Before Review
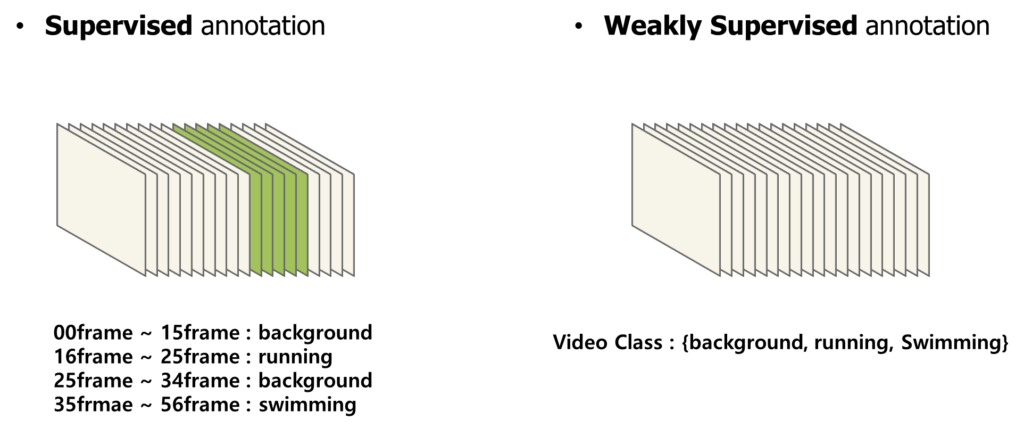
이번 논문 리뷰는 Temporal Action Localization으로 준비했습니다. 그 중 Supervised 방식이 아니라, Weakly Supervised 방식으로 논문을 선택했습니다.
지난 CVPR에 작성했던 논문을 저널로 돌리는데 있어서 insight를 얻고자 논문을 서베이 하던 도중, 괜찮은 논문인 것 같아 일어보게 됐습니다. Motivation 자체는 간단하지만 방법론은 그렇지 않은..? 그래서 이해하는 데 좀 애를 먹은 논문입니다.
TPAMI 저널에 투고된 논문은 처음 읽어보는 것 같은데, 글씨도 작고 내용 자체가 일단 컨퍼런스 논문에 비해서는 좀 많은 편인 것 같네요. 페이퍼 양이 너무 많아 읽는 데 좀 오래 걸렸습니다 따라서 내용도 고봉밥으로 담았습니다.
리뷰 시작하도록 하겠습니다.
Introduction
사람들이 Weakly supervised temporal localization에 관심을 가지는 이유는 언제나 Annotation의 부담 때문이라고 한결같이 얘기합니다. Weakly supervised temporal localization은 비디오 단위의 라벨만을 가지고 Localization을 수행하는 작업으로 상당히 어려운 task라 볼 수 있습니다.
일반적인 방식은 frame 단위로 action의 종류를 예측한 뒤 이를 잘 aggregation에 video level의 label을 예측합니다. 따라서 이러한 가정을 하게 됩니다. Video-level label과 연관된 frame들은 일반적으로 action instance일 확률이 높다. 이러한 가정을 가지고 설계된 방법론들은 한가지 문제점에 봉착할 수 있습니다. 논문에서는 이를 action-context confusion이라는 단어로 표현하고 있는데요.
바로 video-level label과 연관된 frame이 사실 알고보면 background frame이라면 모델의 학습이 원할하게 이루어지지 않는다는 점을 지적합니다.
본 논문의 주장으로는 Weakly supervised temporal localization을 하는 데 있어 가장 큰 이슈는 Background modeling이라고 합니다.

기존의 몇몇 베이스라인 방법론들을 활용하여 위의 통계값을 얻었다고 합니다.
위의 그림(a)를 보면 Weakly Supervised Temporal Localization을 하는데 있어 발생하는 에러 중 Background Error가 가장 큰 비율을 차지하고 있습니다. 저 통계를 어떻게 얻었는지 까지는 설명을 해주고 있진 않지만, 저 정도의 비율을 차지 한다는 것이 꽤나 흥미로운 지표인 것 같습니다.
그림 (b)를 보면 Top-k에 해당하는 frame의 종류를 보여주고 있습니다. Top-k라 함은 frame 단위로 action의 종류를 예측한 뒤 video level의 예측을 수행하기 위해 각 action 별로 score가 높은 top-k의 frame만을 선택하게 됩니다. 결국 action-instance를 찾는 관점에서 봤을 때는 top-k에 해당되는 프레임들이 action-instance를 많이 포함할 수록 예측 성능이 좋다고 볼 수 있겠죠. 저 통계가 시사하는 바는 다음과 같습니다.
첫번째 Background로 부터 발생하는 에러가 상당한 비중을 차지한다.
두번째 베이스라인 자체만으로도 일단 top-k에는 action instance를 포함하는 frame들이 어느정도 존재한다.
이러한 상황에서 저자는 Background-Click Supervision을 제안합니다.
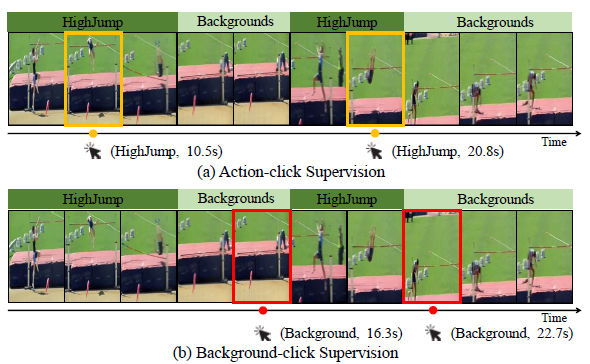
단일 프레임 단위로 어노테이션을 진행하는 것인데, 기존의 Click-Supervision의 방식은 Action인 순간을 가지고 annotation을 진행했습니다. 위의 그림 중 노란색으로 칠해진 부분이 Action-click supervision으로 HighJump를 수행하는 몇몇 순간을 알려주고 있습니다.
