

이전 Video Classification task에서는 주로 한 video에서 하나의 clip을 샘플링하고, 그 clip이 video-level의 label을 잘 표현하도록 모델을 학습해 왔습니다. 그러나 이와 달리, 학습된 모델을 평가할 때는 하나의 video를 uniform하게 여러 개의 겹치지 않는 clip으로 나누고, clip들에 대한 예측 값의 평균으로 해당 video의 label을 판단하였습니다. 이처럼 많은 clip을 사용하여 평가를 한 이유는 한 video 내에 존재하는 일정 구간에 bias 되지 않는 예측을 하기 위함 입니다. 그럼 마찬가지로 일정 구간에 bias되지 않은 학습을 하기 위해서는 한 video에서 여러 clip을 사용하는 것이 좀 더 나은 해결책으로 보일 수 있습니다. 하지만, 여러 clip을 사용할 경우, 학습 시간도 오래걸리고 많은 GPU 메모리도 필요한 이유로 인하여 기존 방법론들은 학습에서 하나의 clip만 사용하는 기법을 취해 왔던 것입니다.
물론, 학습 과정에서 한 video 마다 한 clip만을 샘플링하여 사용했을 때 생기는 문제를 다루었던 방법론이 없지는 않았습니다. TSN과 ECO라는 방법론은 temporal coverage를 넓히기 위해 한 video를 동일한 여러 개의 segment로 나누고, 각 segment마다 랜덤하게 하나의 짧은 snippet 혹은 frame을 샘플링 하였습니다. 그러나, GPU 메모리 cost를 줄이기 위해, lightweight한 3D CNN 혹은 2D CNN을 사용하였고, 이러한 모델들로 인해 성능의 상한이 제한되었습니다. 또한, TSN의 경우 각 segment 마다의 output을 단순히 평균내는 방식으로 aggregate 하였습니다. 다른 방법론으로는 LFB라는 방법론이 존재합니다. LFB는 사전에 한 video에서 여러 clip을 uniform하게 샘플링하여 context feature를 메모리에 저장하고, 학습 과정에서 한 clip을 augment하기 위해 이같은 context feature를 사용하였습니다. 그러나, context feature를 생성할 때 학습 과정에서 사용하는 모델과는 다른 모델을 사용하고 사전에 생성하기에, context feature가 학습 과정동안 update 되지 않게됩니다. 이로 인해 LFB의 context feature가 특정 task에 활용될 경우, 해당 task에 optimize 되지 못한다는 단점이 존재하였습니다.
본 논문의 저자도 한 video 마다 한 clip을 사용했을 때 생기는 문제를 해결하여 long-range temporal dependency를 모델이 파악할 수 있도록 collaborative memory라는 framework를 제안하였습니다. 해당 방식은 기존 다른 방법론들과 달리 end-to-end 방식으로 학습되며, 한 video 내 여러 clip 간의 효율적인 정보 교환을 위한 collaborative memory scheme을 제안하였습니다. 또한, GPU 메모리 제약을 해결하기 위한 몇가지 기법도 소개하였습니다.
1. Method
1.1 Overview of the Proposed Framework
제안된 collaborative memory는 현존하는 여러 video recognition archtecture에 모두 적용가능하며, 이들이 end-to-end 방식으로 video-level learning이 가능하도록하는 것이 목표입니다. 이를 위해 제안된 framework는 한 video에서 여러 clip-level feature를 추출하는 Multi-clip sampling, 여러 clip-level feature 간의 정보 교환을 위한 Collaborative memory, 마지막으로 해당 video의 optimize를 위한 Video-level supervision 으로 구성됩니다.
- Multi-clip sampling
한 video 에서 N 개의 clip을 샘플링하며, 한 clip에는 L개의 연속된 프레임이 존재합니다. L개의 연속된 프레임의 시작위치는 전체 video에서 랜덤 선택됩니다. 이렇게 샘플링된 clip을 R3D, SlowFast와 같은 기존 video recognition backbone network의 입력으로 두며, clip-level feature X_n 을 생성합니다. 여기서 n은 N 개 clip의 인덱스를 의미합니다.
