Abstract
labeled와 unlabeled 데이터를 모두 탐색하여 semi-supervised semantic segmentation문제를 연구한다. consistency regularization 방식으로 동일한 입력 이미지에 대해 서로 다른 초기화된 두 segmentation 네트워크에 일관성을 부여하는 방식인 “cross pseudo supervision(CPS)”를 제안하였다. 각 모델로 생성한 pseudo label은 상대 네트워크로 들어가 standard cross-entropy loss로 학습된다. CPS의 역할은 1. 동일 입력에 대해 두 모델 사이에 유사한 예측을 장려, 2. pseudo label을 이용해 unlabeled 데이터로 학습 데이터 확보이다. Citscapes와 PASCAL VOC 2012에서 SOTA semi-supervised segmentation 성능 달성하였다.
Introduction
segmentation은 픽셀단위의 정답이 필요하여 라벨링 과정에 많은 비용이 들어간다. 이로인해 semi-supervised segmentation이 중요한 문제가 되었다. 해당 논문에서 제안한 “cross pseudo supervision(CPS)”방식은 동일 구조를 가지고 다르게 초기화 된 두 모델에, 동일한 입력 이미지를 넣어 예측 결과를 pseudo label로 이용하여 학습 데이터를 추가하는 방식이다. CPS 학습 방식을 이용한다면 기존의 consistency regularization과 같이 예측의 불확실성을 낮출 수 있고(decision boundary lies in low-density regions) 또한, 학습 데이터를 추가할 수 있어 성능이 향상된다.
Approach
\mathcal{D}^l 를 labeled, \mathcal{D}^u 를 unlabeled 데이터 셋이라 하고, 두 데이터셋을 모두 학습에 사용하는 것이 이 학습 방식의 목표이다.
Cross pseudo supervision
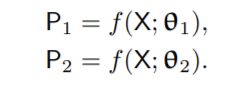
P_1 (P_2)은 f(θ_1) (f(θ_2))로 부터 나온 segmentation confidence map이고, f(θ_1)와 f(θ_2)는 서로 같은 구조를 가지고 초기화만 다르게 된 두 네트워크이다. 두 모델은 서로 예측 결과를 pseudo label로 이용하여 학습을 진행하게 되고, loss는 supervision loss인 \mathcal{L}_s과\mathcal{L}_{cps} 로 구성된다. \mathcal{L}_s는 labeled 데이터를 이용하여 두 모델의 예측 결과와 정답의 픽셀 단위 cross-entrophy loss이고, \mathcal{L}_{cps}는 \mathcal{D}^u 와 \mathcal{D}^l 에 대해 상대 네트워크의 출력 값을 정답값으로 하는 cross-entrophy loss이다.
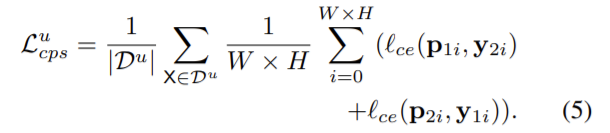
total loss \mathcal{L} = \mathcal{L}_s + λ\mathcal{L}_{cps}이다.
Incorporation with the CutMix augmentation
CutMix augmegntation(두 이미지를 선택하여, 하나의 이미지 일부분에 다른 이미지를 붙이는 방식)을 적용하여 생성한 이미지도 f(θ_1)와 f(θ_2)에 넣었다.
