비디오 검색 관련 논문 리뷰입니다! 오늘은 self-attention 기법을 사용하여 frame-level features 간의 시간 정보를 통합해서, 좀 더 긴 정보를 가진 video representation 을 학습해내는 framework, TCA 에 대해 알아볼 것입니다.
우선 비디오와 비디오를 비교하여 유사도를 예측하여 검색을 하는, Content-Based Video Retrieval 문제 중에는 여러 분야가 있습니다.
- Near-Duplicate Video Retrieval (NDVR)
- Fine-grained Incident Video Retrieval (FIVR)
- Event-based Video Retreival (EVR)
NDVR 과는 비교했을 때 , FIVR 과 EVR 는 ‘사건’에 대한 것이기 때문에 좀 더 시간에 걸친 의미론적인 정보에 대한 의존성이 높습니다. 그렇기 때문에 high-level representation을 학습해야 하고, 공간 정보 뿐만 아니라 시간 정보를 많이 고려해야하니까 어려운 문제라고 할 수 있죠.
CBVR 문제를 해결하기 위해 비디오의 특성을 뽑아내는 방식은 크게 두 가지가 있는데, 첫째는 video-level representation 이고, 둘째는 frame-level representation 입니다. 말 그대로 각 레벨에서 representation을 뽑는 것인데, 이를 이용하여 비디오 간의 similarity 를 구하여 비교하게 됩니다.
두 방법 모두 비디오를 갖고 짧은 clips 이나 하나의 frame 으로 생각되어 가공되기 때문에, 많은 프레임에서 긴 시간 동안 지켜봐야 알 수 있는 의미론적인 시간 정보은 얻기가 어렵게 됩니다.
이 논문에서는 Self-attention 기법이라는 것에 영향을 받아, frame-level features 간의 시간적 정보를 통합할 것을 제안합니다. 이를 이용하면 좀 더 시간적 의존성이 커져서, 우리가 풀고 싶어하는 문제와 좀 더 연관있고 robust 한 feature 를 만들 수 있을 거예요.
또한 이 논문에서는 Video retrieval 에서도 Supervised Contrastive learning 을 사용할 것을 제안합니다. 이건 이 기법을 사용하기 위해 필요한 negative 한 samples 가 video retrieval datasets 에 충분히 있는 덕분이라고도 합니다.
마지막으로, 이 논문에서 제안된 방법이 automatic hard-negative mining 을 해주는 특성도 있다고 합니다. 이러면 최종 성능을 올릴 수 있다는 장점이 있다고 해요.
실험은 CC_WEB_VIDEO, FIVR, EVVE 에서 수행되었습니다. 제안한 방법론 TCA가 video-level 에 대해 sota 를 달성했고, frame-level 에 대해 22배 빠른 inference time 을 달성했다고 하네요.
Problem Setting
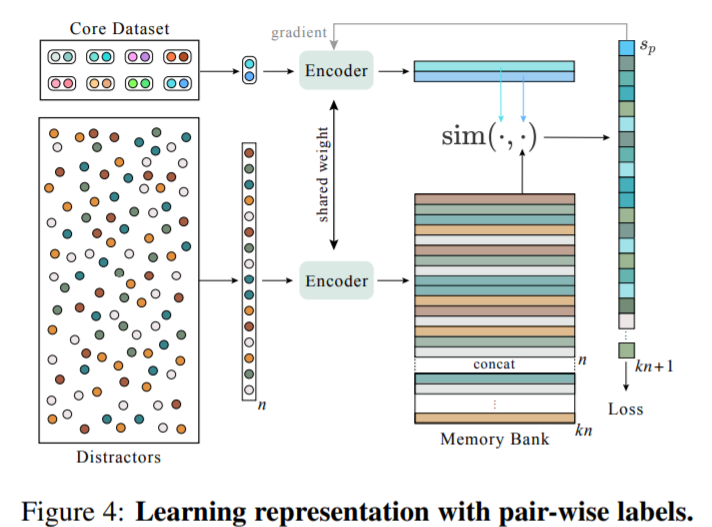
dataset 은 두 개의 split 으로 이루어져 있습니다.