- Collaborative memory
앞서 추출된 clip-level feature 들이 서로 정보 교환을 하며 video-level learning을 하기 위해 Memory interactions과 Context infusion 두 가지 과정으로 나뉩니다. Memory interactions라는 과정을 통해 모든 clip-level feature들이 정보교환을 하게 되고, Context infusion이라는 과정을 통해 매 clip-level feature들이 video-level context 정보를 활용할 수 있게 됩니다. 자세한 내용은 다음 섹션에서 다루도록 하겠습니다.
- Video-level supervision
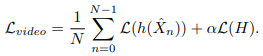
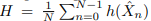
앞선 과정으로 context infusion된 clip-level feature \hat{X}_n 를 식 (1)과 같은 목적 함수로 optimize 하게 됩니다. 식 (1)에서 h는 classifier, \mathcal{L}은 cross-entropy를 의미하며, clip-level loss와 clip-level feature 들의 평균으로 생성된 video-level loss의 합으로 구성되어 있습니다.
1.2 Collaborative memory
해당 논문이 clip-level feature 간의 정보교환을 위해 사용한 collaborative memory scheme은 앞서 말씀드렸던 대로 크게 두가지로 나뉩니다. 먼저 한 video의 clip-level feature들 간의 정보 교환을 통해 global memory를 만들고자한 Memory interactions 과정을 거치고, 그 후 각 clip-level feature에 global context 정보를 주입하고자하는 Context infusion 과정을 거칩니다.
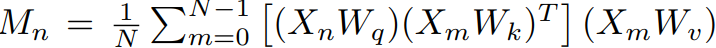
Memory interactions 과정에서는 특정 n번째 clip에 global context 정보를 주입하기 이전, global memory를 생성하게 됩니다. 이는 associative network [링크] 에서 영감을 받아, 식 (2)와 같이 특정 n번째 clip과 다른 clip 간의 행렬 곱들의 평균으로 구성되며, 여기서 M_n은 n번째 clip에 대한 global memory, W_q, W_k, W_v는 X_n의 channel d 를 d'으로 낮춰줄 learnable matrix 입니다. Self-attention과 유사해보이지만, 모든 clip-level feature들 간의 pairwise한 연산이 없어 계산 속도나 메모리 면에서 효율적인 것이 다르다고 합니다.
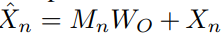
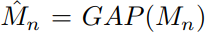
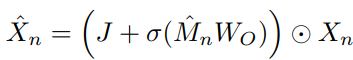
Context infusion 과정에서는 앞서 n번째 clip에 대해 생성된 global memory를 n번째 clip에 주입하게됩니다. 이때 통합 방식으로는 식 (3)과 같이 흔히 사용되는 residual connection이 고려될 수 있습니다. 여기서 W_o는 d' \times d 크기로, 줄였던 차원을 맞춰주기 위한 matrix입니다. 그러나, 이와 같은 방식은 M_n이 X_n보다 상대적으로 정보량이 많아, 학습 과정에서 모델이 M_n에만 의존하게 하여 성능 저하를 일으키게 됩니다. 이를 막고자, 식 (4)와 같은 feature gating operation으로 모델이 특정 n번째 clip-level feature에 직접적으로 접근할 수 있도록 fusion하였습니다. 여기서, J는 모두 1로 구성된 matrix이고, \sigma는 sigmoid를 의미하며, \odot 은 elementwise 연산을 의미합니다. 식 (4)를 통해, clip-level feature에서 global memory를 참조하여 특정 위치는 두 배 더 크게 attention을 주고, 특정 위치는 0으로 두거나 부호를 바꿔주게 됩니다.
