이번에 제가 리뷰할 논문은 2022 Sensors에 나온 논문으로 올해 1월 27에 최종 accepted되었으며, 30일에 출판된 따끈따끈한 논문입니다.
해당 논문에서는 YOLOv4를 이용하여 퓨전모델을 설계하고 KAIST 멀티스펙트럴 보행자 데이터셋에서 다양한 실험을 합니다. 개인적으로 좋은 논문이라고 생각이되어서 소개하려고 하는데요, 제가 좋은 논문이라고 생각하는 이유는 논리적인 글 전개와 뒷받침하는 실험입니다.
먼저, 결과만 놓고보면 해당논문은 YOLO를 기반으로 Early fusion / halfway fusion / late fusion 모델을 설계하고 평가한게 끝입니다. 그러나 Faster-RCNN을 기반으로 fusion되는 레이어의 위치에 따라서 성능을 리포팅한 논문은 이미 2016년? 쯔음에 나왔었으며, 그러한 점을 고려할 때, 해당 논문의 contribution은 그다지 대단해 보이지 않습니다.
또한 해당 논문은 성능이 SOTA하고는 거리가 멀며, 다른 논문대비 특이한점이라고 한다면 YOLO를 이용하여 설계한 모델과 YOLO의 특성상 낮은 latency를 갖는다는점 입니다. 그러나 이 또한, 처음이라고 보기는 어려우며 기존에도 YOLO를 기반으로 멀티스펙트럴 기반의 모델을 설계한 연구들이 있었습니다.
그렇다면 해당 논문에서는 어떻게 sensors에 accepted될 수 있었을까요? 같이 살펴보겠습니다.
논문
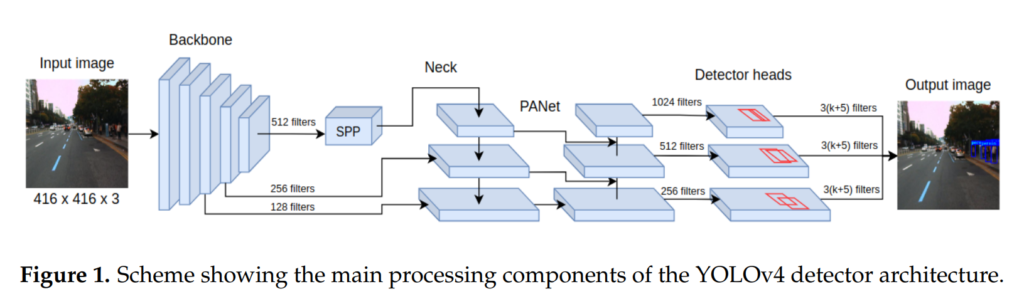
먼저 해당논문에서는 위와같이 YOLOv4를 사용하여 멀티스펙트럴 영상을 인풋으로 받는 모델을 설계하는 것을 목표로합니다. YOLOv4는 YOLO시리즈 backbone / neck / head로 구성되어있으며, 위의 그림과 같이 싱글모달리티 기반의 모델입니다. 가장 큰 특징은 SPP와 PANet, Mosaic data augmentation이 있으며 이에 대해서는 해당 리뷰에서 설명은 생략하겠습니다. (제가 YOLO를 다룬적이 여러번 있는데 X-review나 세미나영상을 찾아보면 해당부분을 설명하는 부분이 있을겁니다. 혹은 YOLO는 워낙 유명해서 구글링하면 자료가 많이나오는 편입니다.) 어찌됐든 해당 논문에서는 YOLOv5를 베이스로 퓨전하는 모델을 설계합니다. 설계한 모델은 피쳐를 퓨전하는 위치에 따라 3가지로 나뉘며 아래의 피규어 3개와 같습니다.
