Before Review
이번 리뷰는 다시 Action Localization으로 준비했습니다. 그 중 Video Level의 annotation 만을 사용하는 Weakly Supervised 방법론을 읽어보았습니다. 방법론 자체는 간단했지만 저자가 주장하는 motivation에는 충분한 설명이 들어가 있지 않아 조금 아쉬웠던 논문 입니다.
리뷰 시작하도록 하겠습니다.
Introduction
Temporal Localization은 비디오내의 Action Instance가 존재하는 구간을 찾고, 그 Action Instance의 종류를 예측하는 문제입니다. Supervised 기반의 방법론은 어디부터 어디까지가 Action인지 Frame 단위의 Annotation이 필요합니다.
Supervised 기반의 방법론은 annotation이 expensive 하며 subject 하고 error-prone한 특성을 가지고 있습니다. 당연히 frame 단위로 annotation은 cost가 클 것이고, action 경계 또한 사람이 명확한 기준을 가지고 정의하기 조금 애매한 구석이 있습니다. 그렇게 때문에 error가 발생할 수 있구요.
Weakly Supervised 방법론은 이러한 frame 단위의 annotation이 아니라 Video level의 annotation만을 가지고 action localization을 수행하는 것으로 조금 더 challenging 할 수 밖에 없습니다.
저자는 여기서 기존의 Weakly Superivsed 방법론들은 single shot 단위로 학습 되기 때문에 temporal cue를 무시한다고 문제를 제기 합니다. 이전의 방법론들 까지 제가 다 알고있는 건 아니라 제가 공감을 못하는 것 일지도 모르겠지만 Motivation 자체는 그래도 좀 애매한 구석이 있습니다.
아무튼 저자는 Weakly Supervised Object Detection 분야에서 사용되던 Pseudo Ground Truth를 활용하는 방식을 도입해 Action Localization을 수행합니다. 논문의 이름에서도 알 수 있지만 핵심은 Weakly Supervised Localization을 학습할 Pseudo Ground Truth를 만들어주게 되는 데 그 Pseudo Ground Truth를 Iteration마다 Refinement 시켜서 좀 더 정확하게 만들 수 있게 설계한 방법론 입니다.
Pseudo Ground Truth를 만드는 방식은 아래 사진과 같습니다.
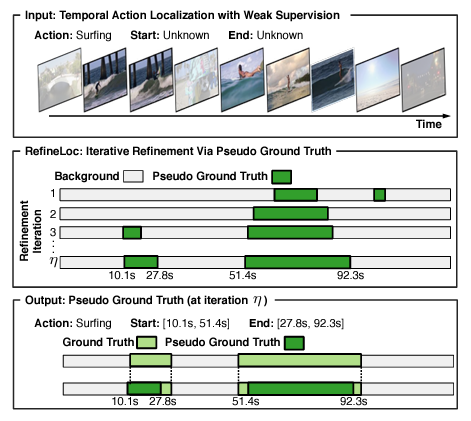
쉽게 얘기하면 매 Iteration 마다 Background와 Foreground 영역을 구분합니다. Background가 아닌 곳이 Foreground이며 Action이 존재하는 구간이라 볼 수 있습니다. N-1번째 Iteration에서 만든 Pseudo Ground Truth를 가지고 N번째 Iteration에 Supervision으로 사용하며 다시 Pseudo Ground Truth를 Refine 시킵니다.
Iteration이 진행될 수록 이 사람들이 설계한 Architecture를 통해 점점 Supervised Ground Truth와 비슷해져가는 것을 볼 수 있습니다.
아이디어 자체는 간단한 것 같습니다. 이제 방법론 한번 살펴보도록 하겠습니다.
Method
본 논문에서 제안하는 Refine Loc은 크게 두가지의 Components를 가지고 있습니다.
