이번 논문은 제가 요새 관심?있어 하는 mutual learning을 semantic segmentation에 적용한 방법론입니다. Mutual Learning에 대한 논문들을 찾아보면 대부분 Classification과 같은 분류에서 많이 사용하고 있고 pixel-level prediction에서는 많이 못본 것 같은데 작년에 Microsoft Research 팀에서 좋은 논문을 작성했더군요.
그럼 리뷰 시작하도록 하겠습니다.
Intro
일단 해당 논문에서 풀고자 하는 task는 논문 제목에서도 아시다시피 Semi-supervised Semantic Segmentation입니다. Semi-supervised learning은 일부 학습 시 모든 데이터에 GT label이 있는 supervised 방법론과 달리 학습에 사용할 수 있는 GT label은 부분적이며 나머지 데이터 셋은 GT label이 없는 unlabled data로 학습을 하게 됩니다.
특히나 annotation이 어려운 semantic segmentation 분야는 unsupervised, semi-supervised 방법론에 대한 연구가 활발하게 진행되고 있는데, 그 중 가장 많이 사용하는 방법은 Pseudo labeling이라고 합니다.
Pseudo label을 만들기 위해서는 그림1과 같이 teacher model이라는 개념을 통해 네트워크로부터 가짜 GT를 만들고 이를 student model의 GT로 활용하는 방식을 사용합니다.
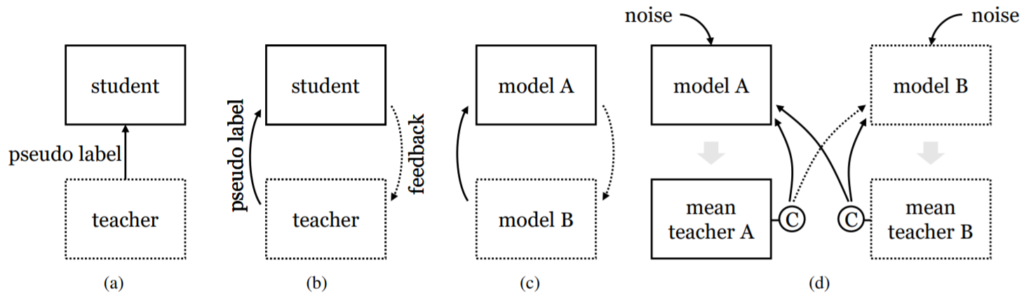
이 때 teacher model은 weakly-augmented unlabeled data를 통해 pseudo label을 생성하며 student network는 strong-augmented data로 학습을 수행하게 됩니다.
하지만 이러한 pseudo labeling 방식은 모델이 teacher model에 overfitting 되기가 매우 쉽다는 단점이 존재합니다. 이러한 문제를 해결하고 teacher model 더 좋은 pseudo label을 만들기 위해서 그림1-(b)와 같이 student model이 teacher model에게 feedback을 주는 컨셉을 적용한 방법론들도 제안되곤 했습니다.
반면에 teacher와 student의 역할을 동시에 수행하는, 즉 서로 학습을 돕고 돕는 mutual learning(그림1-(c))은 모델의 일반화 성능을 향상시켰으며 학습 과정 동안에 두 모델 모두 향상된 결과를 가져왔다고 합니다. 하지만, 두 네트워크들은 결국 동질적인 지식(homogeneous knowledge)을 끝으로 수렴하였으며, 이러한 현상은 coupled noise를 야기하여 제한된 성능 향상을 보였다고 합니다.
대충 mutual learning의 한계를 요약하자면 두 네트워크가 서로 다른 weight를 가졌으니 서로 다른 feature map을 보고 학습함으로써 모델의 일반화 성능을 더 끌어올리고자 하는 것인데, 결국은 두 모델이 동일한 지식을 공유하는 문제가 발생한다… 라는 것 같습니다.