Background-click supervision은 반대로 background인 순간을 알려주는 것이죠. 예를 들어 비디오 A가 있을 때 비디오 A의 16.3초와 22.7초는 확실히 background야! 이런식으로 말입니다.
자 그러면 갑자기 click-supervision이라는 것은 왜 등장하였냐면, 우선 모든 frame 단위로 annotation을 하는 것은 이전에도 언급한 것 처럼 상당한 시간과 비용이 발생합니다. 모든 frame을 어노테이션 하는 것이 아니라, 그 중 몇몇 프레임만 마우스로 클릭하듯 어노테이션을 하는 것은 사실 그렇게 fully supervised 어노테이션 보다는 비용이 덜 발생하게 됩니다.
Weakly Supervised localization 자체가 너무 어렵다 보니, 단순히 Video level의 label만을 가지고는 Background 문제를 해결할 수 없기 때문에 Video level label + some annotated frames 로 접근해보자 이거입니다.
적어도 어디가 background인지 알려줄 수 있는 최소한의 정보를 따로 제공해보자 이거 입니다.
그렇다면 왜 Background-click supervision이냐? 기존의 방법은 Action-click supervision인데 저자는 왜 반대로 제안을 하는지 궁금할 수도 있습니다. 위에서 관측한 두 가지 사실을 통해 저자는 다음의 motivation을 얻습니다.
첫번째 Background로 부터 발생하는 에러가 상당한 비중을 차지한다.
두번째 베이스라인 자체만으로도 일단 top-k에는 action instance를 포함하는 frame들이 어느정도 존재한다.
즉, 성능의 bottleneck이 발생하는 부분은 background이고, action에 집중 안해도 그럭저럭 학습이 잘 될 것이다. 이에 대한 근거는 top-k에 action 비율이 70% 정도에 달한다는 것이 뒷받침 될 수 있겠네요.
따라서 우리는 action 정보를 강화하는 action-click supervision이 아닌, background 정보를 강화시킬 수 있는 background-click supervision을 제안하다. 이렇게 주장합니다.
서론이 조금 길어졌지만, Click-level supervision이라는 생소한 개념이 등장하여 조금 자세하게 설명을 드렸습니다. 지금 부터는 저자가 제안한 방법론에 대해서 자세히 알아보도록 하겠습니다.
Proposed Method
Problem Definition
문제 정의부터 시작해보도록 하겠습니다. 우리에게 주어지는 label 정보와 예측해야 하는 값을 한번 살펴보도록 하겠습니다.
- b=[b_{1},b_{2},\ldots ,b_{T}] 은 action인지 background인지 구별할 수 있게 해주는 label 입니다. T는 비디오의 전체 프레임 갯수로 볼 수 있습니다.
- 초기에 모든 라벨은 b_{t}=-1로 초기화 됩니다. 이때, 우리는 몇몇 background 순간을 알고 있습니다. Click-level로 이전에 annotation을 추가로 했기 때문입니다.
- background frame에 해당하는 프레임은 b_{t}=1로 라벨을 설정합니다.
- 그리고 이제 학습 과정에서 발생하는 top-k 개의 frame들은 confident action frame으로 그나마 action일 확률이 높은 frame들을 의미합니다. 이는 모델이 학습 과정 중간중간에 만들어내는 예측값들이기 때문에 일종의 pseudo label 이라 볼 수 있습니다. 우리는 이 pseudo label을 활용하게 됩니다. 이는 b_{t}=0로 라벨을 설정합니다.
마지막으로 학습 중간중간에 예측하게 되는 output은 \left( t^{s}_{i},t^{e}_{i},c_{i},p_{i}\right)로 action instance의 start point, end point, action class, confidence score로 4개의 값을 반환하게 됩니다.

단순히 글만 보고 상상해보기에는 조금 무리가 있어 위의 그림 예시를 만들어 보았습니다. 갑자기 등장한 저 Matrix는 Class Activation Sequence(CAS)라고 해서, 각 Class마다 프레임의 연속적인 Activation ouput을 담고 있는 정보라 보면 됩니다. 예를 들면 첫번째 Class에 대해 첫번째 프레임은 0.7의 score, 두번째 프레임은 0.3의 score … 이렇게 프레임마다 score를 구했다고 볼 수 있겠네요.
위에서 정리했던 것 처럼 우리에게 주어지는 라벨은 우선 비디오 레벨의 라벨 + 부분적인 frame label이라고 했습니다. T는 frame의 갯수라고 했으니 각 column은 몇번째 인덱스의 프레임인지 나타낸다고 보면 될 것 같습니다. 여기서 첫번째 프레임은 모두 주황색으로 칠해져 있네요. 이 부분이 사람이 직접 어노테이션한 background click이라 하겠습니다.
노란색으로 칠해진 부분은 각 Class마다 score가 높은 top-k개의 frame을 의미합니다. 각 class를 책임질 일종의 후보군이라는 것이죠. 그 class에 confidence score가 다른 frame에 비해 높기 때문에 우리는 잠재적으로 저 frame들을 action instance를 포함한다고 가정할 수 있으며 이러한 가정 아래 top-k 프레임들을 action frame이라고 pseudo labeling 해줍니다.
b=[b_{1},b_{2},\ldots ,b_{T}]이 결국 [1,0,0,0,-1,-1]이렇게 할당 되었네요.
BackTAL Overview
자 위에서 문제 정의는 어느정도 끝난 것 같습니다. Input video feature X가 들어왔을 때, Class Activation Sequence 는 S\in R^{(C+1)\times T}이렇게 정의가 될 것입니다. Video level의 classification을 하기 위해서는 frame level로 흩어진 score들을 잘 aggregate 시켜야 할 것 같습니다.
이를 위해 top-k aggregation이 등장합니다. 목적은 video-level classification score vector를 구하기 위해서겠죠.
- s^{c}_{v}=\frac{1}{k} \max_{M\subset S[c,:],|M|=k} \sum^{k}_{l=1} M_{l}
수식 자체는 복잡해보이지만 간단합니다. 클래스 별로 score가 가장 높은 k개의 프레임을 선택후 k개의 activation score를 평균 내서 video level의 score로 사용하겠다 이거입니다.