Discussions
cross probability consistency
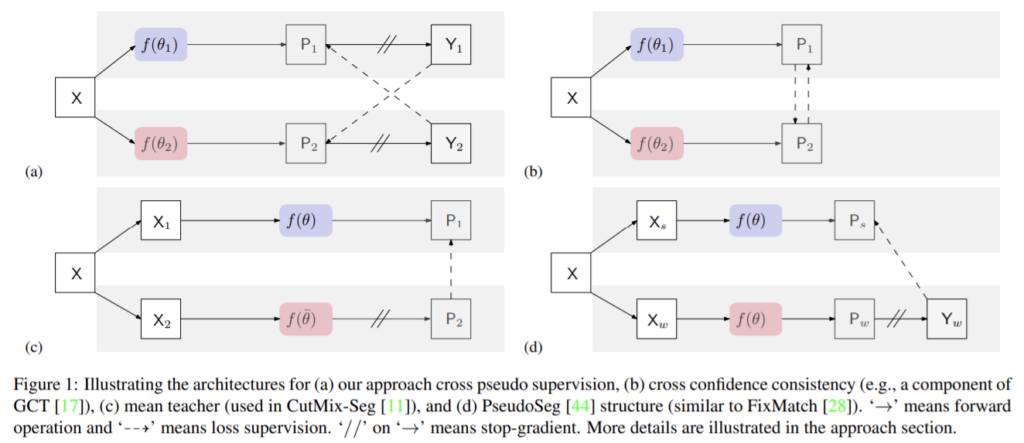
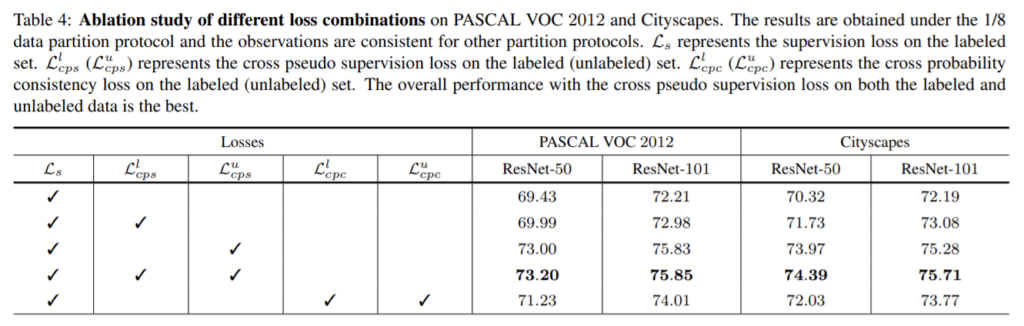
cross probabilityconsistency는 그림1의 (b) 방식으로, 두 네트워크의 교차 확률이 유사하도록 한다. 이와 유사하게 제안한 CPS도 두 변동적인 네트워크가 서로 유사하도록 학습한다. 이때 unlabeled 데이터에 대해 pseudo label을 이용하여 데이터를 보완함으로써 표4에서 확인할 수 있듯이 성능을 향상시킨다. (표4의 마지막행 결과가 cross probability consistency, 4번째 행의 결과가 CPS 성능)
Mean teacher
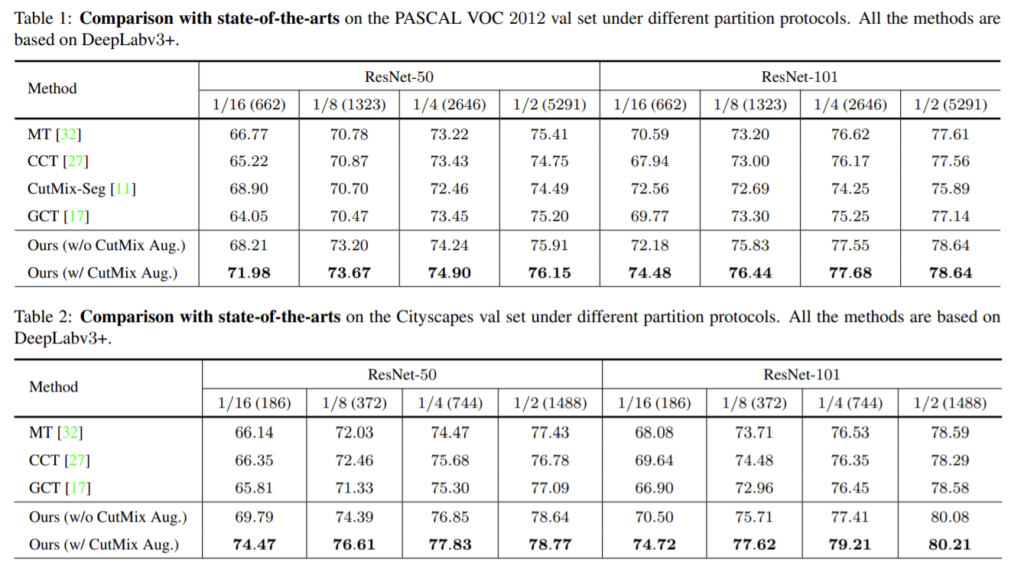
그림1의 (c)의 방식으로, student 네터워크인 f(θ)와 meant teacher인 f(\bar{θ})에 대해 unlabeled 이미지에 다른 augmentation을 적용하여 사용한다. \bar(θ)는 moving average of θ이다. 아래 표 1과 2를 통해 제안한 방식이 mean teacher 방식보다 성능이 좋은 것을 확인할 수 있다.