그래서 해당 논문에서는 이러한 coupling issue를 개선하고자 다양한 mutual learning 기법들을 제안하게 됩니다. 먼저 첫째로, 저자는 두 모델이 서로 이질적인 지식(heterogenous knowledge)를 주고 받는 것이 mutual learning에서 매우 중요하다는 것을 발견하였으며, 두 모델이 서로 이질적으로 하기 위하여 mean teacher를 통해 pseudo label을 생성하였다고 합니다.
mean teacher는 각 모델의 weight에 대하여 EMA(Exponential Moving Average)를 계산하여 적용한 모델로, 기존에 pseudo labeling 방법론에서 teacher 모델로 많이 사용하는 방법론입니다. EMA teacher model과 관련해서는 임근택 연구원님이 예전에 작성하진 리뷰를 참고해보시면 좋을 듯 합니다.
아무튼 EMA teacher model을 사용하게 되면, 두 모델의 결과값을 직접적으로 비교하는 것이 아닌, EMA를 통해 계산된 파라미터로 생성한 결과를 비교한 것이므로 간접적인 비교가 가능하게 된다는 점입니다. 이러한 점을 저자는 coupling issue를 줄일 수 있다고 주장합니다.
또한 두번째로는 strong data augmentation과 model noise(i.e. dropout, stochastic depth)를 mutual learner에 적용하게 되면 모델들이 이질적인 지식들을 학습할 수 있다고 합니다.
마지막으로 세번째는 두 모델의 네트워크 구조 자체를 서로 이질적으로 변경하는 것입니다. 예를 들어 하나의 모델은 CNN, 다른 하나의 모델은 Transformer를 사용하는 것이죠. 이러한 네트워크의 직접적인 변경은 두 모델이 동질적인 결과를 추출하는 것을 매우 크게 예망해주게 됩니다.
Preliminary
방법론에 들어가기 앞서, 용어정리를 조금 하고 가도록 하겠습니다.
- x : training image
- y : Segmentation Lable Map
- \mathcal{D}_{l}=\{x_{l}, y_{l}\}^{n_{l}}_{l=1} : segmentation label이 있는 dataset
- \mathcal{D}_{u}=\{x_{u}\}^{n_{u}}_{u=1} : Unlabeled dataset
- h_{\theta} : segmentation network paramterized by [/latex] \theta [/latex]
- f : feature extractor
- g : linear classifier
자 그러면 일단 h_{\theta}는 feature extractor f 와 linear claissifier g로 구성되어 있으며, 이러한 segmentation network가 labeld dataset으로 학습하는 과정은 수식 1과 같습니다.
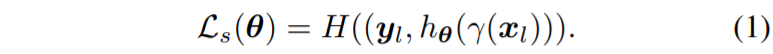
여기서 \gamma 는 photometric augmentation을 의미하며 사용자에 판단에 따라 geometric transformation도 추가적으로 적용할 수 있습니다. 참고로 H는 standard cross entropy loss를 의미합니다.
다음은 unlabeld image에 대한 수식도 알아보겠습니다. 먼저 pseudo label \hat{y}은 unlabeld image에서 생성된 soft preidiction에 argmax를 취하는 과정 즉 \hat{y} = one_hot(h_{\theta}(\gamma(x_{u})))를 수행합니다.
하지만 여기서 pseodu label 중에서는 불확실한 label 정보들이 존재할 수도 있기 때문에, confidence score가 사전에 정의해둔 임계치 \tau 보다 작을 경우에는 제거해버리는 과정이 수행됩니다. 이러한 과정까지 다 포함한 과정은 아래 수식과 같습니다.
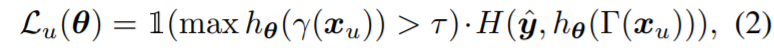
x_{u} 옆에 있는 Upgamma는 strong augmentation에 해당합니다.
pseudo label의 에러를 더 효과적으로 제거하기 위해서, mutual learning을 적용한 두 모델 h_{\theta_{1}}, h_{\theta_{2}} 은 서로 다른 weight initialized를 수행하며, 그 후 pseudo label \hat{y_{1}}, \hat{y_{2}} 를 각각 생성하게 됩니다.
