요즘들어 Homography Estimation과 관련된 논문들을 읽고있으며, 해당 논문도 지난 2021 ICCV에 제출된 논문입니다. 이전 논문들과 연관성이 있으니 잘 이해가 안되시는 분들은 이전에 제가 작성한 리뷰를 함께 참고하시길 바랍니다. 링크
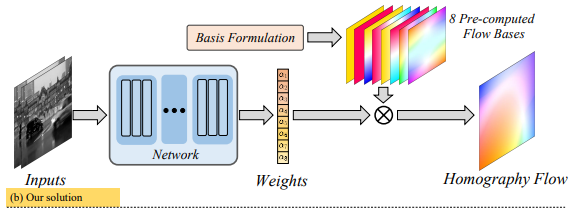
본 연구에서는 Homography matrix를 예측하는 이전 연구들과는 다르게, Homography Flow라는 것을 예측하는 새로운 방안을 제안하고 있습니다. 본 논문에서 제안하는 Contribution은 3가지 입니다.
- Homography Flow 라는 새로운 방식을 제안합니다.
- LRR block이라는 모듈을 제안하며, 이는 motion feature를 효율적으로 제거할 수 있습니다.
- FIL loss라는 것을 제안하며 이는 unsupervised optimization이 stable 하도록 만든다고 합니다.
자 그러면 이러한 Contribution에 대해서 하나씩 살펴보겠습니다.
Homography Flow
먼저 Homographgy Flow는 기존에 4개의 점을 이용하여 H-matrix를 통해 warping하는 것보다는 정교한 Warping이 가능하다는 장점을 갖습니다. 결과적으로 이를 통해 해당 논문에서 제안하는 방법이 더 좋은 성능을 나타냈으며, 아이디어는 다음과 같습니다.
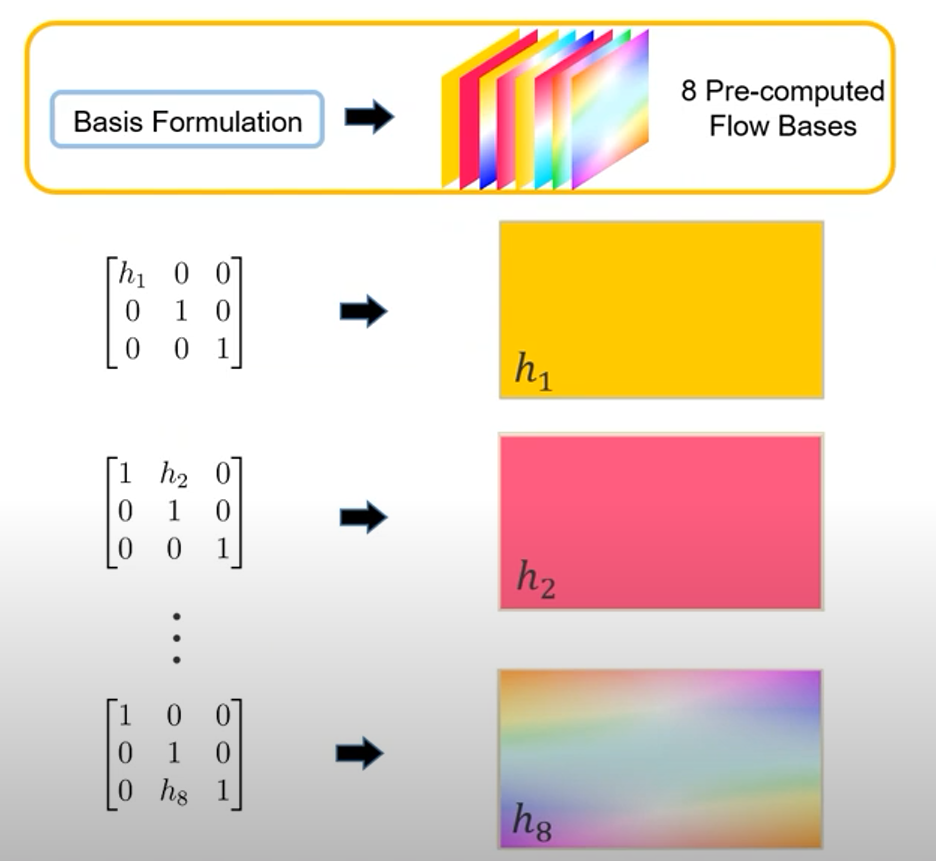
자칫보면 이게뭐지? Optical FLow인가? 라고 생각할 수 있습니다. 비슷하지만 약간 다른 컨셉은 실제 orthogonal한 H-matrix basis가 있다고 가정할 때 각 성분의 값에 따른 이전 이미지의 픽셀의 이동위치를 맵으로 나타낸 그림입니다.