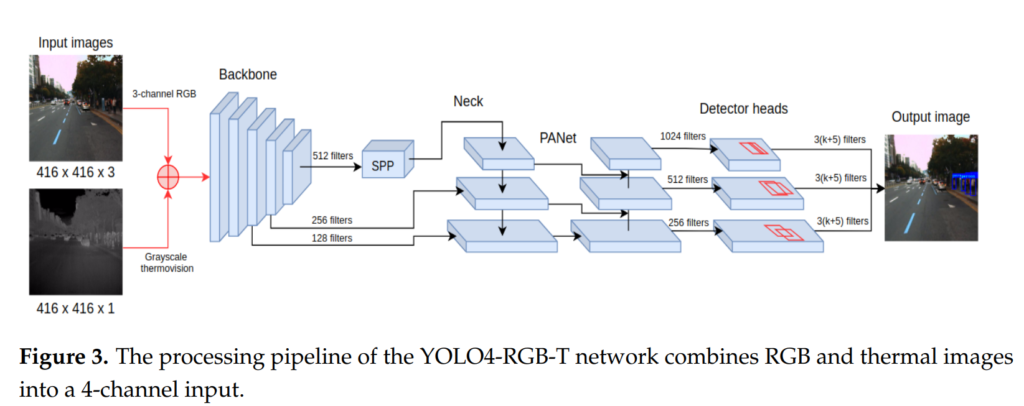
먼저, 인풋레벨에서 4 channel로 concatenate한 후에 모델에 태우는 방식이 있고요.
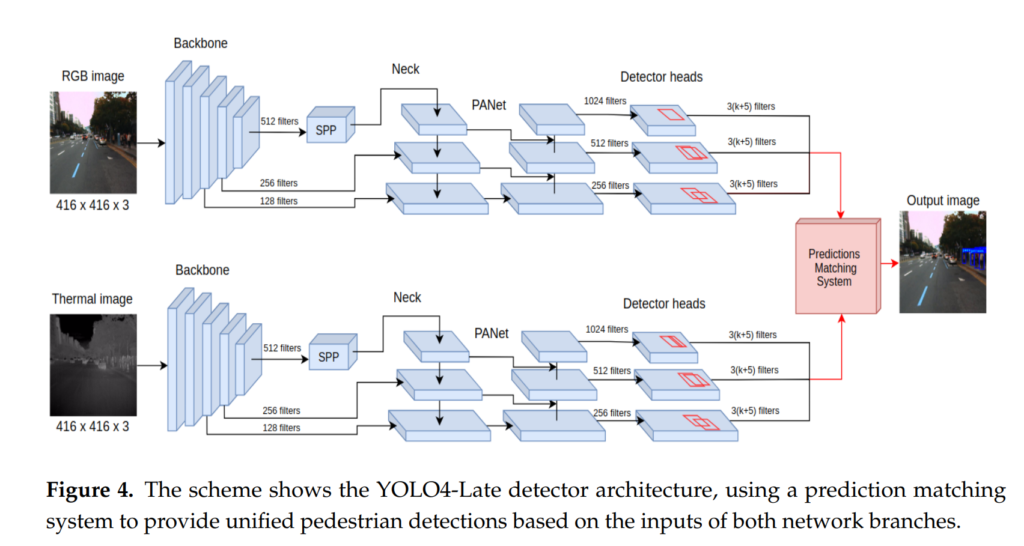
독단적인 모델 2개를 사용한다음 그리드맵단에서 나온 confidence score를 합치는 방식의 모델도 설계하였습니다.
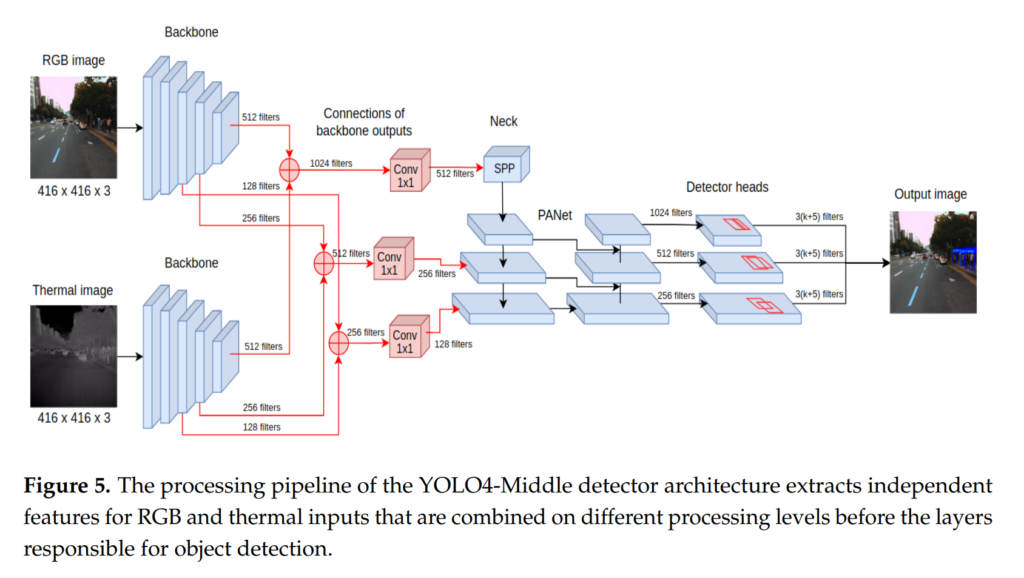
그리고 백본에서 추출하는 3개의 피쳐맵을 concatenation 밑 1×1 커널사이즈의 2d Convolution으로 퓨전하여 사용하는 방법이 있습니다.