즉, s^{c}_{v}는 c번째 class에 해당하는 classification score로 softmax 확률이라 보면 됩니다. 이렇게 Video-level의 classification score vector s_{v}=[s^{0}_{v},s^{1}_{v},\ldots ,s^{C}_{v}]를 가지고 video-level classification을 수행할 수 있을 것 같습니다. A라는 비디오에는 running이라는 action과 swimming이라는 action이 있다 이렇게 말이죠.
- L_{cls}=-\sum^{C}_{c=0} y^{c}log(s^{c}_{v}) : Cross Entropy Loss로 video level classification을 optimization 시켜줍니다.
우리는 여기서 더 나아가 frame level의 classification을 진행할 수 있습니다. 왜냐하면 background-click supervision을 통해 몇몇 background frame의 위치를 알기 때문입니다. 즉 b_{t}=1에 해당하는 frame들만 가지고 이 frame이 Background인지 구분하는 Classification을 frame 단위로 수행한다는 의미입니다.
- L_{frame}=-\frac{1}{N_{frame}} \sum^{N_{frame}}_{t=1} log\left( s^{0}_{t}\right)
N_{frame}는 annotated background frame 갯수를 의미하며 s^{0}_{t}는 background class에 대한 classification score를 의미합니다.
저자는 여기서 그치지 않고 두가지의 추가적인 Module을 제안합니다. Score Speration Module에서는 confident action frame과 annotated background frame을 잘 구분할 수 있게 학습하는 구조를 제안하고, Affinity Module에서는 annotated background frame과 confident action frame간의 embedding distance를 멀게 만드는 방향으로 representation learning을 진행합니다. 자세한 설명은 뒤에 이어서 하도록 하겠습니다.
잠깐 정리해보면 완전한 학습 과정을 이렇게 video-level classification Loss인 L_{cls}와 frame-level classification loss인 L_{frame} 그리고 separation loss L_{sep}와 affinity loss L_{aff}의 joint learning으로 진행됩니다.
- L=L_{cls}+L_{frame}+\lambda L_{sep}+\beta L_{aff}
Score Seperation Module
이 Module에서는 Video-level의 classification을 하는 데 있어 단순한 top-k aggregation의 문제점을 지적합니다. 이를 해결하기 위해 background click-level annotation을 활용한 position information을 강화해 action과 background간 모호한 부분을 구분이 잘 되게끔 설계합니다.
그렇다면 과연 Top-k개의 frame만을 사용했을 때 어떤 문제가 있을 까요? 상대적으로 Top-k에 해당되는 프레임들은 action-instance일 확률이 높습니다. 구조상 Top-k만을 가지고 optimization을 하다보면 action 정보에 bias되기 때문에 상대적으로 background에 대한 대응을 하기 쉽지 않습니다. 학습 과정에 background을 접해본적이 별로 없기 때문에 발생하는 이슈겠죠.
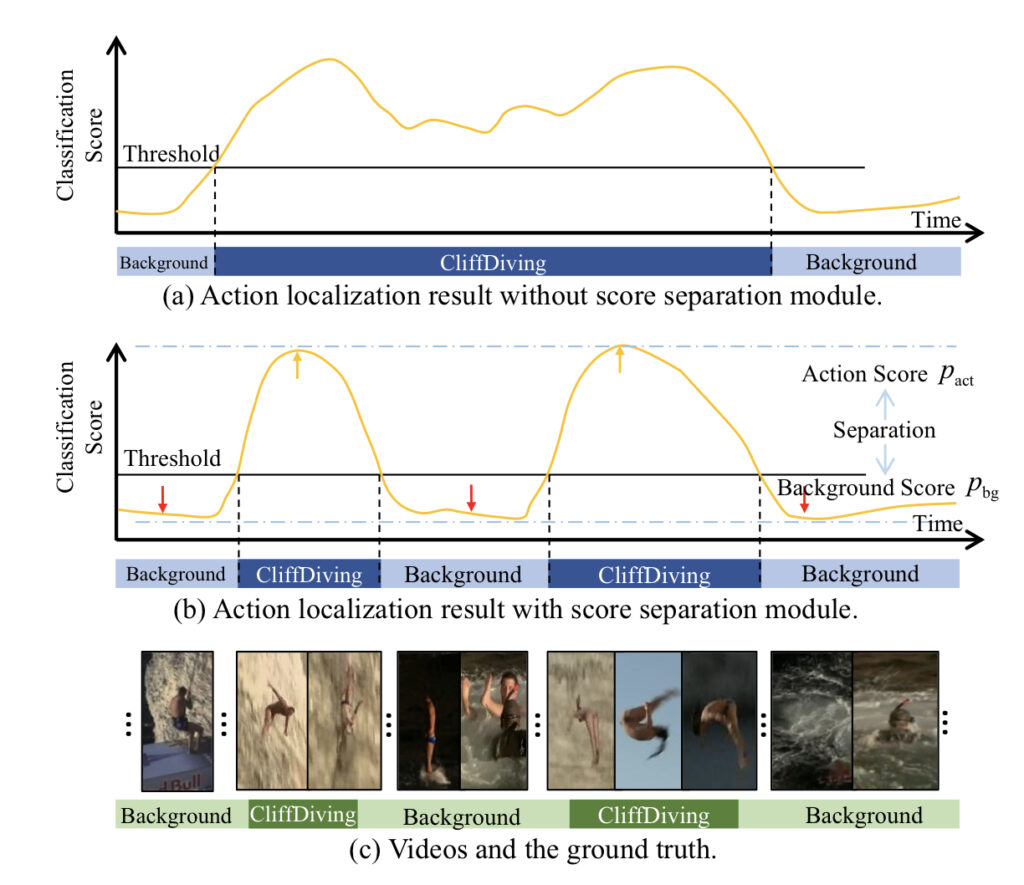
먼저 그림(c)를 보면 Ground Truth가 나와있습니다. GT를 먼저 한번 보고 그림 (a)를 보면 Localization이 조금 아쉽게 되었네요. action과 background에 대한 구분력을 확실히 학습하지 못했기 때문입니다. 그림 (b)는 바로 논문에서 제안한 Score Speration module을 추가했을 때 예측 값 입니다. GT와 거의 비슷한 경향성을 보여주면서 예측을 수행하고 있습니다. 이렇게 background frame에 대한 score를 좀 더 확실하게 suppress하고 action frame에 대한 score를 더 enhance하는 것이 이 모듈의 효과라 볼 수 있겠네요.