- core : 어떤 두 비디오가 유사한지에 대해, pair-wise label 을 가집니다. (near duplicate, complementary scene, same event 등)
- disctractor : retrieval 문제를 더 어렵게 만들기 위해, negative samples 을 포함합니다.
두 비디오에 대한 정보로 RGB 상태의 raw pixel 이 주어지면, 이로부터 frame-level / video-level descriptor 가 추출해서 유사도를 구합니다. 이때 이 유사도 값이 클 수록 두 비디오는 더 유사한 것입니다.
- raw pixels : x_{r} \in R^{m \times n \times f}
- frame-level descriptors : x_{f} \in R^{d \times f}
- video-level descriptors : x_{v} \in R^{d}
- similarity : sim(f(x_1), f(x_2)) , (f 는 embedding function, x1 과 x2 는 descriptor)
해당 논문에서 제안하는 temporal context aggregation modeling module은 여기서 f 와 동일하다고 보면 되는데, frame-level descriptor 를 input 으로 받아 aggregated video-level descriptor 를 만들거나, 더 발전된 refined frame-level descriptors 를 만드는 것이 이 모듈의 역할입니다.
Feature Extraction
Feature extraction 을 하는 방법은 아래의 table 의 결과를 바탕으로 선택하였습니다.
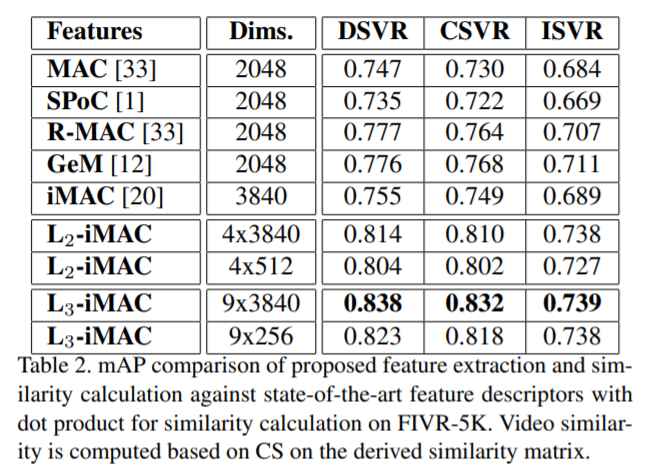
- frame extraction methods : iMAC, modified L3-iMAC
- generated feature map : M^k \in R^{n^k_d \times n^k_d \times c^k} (k = 1, 2, ... K)
- iMAC feature : v^k(i) = max(M^k(\dot , \dot , i), i = 1, 2, ... c^k))
- (이때, 본래의 L3-iMAC 의 방법을 따르지 않고, R-MAC 의 방법을 따라 3×3 feature map 을 합치고 feature map M^k 의 각 채널에 l2-normalization 을 적용합니다.)
- extraction 후, 모든 layer 의 vector 들이 concat 돼서 하나의 single decriptor 로 만들어집니다.
- 그 후, PCA 가 적용되어 whitening 과 차원 축소가 적용됩니다.
- 결과적으로, compact 한 frame-level descriptor x \in R^{d \times f} 가 만들어집니다.
- 앞서 말했듯이, 이를 tca module 에서는 이를 input 으로 받게 됩니다.
Temporal Context Aggregation
temporal context aggregation 을 할 때는 Transformer model 의 encoder 구조를 사용합니다.
Transformer 는 self-attention 기법을 사용하기 때문에 video 의 frame sequence 에 걸쳐져 있는 long-term dependencies 를 좀 더 잘 모델링할 수 있게 됩니다. Attention 은 parmeter matrix 에 Q, K, V 를 적용하여 얻을 수 있는데, 이게 LayerNorm layer 와 FeedForward Layer 로 들어가고, input 인 frame-level descriptor 를 Transformer encoder에 넣으면 이로부터 ouput feature 를 얻을 수 있게 됩니다.