Single-network pseudo supervision
그림1의 (d)와 유사한 방식으로, 같은 네트워크에서 예척 값을 pseudo label로 이용한다. 이 방식은 제안한 CPS와 유사한 방식이지만, 동일한 네트워크를 사용함으로써 pseudo label을 이용한 결과가 supervision에 가까워지기 위해 네트워크를 학습하는 경향이 있어 다른 방향으로 수렴할 수 있다. 즉 변동적인 두 네트워크를 이용함으로써 잘못된 방향으로 과적합되지 않도록 한다.
PseudoSeg
그림1의(d) 방식으로, 약한 augmentation을 적용한X_w와 강한 augmebntation을 적용한 X_s가 동일한 네트워크에 사용하여 pseudo label은 X_w의 결과로 X_s를 supervised 방식으로 학습한다.
Experiments
Dataset
- PASCAL VOC 2012
– 20 classes - Cityscapes
– 19 classes
Result
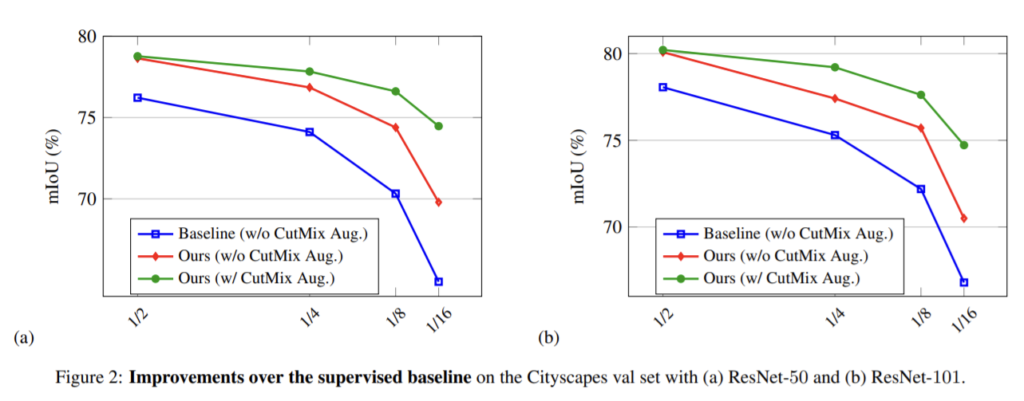
두 결과 모두 baseline보다 성능이 향상되는 것을 확인할 수 있다.
Empirical Study
- Cross pseudo supervision
표4를 통해 loss의 영향을 확인하였다. labeled와 unlabeled 데이터를 모두 이용하는 것이 가장 좋은 성능을 보인다. - trade-off weight λ
λ의 영향을 확인한 결과 loss의 λ는 PASCAL VOC 2012에서는 1.5, Cityscapes에서는 6에서 가장 좋은 성능을 보였다. - Combination/comparision with self-training
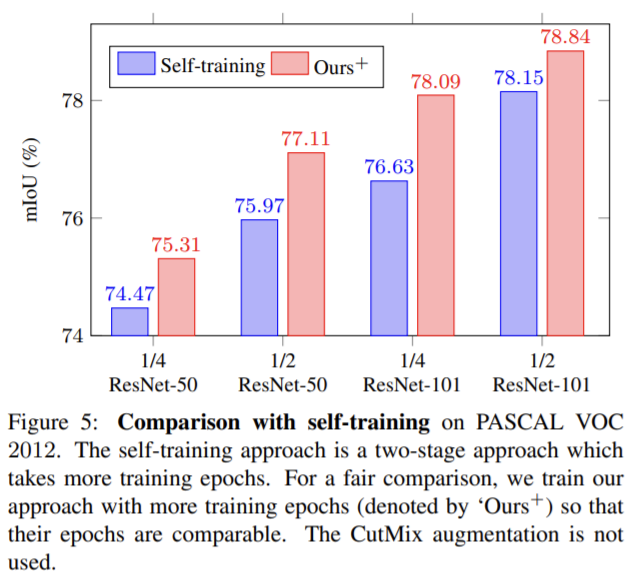

다른 semi-supervised 방식들과의 성능 비교실험이 풍부하게 들어있다고 판단하여 논문을 읽어보았습니다. 실험이 많고, 정리가 잘 되어있습니다.
좋은 리뷰 감사합니다.
최근 세그멘테이션에서 semi-supervised 방식을 많이 사용하능 것 같네요. 그런데 혹시 CPS가 consistency regularization보다 좋은 성능을 가져왔다고 하셨는데 이를 비교하는 실험에 대한 살명은 없나요? 어떤 면에서 더 좋은지 구체적으로 알고싶아서 여쭤봅니다!