이러한 mutual learning의 수식은 수식 3과 같습니다.
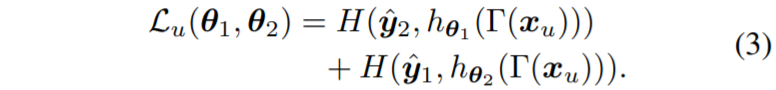
Techniques for Model Coupling Reduction
자 그러면 본격적으로 저자의 방법론에 대해서 알아봅시다. 먼저 위에 intro에서도 말씀드렸다시피, 저자는 Indirect mutual learning을 수행하기 위해서 mean teacher를 활용한다고 하였습니다.
일반적으로 Mutual Learning은 서로의 모델에서 나온 결과값들을 직접적으로 비교하게 되는데, 이렇게 하게 될 경우 두 모델이 너무 빠르게 동일 상태로 수렴하는 현상이 발생게 되며, 이는 coupled noise를 발생시킨다고 합니다.
저자는 이러한 coupling 현상이 두 모델의 결과값을 직접적으로 비교하였기 때문에 발생한 문제로 보고, 이를 해겨하고자 mean teacher를 통한 indriect manner로 변경하였다고 합니다. mean teacher를 활용하게 될 경우 수식 3에서 사용된 pseudo label은 다음과 같이 변경됩니다.
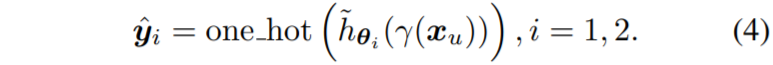
\tilde{h}_{\theta_{i}} 는 EMA teacher model을 의미하게 되며, 이처럼 각각의 모델은 서로의 temporal ensemble knowledge를 통해 학습하기 때문에, 더욱 다양성을 유지한채로 학습을 진행할 수 있다고 합니다.
저자는 이러한 indriect mutual learning이 과연 model coupling의 속도를 얼마나 늦추는지를 판단하기 위해 3개의 FC레이어로 구성된 MLP 모델들에 대하여 MNIST dataset을 가지고 indirect mutual learning을 수행하였습니다. 그리고 이 때 두 모델에서의 softmax output의 total variation distance를 계산하였습니다.
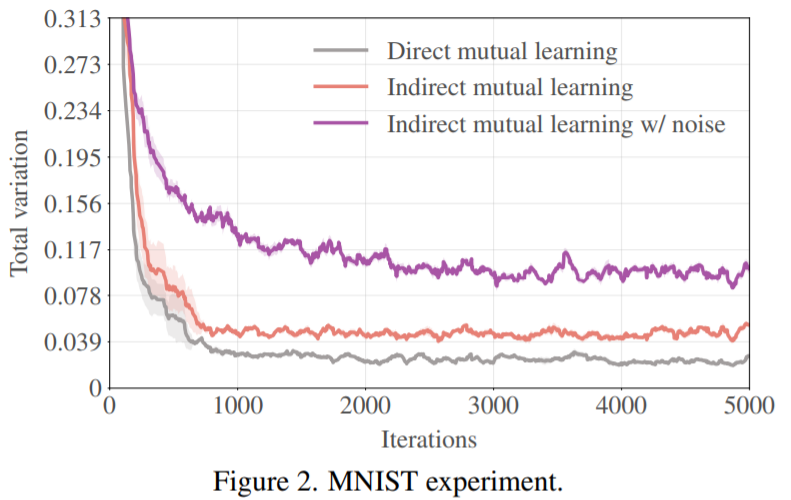
그림2를 보시면 회색 그래프인 Direct Mutual Learning와 비교하여 Indirect mutual learning이 더 큰 variation을 가지고 있음을 보여주고 있습니다. 하지만 Direct Mutual Learning은 거의 0에 근접하는 distance 값을 가지고 있죠.