위의 예시처럼 각 행렬이 나타내는 의미가 있고, 이를 변환시키며 실제 오리지널 영상의 픽셀이 어떻게 이동하는지를 Optical Flow와 같이 matrix를 시각화한 그림이라고 생각하시면 됩니다. 그렇다면 이렇게 각 성분별 총 8개의 Flow bases를 논문에서는 구하고 이를 이용하여 Homography Flow를 계산하게 됩니다. 기존 연구에서 모델이 H matrix의 각 성분들 혹은 potin의 offset을 계산하여 이를 이용해 H-matrix를 계산했다면, 본 연구에서는 이러한 Flow bases의 Weight를 모델이 예측하게되고 이러한 weight를 basis와 곱해서 최종적은 Homography Flow를 만들게 됩니다.
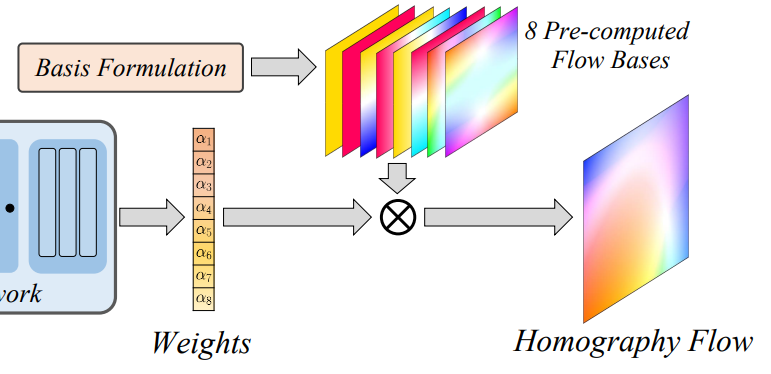
LRR blocks
그렇다면 이미지의 입력을 이용하여 Weights를 계산하는 기존 Homography Estimation이라고 불리는 네트워크는 어떻게 구성됐을까요? 일반적으로 Homograpyh Estimation을 위해서 많은 연구들은 ResNet34를 사용합니다. 그런데 그러한 ResNet34의 입력을 아래와 같이 최종 출력단계에서 Fclayer를 이용하여 8차원으로 줄이게 됩니다. 저자는 이러한 과정에서 발생하는 손실을 개선하기 위해 유의미한 정보만 잘 줄일 수 있는 LRR blocks라는 모듈을 제안합니다.
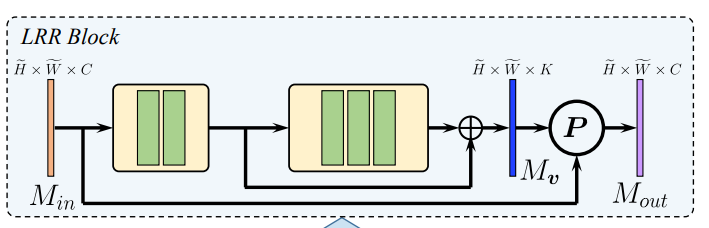
해당 모듈을 통해서 차원을 낮추는 동시에 손실을 줄일 수 있다고 합니다.
Feature Identity Loss (FIL)
해당 Loss는 이미지를 Warping 하여 Feature를 extract 하는것과 이미지에서 feature를 extract하고 warping을 한 것과 같아야 한다는 ‘Warp_equivariant’를 가정으로 설계됐습니다.
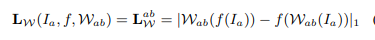
그래서 W를 warping, f를 feature extract라고 했을때 Loss는 위의 수식과 같습니다. 이를 통해서 FIL을 이용하면 기존 연구에서 사용하던 Inlier mask를 사용하지 않아도 실제 유의미한 feature들만 추출하고 이를 이용하요 Homography flow를 계산할 수 있다고 합니다.
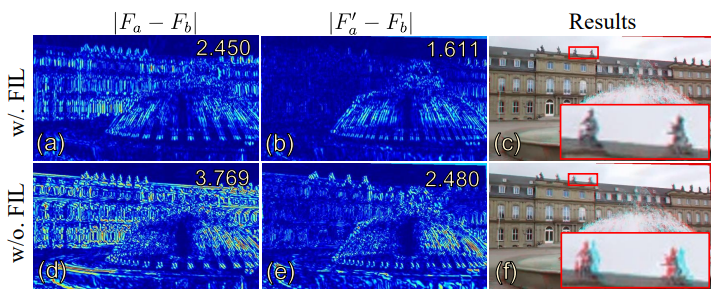
Experiments

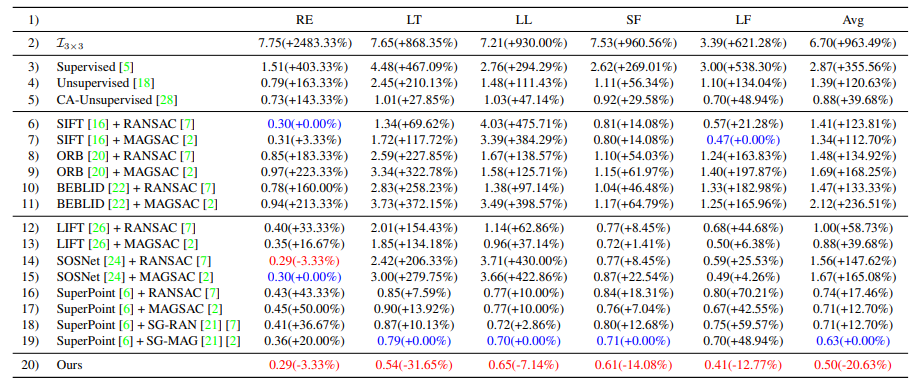
뭐 성능은 기존 연구들 대비 좋은 성능을 나타내고 있습니다. (ICCV Oral 페이퍼입니다.)