어떻게 할 수 있을까요? 예를 들어 Background class에 해당하는 frame일 때는 Background score가 높게 나오는 것이 좋을 것 같습니다. 하지만 Action class에 해당하는 프레임일 때는 Background score가 낮고 나오고, Action score가 높게 나오는 상황이 바람직 하겠네요.
즉, 특정 c^{th} action class에 대해서 고려해보도록 하겠습니다.
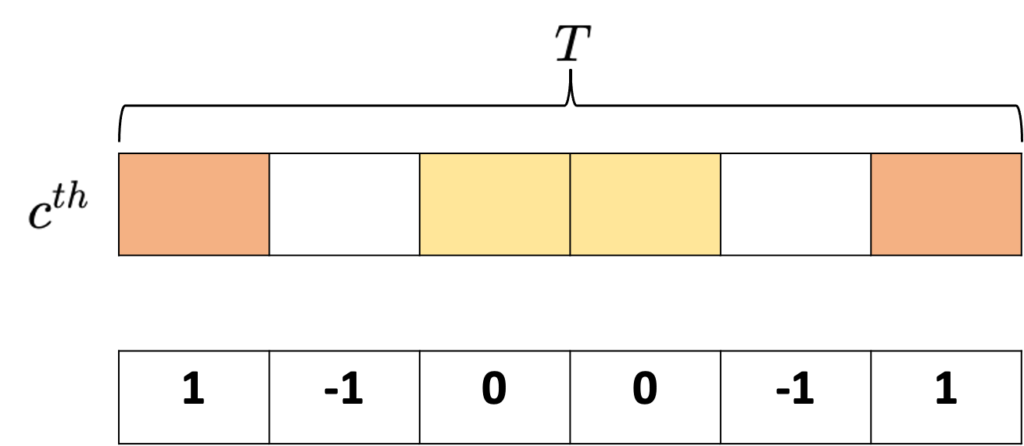
주황색으로 칠해진 프레임들이 click-level로 annotation된 background frame이며, 노란색으로 칠해진 프레임들이 top-k의 potential action frame들 입니다. 여기서 action frame은 action frame끼리 , background 프레임은 background 프레임끼리 mean score를 계산해줍니다.
- p_{act}=\frac{1}{k} \sum_{\forall b_{t}=0} s^{c}_{t}
- p_{bg}=\frac{1}{N_{frame}} \sum_{\forall b_{t}=1} s^{c}_{t}
그리고 action과 background간 상대적인 difference를 더욱 잘 표현하기 위해 softmax normalization을 진행해줍니다. p_{act}, p_{bg}를 0~1 사이의 값으로 만들겠다는 의미겠죠?
- \hat{p}_{act} =\frac{e^{p_{act}}}{e^{p_{act}}+e^{p_{bg}}} ,\hat{p}_{bg} =\frac{e^{p_{bg}}}{e^{p_{act}}+e^{p_{bg}}}
여기까지 왔을 때 다시 한번 우리의 목적을 상기시키겠습니다. 특정 action class에 대해서는 background score가 되도록 작게, action score는 되도록 크게 만드는 것이 목적이었습니다. 따라서 p_{act}이 1이 되도록 그리고 p_{bg}이 0이 되도록 최적화 시킬 수 있는 Loss함수가 있다면 이 Score Seperation module은 잘 학습이 될 것 같습니다.
- L_{sep}=-log(\hat{p}_{act} )-log(1-\hat{p}_{bg} )
Score Seperation module의 Loss 함수는 다음과 같습니다. Loss가 감소하는 방향이 결국 p_{act}이 1이 되도록 그리고 p_{bg}이 0이 되는 방향입니다. 약간 GAN에 등장하는 MinMax Problem이랑 비슷한 것 같네요. 결국 이러한 별도의 seperation module을 통해 모델이 좀 더 background와 action간의 구별력이 생겼다고 볼 수 있고, 이는 Background-click supervision의 도움으로 가능했습니다.
Affinity Module
마지막 모듈입니다. Affinity라고 해서 한글로는 관련성, 유사성 이라는 단어입니다. 이 모듈에서는 video feature의 표현력이 좀 더 좋아지게끔 만드는 것이 목적입니다. 크게 설명하자면 feature embedding 학습과 동시에 attention mask를 만들어 temporal convolution을 좀 더 잘 해보자 입니다.
Feature embedding 학습 부터 살펴보겠습니다. 여기서의 목적은 background feature와 action feature들을 embedding space 상에서 좀 더 잘 구분할 수 있게 representation learning을 하는 것 입니다. 고정된 Backbone Network로 부터 비디오 Feature를 쭉 받아올 수 있겟죠. 그 후 temporal 차원에 대해 1D convolution을 적용하면 embedding feature sequence를 얻을 수 있습니다. E=[e_{1},e_{2},\ldots ,e_{T}],e_{t}\in R^{D_{emb}} 이 때 각 embedding feature는 L2-normalized를 해준다고 하네요. embedding feature 끼리의 유사도는 코사인 유사도를 사용해서 측정한다고 합니다.
- A(e_{u},e_{v})=\frac{e^{T}_{u}\cdot e_{v}}{\parallel e_{u}\parallel_{2} \cdot \parallel e_{v}\parallel_{2} }
그 후 학습 방향 자체는 간단합니다. Background feature 끼리는 모두 유사도가 높게 나와야 하며 Action feature 끼리 역시 유사도가 높게 나와야 합니다. 반대로 Background feature와 Action feature 끼리는 유사도가 낮게 나오게 만들어야겠죠. 이를 위해 세가지 term을 계산합니다.