이렇게 총 3개의 모델을 설계한 후 다양한 실험을 진행하였으며, 저자들이 주장하는 contribution은 아래와 같습니다.
• We investigated how the detection frame rate (expressed in frames per second, fps)
influences the recall measure in a realistic scenario wherein the goal is to detect a
person and brake before a collision occurs. This analysis allowed us to conclude that
low latency during detection is a key factor in pedestrian detection. We ought to
increase speed of detection algorithms so they can spot pedestrians and initiate safe
breaking in time.
• In the context of a realistic scenario, we investigated five different fusion schemes for
multispectral images that were inspired by the state-of-the-art, but are our original contributions to the YOLOv4 architecture. These fusion schemes range from very simple
early fusion at the level of image data to elaborated middle and late fusion schemes.
• As a result of those investigations, we developed a new YOLOv4-based architecture
that allows for middle fusion and scored the best on average in the experiments while
processing the multispectral images at 35 fps.
• Being aware of the limited computing resources of autonomous cars, we prepared a
lightweight model. This detector exceeds 400 fps on the desktop Nvidia RTX 3080
GPU, provides the lowest latency when detecting vulnerable road users from a moving
vehicle, and can be deployed on edge computing devices.
카이스트 데이터셋에서 멀티스펙트럴기반의 퓨전연구를 해보신 분들은 본 논문이 성능이 좋은 것도 아니고 아이디어가 참신한 것도 아니라서 생각보다 contribution이 없다고 느껴질수도 있다고 생각됩니다. 그러나 저는 해당 논문이 꽤나 잘쓰여진 논문이라고 생각합니다.
일단 제가 그렇게 생각하는 이유는 해당 논문에서는 YOLO를 기반으로 하였으며, YOLO가 가지는 단점을 오히려 장점으로 포장하여 논리적으로 글을 전개하고, 해당 주장을 뒷받침하는 실험들이 다양하기 때문입니다. YOLO가 가지는 대표적인 단점은 바로 일반적으로 멀티스펙트럴 보행자 인식 분야에서 사용하는 평가매트릭인 log-average miss-rate로 평가하면 성능이 안좋게 나온다는점 입니다. 제 나름대로 해당 이유를 분석해 보았는데 그 이유는 아래와 같습니다.
특성이 비슷한 대표적인 싱글스테이지 기반의 모델인 SSD와 YOLO를 비교해가며 설명하겠습니다. SSD와 같은 single stage의 detector와 다르게 YOLO시리즈에서는 confidence score에 IoU를 곱하여 사용하며, IoU loss 또한 사용합니다. 이게 무슨소리냐면… YOLO 시리즈에서는 무언가 높은 confidence로 물체를 검출하는데만 포커싱 하지 않고 물체를 얼마나 정확하게 찾냐(GT와의 IoU가 높게)를 고려한다는 의미입니다. 즉, YOLO는 물체를 좀 더 정확하게 찾을 순 있지만 SSD기반 모델에 비하면 confidence score가 전체적으로 더 낮은 경향이 있습니다. 그리고 confidence score가 낮기 때문에 전체적으로 False positive sample이 많습니다. 그러나 이러한 False positive sample들은 log-average miss-rate 평가 매트릭에 아주 민감하며 급격한 성능저하를 일으킵니다. 따라서 자연스럽게 YOLO기반의 모델들은 log-average miss-rate가 아주 안좋게 나오는 경향이 있습니다. 이러한 이유때문인지 일반적으로 YOLO는 평가매트릭으로 AP를 이용합니다. AP는 Precision-recall 커브에서의 면적을 의미하며, 해당 평가매트릭은 상대적으로 False positive에 덜 민감하기 때문입니다.
그렇다면 해당 논문에서는 YOLO의 이러한 문제점을 어떻게 다루었을까요? 그리고 거의 포화상태라서 더이상의 성능개선이 쉽지 않은 카이스트 데이터셋에서 성능을 어떤식으로 리포팅할까요?
