Before Review
이번에도 Weakly Supervised Temporal Localization 논문을 들고 왔습니다. 2020년도 AAAI에 나온 논문이고 반가운건 한국인이 저자인 논문이네요. 네이버 클로바와 연세대학교 연구진이 같이 작성한 논문인 것 같습니다.
최근 논문을 수정하면서 비디오의 Background를 어떻게 처리해야 되나 고민이 많은 상황인데, 이 논문이 참고할만한 Filtering module를 제안한 논문이라 읽게 되었습니다. Method나 실험 부분이 어렵지 않아서 가볍게 읽었습니다.
리뷰 시작하도록 하겠습니다.
Introduction
Weakly supervised temporal localization은 비디오 단위의 라벨만을 가지고 Localization을 수행하는 작업으로 상당히 어려운 task라 볼 수 있습니다. 사람들이 Weakly supervised temporal localization에 관심을 가지는 이유는 Annotation의 문제라고 제가 항상 얘기를 했습니다. 특히나 저자가 주장하는 Fully supervised 방식의 어노테이션이 가지는 문제점은 다음과 같이 요약할 수 있습니다.
어노테이션이 1) expensive 하며, 2) subjective 하고 3) error-prone 하다 이렇게 주장하고 있습니다. 아마 expensive 하다는 것은 모두 공감할 수 있을 거 같고, subjectvie 하다는 것은 action과 background간의 경계를 어떻게 정의할 지 조금 애매한 감이 있어 subjective라고 표현한 것 같습니다. error-prone 하다는 의미는 역시 사람이 수행했기 때문에 제대로 안된 부분도 조금 있겠죠. 당연한 말인 것 같지만 인지를 하고 있는 것과 아닌 것은 차이가 있기 때문에 저자가 얘기를 한 것 같습니다.
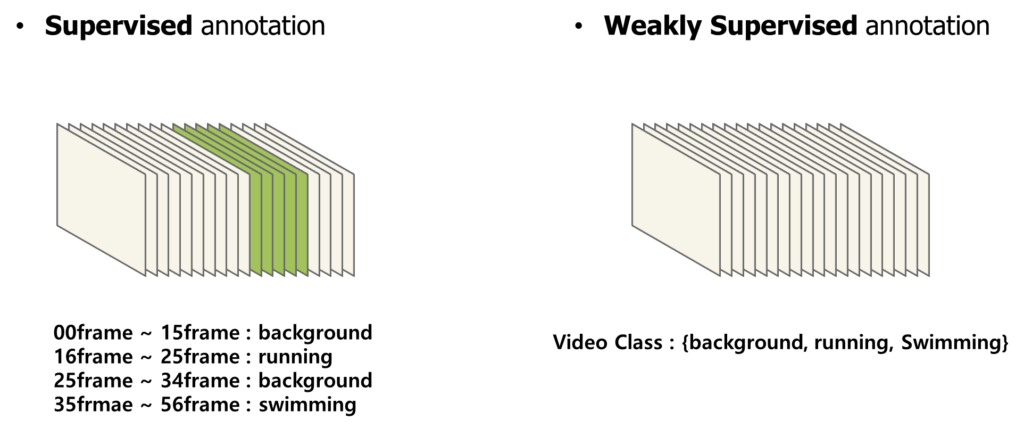
Weakly Supervised 일반적인 방식은 frame 단위로 action의 종류를 예측한 뒤 이를 시간 순서에 따른 Sequence Map을 만들어 Class Activation Sequence(CAS)를 만들어냅니다. 그리고 잘 aggregation하여 video level의 label을 예측할 수 있는 video level score vector를 만들어줍니다.
여기서 중요한 것은 이전까지의 Weakly Supervised Temporal Localization(WTAL) 방법론들은 Video의 Background에 대한 별다른 처리를 하지 않았고 오로지 Action Class만 고려한 학습을 진행했습니다. 이렇게 되면 Background frame들도 action으로 분류가 되며 결국 Localization 성능을 떨어트리게 됩니다.