- L^{bg}_{aff}=\max_{\forall b_{u}=1,b_{v}=1,u!=v} \lfloor \tau_{same} -A\left( e_{u},e_{v}\right) \rfloor_{+}
사실 알고보면 간단한데 이 수식을 해석 하는 게 요 논문에서 가장 어려웠습니다. \forall b_{u}=1,b_{v}=1,u!=v 즉, annotated 된 모든 background frame들에 대하여 유사도를 서로 구했을 때, 어떤 하나의 조합이라도 유사도가 \tau_{same}이 값보다 작다면 Loss가 발생합니다. 결국 모든 background feature 끼리의 유사도는 \tau_{same}를 넘겨야만 Loss가 줄어들게 되고 우리의 목적과도 일맥상통 합니다. 글로 풀어쓰면 간단해보이는 데 논문에는 수식만 덩그러니 나와있고 별다른 설명이 없어 이해하는 데 조금 어려웠네요.
- L^{act}_{aff}=\max_{\forall b_{u}=0,b_{v}=0,u!=v} \lfloor \tau_{same} -A\left( e_{u},e_{v}\right) \rfloor_{+}
마찬가지로 action frame feature 끼리 유사도가 높아질 수 있도록 action frame feature에 대한 term도 계산해줍니다.
- L^{diff}_{aff}=\max_{\forall b_{u}=1,b_{v}=0} \lfloor A\left( e_{u},e_{v}\right) -\tau_{diff} \rfloor_{+}
action feature와 background feature 끼리는 유사도가 낮아질 수 있게 하는 term도 필요할 것 같습니다. 이를 위해 max안의 수식이 반대로 되어있네요. 서로 다른 두 feature 끼리는 \tau_{diff} 보다 유사도가 낮아질 수 있게 만들어주는 term이라 보면 될 것 같습니다.
이렇게 high-quality의 embedding vector를 얻었을 때, 각 frame과 그 이웃된 frame끼리의 feature 유사도를 계산한 attention mask를 만들 수 있습니다. attention mask는 어디에 사용을 하느냐? 바로 temporal 차원으로 1D convolution을 할 때 단순히 공유된 weight를 사용하는 것이 아니라, local position information이 적용된 attention weight를 추가해서 frame-specific한 연산을 진행할 수 있게 만들어줍니다. 이를 통해 action과 confusing background를 구별할 수 있는 능력이 길러진다고 하네요.
전체 프레임의 갯수가 T이고, 이웃된 h개의 프레임끼리 유사도를 구했으니, 유사도 행렬은 a\in R^{h\times T}의 차원을 가지는 Mask라 볼 수 있습니다. 이 이웃된 프레임의 갯수는 사실 temporal convolution kernel의 shape이기도 합니다. 1D convolution이라 shape 자체도 h로 1차원으로 정의가 됩니다.
- \overline{X} [:,t-\left\lfloor \frac{h}{2} \right\rfloor +i]=X\left[ :,t-\left\lfloor \frac{h}{2} \right\rfloor +i\right] \times a[i,t],i\in [0,\ldots ,h-1]
수식이 복잡해보이는데 간단합니다. 1D convolution은 그대로 하지만 한번 filtering을 할 때 마다 그 region에 해당하는 attention mask를 곱해줘서 각 frame마다 다른 weight로 연산이 된다고 보면 됩니다.
단순히 Convolution만 사용해서 embedding feature를 추출 하는 것보다 이렇게 attention을 적용해 보다 더 local한 position 정보를 살릴 수 있다고 합니다.
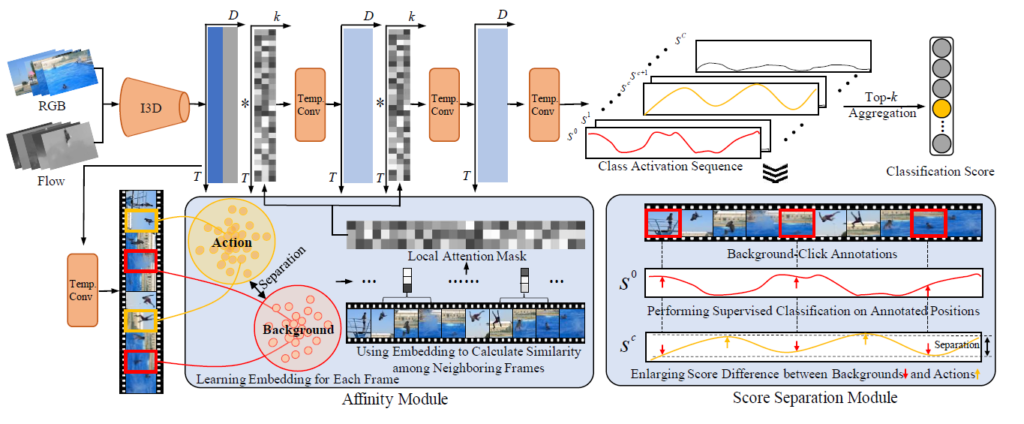
전체적인 구조 입니다. 복잡해보이지만, 글을 열심히 읽었다면 눈에 잘 들어올 것 같습니다.
Inference
Inference 자체는 간단합니다. 모든 것은 class activation sequence(CAS)으로 처리하죠. top-k aggregation을 통해 video-level classification score를 가지는 vector s_{v}를 얻을 수 있다고 했었습니다. 여기서 video level classification score가 일정 threshold를 넘기지 못하는 action category는 전부 버립니다. 마지막으로는 살아남은 frame들 중에서 연속적인 프레임들을 모아 하나의 구간을 만들 수 있겠네요. 각 구간별 confident score는 AutoLoc에 나오는 방식과 동일하게 만들어준다고 합니다.