결론적으로 해당 논문에서는 miss-rate를 아예다루지 않습니다. 어찌보면 당연한 것입니다. YOLO기반으로 설계를 했는데 현존하는 좋은성능의 모델들과 비교될게 뻔하니깐요. 그저 현존하는 좋은 매트릭으로 log-average miss-rate와 AP가 있다고 언급하며, 우리는 그중에서 AP를 사용하여 평가하였으며, AP 의 장점 및 평가매트릭으로 선정한 이유에 대해서만 주구장창 설명합니다. 굳이 miss-rate에 대해서 장황하게 설명하거나 변명을 늘어놓아서 의구심만 키울 필요가 없다고 생각을 한거 같습니다.
그리고 굳이 현존하는 좋은 성능의 모델들과 성능을 겨루지 않습니다. 애초에 사용하는 학습 및 평가 세팅이 최근 트렌드와 많이 다릅니다. 따라서 fair comparison이 쉽지 않을뿐더러 굳이 해야할 필요성을 느끼지 못했습니다.
현재 카이스트 데이터셋은 3가지 annotation version이 있고, 아래와 같습니다.
- Original
- Paired
- Sanitized
그리고 현재, Sanitized에서 평가를 하는게 가장 공신력있는 평가방법으로 어느정도 기정사실화 되어있으며, 보통 다른 모델과의 fair comparison을 위해 sanitized를 사용하여 평가합니다.
이와 더불어 “reasonable setting”이라 불리우는 55픽셀 이하를 제외하는 방식을 취하며, Person 클래스만을 학습에 사용합니다.
그러나 해당논문에서는 이러한 조건들을 다 이야기하고 설명하면서 문제점을 지적하고, real-world situation에서는 다양한 이유로 error가 발생하기 때문에 아무런 제한조건 없이 original에서 모든 크기의 annotation을 사용하여 학습 및 평가하였다고 합니다. 그리고 person만을 학습하는게 모델성능에는 도움이 되지만, 좀 더 진보한 자율주행기술을 위해서는 모든 class를 고려하여 주변 상황을 더 잘 인식하는것이 필요하다고 주장하며 person을 제외한 나머지 class도 학습에 포함합니다.
애초에 성능을 높이기보단 real-world condition 을 고려하여 성능이 낮더라도 현실적인 환경에서의 성능만을 리포팅하기 때문에 다른모델과의 비교가 어려울뿐더러 굳이 할 필요도 없는 것 입니다.
그러한 다른 모델과 경쟁하는 평가를 하는데 에너지를 소비하는 대신에 해당 논문에서는 latency와 Recall에 대해서 아주 강조하면서 다양한 실험도 합니다. 먼저, latency는 real-time 으로 working하려면 중요한 요소라고 주장을 하고요. Recall은 자율주행의 safety를 위해서는 false positive보다는 일단 찾는 것 자체가 중요하다고 주장하며 recall의 중요성을 강조합니다.
사실 latency하고 recall은 YOLO 기반의 모델이 갖는 대표적인 가장 큰 장점입니다. 해당 논문에서는 YOLO가 갖는 장점을 부각시키고 단점을 가리기위한 방식으로 모든 글을 서술하고 있습니다.
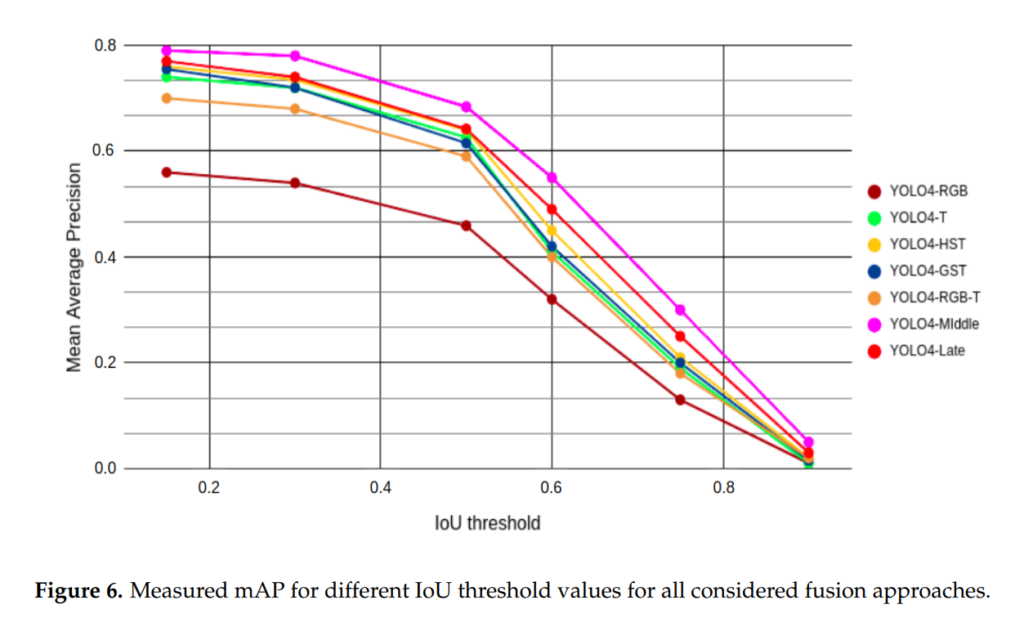
실험은 주로 자신들이 설계한 모델들로만 진행을 하였으며, AP로만 평가합니다. 이유에 대해서는 위에서 설명하였습니다.