자 그러면 그림1-(d)와 같이 각각의 모델에 대하여 EMA teacher가 존재하게 되는데, 이때 EMA teacher는 상대방 모델에게만 pseudo label을 전달하는 것이 아니라, 자신편에 model에게도 전달해주게 됩니다.(예를들어 A모델의 EMA teacher는 B 모델 뿐만 아니라 A에게도 Pseudo label을 전달해준다는 것이죠.)
아무튼 간에, 이를 수식으로 나타내면 수식5와 같습니다.
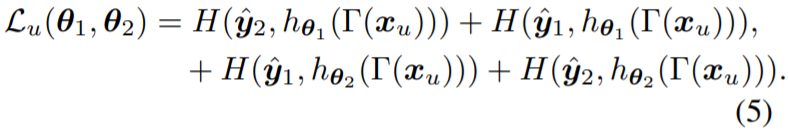
Data augmentation and model noises
Coupling issuse를 해결하기 위한 2번째 방법으로는 Data augmentation과 model noises를 추가하는 방법이 있다고 했습니다. 그림2 결과를 보시면 아시겠지만, EMA 모델을 사용하였을 때 전체적인 variation distance 값이 더 커지는 것은 맞지만, distnace가 수렴하는 경향성 등을 보았을 때는 direct와 매우 유사하며 아직 불만족스러운 결과입니다.
그래서 저자는 data augmentation을 통해 data에도 noise를 적용하며, 동시에 dropout 등의 기법을 통하여 model에 noise도 적용함으로써 mutual learner들이 동질된 결과를 추론하도록 하는 것을 방해하였다고 합니다. 여기서 data augmentation은 photometric augmentation으로 이루어진 RandAugment이며 해당 방법은 student model에게만 적용하였습니다.
이러한 노이즈를 추가하는 것은 2가지 이점이 있는데, 먼저 student model이 더 어렵게 학습하도록 강조한다는 점입니다. 이는 self-training에서 매우 중요다는 것이 이전 연구들을 통해 증명되었다고 합니다. 둘째로, 방금전에도 설명했다시피 이러한 방해공작들은 mutual learner들이 동일상태로 수렴되는 것을 막아주게 됩니다. 추가로 저자는 CutMix를 data augmentation으로 적용하였는데, 해당 기법은 consistency learning을 향상시켜준다고 합니다.
그러면 위의 기법들을 적용하였을 때 얼만큼의 이점이 있는지를 확인해봐야겠죠? 저자는 아까와 동일하게 MNIST 데이터 셋에 대하여 실험을 진행하였으며 그림2에서 결과를 확인하실 수 있습니다. 보라색 그래프를 살펴보시면, indirect mutual learning을 하였을 때보다 더 큰 total variation distance 격차를 보여주고 있습니다.
Heterogeneous architecture
마지막으로는 두 mutual learner들의 network architecture 구조 자체를 서로 다르게 설계하는 것입니다. 해당 방식은 noise를 추가하는 방법들 보다 더욱 직접적으로 두 모델에 이질성을 부여해줄 수 있기 때문이죠.
저자는 Transformer와 CNN을 사용하였는데, Transformer를 통해 long-range dependecy를 포작할 수 있으며, CNN을 통하여 local context modeling을 조금 더 수월하게 하겠다는 것이죠. 그리고 이러한 두 네트워크의 특성 차이로 인하여 자연스럽게 mutual learning은 coupling issue를 더 수월하게 해결할 수 있을 것이라고 판단하였습니다.
참고로 저자가 해당 실험에서 사용한 CNN 방법론은 DeepLabv2이며 Transformer의 경우 SETR이라는 방법론을 사용하였습니다.
Experiments
먼저 저자는 Cityscape와 PASCAL VOC 2012 dataset으로 실험을 수행하였습니다. Cityscape dataset의 경우 저자는 랜덤하게 1/30, 1/8, 1/4 이미지에 대해서만 각각 GT를 사용하고 그 외에 데이터에 대해서는 unsupervised로 학습을 수행하는 semi-supervised 환경을 구축했다고 합니다.
