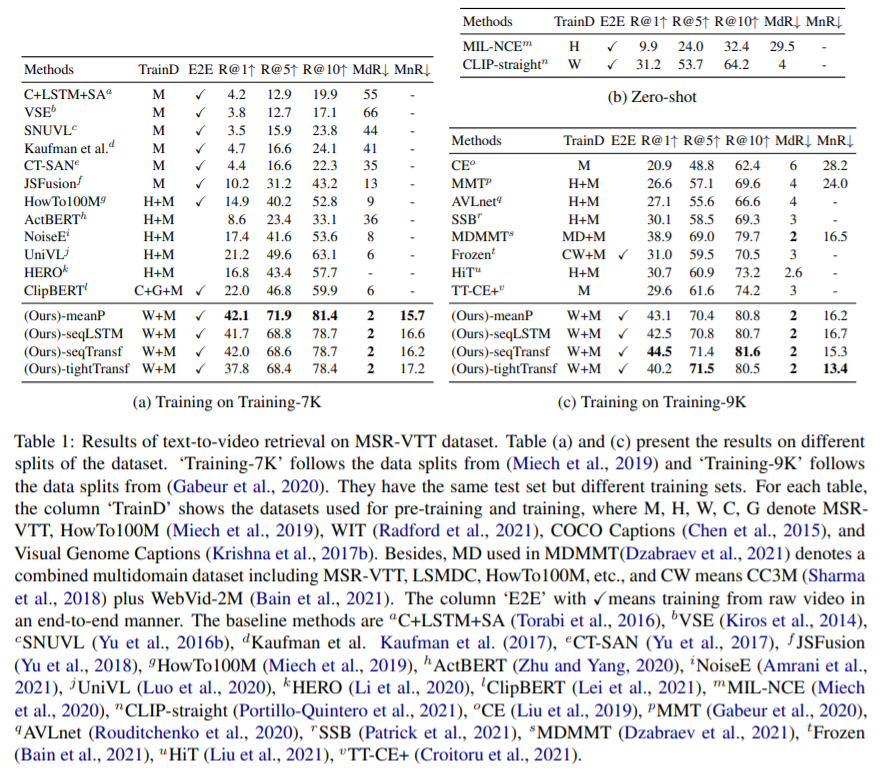
Methods 는 (Ours)-(types of similarity calculator) 이고, 해당 table 은 text-to-video 에 대한 결과입니다.
7K에서는 meanP (parameter free) type 의 성능이 가장 좋았고, 9K 에서는 seqTransf 와 tightTransf 의 성능이 좋았음을 알 수 있었습니다. 이를 통해 small dataset 에서는 새로운 parameter 를 추가하지 않는 것이 좋고, large dataset 에서는 새로운 parameter 를 도입하는 것이 학습에 더 효과적이라는 것을 알 수 있었습니다. 그 이유는, 추가 parameter 가 pretraiend weight 에서 멀어져서, 그 weight 로부터 이득을 보지 못하는 것을 을 방지하기 위해서는 더 큰 데이터 세트가 필요하기 때문이라고 이해된다고 합니다. 다른 데이터셋들도 비슷한 경향을 띄며, 대부분의 경우 tightTransf type 이 성능이 가장 안 좋은 calculator 였다고 합니다. 그리고 이 이유는, tight type 은 데이터셋의 야이 충분하지 않으면, cross-modality interaction 을 학습하는데 어려움을 겪기 때문이라고 보여졌습니다.
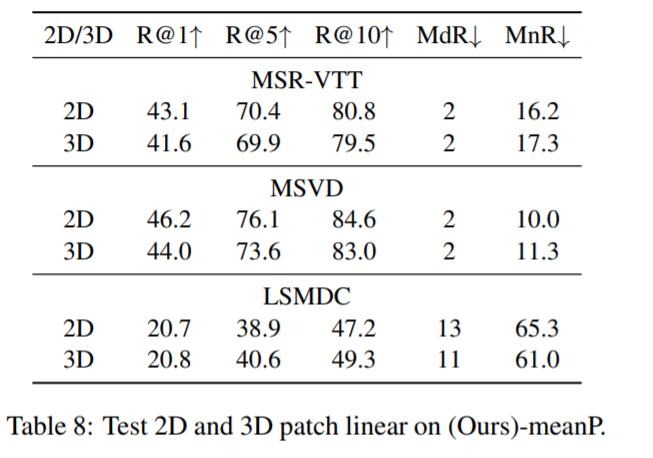
본 논문에서는 3D patch linear 이 temporal information 을 frames 로부터 잘 뽑아서, performance 가 언제나 더 좋아질 거라고 생각했었는데, MSR-VTT 와 MSVD 데이터셋에서는 2D 가 더 좋았다고 합니다.
저자는 CLIP 이 2D linear 에서 학습되었기 때문에, 초기화를 무시한 3D를 사용하는 것은 temporal info 를 학습하는데 어려움을 겪기 때문이라고 말했습니다.