이에 저자는 Background를 담당할 auxilary class를 만들어 총 C+1개의 클래스를 가지고 WTAL을 진행하는 framework를 제안합니다.
또한 효과적인 학습을 위해 Filtering module을 통해 비디오의 Background를 Suppression할 수 있는 장치를 제안합니다. 간단하지만 저의 논문 연구에 시도해볼 법한 아이디어인 것 같습니다.
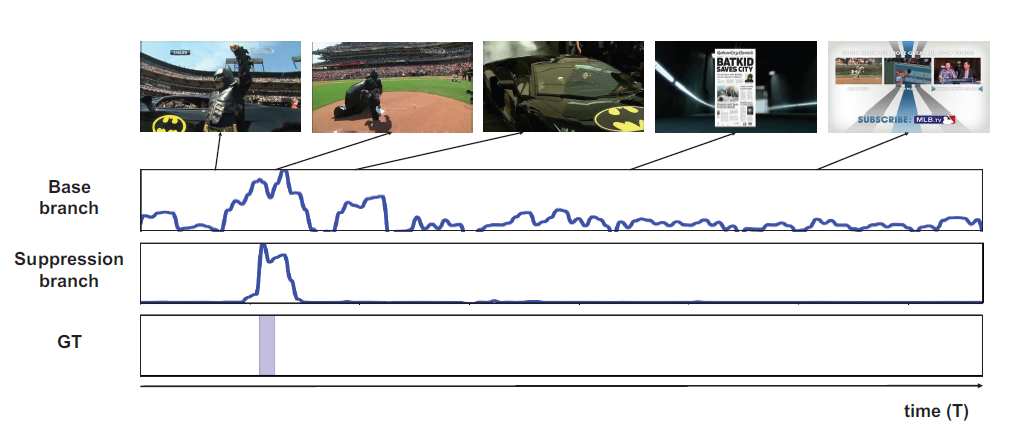
Background를 고려하지 않은 방법이라면 저렇게 CAS를 보았을 때 action 구간이 아닌 곳에서도 activation이 조금씩 발생하는 것을 알 수 있습니다. 하지만 저자가 제안한 background suppression 방식을 적용하면 action 구간에만 activation이 발생하고 나머지 구간에서는 activation이 suppression 된 것을 그림으로 보여주고 있습니다.
방법론 설명에 들어가기에 앞서 저자가 제안한 이 방법에 대한 contribution을 정리하고 가겠습니다.
- WTAL에서는 고려되지 않았던 Background를 최초로 auxilary class로 고려해 처리를 해주었다.
- Filtering module을 제안해 background frame으로 부터 나오는 activation들을 suppression할 수 있는 방법론을 제안하였다.
- THUMOS’14와 ActivityNet에서 WTAL SOTA를 달성하였다.
Method
Problem Formulation
우리에게 주어지는 데이터 자체는 N개의 비디오가 존재하는 학습 데이터와 \{ v_{n}\}^{N}_{n=1} 그들의 video-level 라벨 \{ y_{n}\}^{N}_{n=1} 이 존재합니다.
기본적으로 WTAL 방법론은 Class Activation Sequence(CAS)를 만들어 video-level score를 담당할 single vector를 만들어주는 구조를 취하게 됩니다. CAS를 만들 때 frame-level feature를 aggregate 하는 방식이 있고, segment-level feature를 aggregate하는 방식이 있습니다. 본 논문에서는 segment-level feature를 aggregate하여 사용해주고 있네요.
이제 하나의 비디오 v_{n}가 들어왔을 때, 고정된 프레임수를 사용하는 non-overlapping segment를 만들어줍니다. 또한 비디오는 가변적인 길이를 가지고 있기 때문에 마찬가지로 segment의 갯수 역시 고정된 T개만을 sampling하여 사용합니다.