Experiments
Benchmark Datasets
방법론도 정말 호흡이 길었지만, 실험 역시 만만치 않습니다. 정신 차리고 집중해서 읽어야 실험이 보여주는 의미를 깨닫지 않을 까 싶네요. 데이터셋은 세가지 공개 데이터셋을 활용했다고 합니다. THUMOS14, ActivityNet v1.2, HACS 데이터셋 별로 소개를 하면 너무 길어지니 특징 정도만 정리하겠습니다.
THUMOS14 데이터셋의 학습 데이터셋은 trimmed video로 구성되어 있고, action의 길이가 짧은건 10초에서 긴건 100초가 넘어가는 상황이라 비디오 길이에 따른 dramatic한 variation이 있습니다.
ActivityNet 데이터셋의 학습 데이터셋은 untrimmed video로 구성되어 있고 200개의 class를 제공합니다. 200개의 많은 action instance가 있기도 하고 같은 action instance 끼리도 intra-class variation이 높은 편이라 challenging한 dataset 입니다.
HACS 데이터셋의 학습 데이터셋은 untrimmed video로 구성되어 있고 200개의 class를 제공합니다. 현존하는 benchmarking dataset에 비하여 더욱 realistic하고 challenging한 benchmark dataset 이라고 합니다.
Background-Click Annotation
annotation이 어떻게 진행됐는 지만 간단하게 짚어보고 넘어가도록 하겠습니다. 3명의 숙련된 어노테이터가 독립적으로 어노테이션을 수행했다고 하네요. 서로 중복된 비디오를 annotation 시킨게 조금 특이하긴 하네요. 방식은 Background segment가 등장할 때마다 그 segment안의 프레임을 랜덤하게 하나 선택하는 방식으로 진행했습니다.
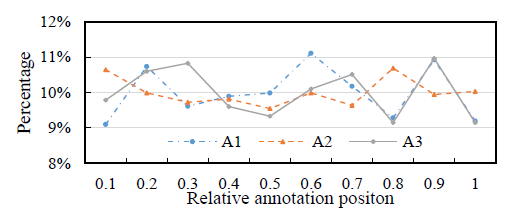
x축이 상대적인 annotation position입니다. 0에 가까울 수록 background segment에 앞부분에서 frame을 sampling 했다는 의미이고, 1에 가까울 수록 뒷부분에서 frame을 sampling 했다는 의미입니다. 임의의 Segment 내에서 특정 구간에만 몰려있다면 그것 또한 문제가 될 수 있겠지요. 하지만 그래프를 보면 대체적으로 모든 위치에서 골고루 뽑은 것을 볼 수 있네요.
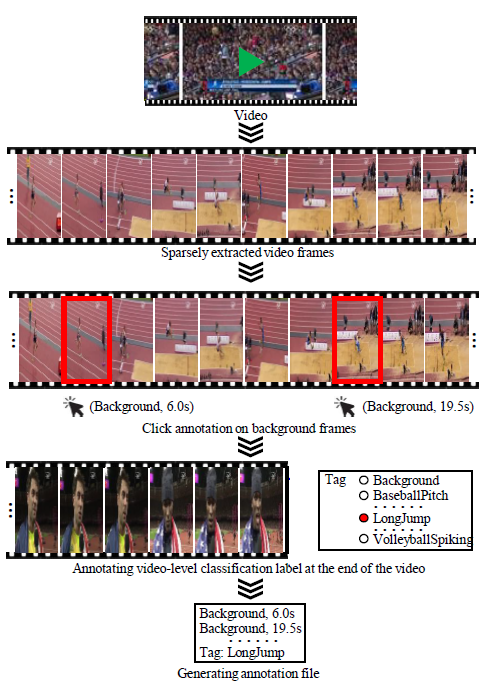
위의 사진 처럼 Background 순간에 대해서 마우스로 딸깍 클릭하듯 annotation을 할 수 있겠네요. 이따 더 자세히 보겠지만 이런식으로 하면 Video-level label만 제공했던 Weakly supervised 방식과도 annotation cost가 비슷하다고 합니다.
Comparison with State-of-the-Art Methods
THUMOS14에서의 성능 테이블 입니다. 본 논문의 접근 방식은 기존의 Video-level의 annotation만을 사용하는 Weakly Supervised 방식에서 Click-level의 Supervision이라는 추가적인 정보를 더 사용하다 보니 이를 구분해야할 필요가 있기에 성능 테이블에도 따로 구분을 해주고 있는 모습입니다.
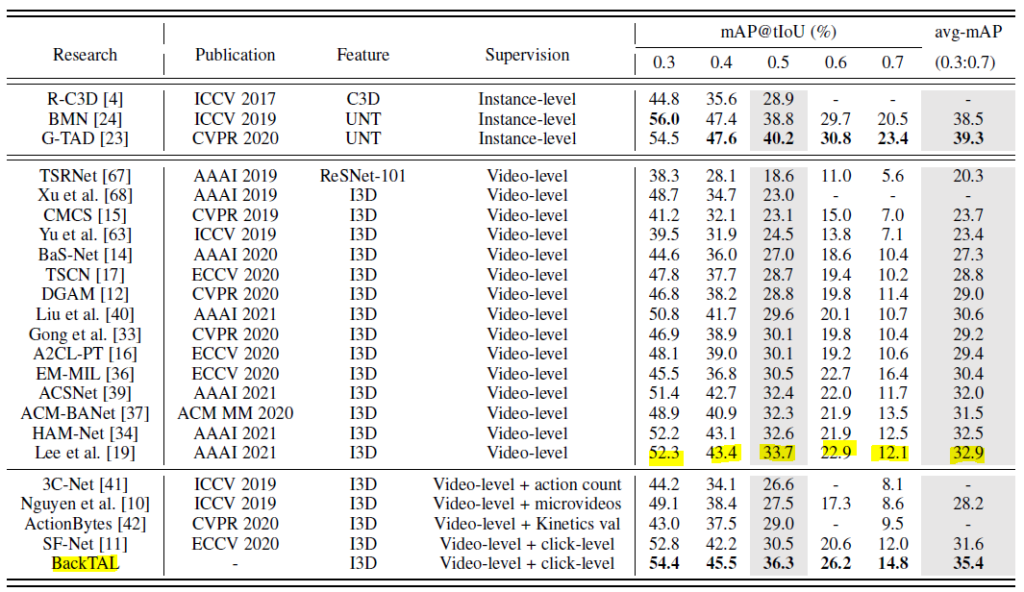
우선 결론만 말씀 드리자면 Weakly Supervised에서는 SOTA입니다. Supervision이 Instance-level로 정의 되어 있는 방법론들은 fully supervised 방식으로 학습 했다 볼 수 있습니다.
