이번에는 Video retrieval 논문 읽기에서 골라서 읽은 논문으로 가져왔습니다.
- (2017) Near-Duplicate Video Retrieval by Aggregating Intermediate CNN Layers
- (2017) Near-Duplicate Video Retrieval with Deep Metric Learning
- (2019) ViSiL: Fine-grained spatio-temporal video similarity learning
- (2021) DnS: Distill-and-Select for Efficient and Accurate Video Indexing and Retrieval
이전 논문에서 제가 위와 같이 논문 순서를 정리했는데, 이번에는 위에 진하게 표기된 논문입니다. DnS는 비디오 검색 과제 세미나에서 본 적은 있어서 이것만 읽으면 다 읽었네요. 이 논문은 비디오 검색을 앞서 논문에서 소개한 딥러닝 방법론으로 추출한 feature를 기반으로 수행하는 논문입니다.
Introduction
논문 제목에서도 확인할 수 있듯이 이 논문은 NDVR이라는 복제 비디오를 탐지하기 위한 task를 해결하기 위해 제안된 논문입니다. NDVR에 대한 정의는 “near-duplicate videos are considered to be identical or close to exact duplicate of each other”인데요. 한국어로 바꾸면 거의 비슷하거나 완전 똑같은 비디오라고 보면 됩니다. (이 내용은 이전 리뷰랑 중복되지만 task에 대한 설명이라 가져왔습니다.)
기존의 NDVR에서의 SOTA 방법론은 학습한 데이터셋으로 평가하거나, codebook이나 hashing 기반 방법론들이었습니다. 이 논문에서는 CNN을 통해 feature를 뽑고, triplet 방법론을 이용한 Deep Metric Learning(DML)을 제안했습니다. 그리고 특이한 점은 video level feature 기반 방법론입니다.
Approach Overview
Feature Extraction
Feature 추출 단계는 이전에 작성한 “Near-Duplicate Video Retrieval by Aggregating Intermediate CNN Layers”리뷰에 자세한 방법이 나와있습니다. 해당 논문에서 사용한 방법론을 약간 수정해서 사용하고 있습니다.
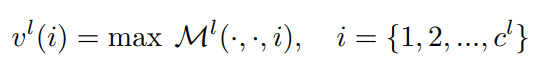
위 수식과 같이 레이어마다 뽑아진 feature는 max라고 표기된 max pooling layer을 채널마다 수행해줘 하나의 값으로 변환합니다. 그럼 우리는 각 레이어의 vector v를 레이어의 갯수만큼 얻을 수 있고, 이 레이어들을 모두 concat 해주면 frame-level feature가 됩니다.
그럼 video-level feature는 어떻게 구할까요? 여기서는 초당 1프레임씩 뽑아서, 이 프레임들의 feature를 뽑아주고 zero-mean(averaging)과 L2 normalization(normalizing)을 수행해주었다고 합니다.
Metric Learning
Problem setting
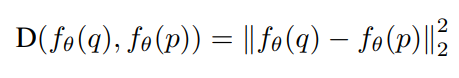
NDVR 문제를 풀기 위해 Query video와 Database video의 유사도를 정의하기 위해 위와 같은 수식을 사용합니다. q와 p는 두 비디오를 나타내고, video embedding 간의 squared Euclidean distance를 계산하면 그게 두 비디오의 유사도를 나타낸다고 합니다.
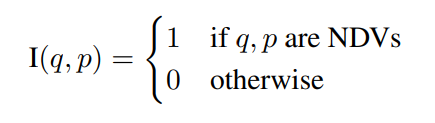
이 수식은 pairwise indicator function으로 q와 p 비디오가 복제된 비디오인지 아닌지를 나타내는 함수입니다.
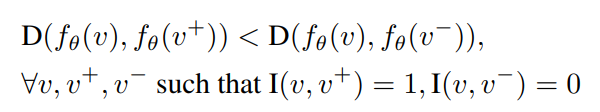
이러한 함수는 결국 이 NDV 문제가 embedding function f를 학습해야하기 때문에 필요합니다. v+가 유사한 비디오, v-가 유사하지 않은 비디오라고 할때, 위와 같이 Euclidean distance는 항상 유사한 비디오와의 값이 작게 계산된다는 목표를 가지고 학습을 수행합니다.
Triplet loss
이 논문의 가장 중요한 내용입니다. 여기서 쓰는 이 triplet을 ViSiL에서도 사용하거든요. 여기서 사용하는 Triplet은 (anchor 비디오, 유사한 비디오, 유사하지 않은 비디오) 쌍을 가지고 있는 비디오 셋입니다. 수식으로 나타내면 T = \{(v_i, v_i^+, v_i^-), i=1...N\}와 같이 됩니다.