하나의 segment에 대해 RGB feature와 optical flow feature를 concat하여 사용하는 방식을 사용하기 때문에 segment의 feature dimension은 R^{2F}로 표기하고, 비디오에는 T개의 segment가 존재하니, X\in R^{2F\times T}인 CAS를 얻을 수 있습니다.
이러한 정보를 가진채 우리는 Temporal Localization을 해보도록 하겠습니다.
Background Class
Introduction에서도 얘기했지만, 저자가 정의했던 문제는 바로 Background class 없이는 background frame들의 activation이 action class를 향해 발생한다는 점입니다. 모델이 학습 하는 입장에서는 당연히 noise로 작용하겠죠. 따라서 부정확한 localization으로 이어질 수 밖에 없습니다.
단순히 CAS를 생성할 때 background class를 만들어내는 것은 사실 문제가 아닙니다. 컨볼루션 연산을 하거나 선형 레이어를 거칠 때 반환되는 출력 차원을 하나 더 만들어주면 끝입니다. 이렇게만 하면 문제가 해결이 될까요?
우선적으로 Temporal Localization에서 사용하는 데이터셋은 Untrimmed Video로 구성되어 있습니다. Untrimmed Video라는 것은 비디오 내부적으로 background가 존재하는 것을 의미합니다. 모든 학습 비디오는 Untrimmed video이기 때문에 Background class에 대해서는 모든 학습 비디오가 Positive하다고 볼 수 있습니다. 따라서 Class Imbalance가 발생하며, background class에 대한 비디오의 CAS는 항상 높게 나올 수 밖에 없습니다.
별다른 장치 없이는 자명해에 도달할 확률이 높다고 해석하면 되겠습니다. 저자는 이러한 문제를 해결하기 위해 Suppression branch내의 filtering module 제안하여 해결하고 있습니다. 자세한건 조금 뒤에 다루도록 하겠습니다.
Background Suppression Network (Bas-Net)
논문의 전체 구조를 보여주는 그림입니다. 두개의 branch로 나뉘어져 있지만 동일한 parameter를 share하는 구조라 보면 됩니다. 사실 architecture는 정말 간단합니다. 하나씩 설명해보겠습니다.

Base Branch
Base Branch에서는 Video-level classification을 수행하는 곳이며, CAS와 top-k aggregation을 사용하는 전형적인 WTAL의 방식을 접목한 구조 입니다. 제가 이전 WTAL 리뷰에서도 많이 다뤘던 내용이긴 하지만 비디오에 관심이 없는 분이라면 그래도 잘 모를 수 있으니 다시 한번 설명하도록 하겠습니다.
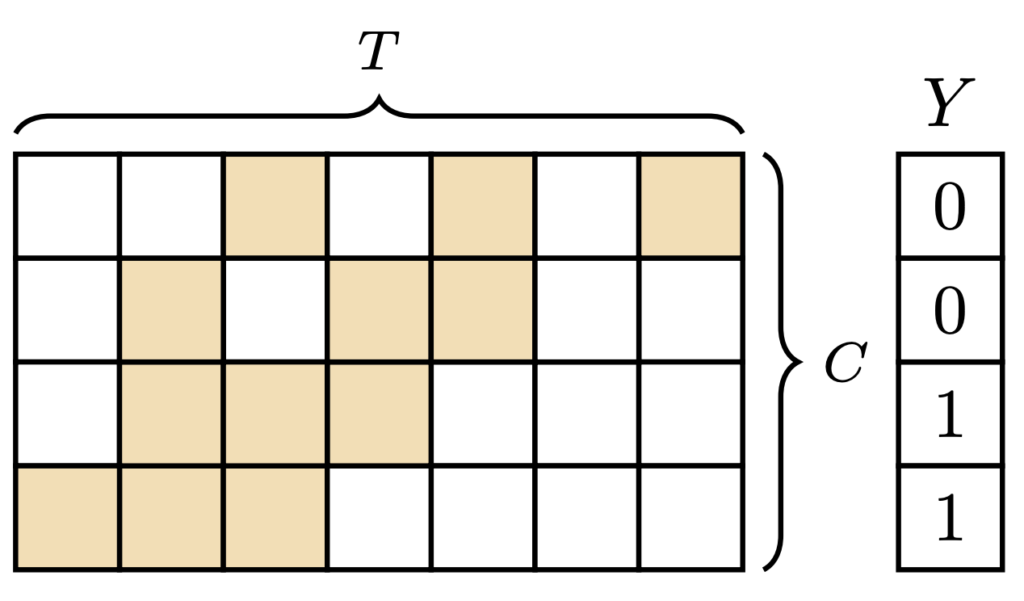
T개의 Segment Feature에 대해 우리는 Class activation Sequence(CAS)을 1D convolution이나 Linear Layer를 통해서 얻을 수 있습니다. 위의 그림을 가지고 설명을 해보면 총 7개의 Segment가 존재하고 4개의 Class가 존재합니다. 각 Segment feature를 가지고 1D convolution 연산을 통해서 얻은 Vector를 Activation map이라 볼 수 있습니다. 당연히 우리는 그 Vector의 차원을 C로 투영을 시켜야겠죠.