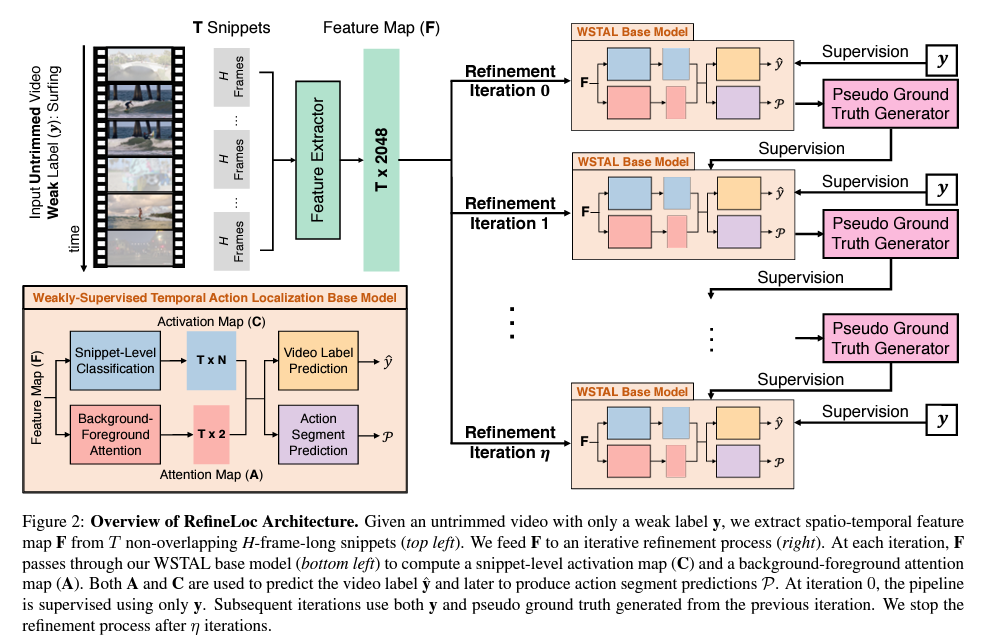
기본적인 Base Model이 있고 여기서 Pseudo Ground Truth를 생성해줍니다.
그리고 나서 생성된 Pseudo Ground Truth를 가지고 Iteration을 돌면서 Base Model을 Refinement 시킵니다. 우선 Base Model 부터 살펴보고 Refinement Processing에 대해서 살펴보도록 하겠습니다.
Base Model
- Feature Extraction Module
Feature Extraction은 많이들 사용하는 3D Convolution 기반의 Action Recognition Backbone을 사용합니다. 본 논문에서는 TSN, I3D 두가지 backbone을 이용하여 사용하였고, 결국 하나의 비디오가 T개의 Snippet Feature로 요약이 되며 하나의 Snippet은 16개의 프레임을 특징으로 기술 한 것으로 2048의 차원을 가지고 있습니다. 따라서 Input Feature의 Dimension은 T\times2048로 정의가 됩니다.
- Snippet Level Classification Module
이제 Snippet 단위로 Classification을 진행합니다. 지금 이 Snippet이 어떤 Action인지 예측하는 문제로 비디오 하나는 T개의 snippet feature로 구성이 되어 있고, 데이터셋에 존재하는 action의 갯수가 N개라고 할 때 Snippet Level Classification Module에서는 T\times N의 class activation map을 만드는 것이 목적입니다.
단순히 FC Layer 통과시켜서 저러한 map을 만들 수 있다고 하네요. 간단합니다.
- Background-Foreground Attention Module
이 Module의 목적은 background snippet은 억제하고 foreground snippet에 집중할 수 있도록 하는 attention weight를 학습하는 것이 목적입니다. 따라서 T\times 2의 attention map을 만드는 것이 목적입니다. 각 snippet 별로 binary classification을 진행하여 foreground 인지 background 인지 예측할 수 있는 FC Layer를 학습한다고 보면 됩니다.
- Video Label Prediction Module
위에서 Class Activation Map(C)와 Attention Map(A)를 FC Layer를 통해 얻을 수 있었습니다. 이제는 이 C와 A를 결합하여 N차원의 확률 벡터인 \hat{y} 을 만드는 것이 목적입니다.
이 부분이 조금 헷갈렸는데 우선 class activation map(C)을 가지고 Softmax를 취하면 어떻게 될까요? 각 Snippet에 대해서 각 action에 대한 확률이 나오겠죠?