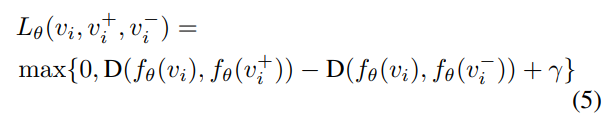
이러한 Triplet을 학습하게 되면 유사한 비디오와 아닌 것에 대한 embedding을 학습할 수 있겠죠? 그런 원리로 위와 같은 Loss를 구성합니다. 유사한 비디오의 Euclidean distance는 커지고, 유사하지 않은 비디오와의 Euclidean distance는 작아지도록 하는거죠. 여기서 등장하는 margin 역할을 수행하는 γ가 안정적인 학습을 도모하는 중요한 값이라고 합니다.
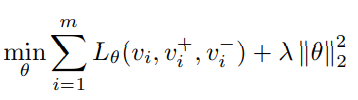
추가적으로 이러한 연산이 결국은 근삿값으로 수행되고 있어서 위의 수식과 같이 batch gradient descent를 사용해서 최적화를 수행해줬다고 합니다.
DML architecture
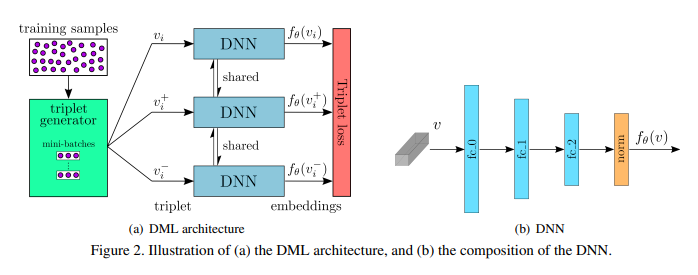
위 그림이 이 논문에서 사용하는 DML의 그림입니다. 왼쪽이 구조도이고, 오른쪽이 DNN의 세부 구조도입니다. 위에서 Triplet의 구조에 대해 설명드렸는데요. 이 구조를 바탕으로 각각의 쌍을 weight 공유하는 DNN을 통해 학습해서 Triplet loss를 학습합니다. 그러면 최종적으로 각각의 비디오에 대한 embedding을 학습할 수 있습니다.
Video-level similarity computation
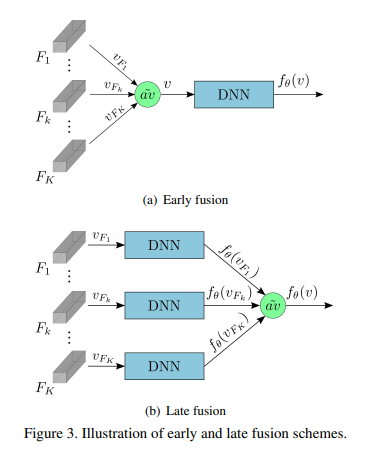
DML의 video embedding을 학습하는 방식도 위 그림처럼 두가지로 나뉩니다. Early fustion과 Late fusion인데요. 일반적으로 early fusion이 좀 더 직관적이고 가볍지만 성능이 떨어진다는 단점이 있고, late fusion은 성능은 더 좋지만 느리다는 단점이 있다네요. 이 논문에서는 둘 다 실험을 하긴 합니다.
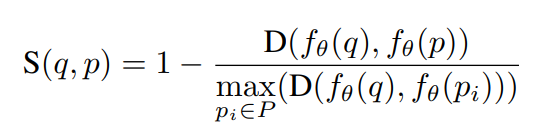
그래서 최종적으로는 비디오들끼리의 유사도는 위와 같이 구합니다. 여기서 q는 query 비디오를 뜻하고, p는 database video들을 말합니다.
Triplet Generation
자 그럼 triplet이 뭐고, 이걸로 학습하는 방법까지는 알았는데 정작 이 triplet을 어떻게 구하는지에 없었죠? 그 부분이 지금부터 등장합니다. 일단 이 triplet은 미리 알아야 학습을 할 수 있기 떄문에 이게 큰 단점입니다. (제가 리뷰한 TCA에서는 이 단점을 해결하기 위해 다른 방법론을 제시했죠?)
그렇다고 해도, 이게 비디오들끼리 랜덤으로 쌍을 만들면 이론상 엄청나게 많은 쌍이 만들어집니다. 당연히 그렇게 만들어진 triplet이 비디오들의 관계를 잘 표현하고 있지 않겠죠? 그래서 이 논문에서는 hard candidate를 만들어서 사용합니다. (학습 할 때는 1000개씩만 씁니다.)
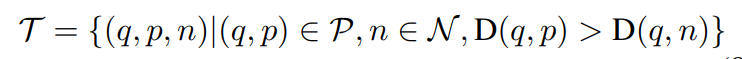
어쩃든 위와 같은 수식으로 만들어집니다. (q는 query, p는 positive, n은 negative) video descriptor를 바탕으로 이 조건에 만족하는 triplet을 만듭니다.
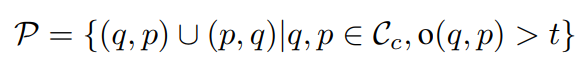
DML에서는 VCDB라는 대용량 video copy detection 데이터셋을 이용했는데요. 라벨링된 구간이 있는 비디오들 끼리는 유사점이 있다는 것이기 때문에 이를 바탕으로 비디오가 theshold t이상 겹치면 query-positive 쌍으로 결정했습니다. Negative 비디오는 Triplet 수식을 이용했고, VCDB의 distractor 중에서 저 조건을 만족하는 비디오들을 선택합니다.