이 output feature의 시간 축에 따른 평균을 구하면, (시간으로 나눈다는 뜻) 좀 더 compact 한 video-level representation 을 얻을 수도 있습니다.
- input : x \in R^{d \times f}
- parameter matrix : W^Q, W^K, W^V (Query, Key, Value)
- linear transformations to input : Q = x^T*W^Q, K = x^T*W^K, V = x^T*W^T
- Attention(Q,K,V) = softmax( {{Q*{K^t}} \over { \sqrt{d} }} ) * V
- output : f_{Transformer}(x) \in R^{d \times f}
- output (compact) : f_{Transformer-average}(x) \in R^{d}
Contrastive Learning
dataset 은 anchor, positive, negative examples 로 이루어져 있습니다. 이에 대한 video-level representation 을 이용하여, 각 similarity scores 를 구하고, 이를 이용하여 InfoNCE loss 를 구할 수 있습니다. 이 Loss 같은 경우, Contrastive Predictive Coding 을 사용하여 Representation Learning 을 하는 논문에서 제안된 함수입니다. 또한 Circle Loss 라는 함수를 이용하여 구할 수도 있습니다. 이는 InfoNCE Loss 와 비교했을 때, positive simlarity 와 negative similarity 를 분리하여 최적화 한다는 이점이 있습니다.
- video-level representation : w_a, w_p, w^j_n (j=1,2, ... , N-1)
- similarity scores : s_p = w_a^T*w_p / (||w_a|| * ||w_p|| ), s^j_n = w_a^T*w^j_n / (||w_a|| * ||w_p|| )
- \tau : temperature hyper-paramter (negative samples 를 이용하여 더 좋은 성능을 내기 위함, memory bank 관련)
- N = (batch size) * (numbers of negative samples from distractors) * s_n
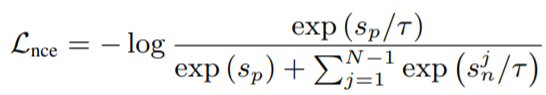
- \gamma : scale factor ( \tau 와 동일)
- m : relaxation margin
- \alpha_p = [1 + m - s_p]_{+}, \alpha_n^j= [s^j_n + m]_{+}
- \bigtriangleup_p = 1 -m, \bigtriangleup_n = m
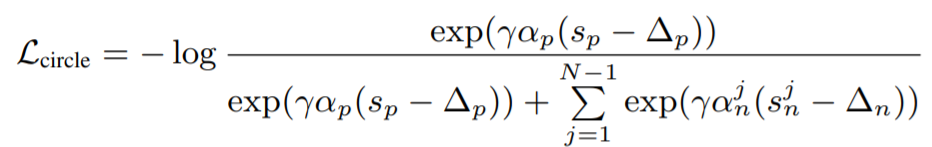
Similarity Measure
computation && memory cost 를 줄이기 위해, 해당 논문에서는 모든 모델을 video-level descriptors f(x) \in R^{d \times f} 로 학습시켰습니다. 이를 이용하면 두 비디오 간의 similarity 는 단순히 dot product 를 이용한 chamfer similarity 로도 구할 수가 있습니다. 그런데, frame-level video descriptor 가 평균 내어져서 만든 compact representation 을 사용하는 경우에는, chamfer similarity 를 적용하는 게 적절하지 않습니다. 따라서 이 경우는 다른 방법으로 similarity 를 구합니다.