반면에 PASCAL VOC의 경우 1/100, 1/50, 1/20, 1/8로 구성하였습니다.
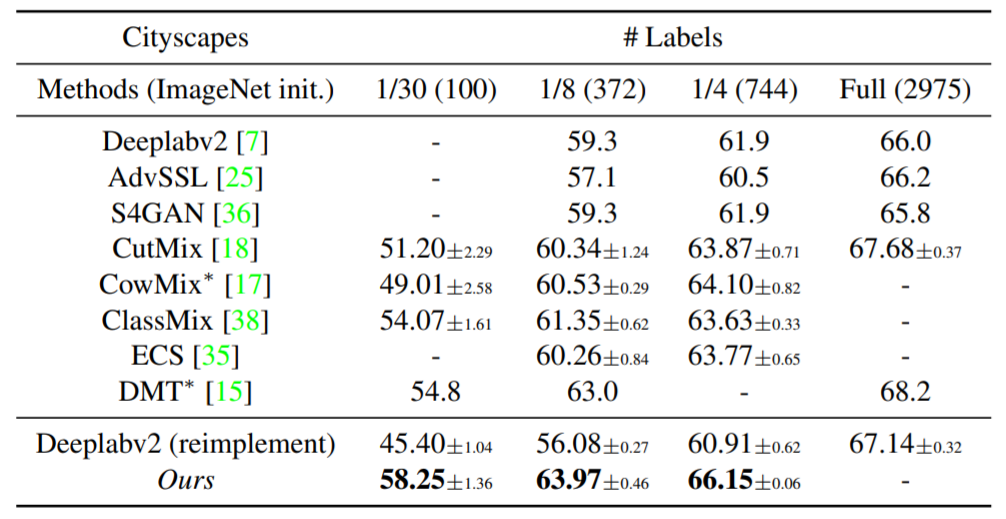
위에 표는 CityScape에 대한 결과입니다. AdvSSL과 S4GAN은 Adaversarial 기법을 활용한 semi-supervised 방법론이며, CutMix, CowMix, ClassMix는 consistency 기반 방법론이라고 하는데 음.. 해당 방법론들에 대해서는 잘 모르겠네요. 그리고 ECS와 DMT는 mutual learning과 유사하게 두 네트워크들을 협동하여 학습시키는 방법론이라고 합니다.
사용한 GT label의 수가 얼만큼이던 간에, 타 방법론과 비교시 가장 좋은 성능을 보여주고 있으며, 1/4 GT만을 사용하였을 때는 Full condition과 거의 유사한 성능을 보여주고 있습니다.
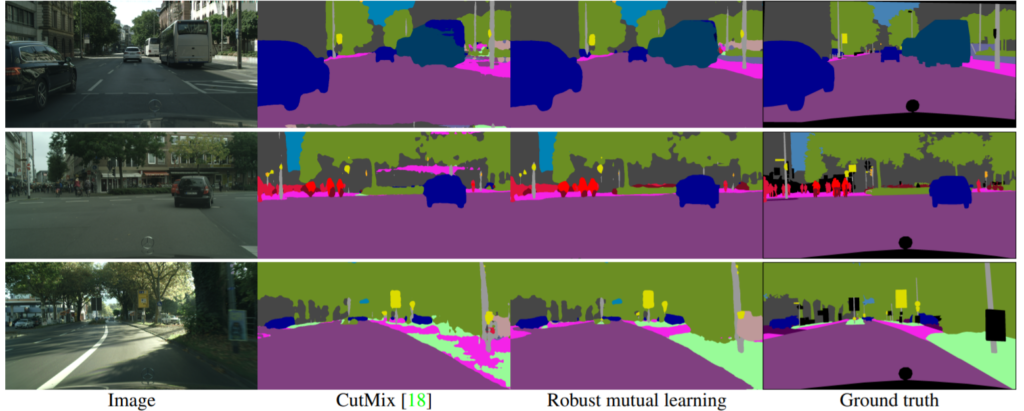
정성적 결과에서 눈여겨 보실점은, 저자의 방법론이 작은 물체나 애매한 물체에 대해서 일관성 있는 결과를 보여준다는 점입니다.