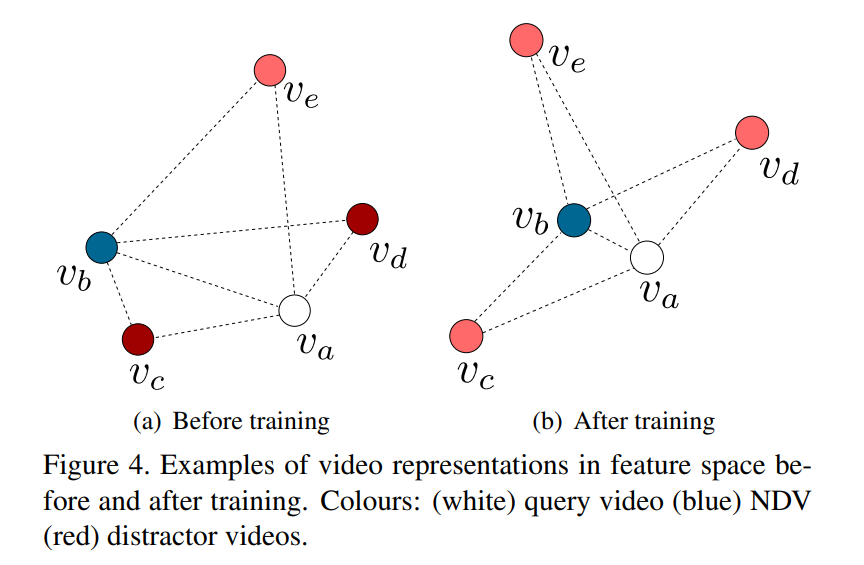
학습 과정을 보면 위와 같이 된다고 하네요. Distractor라고 부르는 비디오가 negative 비디오들인데요. 이 비디오들과의 embedding은 멀어지고, positive와는 가까워지는 모습입니다.
Experiments
평가는 모두 CC_WEB_VIDEO에서 수행되었습니다. 논문 저자는 같은 데이터셋으로 학습하고 평가하는 기존의 방법론들의 성능이 과도하게 잘 나왔다고 생각한다고 말하는 부분이 있었는데, 이 논문에서는 VCDB로 학습하고 CC_WEB_VIDEO로 평가해서 이러한 문제 제기도 해결하려는 모습을 보여줍니다.
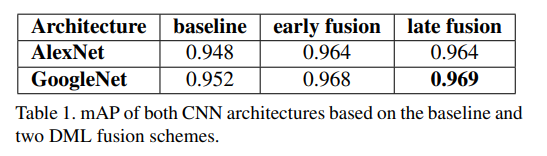
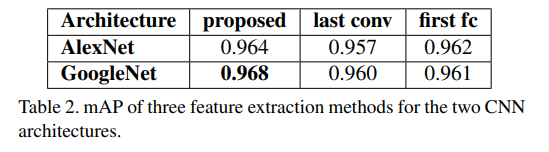
위 두 성능 표는 DML의 DNN을 학습할 때 fusion 방식에 대한 성능 비교와 feature를 추출하는 위치에 따른 성능 비교입니다. proposed 방법론이 max-pooling을 통한 방법인데, 논문 저자들이 제안한 방법이 다른 방법보다 성능이 좋았다고 합니다.

기존의 SOTA 방법론들과 비교해도 성능이 좋은데요. DML을 CC_WEB_VIDEO로 학습하고 평가한 수치도 함께 기재되어 있습니다. 당연히 그 성능이 좋긴하지만, vcdb로 학습하고 평가한 성능도 우수한 것을 확인할 수 있습니다.
유사도를 계산하는 방식이 기존에 알던 거랑 조금 차이가 있는 것 같습니다.
저 similarity의 이름은 무엇인가요? 또한 저 similarity를 사용하는 것은 어떤 특징을 가질 수 있나요? (가령 코사인 유사도는 1에 가까울 수록 두 벡터가 유사하다 볼 수 있다 이런식으로..?)
유사도 자체는 euclidian distance로 계산하기 때문에 그건 익숙할 것 같고. 논문마다 video to video similarity를 구하는 방식은 차이가 있는 것 같습니다. ViSiL에서는 matrix를 만들어서 학습하고 여기서는 위와 같은 수식을 쓰는 거죠. 일단 저 수식에서 아래 P는 M개의 candidate 비디오에 대한 [latex]\{p_i\}_{i=1}^M ∈ P[/latex]를 만족하는 수식을 의미합니다. 논문에서는 딱히 어떻게 된다는 설명이 없어서 생각해보면, 결국은 여기서 말하는 유사도는 embedding을 학습하기 위함이기 때문에 max를 통해서 가장 유사한 비디오와 유사하지 않은 비디오 간의 거리를 학습한다고 보면 될 것 같습니다.