저는 이번에 다크데이터와 관련하여 Semi-Supervised Learning 관련 논문을 리뷰해보고자 합니다. Semi-supervised learning과 관련해서는 워낙 많은 관심을 받는 분야여서 많은 분들이 잘 알고계실 것이라 생각이 듭니다.
Semi-supervised learning (이하 SSL)이란 간단하게 정리하면 labeled-data 와 Un-labeled-data를 동시에 사용하는 방법론으로, Unsupervised와 Supervised 의 절반이라는 뜻의 Semi를 붙힌 것입니다.
그 차이는 아래 그림을 통해 쉽게 확인할 수 있을 것 같습니다. ** 색이 있는 것이 레이블링된 데이터*
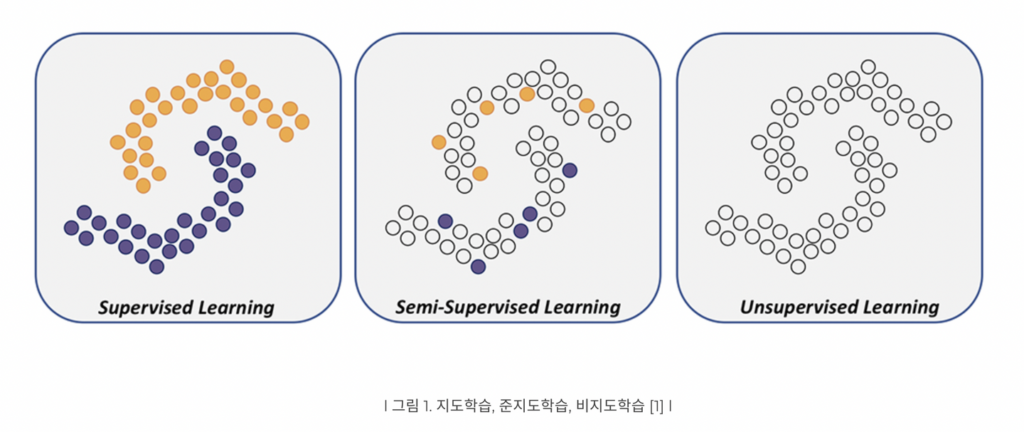
제가 이번에 소개해드릴 논문 역시 Semi-supervised learning 과 관련된 논문으로, 그 중 imbalanced-class 불균형 데이터인 상황을 해결하는데 집중하였습니다.
그럼 리뷰시작하겠습니다.
[CVPR 2021] CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning

Intro.
SSL에서 흔히 사용되는 Pseudo-labeling 기법이란, 일부 labeled 데이터로 먼저 모델을 학습 후, 라벨이 없는 데이터에 대한 해당 모델의 예측값을 가짜 GT (pseudo-label)로 설정하여 학습하는 방법입니다.
Semi-supervised Learning과 관련된 연구는 활발하게 지속되고 있지만, 그 안에서 Imbalance-Data를 다루는 연구가 많지는 않다며 운을 띄웁니다.
게다가 라벨이 없는 데이터를 다루는 SSL에서는 많은 문제를 발생시킬 수 있는데요, 앞서 설명한 Pseudo-labeling 을 사용하는 접근법에서는 특히 그렇습니다.
왜냐하면 불균형 데이터로 학습된 수도 레이블 생성 모델은 majority-class로의 편향되고, 곧 이 수도 레이블을 사용한 이후의 학습에도 이어져 이 bias가 강화되어 모델의 성능이 저하되는 현상이 발생하기 때문입니다.
이런 치명적인 문제임에도 불구하고 기존 연구들은 불균형 문제를 다루지 않았죠.
따라서 본 논문에서는 아래 그림과 같이 labeled와 unlabeled 가 비슷한 분포를 갖는 불균형 데이터에 대한 문제를 해결하고자 하였습니다.