- video x = [x_0, x_1, ... , x_{n-1}]^T
- video y = [y_0, y_1, ... , y_{n-1}]^T
Chamfer similarity :
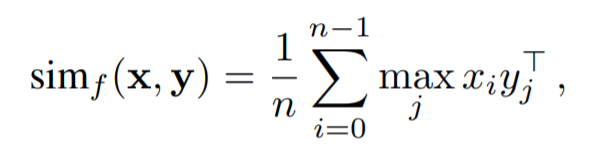
Chamfer similarity (symmetric version) :
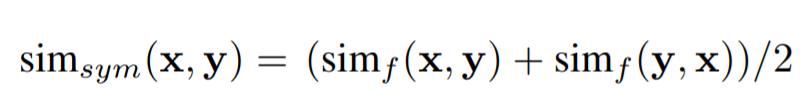
Cosine similarity (compact video descriptor) :
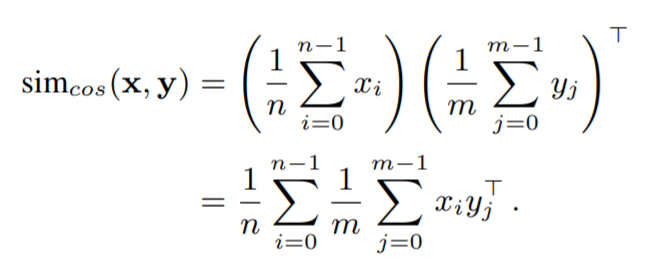
Experiments
- Video Retrieval Task : NDVR, FIVR, EVR
- Metric : mAP (mean Average Precision)
- Training dataset : VCDB dataset
- Evaluation dataset : NVDR -> CC_WEB_VIDEO, FIVR -> FIVR-200K, FIVR-5K, EVR -> EVVE
Ablation Study
빠른 Ablation study 를 위해 FIVR-200K 뿐만 아니라 그 일부인 FIVR-5K도 사용하였다고 합니다.
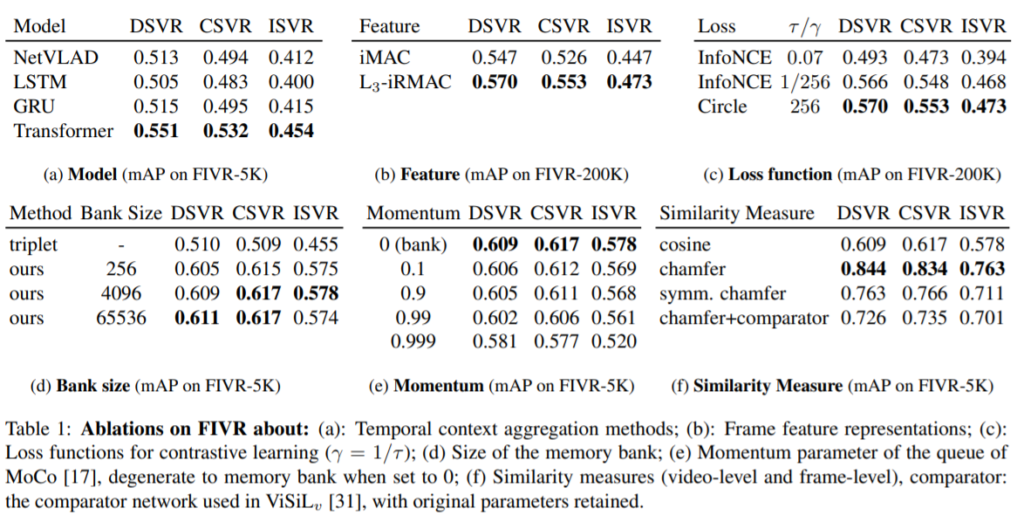
(a) Model : Transformer 의 성능이 가장 좋았습니다. 이는 long-term temporal dependency modeling 을 가능케 한 self-attention 기법 덕분으로 보입니다.
(b) Feature : L3-iRMAC 이 iMAC 보다 성능이 좋았습니다. 이는 local 한 지역 공간 정보가 좀 더 많이 활용되었기 때문으로 보입니다.