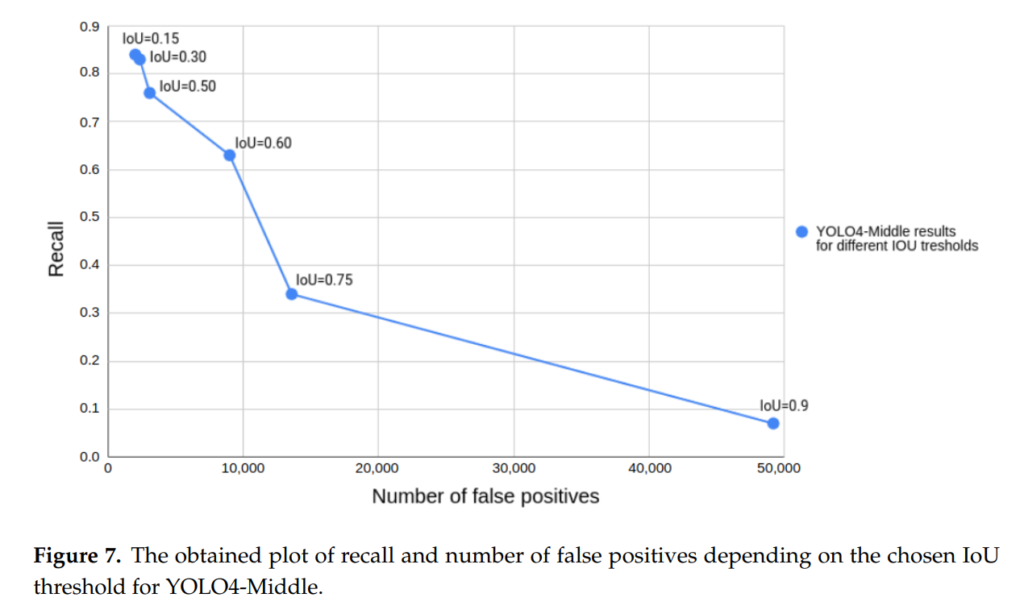
그리고 recall과 false positive, IoU의 상관관계를 비교하는 실험을 합니다. 사실상 저정도의 False potive가 나오면 miss-rate로 평가하면 90프로대가 나오지 않을까 싶습니다.
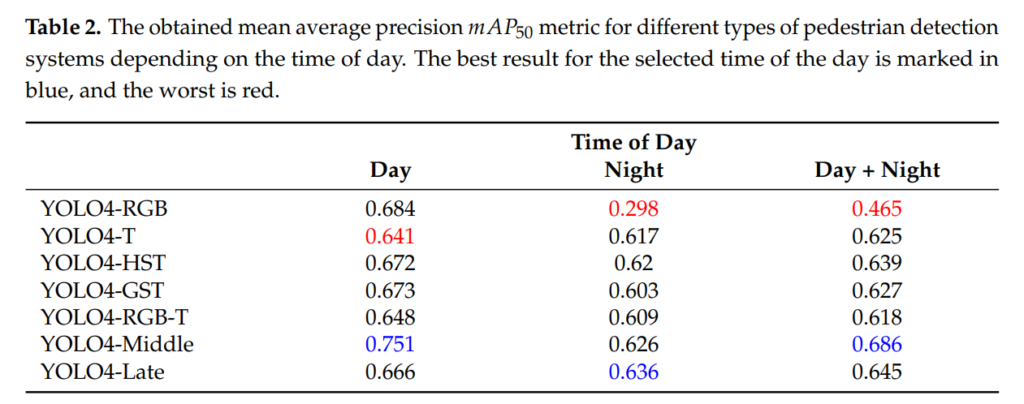
그리고 성능을 리포팅하는데 결국엔 YOLO시리즈도 Middle-level에서 fusion하는게 젤 성능이 높았습니다.