다음으로는 attention map을 가지고 softmax를 두번 취해줍니다.
한번은 background-foreground 차원 축에 대해서 진행해주고
한번은 시간 축에 대해서 진행해주는 데 무슨 얘기냐면 attention map : A\in R^{T\times 2}인데 softmax를 한번은 N에 대해서 진행해주고, 한번은 2에 대해서 진행해준다는 얘기 입니다.

즉 Attention map에 대한 softmax는 위에 두가지 형태로 정의가 됩니다.
즉 A^{-bf}_{t}은 각 snippet당 foreground 이거나 background일 확률을 정의하는 벡터가 되며
A^{-time}_{t}은 가장 foreground이거나 background 같은 snippet에 대한 확률을 정의하는 벡터가 됩니다.
A^{-time}_{t}는 결국 Video Level의 Prediction을 생성하는 데 사용이 됩니다. \hat{y} =\sum^{T}_{t=1} A^{-time}_{t}\times C_{t}
Action Segment Prediction Module
여기서는 post processing 과정입니다. 무언가 흩어져있는 정보를 종합하여 하나의 구간을 만들어야 합니다. Class Activation map과 A^{-time}_{t}을 이용하게 되는 데 우선 background attention score가 일정 threshold 이상 넘어가는 snippet은 filtering 시킵니다. 이는 A^{-time}_{t}에 담겨져 있는 정보를 토대로 진행할 수 있을 거 같네요.
다음으로는 top-k개의 class 만을 고려하게 되는데 각 top class n에 대해서 class score가 일정 threshold 보다 낮은 것 역시 filtering을 진행해줍니다. 이는 Class Activation Map에 있는 정보를 토대로 진행할 수 있을 것 같습니다.

여기서는 결국 background snippet 들을 grouping 시켜서 background 구간을 예측할 수 있습니다. s는 그 segment에 대한 score 이구요.
Iterative Refinement Process
이제 Base model에서 일어나는 전반적인 과정을 알았으니, 어떻게 Refinement 시켜서 정확하게 만드는 지 알아보도록 하겠습니다.
간단합니다. 비디오 레벨의 예측은 단순히 Classification 문제로 Cross Entropy Loss를 통해 최적화 시킬 수 있습니다. 여기서 만들어지는 Pseudo Label은 모델이 예측한 Foreground Segment 입니다. 즉 각 Snippet 별로 이제 Label이 생겼다고 볼 수 있네요. 근데 저 Pseudo Label은 이전 Iteration에서 만들어준 예측값으로 사용해준다고 합니다. Snippet 별로 Foreground인지 Background인지 예측하는 이진 분류 문제이기 때문에 동일하게 Cross Entropy Loss를 통해 최적화 시킬 수 있습니다.

\Beta는 trade-off coefficient로 이따 ablation에서 최적의 parameter를 찾았다고 합니다. 어떤 Loss에 더 가중치를 두냐에 따라 성능이 달라지겠죠.
Experiments
Ablation Study
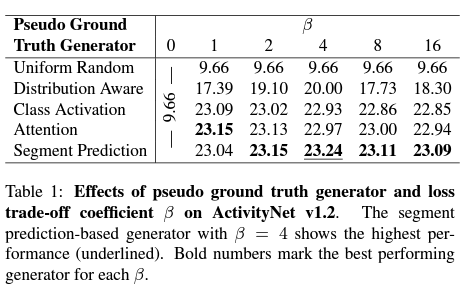
간단한 ablation을 수행하고 있습니다. Pseudo Ground Truth Generator를 다르게 하면서 loss trade-off coefficient \beta 에 대한 실험입니다. \beta 가 0일 때의 성능 보다는 확실히 refinement를 진행하는 것이 더 높은 성능을 보여줌으로 써 저자가 제안한 방법론의 effectiveness를 입증하고 있습니다. 또한 Pseudo Ground Truth Generator로써 Segment Prediction을 Pseudo label로 사용하는 것이 가장 좋은 성능을 보여주고 있습니다.

