
Google AI에서 2019 CVPR에 발표한 논문이고, IITP 비대면 우울증 과제에서 KETI라는 기관에서 사용한 방법론을 나타내고 있어 간단히 리뷰를 진행하겠습니다.
얼굴 표정을 인식해서 감정을 나타내는 연구들이 있습니다. 일반적으로 저희가 생각할 수 있는 감정 분류에 대한 방법론은 어떻게 될까요? 아마도 다음과 같이 않을까요?

데이터셋이 되는 사진의 얼굴 표정들에 일일히 감정을 나타내는 클래스를 레이블링하고, 이를 모델을 통해서 분류하도록 하는 방법이 있습니다. 그런데 이러한 방법은 과연 얼굴 감정 인식에 정말 유효한 방법일까요?
:max_bytes(150000):strip_icc():format(webp)/GettyImages_170955996-56a794ec5f9b58b7d0ebe594.jpg)
사람의 감정이란 수백개가 넘으며, 또한 감정들을 단순히 이산화된 값으로 표현할수도 없습니다. 따라서 해당 논문에서는 이러한 기존 연구들의 문제점을 이야기하며 사람의 얼굴 표정에 따른 감정인식을 retrieval 문제로 풀어야한다고 주장하며, 이를 위한 대규모의 데이터셋을 공개하고 있습니다.

해당 논문의 티저 이미지 입니다. 만약 Query의 해당하는 얼굴 표정을 기존처럼 클래스로 했다면 해당 표정은 어떤 클래스에 정의할 수 있을까요? ‘입술 내밀고 눈감은 표정’과 같이 특수한 케이스로 분류하고 해당 클래스와 유사한 데이터셋을 수집해야 했습니다. 하지만 해당 논문은 retrieval로 문제를 풀기 때문에 기존 연구들보다 더욱 정확하게 유사한 이미지들을 구할 수 있고, 이러한 방식은 클래스 즉, 모델이 구할 수 있는 감정 표현의 레이블 값을 무한으로 늘릴 수 있다는 것을 나타냅니다. 그리고 해당 논문에서는 이러한 데이터셋을 제공하고 있으며, 데이터셋이 핵심인 논문입니다. 그러면 우리가 아는 일반적인 retrieval문제는 어떻게 풀 수 있을까요? 가장 기본이 되는 방법이 바로 ‘triplet loss’ 입니다. 따라서 본 논문에서도 triplet loss를 이용하여 모델을 학습시킬 수 있도록 대규모의 데이터셋의 annotation을 진행합니다.

해당 논문에서 공개한 데이터셋이 어떻게 수집되고 annotation이 됐는지를 나타내는 핵심입니다. 해당 데이터셋을 다운받으면 함께 첨부된 데이터셋의 설명에 나타나있으며, 이러한 내용이 논문에서도 설명합니다. 하지만 해당 설명이 더욱 정확하고 명확하게 이해할 수 있어 논문의 내용보다 위의 문서내용을 가져왔습니다. 결국 본 논문에서 수집한 데이터셋은 다양한 감정을 포함하는 얼굴 사진을 가지고 사람에게 가장 시각적으로 비슷한 영상을 선별하라고 하여 annotation을 수행합니다. 이때, 감정과 관련된 정보만 비교하며 기타 다른 요소(성별, 자세, 나이 등)은 무시하도록 지시했다고 합니다. 따라서 결국 해당 데이터셋은 3가지의 타입으로 annotation이 구분되어 있는데 이를 시각적으로 표현하면 다음과 같습니다. (설명은 위에 글에 잘 나타나 있습니다.)

결국 해당 논문의 가장 핵심이 되는 contribution은 대규모의 데이터셋을 공개하고 있다는 점 입니다. 그렇다면 데이터셋의 양이 얼만큼 많은지 알아봐야겠죠…?
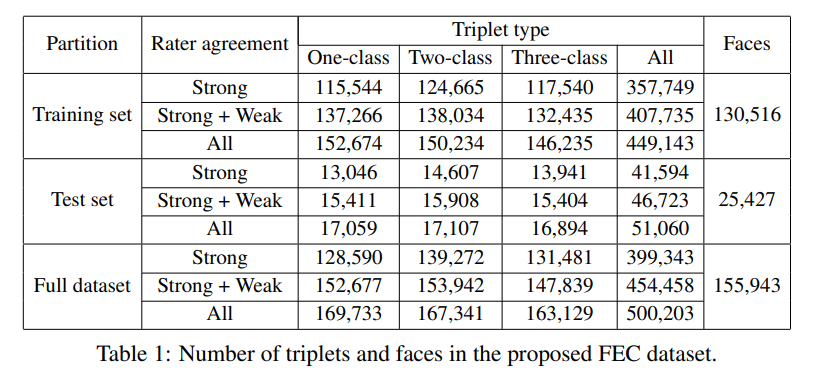
데이터셋에 Strong과 Weak는 무엇일까요…? 해당 데이터셋은 6명의 평가자(raters)에 의해서 triplet annotation이 이뤄졌는데 대다수가 유사함을 동의했으면 Strong 그 중 일부만 동의하면 Weak 로 표기한것 같습니다.
Each triplet in this dataset was annotated by six raters. For a triplet, we say that the raters agree strongly if at least two-thirds of them voted for the maximum-voted label, and agree weakly if there is a unique maximum-voted label and half of the raters voted for it. The number of such triplets for each type are shown in Table 1.
자 그럼 이렇게 좋은 데이터셋을 가지고 데이터셋이 쓸모가 많은지 테스트를 해봐야겠죠? 해당 논문에서는 triplet loss를 이용하여 facial expression을 잘 나타낼 수 있는 좋은 embedding vector를 만드는게 목표입니다. 이를 위해 해당 논문에서 사용하는 네트워크는 다음과 같습니다. (간단한 네트워크 이므로 설명은 넘어가겠습니다.)