Failure cases
The predefined flow bases is friendly to small-baseline scenarios. By contrast, it may introduce error when applied to the large baseline cases as bases h7 and h8 are a linear approximate representation of small range perspective transformation in the Cartesian coordinates.
안녕하세요.
질문이 있는데, Homography Flow는 입력 영상과 동일한 해상도를 가지는 것인가요? 그러면 FIL loss 계산할 때 warping한 결과에 Feature Extractor 결과는 원본 입력 영상에 warping을 바로 하면 될 것 같은데, F(I)에 대한 warping은 어떻게 진행하나요? Homography Flow를 그냥 저희가 아는 interpolation을 통해 down sampling하면 되나요?
그리고 LRP Block은 보여주신 그림만으로 어떤 구성인지 잘 모르겠네요. P는 무엇을 의미하는건가요? 그리고 해당 LRP Block을 적용하게 될 경우 일반적인 Encoder를 사용했을 때 대비 성능이 더 좋아진다는 ablation study는 없는건가요? LRP Blcok이 motion feature를 효율적으로 제거할 수 있다는데, 그림만 봐서는 잘 모르겠네요.
1. 네 Feature extractor 하면 결국 입력 이미지와 동일한 해상도를 갖는 feature를 추출하게 됩니다. 음 자세히 말하면 gray 스케일의 이미지를 ‘1->4->8->1’ 이런식으로 채널만 변경하고 해상도는 유지됩니다. 따라서 Featuremap에 대한 Homgraphy flow도 동일하게 적용할 수 있습니다.
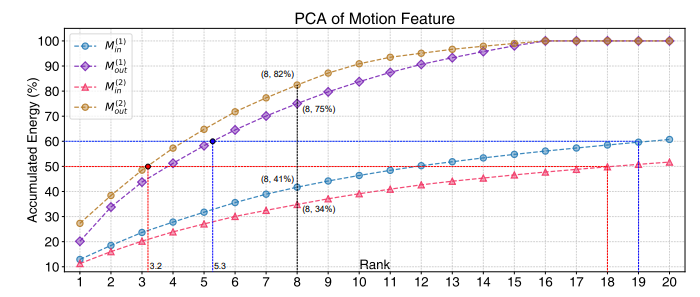
2. LRP Block은 아니고 LRR Block인데, ‘a Low Rank Representation’를 줄여서 LRR이라고 명칭하였습니다. 즉 저차원의 벡터로 줄여나가면서 결국 8개의 weight를 얻기 때문에 feature의 정보를 저차원으로 잘 줄여야 하는데, 자신들의 모듈이 이를 잘 진행한다고 나타내며, 원본의 그림처럼 x축의 차원에 따른 에너지의 비율로 이를 증명합니다. 또한 Albation study도 진행하는데, 이는 해당 리뷰에 포함하지 않았습니다. (논문에 나타나있습니다)
아 LRR Blcok이었군요. 제가 잘못봤네요. 근데 해당 block 약자의 의미를 궁금해한 것이 아니라 리뷰에 나와있는 그림(파란색 feature가 P과정을 거쳐 보란색 feature로 되는 그림)에서의 P가 무엇인지를 물어본 것이었습니다.
좋은 논문 소개해주셔서 감사합니다.
몇 가지 질문이 있습니다.
1. 해당 논문의 메인 태스크는 두 영상에 대한 영상 정합인가요? 아니면 한 영상에 대한 왜곡 보정인가요?
2. Basis Formulation은 어떻게 얻어지는 건가요? 만약에 두 영상에서 구해지는 거라면 지도 학습과 유사해 보입니다. 추론에서는 어떻게 작동되는 건지 궁금합니다.
1. 해당 논문의 목표는 작은 베이스라인을 갖는 두 영상의 정합입니다.
2. 해당 Basis Formulation은 위에 댓글에서 언급한것처럼 논문에 명확히 나타나있지 않습니다. (저도 논문을 읽으며 찾았던 부분입니다.) 다만 코드상에서 확인해보면 임의의 값으로 설정(논문에서는 이또한 작은 베이스라인을 기준으로 설정된 값이라고 설명하고 있으나..)하거나 0,0,0,0,0,1,1 와 같은 값으로 설정하고 있습니다. 결론은 이렇게 임의로 설정한 basis를 기준으로 그냥 모델은 그때그때마다 weight를 계산하고 그 weight를 basis에 곱하여 최종적인 homography flow가 됩니다.
https://github.com/megvii-research/BasesHomo/blob/db9bf69ab6b60baf57de86068692ec3fea0d1169/model/net.py#L280