본 논문과의 가장 큰 비교군은 SF-Net이라고 해서 Action-click 기반의 annotation을 사용한 방법론이라 비교를 하면 될 것 같습니다. 모든 t-IoU threshold에서 더 높은 성능을 보여주고 있는 것으로 보아 background-click supervision이 더 효과적이다 라는 것을 보여주네요. 물론 이러한 사실은 뒤에 ablation study에서 더 자세히 다루게 됩니다.
Supervised 방식으로 학습된 성능 보다는 조금 떨어지는 성능을 보여주고 있습니다. 이를 통해 아직 weakly supervised localization이 개선될 여지는 충분히 남아있다는 점을 시사하는 것 같습니다.
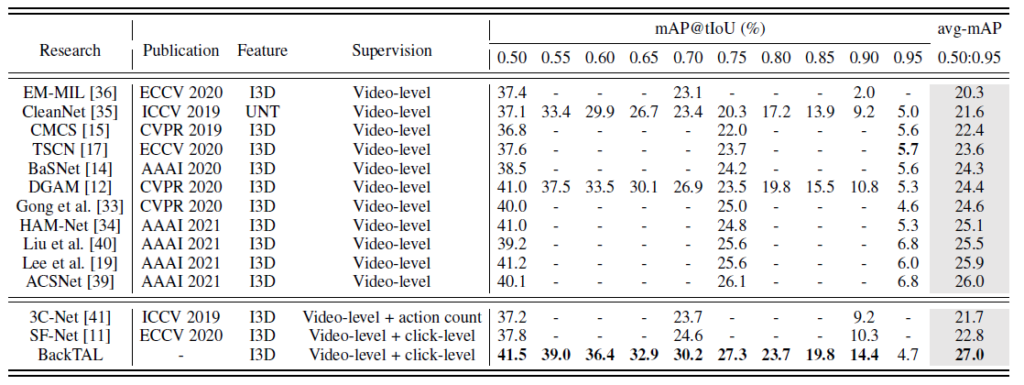
ActivityNet에서의 성능입니다. 역시나 Weakly supervised 분야에서는 제일 높은 성능을 보여주고 있습니다. 인상깊은 것은 SF-Net은 다른 방법론들 보다 떨어지는 성능을 보여주네요. 저자는 아마도 action-click annotation이 local한 영역내에서의 pattern을 학습하기에는 적합할지 몰라도 activitynet 처럼 long-range interval을 가지는 환경에서는 잘 작동을 못한다고 얘기하고 있습니다.

다음으로는 HACS에서의 성능 테이블 입니다. 계속 얘기해서 입이 아프지만 여기서도 SOTA라고 하네요. HACS 데이터셋이 main benchmarking dataset은 아니라 비교군이 적긴 하지만 역시나 SOTA라고 하네요.
그렇다면 지금 모든 데이터셋에서 SOTA를 달성했는 데, 한가지 의문이 들 수 있습니다. 아니 SOTA인 건 알겠는데 이거 사실 너희가 추가적으로 click level로 annotation 한 거 때매 발생한 이득인거 아니야? 라고 물어볼 수 있겟죠.
그래서 저자는 annotation cost와 localization performance간의 trade-off를 보여주는 그래프를 제시합니다.
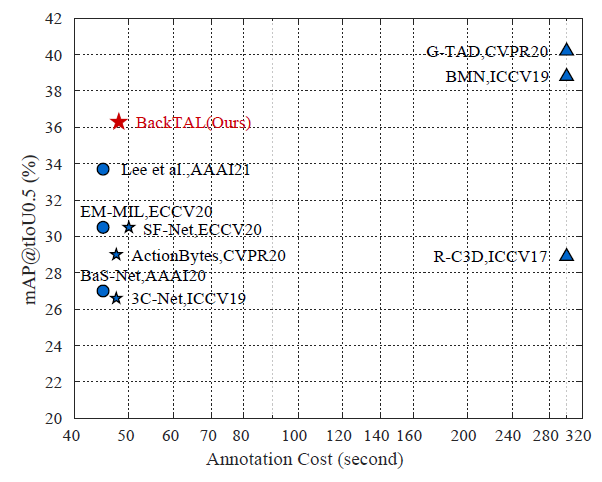
그림에서 볼 수 있듯, 사실 click level로 annotation 했다고 해서 annotation cost가 막 증가하고 그러지 않다고 합니다. 비슷한 annotation cost를 가지는 상황에서는 제일 좋은 성능을 보여주고 있습니다. 저기 위에 보이는 G-TAD랑 BMN은 supervised이니 cost가 큰 대신 성능은 그래도 더 높네요.
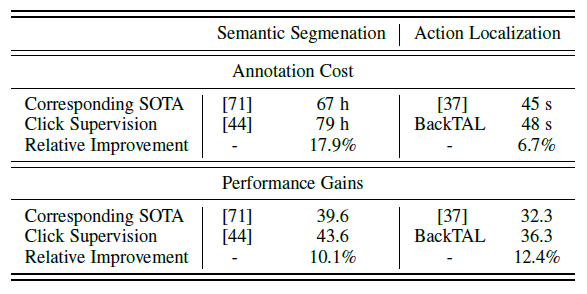
또한 저자는 논문에서 사용한 Click-level의 supervision의 effectiveness를 semantic segmentation domain에서 같이 확인을 해봅니다. 핵심은 click-level annotation을 함으로써 증가되는 annotation의 cost 비율보다 이를 통해 얻는 성능 향상 비율이 더 높다는 점입니다. annotation cost는 6.7% 증가한 것에 비해 성능 향상은 12.4%를 얻을 수 있었네요. 나쁘지 않은 장사다! 이렇게 주장하는 것 같습니다.