1.3 Coping with the GPU Memory Constraint
한 video에서 여러 clip을 사용함으로써 발생할 수 있는 GPU 메모리 문제를 해결하고자 저자는 두 가지 방식을 소개하였습니다.
- Batch reduction
만약 다른 방법론에서 사용하는 한 iteration마다의 mini-batch 크기가 B라면, 이를 clip의 개수 N으로 나눈 \hat{B}=B/N을 새로운 mini-batch 크기로 사용하는 전략입니다. 그리고 batchnorm layer에서 parameter 업데이트에 clip diversity를 향상시키기 위해, batchnorm statistics를 계산할 때 서로 다른 video의 clip 간 계산을 하였습니다.
- Multi-iteration
한 video에서 N 개의 clip을 한꺼번에 불러오는 대신, 하나씩 불러와 연산하는 loop unrolling을 적용하였습니다. 이를 통해 GPU 메모리를 효율적으로 관리하였다고 합니다.
2. Experiments
2.1 Evaluating Collaborative Memory
- Effectiveness of video-level learning
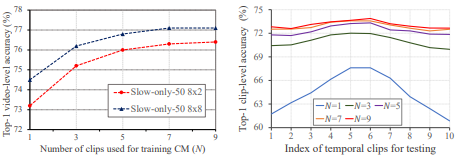
Fig 3은 N개의 clip을 제안된 collaborative memory(CM)을 활용하여 video-level learning 한 것의 효력을 보여주는 그림 입니다.
Fig 3의 왼쪽 그림은 각각 Slow-only-50 backbone network를 2프레임의 간격으로 총 8프레임 사용한 것과 8프레임 간격으로 총 8프레임 사용한 것의 N 값의 따른 성능 그래프 입니다. 간격이 다른 것은 한 clip의 coverage가 다름을 의미하며, N=1 즉 CM을 사용하지 않았을 때 8×2의 경우 coverage가 작기때문에 8×8에 비해 낮은 성능을 보입니다. 그러나 CM을 활용하여 N>1인 경우, 두 그래프 모두 성능 향상을 보이며, 이는 CM을 통해 coverage를 늘린 것이 성능 향상에 효과적이었음을 나타냅니다.
Fig 3의 오른쪽 그림은 한 video를 총 10개의 segment로 나누고, N 크기에 따라 해당 위치의 clip을 활용했을 때의 성능입니다. N=1 즉 CM을 사용하지 않았을 경우 주로 중앙에 위치하는 clip들의 성능이 가장자리보다 높은 것을 보이며, 이는 video 내의 정보가 주로 중앙에 위치하였기 때문입니다. 그러나 N>1일 경우, 모든 위치의 clip의 성능이 상대적으로 균일해지는 경향성을 보이며, 성능의 평균치도 높아지는 것으로 CM의 효력을 알 수 있습니다.
- Generalization to different backbones
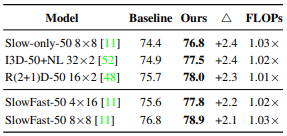
Table 1은 backbone network에 CM을 적용하였을 때의 성능 향상을 나타냅니다. 모든 backbone에서 2%이상의 성능 향상을 보였으며, GFLOPs의 경우 4개의 learnable matrix만이 추가 되었기에 기존 대비 거의 변화가 없는 것을 알 수 있습니다.