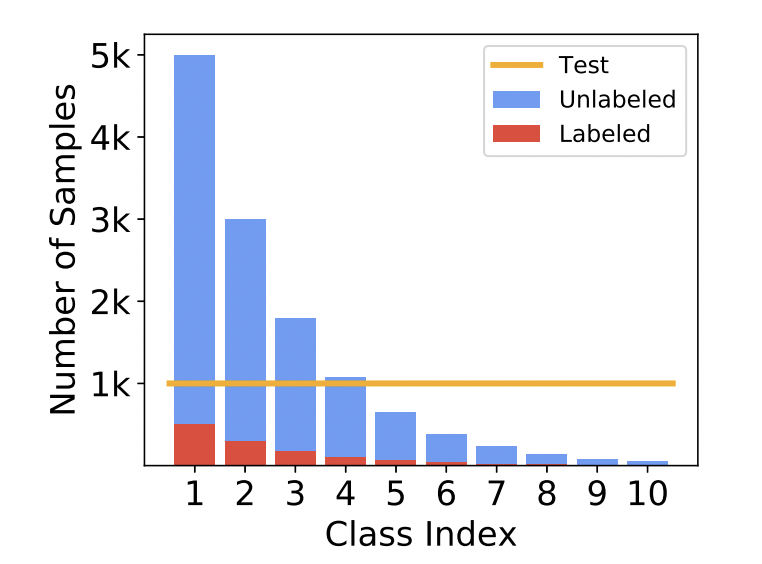
여기서 특이한 점은 다음과 같은데요. 저자가 말하길 기존 불균형 데이터로 학습한 기존 SSL의 성능 저하는 minority-class의 recall 이 작아서라고 합니다. 이 때 동일한 minority-class의 precision은 굉장히 높았다고 합니다.
뿐만 아니라 FixMatch에서 역시 불균형 데이터로 학습한 결과 minority-class의 리콜이 낮아 전반적인 정확도가 낮아지긴 하지만, precision의 경우 거의 완벽에 가까운 결과를 보였다고 하였습니다.
따라서 저자들은 소수 클래스에서 모델이 높은 precision을 가진다는 것을 사용하였습니다.
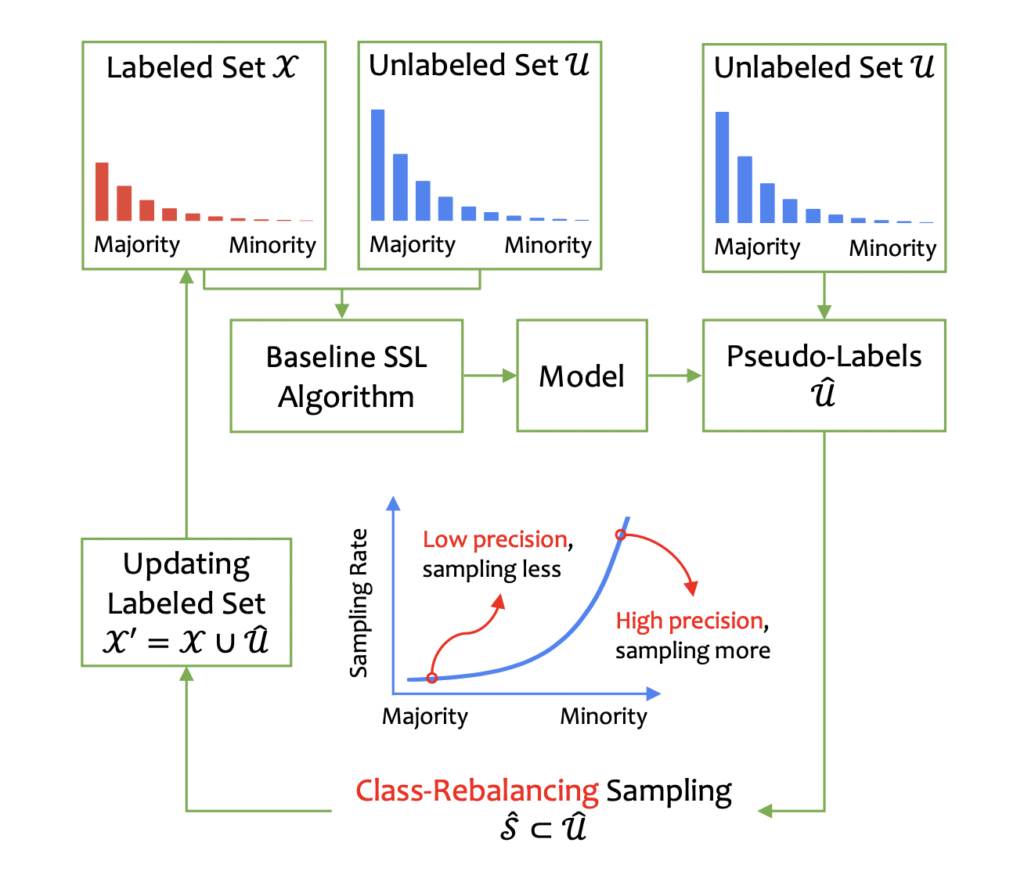
본 논문에서는 Unlabeled-set과 Pseudo-labeled set을 적응적으로 샘플링하여 원래 labeled-set을 보완한 후, baseline SSL 모델을 재학습하는 class-rebalancing selftraining scheme (CReST) 를 제안합니다. unlabeled-set의 pseudo-label이 label-set에 추가되어 재학습 과정에서, minority class로 예측되는 데이터를 (precision이 높으니) 더 높은 확률로 샘플링할 수 있도록 확률적 업데이트를 적용시킨 방법입니다. 이 업데이트 확률은 labeled-set에서 추정된 데이터 분포 함수가 됩니다.
아래 각 과정에 대해 Method를 통해 자세하게 알아보도록 하겠습니다.
Method