Refinement Iteration에 따른 mAP 성능을 측정하고 있는 테이블 입니다. Refine을 계속한다고 해서 성능이 계속 좋아지지는 않는 모양입니다. 저자가 얘기하기로는 Iteration 처음 한번 돌 때 성능 향상이 9.48로 큰폭을 보이며 증가한다고 얘기하지만 애초에 베이스 성능이 너무 낮아서 인상 깊은지는 모르겠습니다..
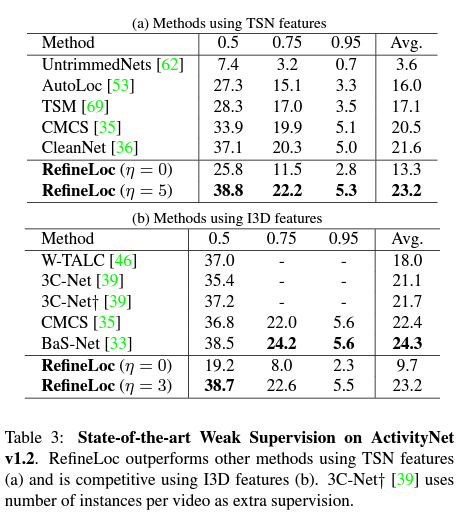
ActivityNet v1.2에서 SOTA를 달성했다고 합니다. TSN feature일 때는 SOTA이지만 I3D일 때는 조금 떨어지는 성능을 보여주고 있습니다.
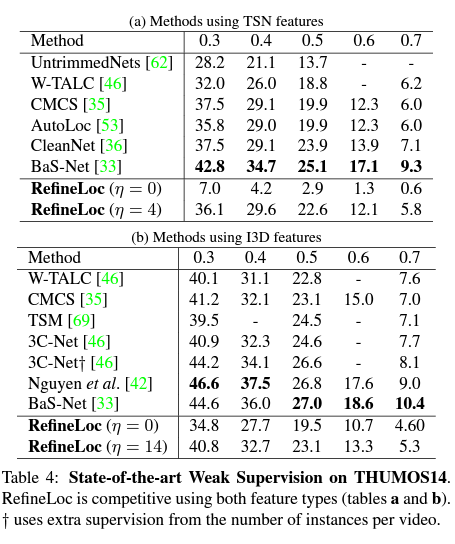
THUMOS14에서는 SOTA도 아닌데 왜 Reporting을 했는지 모르겠습니다. 논문에서도 너무 짧게 서술이 되어있는데 그냥 base model의 성능을 refinement를 통해 올렸다 이렇게 얘기하고 있는데 의미가 있는지는 모르겠습니다.

이 실험은 조금 의미가 있는 것 같습니다. 기존 SOTA였던 W-TALC와 BaS-Net에 대해서 Refinement 과정을 추가해서 학습 시켰더니 새로운 SOTA를 달성했다고 주장하고 있습니다. 이런 실험은 저자가 제안한 Refinement과정에 대해서 Generality를 어느정도 보여줬다고 생각합니다.

마지막으로 정성적 결과인데, 사실 Temporal Localization에서 정성적 결과는 그냥 거의 체리피킹이라 생각하고 있습니다. 워낙 데이터셋이 역동적이고 변동성이 커서 그렇습니다. 마지막 정성적 결과는 실패에 대한 케이스를 보여주고 있습니다. 결과만 보면 첫번째 Iteration에서의 결과가 가장 좋은 것 같은데 5번째 Iteration의 결과는 그냥 모두 aggregate 되어 좋지 못한 예측을 수행하고 있습니다.
Conclusion
방법론 자체는 간단했지만 좋았지만 성능적인 측면이나 실험 분석에 대한 내용에 대해서는 조금 아쉬웠던 논문이었습니다.
개인적으로 가장 큰 공부가 되었던 건 비디오의 Background와 Foreground를 구분할 수 있는 Attention Module을 설계하는 부분이 었던 것 같습니다.
다음 리뷰는 본 논문에서 비교 실험 대상이었던 BaS-Net에 대해서 읽어볼 예정입니다.
리뷰 읽어주셔서 감사합니다.