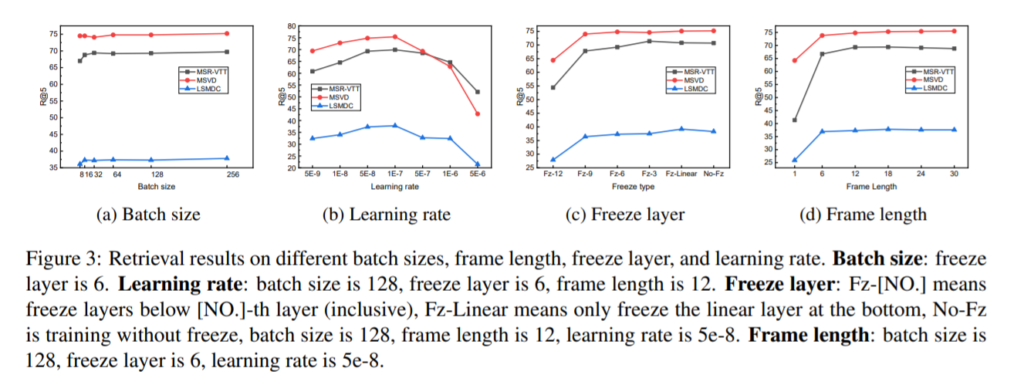
Hyper parameters 에 대한 experiments 를 진행하여 최적의 세팅을 알아내기도 하였습니다. 이때, learning rate 에 따라 성능이 많이 떨어지는 경우도 있는데, 해당 모델이 lr 에 sensitive 하다는 것을 알 수 있었고, lr를 너무 작거나 너무 크게 선택한 경우, 성능이 떨어질 뿐만 아니라 pre-trained weight 로부터 받는 advantage 를 이용하지 못하게 됨으로 보여집니다.
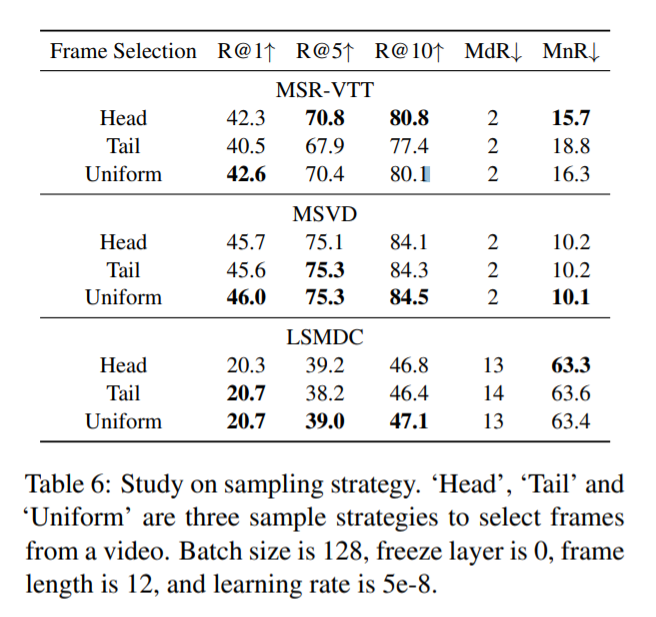
그 외에도 sampling 을 하는 전략으로 head, tail, uniform 방식을 비교하기도 하였습니다. 이를 통해 uniform 을 선택했습니다.
Conclusion
본 논문은 frame-level input 으로 video clip retrieval 문제를 해결하기 pretrained CLIP 을 backbone으로 사용하는 CLIP4Clip 모델을 제안했습니다. 또한 세 가지 타입의 similarity calculator 를 사용하여 비교했습니다.
실험을 통해, 경험적으로 아래와 같은 insight 를 얻었습니다.
- video-text retrieval 에서 image feature 는 쓸 만하다.
- image-text pretrained CLIP 을 post-pretrain 하는 것은 video-text retrieval 의 성능을 올릴 수 있다.
- retrieval task 에서, 3D patch linear projection 과 sequential type similarity 를 사용하는 접근 방식이 효과적이다.
- video-text retrieval 을 할 때, CLIP 은 learning rate 에 sensitive 하다.
CLIP 로부터 파생된 모델들이 sota 인게 많아서, 계속 보이니까 읽고 싶은… 그런 상태였습니다. 아마 당분간은 multimodal 관련해서, 특히 video-text 관련된 걸 많이 읽을 것 같네요. 이상으로 리뷰 마치겠습니다.
비디오 representation과 텍스트 representation이 서로 다른데 유사도를 어떻게 계산하는지 궁금했는데, 비디오를 임베딩해서 처리하는 것으로 생각하면 되겠군요. 근데 Tight type 유사도 계산에서 T는 왜 필요한가요? 이비 fused feature로 하나의 feature로 합쳐서 트랜스포머의 입력값으로 넣는 것으로 이해했는데, 왜 타입을 알려줘야하는지 모르겠습니다. 추가적으로 Tight type 의 유사도가 결국은 FC layer의 결과값이 되는데, cosine simliarity같이 하나의 유사도 값으로 나오나요?
1. Tight type 유사도 계산에서 T가 필요한 이유
우선 fused feature 는 단순히 text representation 과 video representation 을 합쳐놓은 상태입니다.
이 feature 에 type embedding 과 position embedding 이 적용한 후에 transformer 의 입력으로 넣게 됩니다.
fused_feature = [w, z1, z2, …. zN] 이면
embeddings = type_embeddings + position_embeddings
= [0, 1,1,1, … 1] + [0,1,2,3,4,… N]
= [0, 2, 3, … N + 1] 입니다.
이때 type_embedding 은 text 면 0, video 면 1을 더해줌으로써 최종으로 embedding 하고 나면 token sequence 가 불연속적이라는 것을 알 수 있게 됩니다. 이 type_embedding 이 T 입니다.
그래서 T 덕분에 각 토큰이 text 로부터 만들어진 것인지, video frames 로부터 만들어진 것인지 구분할 수 있으므로, transformer 가 각각을 잘 나타내도록 학습하게 돕는 역할을 합니다.
(bert 에서도 [sep] token 이 있어서, sentence A 와 B 를 구분하도록 embedding 을 학습했었는데, 비슷한 역할이라고 보시면 될 것 같습니다!)
2. 네 하나의 유사도 값으로 나옵니다!
이때 fc layer 는 nn.Linear(hidden_size, 1) 형태입니다.