2.2 Ablation study
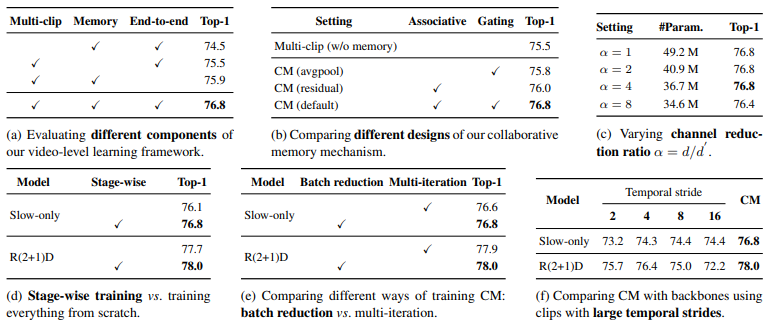
- Assessing the components in CM framework
Table 2의 (a)는 CM framework의 component에 대한 ablation study 입니다. 한 video에서 여러 clip이 아닌 한 clip만을 사용하였을 때 2.3퍼센트의 가장 큰 하락을 보이고, global memory 없이 clip-level feature를 독립적으로 사용하였을 때 1.3퍼센트의 하락을 보이는 것으로 CM이 여러 clip 간의 정보 교환을 통해 성능 향상을 이끌어냈음을 알 수 있습니다.
- Collaborative memory design
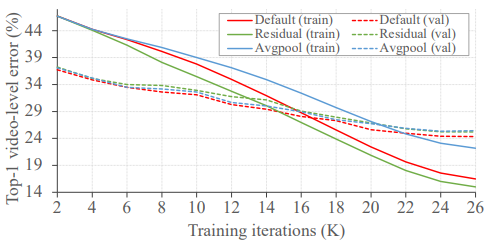
Table 2의 (b)는 CM을 설계할 때 고려했던 사항에 대한 ablation study 입니다. 식 (2)가 아닌 모든 clip-level feature를 단순히 평균한 뒤 제안된 feature gating 방식으로 infusion할 경우 0.3퍼센트의 성능 향상 밖에 보이지 못했으며, feature gating 방식이 아닌 residual 방식으로 infusion할 경우 0.5퍼센트의 성능 향상 밖에 보이지 못했습니다. 반면, 두 과정을 모두 거친 CM의 경우 1.3퍼센트의 성능 향상으로, CM의 두 과정이 효과적으로 설계되었음을 보입니다.
또한 Fig 4를 통해, 앞서 언급했던 대로 residual 방식은 모델이 global memory에 의존하게 하여 overfit된 반면, feature gating 방식은 이를 완화시켜 준 것을 알 수 있습니다.
그리고 Table 2의 (c)에서 learnable matrix를 통해 feature의 channel을 얼만큼까지 줄일 수 있는지 ablation study를 진행하였습니다. 실험했을 때, 4배까지 줄여도 성능이 유지되었고 이를 통해 default 세팅을 4로 두었다고합니다.
- Training strategies
제안된 CM은 각 backbone network에 적용될 때, backbone network 자체를 먼저 학습하고 backbone+CM으로 다시 학습하는 stage-wise 학습 기법을 사용합니다. Table 2의 (d)에서는 이에 대한 ablation study를 보이며, stage-wise 학습 기법을 사용하지 않는 경우 scratch부터 backbone+CM을 학습하였습니다. Stage-wise한 학습 방식을 사용하였을 때 전체적인 성능 향상을 보엿으며, 이는 사전 학습된 backbone network가 well-initialize된 clip-level feature를 제공해주었기 때문이라고 합니다.
그리고 Table 2의 (e)는 GPU 메모리 문제를 해결하기 위한 두 가지 방식에 대해 ablation study를 한 것으로, 두 가지 방법을 썻을 때 전후로 비슷한 성능을 보인다고 합니다. 이를 통해 성능은 유지하되 GPU 메모리 면에서 이득을 취할 수 있었습니다.
- Limitations of temporal striding
마지막으로 Table 2의 (f)는 각 backbone 별로 하나의 clip만을 사용하는 기존 학습 방식을 따르되 clip 내의 frame 샘플링 간격을 넓혀 temporal coverage를 넓혔을 때와 제안된 CM간의 성능 차이를 보여줍니다. 단순히 간격을 넓히게 될 경우, 간격이 커질 수록 성능 하락 또는 상대적으로 낮은 수치로 수렴하는 경향을 보여주는데, CM을 활용할 경우 이들을 넘는 성능 향상을 보여줍니다.