그리고 이러한 네트워크를 학습하기 위해서 모두가 알고있는 triplet loss를 사용합니다.
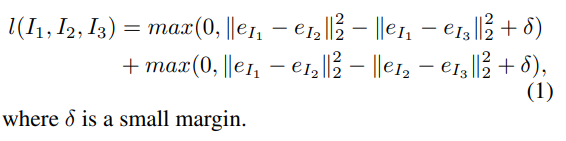
Annotation이 Triplet loss를 위해서 설계됐으므로 사용하는데 크게 어려움은 없습니다.
Experiments
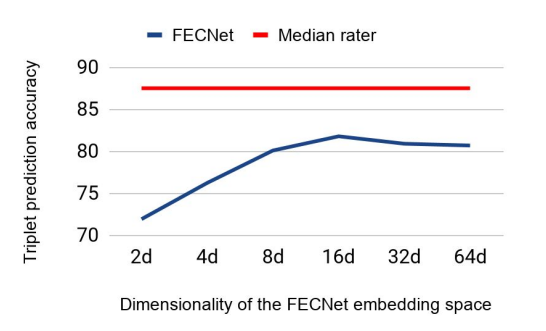
먼저 사람과 비교했을때 성능이라고 합니다. y축은 정확도 x축은 embedding vector의 차원을 다르게 했을때 결과를 비교한 값 입니다.

해당 연구는 각 감정을 클래스로 학습하지 않았고, feature의 유사도만을 나타냈는데 위와 같이 어느정도 유의미하게 벡터 스페이스에서 군집화 되는것을 볼 수 있다고 합니다.
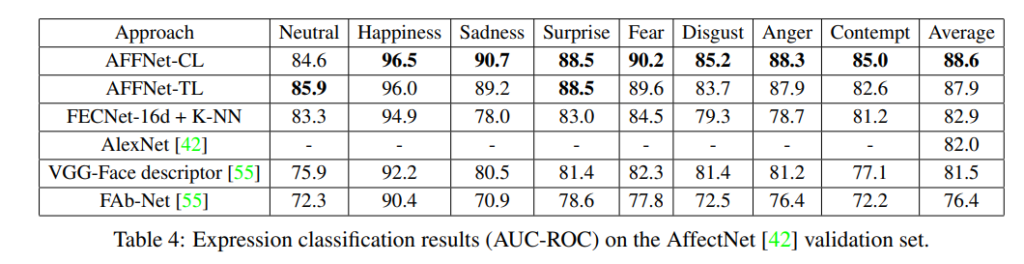
AffectNet에서 공개한 데이터셋의 validation 셋에 대해서 평가한 결과 입니다. AFFNet은 위에 나타난 클래스를 라벨링하여 모델을 학습한 결과이고 FECNet은 라벨링 없이 학습하고 KNN만 이용하여 예측한 결과입니다. 중요한점은 AFFNet보다 해당 논문에서 사용한 FECNet이 성능이 낮지만 클래스 라벨링 없이도 유의미한 성능을 나타냈다는점 입니다. (아키텍처는 동일하다고 합니다.) 또한 그냥 일반적인 분류를 진행하듯 VGG나 AlexNet에 클래스를 변형하여 학습한 모델들 보다는 더 높은 성능을 나타냈다고 합니다.

또한 정성적 비교를 보아도 실제 쿼리와 유사한 이미지들이 추출됨을 볼 수 있다고 합니다. (자세한 부분은 논문을 참조)
논문 : 링크
감정이란게 라벨링하기 상당히 어려운 이슈가 있는거 같습니다. strong / strong + weak / All 에따라서 성능을 리포트한 실험은 없나요?
Strong / Strong + Weak / ALL 에 대해서 따로 평가할 만큼 해당 논문에서 이 차이를 중요하게 다루고 있지 않는것 같습니다.
저기서 라벨링된 얼굴과 감정이 일치하는지는 어떻게 아나요…?
사람이 수동으로 라벨링한 감정과 비교한 사진입니다. 얼굴 표정과 그 사람의 실제 감정을 정확히 매칭할 수 없겠지만 사람이 수동으로 해당 얼굴에 대해서 이러한 감정을 나타낸다고 라벨링한 값을 의미합니다.