이러한 과정을 T개의 Segment에 전부 동일하게 진행할 수 있겟죠. 이걸 하나의 Sequence로 묶어준 것이 Class Activation Sequence(CAS)입니다. 각 Class별로 이제 Video-level score를 얻어야 할 것 같습니다. 각 Class 별로 모든 Segment의 activation score를 고려하는 것이 아니라 Top-k개의 score만을 고려해줍니다. 이러한 방식은 직관적으로 action일 확률이 그나마 높을 애들만 사용해서 optimization을 하겠다라는 의도로 볼 수 있습니다.
그래서 각 class별로 top-k aggregation을 한 후, top-k score를 평균하여 각 class에 대한 video-level score로 사용합니다. 그림에서 보면 노란색으로 칠해진 부분들의 score를 평균하여 video-level score를 생성했다고 생각하면 됩니다.
그렇게 얻은 score vector와 정답 label간 cross entropy loss를 통해 video-level classification task로 network를 optimization 할 수 있습니다.
- A_{n}=f_{conv}(X_{n};\phi )\in R^{(C+1)\times T}
Backbone Network를 통해서 나온 feature X_{n}를 입력으로 받아서 1D convolution layer들을 거친후 CAS를 만들어주는 모습입니다.
- a_{n;c}=aggregate(A_{n},c)=\frac{1}{k} \max_{A\subset A_{n}[c,:],\mid A\mid =k} \sum_{\forall a\in A} a
위에서 설명 했던 것 처럼 비디오 레벨 score를 만들기 위해 top-k aggregation 후 평균을 취해 score를 계산하고 있는 상태입니다.
- p_{n}=softmax(a_{n})
- L_{base}=\frac{1}{N} \sum^{N}_{n=1} \sum^{C+1}_{c=1} -y^{base}_{n;c}\times log(p_{n;c})
결국 video안에 어떤 action들이 존재하는 지 맞추는 분류 문제이기 때문에 cross entropy loss로 학습이 가능합니다.
- y^{base}_{n}=[y_{n;1},\ldots ,y_{n:C},1]^{T}\in R^{C+1}
이때 우리가 사용하는 정답값은(C+1)차원의 벡터로 background class는 항상 1로 고정되어 있습니다. 왜냐하면 학습 비디오가 모두 untrimmed video로 background를 모두 포함하기 때문입니다.
Suppression Branch
Base Branch와 다른 점은 Filtering module이 들어갔다는 점 입니다. 이 Filtering Module의 목적은 Background Segment Feature에 Weight를 주어서 0에 가깝도록 만들겠다는 의도라 보면 됩니다. 그림에서 볼 수 있듯 시간 차원에 해당하는 vector를 만들어줍니다. 이 vector는 foreground weight라고 해서 segment feature가 foreground 영역에서 나온 feature라면 1에 가까운 값을 반대로 segment feature가 background 영역에서 나온 feature라면 0에 가까운 값을 가지는 vector 입니다.