2.3 Comparison with the State of the Art
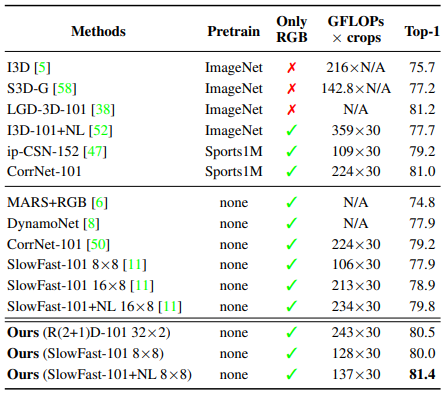
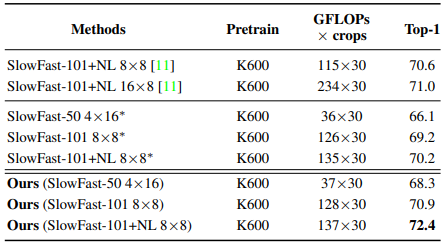
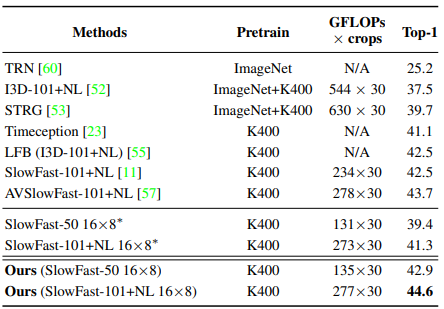
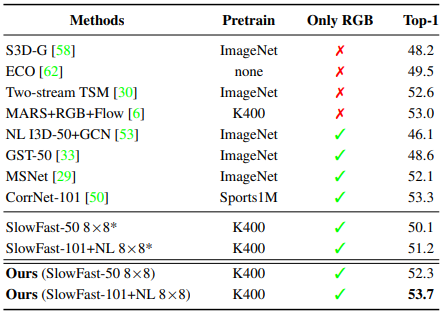
Table 3~6은 각각 Kinetics-400, Kinetics-700, Charades, Something-Something-V1 데이터 셋에서의 제안된 CM에 대한 benchmark입니다. Kinetics 데이터 셋은 주로 짧은 길이의 video로 구성되며, action을 분류하는데에 있어 scene의 역할이 큰 데이터 셋입니다. Charades의 경우, 약 30초의 상대적으로 길이가 긴 action video로 구성되어 있어 long-range dependency를 확인하기 좀 더 유리한 데이터 셋입니다. Something-Something-V1의 경우 보다 motion에 초점이 맞춰져 있는 action 데이터 셋입니다.
모든 데이터 셋에서 최소 2퍼센트 정도의 성능 향상을 이끌어 냈으며, 눈여겨 볼 점은 좀더 long-range dependency가 나타나는 Charades 데이터 셋에서는 3.5퍼이상의 높은 성능 향상을 보였습니다. 이를 통해 제안된 CM이 coverage를 넓히는데에 효과적이었음을 알 수 있습니다.
2.4 Collaborative Memory for Action Detection
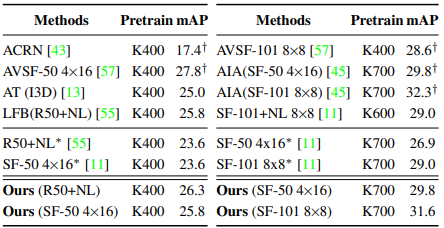
Table 7은 제안된 CM 방식을 video classification 뿐만아니라, action detection task에 적용하였을 때의 성능입니다. 여기에서도 마찬가지로 2퍼센트 이상의 성능 향상으로 제안된 CM이 classfication과 localization으로 구성된 detection framework의 boosting에 도움을 주었음을 알 수 있습니다.
3. Reference
[1] https://arxiv.org/abs/2104.01198