(c) : Loss function : Contrastive learning 에 사용한 loss 함수를 \tau / \gamma 에 따라 비교했는데, 값을 조정해도 InfoN 를 사용한 경우는 Circle 를 사용한 경우보다 항상 낮은 mAP 를 보였습니다.
(d) : Memory Bank : memory bank 의 size 에 대해 비교를 하였습니다. memory bank 의 크기가 클 수록 성능이 점차 좋아지는 것을 볼 수 있었으므로, negative samples 의 양은 많을 수록 좋다는 걸 보여준 것입니다. 또한 hard negative mining 을 사용하는 triplet based approach 와도 비교해보았는데, 이 기법은 시간이 해당 논문의 방법보다 많이 듦에도 불구하고 더 낮은 성능을 보였습니다.
(f) : Similarity Measure : video-level 은 cosine similarity, frame-level 은 chamfer similarity (+a) 를 사용했다. video-level 보다는 frame-level 로 한 경우가 성능이 좋았습니다. comparator 를 사용한 경우가 성능이 안좋았는데, 본 논문에서는 features 간의 bias 문제 때문이라고 주장했습니다.
Comparision against Sota
similarity measure 에 따라 TCA 에 대한 각 방법론을 아래와 같이 부르게 됩니다.
- TCA_c : cosine (video-level)
- ——————————————
- TCA_f : chamfer (frame-level)
- TCA_sym : symmetric-chmafer
- TCA_v : video-comparator
결과를 보면 대체로 sota 를 달성하였습니다. 다만 몇 가지 짚고 넘어갈 부분이 있기도 합니다.
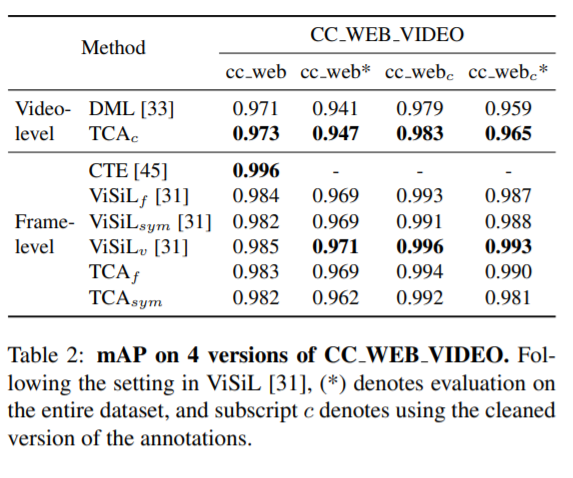
NDVR 에서 video-level 쪽에서는 sota 인데, frame-level 에서는 sota가 아녔다고 합니다. 저자는 해당 논문은 좋은 video representation 을 학습하는 것이 목적이었고, similarity calculation 에 따라 달라질 수 있으므로 우리는 이걸 빨리 효율적으로 할 수록 이득이라고 말하였습니다. 그리고, TCA_f 와 ViSiL_f 가 유사한 simialrity calculation 을 사용하니까, 이 둘을 비교하는 게 더 공평하다고 말했습니다.
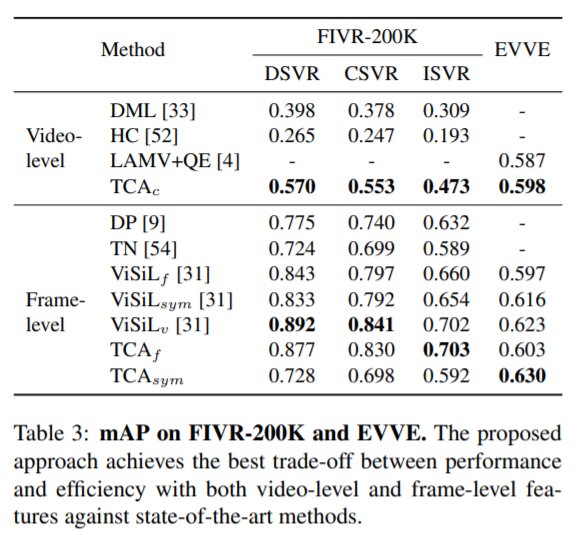
FIVR에서는 마찬가지로 video-level 쪽에서는 sota 고 frame-level 에서는 아녔는데, 이는 성능이 낮지만 소요되는 시간이 22배 정도 빠른 장점이 있다고 합니다. EVR 에서는 특이하게도 video-level 쪽에서 TCA_c 가 sota 를 달성했고, frame-level 까지 포함했을 때 TCA_sym 이 sota 를 달성했습니다. video-level 이 아닌 frame-level 이 sota 인 것을 보면서, 어쩌면 EVR 문제에서, temporal inmformation 과 fine-grained spatial information 이 사실은 필수가 아닌 게 아닐까… 라며 저자는 의견을 냈습니다.