Filtering Module은 두개의 1D convolution layer로 구성되어 있고, 그 사이 사이 Sigmoid layer를 사용해 출력값을 0~1 사이로 mapping 시켜주는 간단한 구조를 가지고 있습니다.
- W_{n}=f_{filter}(X_{n};\theta )\in R^{T}
W_{n}라는 foreground weight를 가지고 이제는 입력 feature와 temporal 축에 대하여 element-wise product를 수행합니다. 이게 무슨 의미냐면 전체 Segment 중에서 Background에 해당하는 Segment의 feature는 값을 0에 가깝게 만들어 activation을 줄이겠다는 뜻으로 볼 수 있겠습니다.
- X^{\prime }_{n}=W_{n}\otimes X_{n}\in R^{2F\times T}
어떻게 보면 Foreground attention이라 볼 수 있는 이 과정은 feature level 단에서 진행이 되며 새롭게 얻어진 feature를 가지고 동일하게 video-level classification을 진행합니다. 다만, 여기서 생각해야 할 부분은 비디오 라벨입니다.
이상적으로 Background suppression이 잘 되었다면 이 비디오에는 Background라는 Class가 없다고 가정하는 것이 맞습니다. 때문에 Base Branch에서 사용했던 비디오 라벨과 다른 점은 Background class가 없다고 가정한 라벨을 사용해야 한다는 점 입니다.
- y^{supp}_{n}=[y_{n;1},\ldots ,y_{n:C},0]^{T}\in R^{C+1}
즉, Suppression branch에서는 background에 대한 라벨은 0으로 고정이 되어야 한다는 점 입니다.
나머지는 Base Branch와 동일합니다. 이렇게 Suppression Network를 통해 Background에 대한 Negative case를 인위적으로 만들어 학습할 수 있었고, Background의 activation이 action 부근에서는 발생하지 않도록 하여 Localization 성능까지 잡을 수 있었습니다.
최종 Loss 함수는 아래와 같습니다.
- L_{overall}=\alpha L_{base}+\beta L_{supp}+\gamma L_{norm}
해서 foreground attention weight에 대한 L1 normalization term 까지 추가한 것이 전체 Loss입니다.
Classification and Localization
전형적인 CAS 방식의 Inference를 하고 있습니다. 이때 Base Branch를 가지고 하는 게 아니라 Suppression Branch를 가지고 진행합니다. 각 segment에 대해 일정 threshold를 넘기지 못한 segment는 버리고 살아남은 segment들 중 같은 action이고 연속적인 부분을 묶어서 proposal로 만들어줍니다.
Experiments
Comparison with state-of-the-art methods
두가지 데이터셋을 가지고 진행합니다.
THUMOS14 데이터셋의 학습 데이터셋은 trimmed video로 구성되어 있고, action의 길이가 짧은건 10초에서 긴건 100초가 넘어가는 상황이라 비디오 길이에 따른 dramatic한 variation이 있습니다.
ActivityNet 데이터셋의 학습 데이터셋은 untrimmed video로 구성되어 있고 200개의 class를 제공합니다. 200개의 많은 action instance가 있기도 하고 같은 action instance 끼리도 intra-class variation이 높은 편이라 challenging한 dataset 입니다.
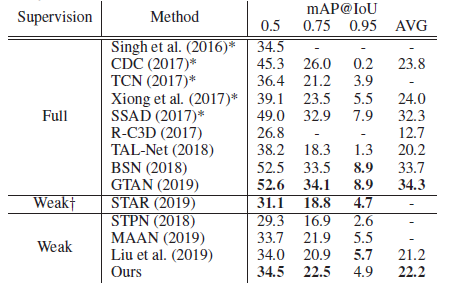
먼저 THUMOS’14 데이터셋에 대한 테이블 입니다.