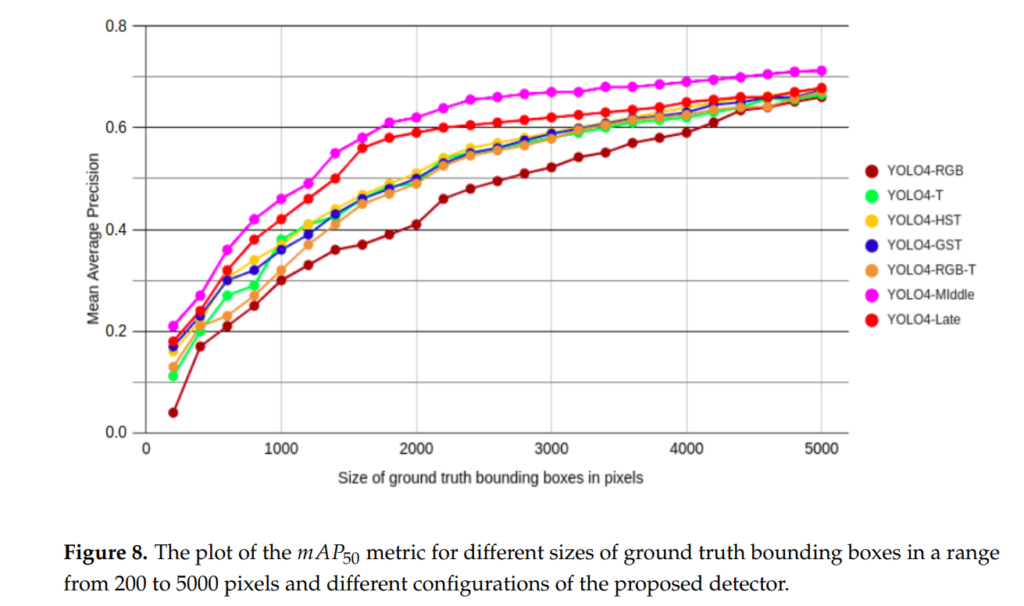
저자가 애초에 55 pixel 이하는 무시하는 reasonable setting에 대해 옳지 않다고 주장하였으므로, 위와 같이 모든 크기의 object에 대해서 AP성능을 분석하는 실험을 합니다. 이때, 물체의 크기는 GT bbox 내에 존재하는 픽셀의 개수로 나타내었습니다.
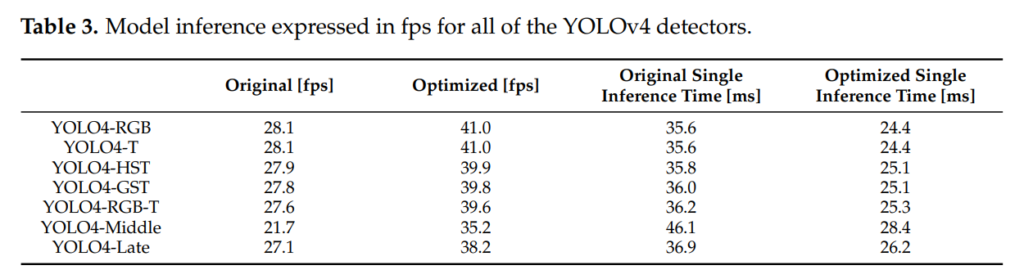
논문에서의 컨셉은 latency가 낮은 real-world application에 쓰기 적합한 모델을 찾는 것 이므로, 위와 같이 모델 속도 분석실험을 진행하였습니다. 해당 결과에는 실제 implementation 했을때를 고려해서 optimizing한 결과도 포함시켰습니다.