TCA 를 이용하여 시각화 한 것들을 보여주었습니다.
figure 5 에는 self-attention 기법의 효과를 눈으로 보기 위해 만든 것입니다. 이를 이용하면 frame, clips 뿐만 아니라 비디오의 거의 전체에 대한 long-range semantic dependencies 를 모델링할 수 있습니다.
특히 figure 6 같은 경우는, DML 과 비교했을 때 TCA_c 가 relevant videos 에서 얻은 refined features 끼리 잘 clusters 를 만들어 뭉쳐있음을 보여줍니다. 또한, 회색의 distractors 가 색칠된 core 들과 잘 떨어져있음을 알 수 있습니다.
TCA와 ViSiL의 가장 큰 차이점 중 하나는 Triplet이 없이 학습이 가능하다는 점 같습니다. 제가 기억하기로는 논문에 해당 내용이 명시되어 있는데, 리뷰에 빠져있는 것 같네요. 혹시 왜 Triplet 없이 학습이 가능한지 정리해주실 수 있나요?
Triplet learning 은 time-consuming 한 hard-negative sampling process 가 필수적이라는 단점이 있었는데, Contrastive Learning 은 이러한 process 가 필요없었고, triplet 은 anchor-positive-negative 이렇게 하나씩 사용을 해서 loss 를 최적화하는데, contrastive learning 의 samples 를 한꺼번에 사용하여 최적화할 수 있어 representation learning 에 효과적이 때문이라고 이해했었습니다. 또한 Video retrieval 관련 datasets 의 양이 많아져서 supervised contrastive learning 이 가능하기도 했고요…!
단순히 contrastive learning 이라 negative samples 를 많이 사용해도 된거라 생각하여 자세한 내용은 적지 않았던 것인데, 다시 읽어보니 shared memory bank 덕분에 negative samples 의 양이 많아졌다는 부분이 중요한 내용이었네요…!
우선 dataset 은 core dataset 과 distractor dataset 로 split 되어 있습니다.
core dataset 에서 하나의 postivie pair 를 가져오고, distractors로부터 랜덤한 n 개의 negative samples 를 가져옵니다. 그리고 shared encoder 를 이용하여 각 sample에 대해 compact 한 video-level descriptor 를 만듭니다. 이때 모든 negative samples 에 대한 descriptor 들을 concat 해서 memory bank 를 만듭니다. 이것들을 이용하여 anchor 에 대해 positive sample, 그리고 memory bank 에 있는 모든 negative samples 간의 similarity 를 비교하여, sim(f(x_1), f(x_2)) 에서 embedding function f 를 최적화하는 방식으로 하기 때문에 anchor-positive-negative 로 이루어진 triplet 없이, 학습이 가능하게 되는 것입니다. 다시 읽어보니 shared memory bank 부분을 좀 더 다뤘어야겠다는 생각이 드네요. 질문 감사합니다!
참고로 혹시나 해서 말하는 건데 본 리뷰는 저번주의 것이니… 혹시나 이번 주 논문에 달아야하신거라면 한 번 알아보시는 게 좋을 것 같습니다. 아무튼 감사합니다!