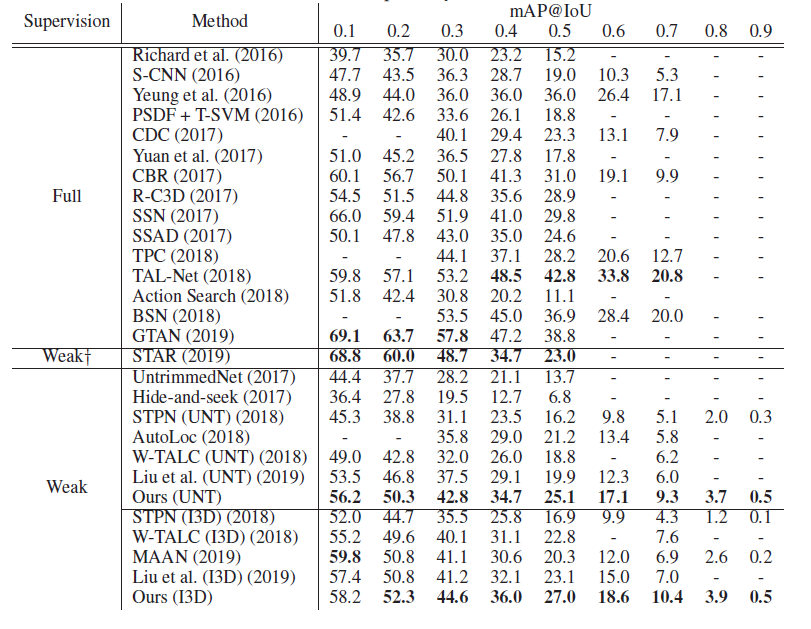
하나 주의해야 할 것은 STAR라고 하는 방법론은 Weakly Supervised 이긴 하지만 Video-level의 label 말고 추가적으로 action-frequency라는 라벨을 사용하였기에 성능이 높다고 볼 수 있습니다. 당연히 Video-level의 label 만을 사용하는 방법론들과의 직접적인 비교는 할 필요 없습니다.
정리하면 두가지 Backbone에 대해서 모두 SOTA 입니다. 방법론이 참 간단한데 SOTA 인걸 보면 역시 비디오는 Background를 잘 처리하는 게 중요한가 싶기도 하네요. 성능이 꽤 높아서 R-C3D라고 17년도에 나온 fully supervised 정도는 이기는 모습을 보여주고 있습니다.
다음으로는 ActivityNet 1.3에 대한 테이블입니다.
마찬 가지로 제일 높은 성능을 보여주고 있습니다. 두가지 공개 데이터셋에 대해서 SOTA를 달성함으로 써 본 논문의 우수성을 입증하였네요.
Ablation Study

ablation study 입니다. Base Branch 만을 사용한다는 것은 일반적으로 WTAL에서 사용하는 TCA를 통한 Multi label classification을 푸는 문제로 보면 됩니다. 여기서 단순히 background class만 사용해주면 성능이 13.4에서 11.3으로 하락 하는 것을 볼 수 있습니다.
이유는 앞서 언급했지만 단순히 background class를 생성해내면 데이터셋의 class imbalance 문제가 생겨 오히려 학습에 방해를 가져다 준다고 했습니다.
여기서 이제 suppression branch를 사용하면 13.4에서 21.2로 성능이 많이 오르는 것을 확인할 수 있습니다. Filtering module을 통해 foreground attention을 수행할 수 있고 이를 가지고 좀 더 정확한 Localization을 할 수 있어 전반적인 성능이 많이 개선되었습니다.
마지막으로 Base branch와 Suppression branch를 모두 사용하면 최고의 성능을 보여주고 있습니다.

또한 Background frame을 detecting 하는 데 있어 F-score를 계산한 결과 suppression branch만을 사용하는 것 보다 jointly하게 사용하는 것이 더 좋은 성능을 보여주고 있습니다.