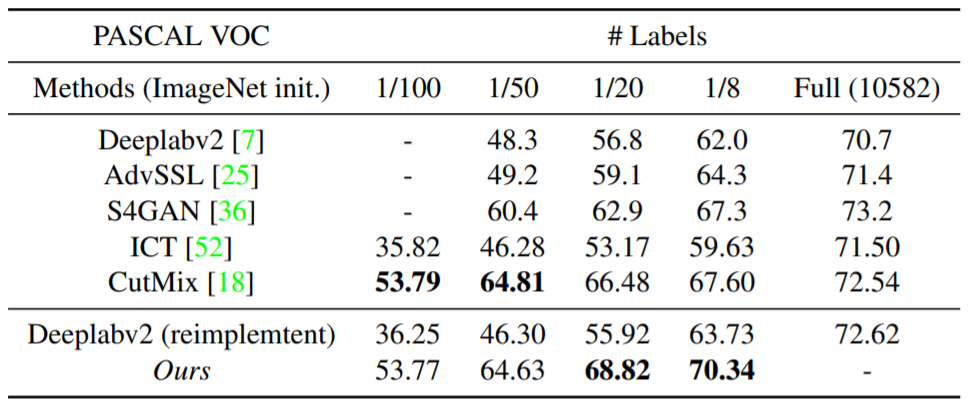
위에 표는 PASCAL VOC dataset에 대한 결과입니다. Pascal VOC에서는 Cityscape와 달리 1/20 이상 GT를 사용하였을 때 비로서 Sota를 달성하는 모습이긴 하지만, 1/100과 1/50에서도 이전 Sota 방법론과 성능의 차이가 그리 크지 않은 것을 확인하실 수 있습니다.
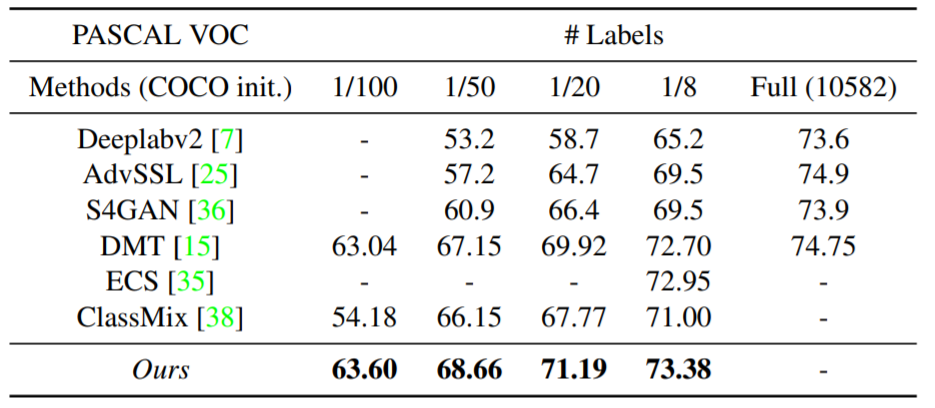
놀랍게도, COCO dataset으로 사전학습된 모델에 대하여 Pascal을 다시 학습시키게 되면 타 방법론과 비교하였을 때 매우 큰 성능 개선도를 보여주고 있습니다. 이 부분에 대해서는 딱히 설명은 없습니다만, Mutual Learning이 사전학습된 모델들로 하게 되면 더 좋아지는게 아닌가 라는 추측을 할 수 있습니다.