여기서의 목표는 class-imbalanced sets X 와 U 가 주어졌을 때, balanced 한 분포를 만드는 분류기를 학습하는 것입니다.
앞서 설명하였듯 대부분의 SSL에서는 수도 레이블링 접근법으로 구성됩니다. 먼저 labeled-set 으로 모델을 학습하고, 수도 레이블을 발생시켜 unlabeled & labeled-set 모두에 모델을 다시 학습시킵니다. 그렇기 때문에 수도레이블의 정확도는 결국 최종 성능에 중요한 요소일수밖에 없습니다.
A closer look at the model bias
CIFAR-LT는 기존 지도학습에서의 클래스 불균형 문제를 다루기 위해 다양한 클래스 불균형 비율로 만들어진 데이터셋입니다. Intro에서 언급했던 것처럼 정말 소수 클래스에서의 recall은 작고, precision은 높은 지에 대한 실험을 아래 그림에서 확인할 수 있습니다. 아래 그림은 각 데이터에 대한 Fixmatch 모델의 Recall, Precision 그래프입니다. *(좌) imbalance ratio γ = 100인 label fraction β = 10%을 가지는 CIFAR10- LT, (우) imbalance ratio γ = 50인 label fraction β = 30%인 CIFAR100-LT.
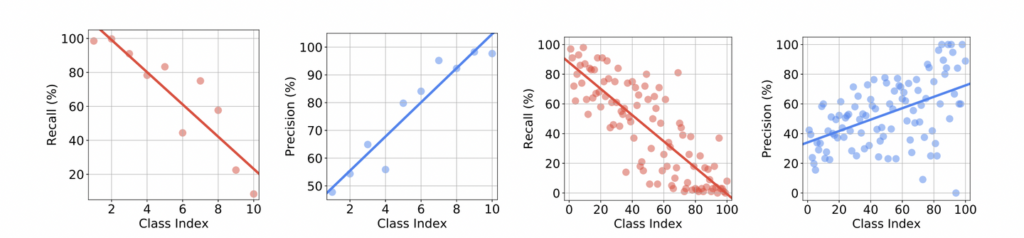
(class index가 작을 수록 majority, 클수록 minority 합니다)
첫번째 그래프인 CIFAR10-LT을 보면 가장 많은 클래스와 두 번째로 많은 클래스의 recall은 각각 98.5%와 99.7%인 반면, 가장 작은 클래스의 recall은 8.4%입니다. 다시 말해, 모델은 majority-class에 대해 크게 편향되었습니다.