Qualitative results
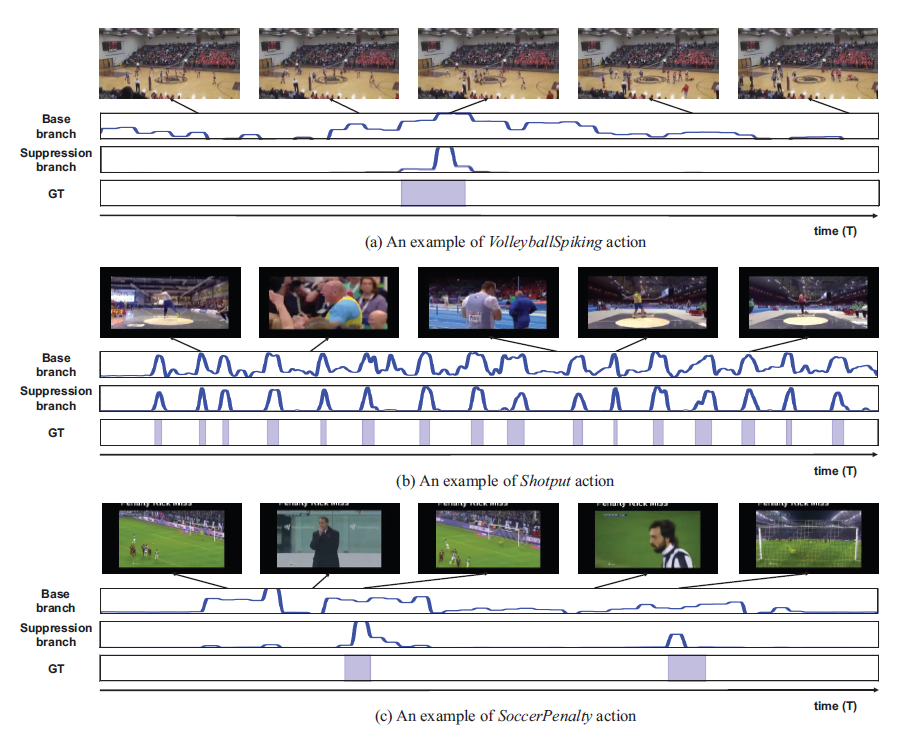
마지막으로 정성적 결과 입니다. Suppression branch로 부터 발생하는 activation이 실제 GT와 매우 유사하다는 것을 보여주고 있습니다.
여기서는 각각 case를 정의해서 설명하고 있습니다.
그림 (a)는 Sparse case라고 해서 human이 작고 action이 sparse하게 등장하는 어려운 케이스라고 합니다. 그럼에도 잘 잡고 있네요.
그림 (b)는 action이 너무 자주 등장하는 case로 역시나 localization을 어렵게 만드는 케이스입니다. 마찬가지로 잘 잡고 있는 경우를 보여주고 있습니다.
그림 (c)는 challenging background case로 비디오의 background가 foreground와 상당히 유사한 케이스를 의미합니다. 이러한 경우에도 Suppression branch가 성공적으로 background를 약화시킨다는 점을 강조하며 본인들 방법이 우수하다고 주장합니다.
뭐 정성적 결과이니 너무 맹신하면 또 안되겠죠.
Conclusion
내용이 짧은 거 같지만, 사실 논문에 나와있는 내용과 실험은 빠짐없이 모두 서술 했습니다. 방법론이 간단하기도 하고 실험이 많지 않아 리뷰도 조금 전체적으로 짧은 감이 있네요.
제가 나중에 참고해서 생각해볼 부분은 Filtering module을 통한 foreground attention 방식을 참고할 수 있을 것 같습니다.
한국에 temporal action localization 연구를 하는 그룹을 만나 반가웠던(?) 논문이었습니다.
리뷰 읽어주셔서 감사합니다.