Ablation Studies
ablation study입니다. 여기서는 정말 다양한 실험을 하니 정신차리고 읽어야 실험의 의미를 알 수 있습니다.

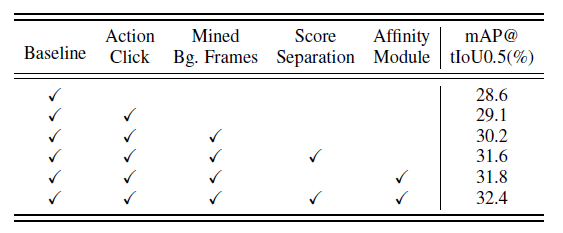
첫번째 ablation 입니다. 사실 Action Click-level의 Supervision은 SF-Net이라는 방법론에서 이미 제안이 되었고, 저자는 이를 반대로 접근하여 Background Click-level Supervision을 제안했습니다. 그렇다면 과연 정말 Background Click-level이 Action Click-level 보다 좋은 지 확인해봐야겠죠?
Baseline에 Action Click과 Background Click을 적용했을 때 성능이 나타나고 있습니다. 결과는 Background 압승이네요. 저자는 이 결과에 대한 근거를 다음과 같이 정의하네요. 처음에 봤던 통계 기억하시나요? 글이 길어져서 까먹었을 수 있지만 Weakly temporal localization에서 가장 많이 발생하는 에러는 Background error 였습니다. 모델이 Background에 대한 정보가 부족한 상태에서 학습 했기 때문입니다.
가장 문제가 많은 부분을 해결하기 위해서는 당연히 Background Click-level로 접근하여 더욱 유연하게 학습 시키는 것이 정답이었던 모양입니다.
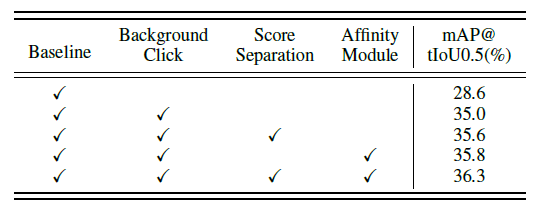
또 다음으로는 저자가 제안한 두가지 module에 대한 ablation 입니다. Background Click 까지 적용했을 때의 성능이 35.0인데, Score Seperation Module과 Affinity Module을 활용하여 성능 총 1.3 더 증가를 시켰네요. 이를 통해서도 각 모듈의 필요성에 대한 이유를 납득할 수 있을 것 같습니다.
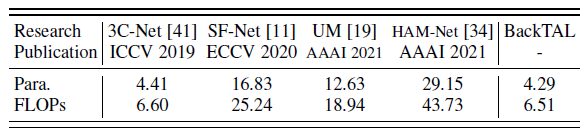
다음으로는 computational complexity에 대한 ablation 입니다. 조금 놀란건 상당히 가벼운데 성능이 제일 좋다는 점입니다. computational complexity와 performance가 둘 다 좋은 것은 확실히 strong contribution으로 작용할 수 있을 것 같습니다. 가장 최근의 방법론은 HAM-Net에 비해서 parameter는 14.72% 수준이고 flops는 14.89% 수준이라고 하니 대략 6배 정도 가벼운가 봅니다. 하지만 아까 테이블을 보면 알겠지만 HAM-Net 보다 성능도 뛰어나네요.
마지막 ablation은 자꾸 비교군으로 등장했던 SF-Net(Action Click으로 학습한)에 Score Separation과 Affinity Module을 가미했을 때 최대 성능을 보여주는 테이블 입니다. 결국 Action Click으로 학습 했을 때의 최대는 32.4에 수렴한 반면, Background Click으로 학습 했을 때는 36.3까지 달성이 가능합니다. 이를 통해서도 역시 Action Click 보다는 Background Click이 더 좋다! 이렇게 생각할 수 있겟네요.
Qualitative Analysis

먼저 affinity module에서 만들어지는 attention mask를 한번 보도록 하겠습니다. Action frame을 위한 attention mask는 정말 action 부분에 값이 높은 것을 확인할 수 있습니다. 색이 밝을 수록 mask의 값이 높다고 생각하면 됩니다. Background frame을 위한 attention mask도 잘 만들어지는 것 같습니다. 뭐 어디까지나 정성적 결과이니 그냥 가볍게 보면 될 것 같습니다.

다른 방법론에 비해서 비교적 잘 예측을 수행하고 있습니다. 저자가 밝히는 Back-TAL의 단점은 long action instance를 몇몇 segment로 쪼개는 경우가 있다고 합니다. 이는 view point가 바뀌는 등의 action 내부의 variation이 극도로 커지게 될 때 나타나는 현상으로 weakly supervised localization이 아직 갈 길이 멀었다고 언급합니다.
Conclusion
이전에 연구가 되었던 action-click supervision의 문제점을 파악하고 이를 뒤짚어서 생각한 background-click supervision과 이를 도와줄 두가지의 모듈이 너무나도 참신했고 인상 깊었습니다.
페이퍼 양 자체가 많아서 논문을 읽기전에는 내용들을 이해할 수 있을 까 걱정이 들었는데, 다 읽고 나니 조금 뿌듯하네요.
논문을 읽으면서 계속 느낀것은 저자가 이 연구분야에 대해 빠삭한 것이 느껴졌습니다. 저도 이런 사람이 되고 싶네요 논문을 계속 열심히 읽어야 할 것 같습니다.
아무튼 이상으로 리뷰 마무리 하도록 하겠습니다. 감사합니다.
Click-level annotation으로 정보를 제공해줄 경우, boundary가 coarce해지지는 않나요?