그런데 두번째 네번째 그래프에서의 minority-class에서는 굉장히 높은 precisio을 보입니다. 오히려 majority-class에서 상대적으로 낮은 precision을 기록되는데요, 이는 많은수의 minority-class가 majority-class 중 하나로 예측된다는 것을 의미하게됩니다.
따라서 저자들은 minority-class의 높은 precision에서 착안하여, 데이터 균형 문제를 해결하고자 하였습니다.
Class-rebalancing self-training
계속 설명들었지만, 해당 논문에서 차용하는 SSL 에서의 과정은 다음과 같습니다 (1) teacher 모델을 얻기 위한 labeled-set에 대한 지도학습 (2) 이 teacher 모델의 예측은 곧 수도 라벨로서, (3) 이 수도 라벨의 쌍은 labeled-set에 추가되어 다시 학습되게 됩니다. 이 절차를 반복하는 것이 Self-training 인데요.
저자는 클래스 불균형을 해결하기 위한 self-training에 대해 두 가지를 제안하였습니다.
- (1) 단계에서 teacher 모델을 학습하기 위한 데이터를 레이블링된 데이터에 대해서만 사용하는 것이 아닌, SSL을 사용한 labled-data / unlabeled-data를 모두 사용
- 모든 샘플을 labeled-set에 포함하는 것이 아닌, 선택된 부분 집합으로 labeled-set을 확장하는 것입니다. 즉, 클래스 재조정 룰에 따라 \hat{S}을 선택하게 됩니다. 클래스 I의 빈도가 낮을수록 I의 수도 레이블 데이터 세트가\hat{S}에 포함되게 됩니다.
이 때, Labeled-dataset에서의 클래스 분포를 추정하며, 클래스 l로 예측되는 레이블이 없는 샘플을 다음과 같은 비율로 \hat{S}에 포함되게 됩니다.
다시 정리하자면, 본 논문의 제안은 다음으로 정리할 수 있습니다.
먼저, 소수 클래스의 precision은 다른 class에 비해 높기 때문에, 초기 teacher model 지도학습을 위한 데이터에 소수 클래스의 수도 라벨링을 추가하는 것은 덜 위험하다.
둘째로, 불균형 문제를 해결하기 위한 소수 클래스 데이터를 추가해야하며, 그래야 수도 레이블링에 대한 편향이 줄어든다. 따라서 클래스 밸런싱 방식으로 수도 레이블을 샘플링하는 간단한 방법을 제안하였다.
Experiments
데이터셋은 앞서 설명한 것처럼 데이터 불균형 정도를 나타내는 γ 와 라벨이 있는 데이터의 정도인 β 에 따른 CIFAR-LT 를 사용하였습니다.
아래 그래프는 본 논문이 제안하는 클래스 불균형 해결을 위한 CReST 적용 전 후 비교에 대한 결과를 확인할 수 있습니다. 가장 대표적인 SSL방법론인 FixMatch에 적용한 결과를 비교하였습니다.
FixMatch는 불균형 비율이 50 에서는 좋은 성능을 보이지만 비율이 증가할때마다 성능 저하가 크게 발생합니다. CReST를 적용한 결과는 최대 9.6%의 성능 향상을 가져온 것을 확인할 수 있습니다. 또한 라벨이 있는 샘플 수가 증가함에 따라 성능 차이도 있었습니다.
불균형 비율이 중간일 때 모델이 labeled-set을 증가시키기 위해 더 정확한 수도 레이블이 지정된 샘플을 찾기 때문에 성능이 증가하였다고 판단했다고 합니다.
그러나 불균형 비율이 200과 같이 매우 높을 때는 오히려 minority-class의 학습 데이터수가 많지 않아 성능이 크게 저하하였다는 결론을 내립니다.