Ablation study
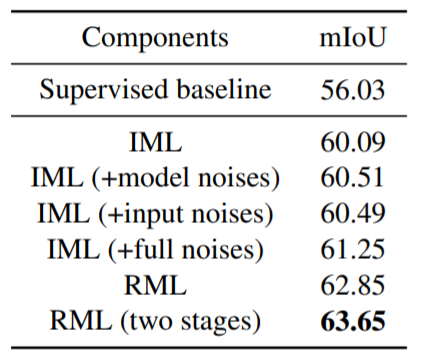
다음은 Ablation study에 대한 결과입니다. Cityscapep 1/8 dataset에서 ablation 실험을 진행하였으며, Mean teacher를 활용한 Indirect Mutual Learning을 할 경우 성능이 4% 향상되는 것을 확인할 수 있습니다. 그리고 각각의 noise를 추가하여 coupling issue를 줄여나감으로써 성능을 더 개선시킬 수 있었습니다.
여기서 이제 RML에 해당하는 부분은 사실 제가 리뷰에서 따로 설명하지 않은 부분이 하나 있는데 바로 pseudo label에 대한 self-rectification 방법을 의미합니다. 이 부분을 다루고 싶었지만, 논문을 아무리 읽어봐도 도저히 이해를 못하겠어서 해당 리뷰에서는 다루지 않았습니다. 혹시 관심있으신 분들은 논문을 직접 참고해보시면 좋을 듯 합니다.
해당 ablation study에서 한가지 아쉬운 점은, baseline으로 Supervised 방법론만을 정한 것입니다. 사실 EMA teacher를 활용하지 않은, Direct Mutual Learning에 대해서도 다뤄주었으면 좋았을텐데, 그 부분이 없으니, IML의 성능 개선이 어느정도인지를 가늠하기가 어렵다는 단점이 존재하네요.

마지막으로 table5는 서로 다른 모델 구조에 따른 성능 개선도를 보인 것입니다. 결과적으로 보시면, CNN/CNN, Transformer/Transformer 보다, CNN/Transformer 조합이 가장 좋은 성능을 보여줌을 나타내고 있습니다.
결론
Mutual Learning에 대해 요새 공부하면서 제 연구에 적용해볼 수 있는지를 검토하고 있는데 제가 잘 못찾아서인지는 모르겠으나 생각보다 pixel-level preidction에서 사용하기 어려운 것 같더군요. 그러던 와중에 해당 논문은 pixel-level mutual learning에 대해 좋은 결과를 보여주는 논문으로 생각합니다.
사실 해당 논문의 방법론을 보면 pixel-level에서 잘 동작하게끔 이라기 보다는, 어떠한 분야든 상관없고 mutual learning의 성능을 향상시키기 위한 방법으로 볼 수 있을 것 같습니다. 이 논문에서의 가장 큰 핵심은 mutual learning은 domain adaptation과 같이 두 모델이 또는 두 도메인이 coupling되는 것을 지향하는 것이 아니라, hetegenous를 지향해야만 큰 성능을 기대해볼 수 있다라고 보시면 될 것 같습니다.
성능 향상 폭이 매우 인상적이네요. 확실히 Segmentation 분야에서는 이렇ㄴ semi-supervised 관련 논문이 많은 것 같습니다. 이런 방식이 depth 쪽에도 적용가능 할까요..?
단순히 적용하라고 하면 할 수는 있겠지만, 논문이라는게 그렇듯 문제점을 정의하고 이를 해결하기 위한 무언가를 추가하기 위한 과정에서는 DML이 생각보다 어렵다고 판단하고 있습니다.
mutual learning 관련 글 쓰시는 것 매주 따라서 잘 읽고 있습니다. 모델이 서로 다른 값을 예측하면서 상호학습을 해야한다는 것을 달성하기 위해 아예 teacher-student 모델을 서로 다른 모델을 쓰는 것이 뭔가 근본적인 문제를 생각해보고 고치는 느낌같아서 매우 신기한 방법이네요. 이번주도 잘 읽었습니다.
잘 읽어주셔서 감사합니다.