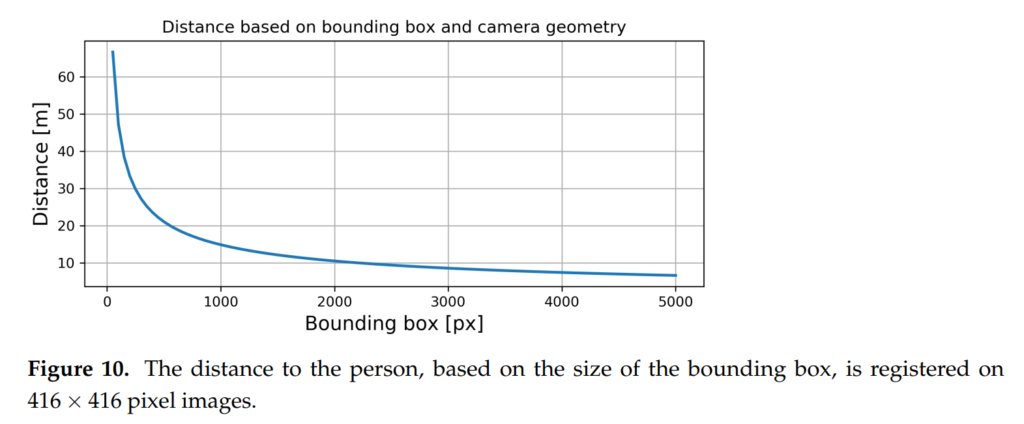
또한 일반적인 카메라의 Field of View와 focal length를 고려하였을때,

카메라와 보행자 사이의 거리는 위와같이 근사되며, 해당 식을 이용해서 카이스트 데이터셋을 분석해본 결과 그림 10과 같이 보통 bbox가 차지하는 면적이 50~5000픽셀사이에서 detection이 이루어지는 것을 확인했다고 합니다.
그리고 bbox 사이즈가 500pixel 이하정도가 되는시점부터 distance가 linear하게 올라가는게 아니라 exponentially 올라가는 것을 근거로 small object detection의 중요성에 대하여 언급합니다. 이러한 주장은 앞에서 이야기했던 55 pixel 이하도 고려해야한다는 것과 일맥상 통합니다.
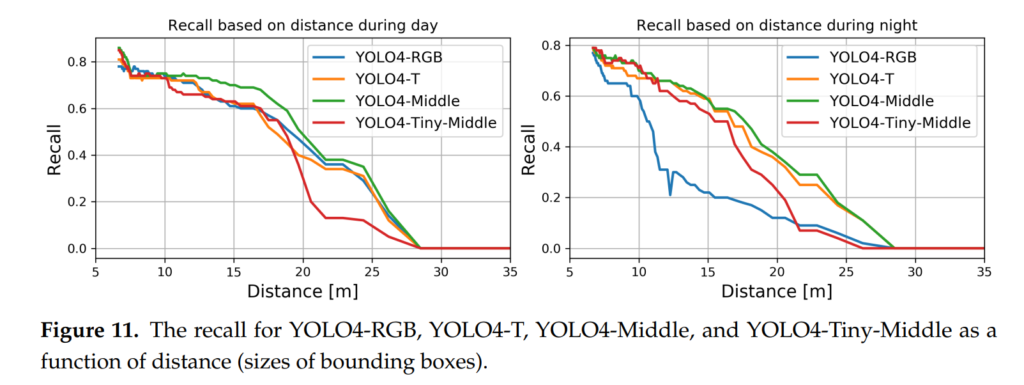
앞에서 말씀드렸듯이 recall의 중요성을 강조하며 distance에 따른 recall의 변화를 실험합니다.
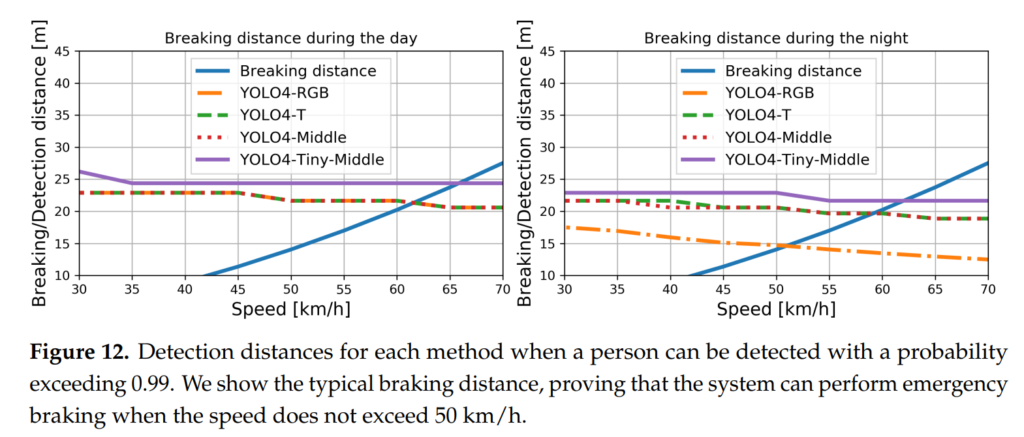
또한 차의 speed에 따른 breaking distance를 고려하였으며, 이를 detection distance와 비교합니다. 즉, detection distance가 braking distance보다 작으면 성공적인 모델이라고 할 수 있습니다.