ImageNet127에 대한 실험도 진행하였습니다. ImageNet12이란 ImageNet의 1000개 클래스를 127개 클래스로 그룹화한 데이터셋으로, γ =286의 불균형 데이터셋입니다. 실험을 위해 labeled로는 β = 10% 으로, 테스트는 그래도 유지하여 사용하였습니다. 결국 대규모 데이터셋에서도 성능 향상을 보였다는 것을 확인하였다고 합니다.
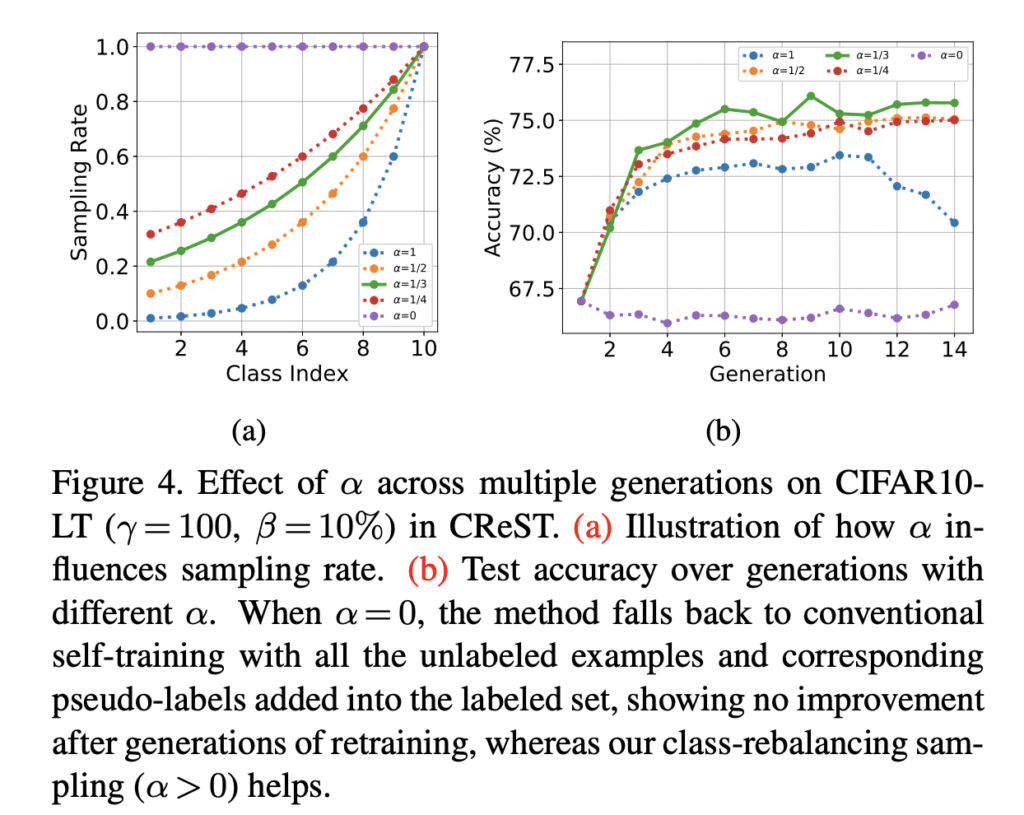
굉장히 간단한 방식으로 불균형 데이터를 다룬 논문이었습니다. 아직 본격적으로 다크데이터에서의 적용 여부를 확인하기는 어려우나, 추후 이러한 문제에 봉착한다면 한번 간단하게 적용해봐야겠다는 생각이 들었습니다.
labeled와 unlabeled의 분포가 유사할 경우 잘 작동한다고 하셨는 데, 여기서 unlabeled 데이터의 분포는 정답 라벨의 분포를 알아야 하는 것인가요?아니면 pseudo-label의 분포를 이용하는 것인가요??
안녕하세요 좋은 리뷰감사합니다
클래스의 크기가 작은경우 precision이 높은경항이 있다고 하였는데 이것이 클래스에 해당하는 데이터가 적어 다양성이 부족하기 때문이 아닌지 궁금합니다. 맞다면 이러한점으로 예측되는 어려움이 있나요?