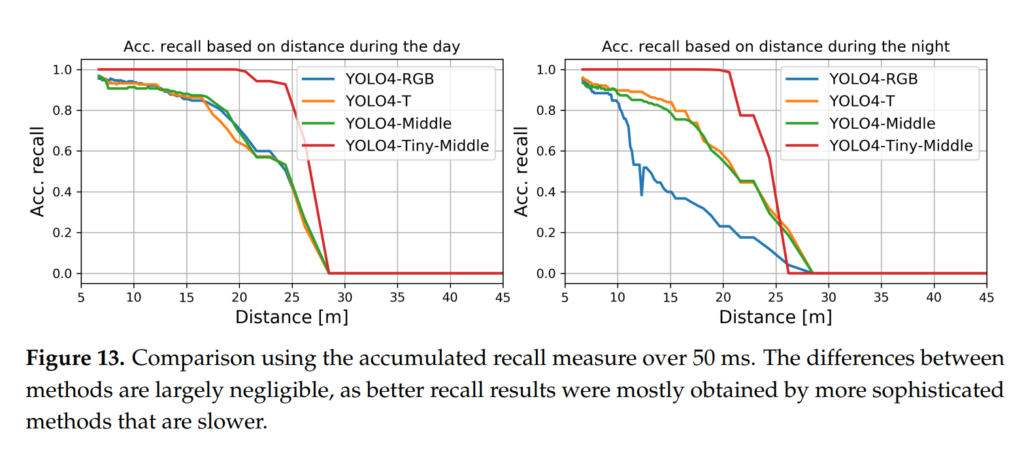
또한 일반적으로 그냥 frame으로만 평가를 하는게 아니라 50 ms동안 detection된 결과를 누적하였을 때, distance에 따른 accumulated recall의 값을 분석합니다. 결과적으로 tiny model을 제외하고는 accumulated recall의 변화가 크지 않았음을 알 수 있습니다.
감상평
기존에 당연하다고 받아들이던 것들이 글을 읽다보면 다시 한 번 생각해보게 되는 그런 논문이었던거 같습니다. 무저건 남들과 똑같은 학습 및 평가 세팅에서 sota를 찍거나 참신한 아이디어를 찾는데 혈안이 되기보다는, 실제로 연구다운 연구를 하기위해서는 자신만의 생각을 담는것이 중요하단 것을 느끼었습니다. 개인적으로 YOLO기반의 퓨전모델을 설계하며 답답했던 부분들이 많았는데, 해당 논문에서는 오히려 그러한점들을 장점으로 승화시켜서 잘 쓴 논문이라고 생각합니다.
‘person만을 학습하는게 모델성능에는 도움이 되지만, 좀 더 진보한 자율주행기술을 위해서는 모든 class를 고려하여 주변 상황을 더 잘 인식하는것이 필요하다고 주장하며 person을 제외한 나머지 class도 학습에 포함합니다.’
라고 하셨는데, 논문에도 그렇게 표현됐나요..? 카이스트 데이터셋에서는 person이외에도 다양한 데이터셋이 존재하고, MLPD 뿐만 아니라 MBNet, AR-CNN 등 모든 연구에서도 모든 클래스를 사람으로 학습하고 있고, 실제 모든 클래스를 학습하는게 오히려 성능이 더 좋다고 리포팅되어 있어 해당 부분이 잘못된것 같아 질문드립니다.
https://github.com/CalayZhou/MBNet/issues/10
제가 썻던 ‘person만’을 학습하는게 모델성능에 도움이 된다는 말의 의도는 모든 클래스를 person으로 학습하는 거였는데, 제가 지금 읽어보아도 글의 의도가 잘못전달 되었네요.
음… 그리고 제가 해당 논문을 읽을당시에는 reasonable setting과 다르게 아무런 변화없이 그대로 사용하였다 라는 표현이 있어서서 헷갈렸는데, 지금 다시 확인해보니 말씀하신대로 해당 논문 또한 모든 클래스를 person으로 학습한게 맞습니다.