오늘은 video summarization에 대한 논문을 가져왔습니다. 긴 비디오를 압축 한다는 말은, 결국 비디오가 담고 있는 주제를 잘 요약한다는 것이고 궁극적으로 비디오 검색에도 활용이 가능하지 않을까 싶어서 읽어봤습니다. 그럼 시작하겠습니다.
Introduction
먼저 Video summarization(이하 비디오 요약)은 무슨 task 일까요?
Given an input raw video, the goal is to select a small subset of key frames from the input video to create a shorter summary video that best describes the content of the original video.
논문에서는 위와 같이 작성되어 있는데요. 즉, 원본 비디오를 요약할 수 있는 짧은 비디오를 key frame을 기반으로 만드는 것이 목표입니다.
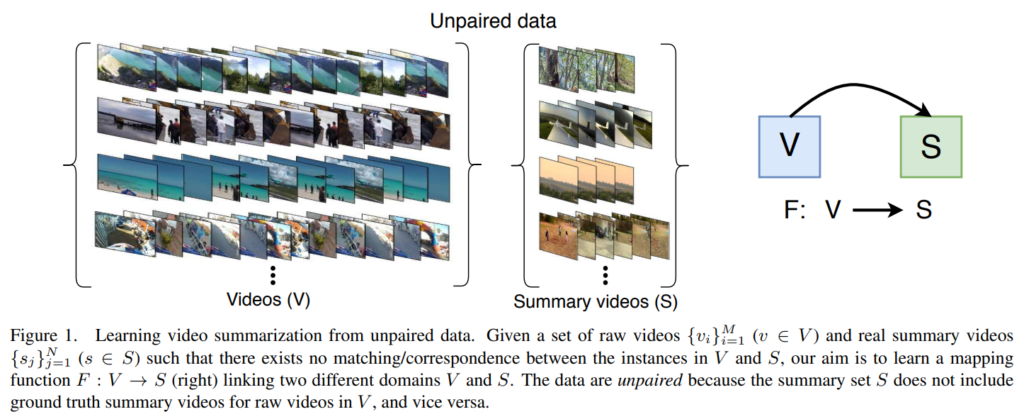
적혀있는 것과 같이 이 논문은 위와 같은 비디오 요약을 수행하는데, 이걸 unpaired data로 학습하는 방법론을 제안했습니다. 이 방법은 데이터를 수집하는 것에 있어서 큰 도움이 됩니다. Raw video(V)는 인터넷에서 쉽게 구할 수 있습니다. 그리고 요즘은 유튜브에 하이라이트 영상들도 많아서 Summary video(S)도 쉽게 구할 수 있죠. 이 V와 S로 학습을 한다고 생각하고 그림을 보면, 문제가 있습니다. V와 S의 관계가 딱히 없어보이죠? 맞습니다. 이 V랑 S가 관계가 있을 수도, 없을 수도 있다는 문제점이 있습니다. 이 논문은 이러한 문제점들을 모두 고려해서 학습할 수 있는 방법론을 제안합니다.
그럼 왜 라벨 없이 학습하는 것이 좋은가? 당연히 지도 학습이 당연히 사람의 직관이 들어간 요약 비디오를 바탕으로 학습하기 때문에 성능이 좋지만, 이런 류의 라벨링은 인간의 직관이 들어가야해서 비용이 매우 비싸죠. 그렇기 때문이 이러한 방법론이 좋다고 합니다.
일단 contribution이 아래와 같다고 합니다.
- Unpaired 데이터로 비디오 요약을 학습할 수 있는 새 공식 제안
- GAN을 통해 Unpaired 데이터로 학습하는 모델 제안
- 이 모델의 효용성을 보이기 위한 benchmark와 실험 결과들
- 성능 개선을 위해 partial supervision으로의 확장 가능한 방법론 제안
Our Approach
일단 아래의 두 네트워크가 등장하는데요.
S_K : key frame selector network
S_D : summary discriminator network
이런 네트워크가 있는 점을 알고, 각 네트워크에 대한 설명과 Loss에 대한 설명이 이어집니다.
Network Architecture
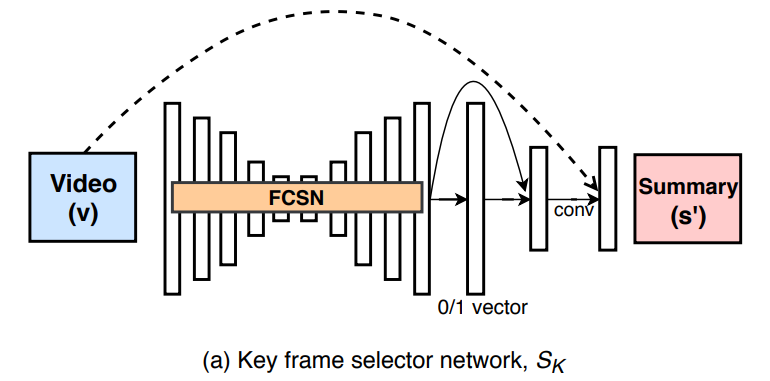
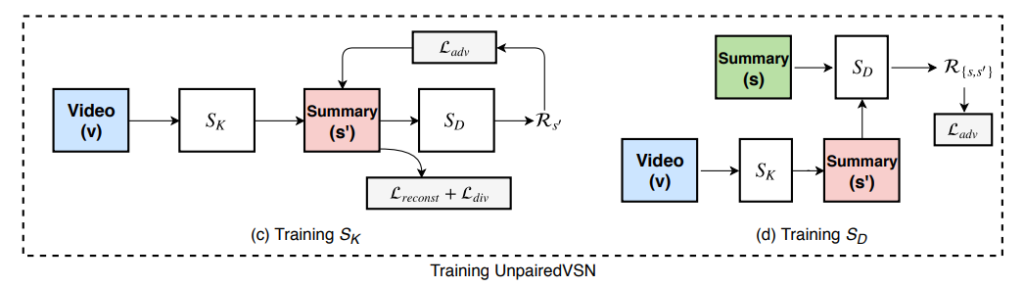
S_K는 T frame의 입력을 받아, k key frames의 요약된 비디오를 뽑아냅니다. 여기서 FCSN (Fully convolutional sequence network)를 사용합니다. (논문 저자들의 이전 논문에서도 video summarization을 위해 사용했네요.)
FCSN가 temporal한 정보를 보존하면서 video frame을 encoding 해줍니다. 이 값을 바탕으로 decoding을 하면서, 입력 비디오의 크기와 동일한 크기의 prediction score vector를 생성해줍니다. 이 score vector는 이 프레임이 keyframe인지 아닌지를 구분해주는 score이고, 이 값을 바탕으로 key frame을 선택해서 요약된 비디오를 만들어줍니다.
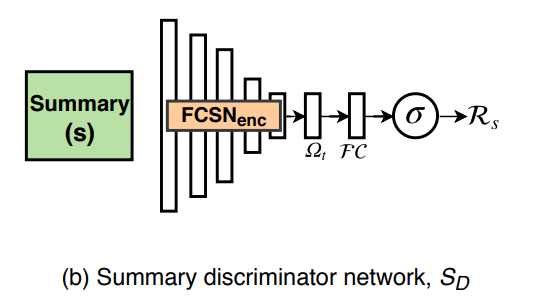
그림상에서는 입력이 한종류 같지만, 실제로는 두종류를 입력합니다. 같은 요약 비디오 S지만, 진짜 요약 비디오 S가 있고, 생성된 S_K(V)가 있기 때문입니다. 이 네트워크의 최종 목표는 R_s라는 점수를 계산하는 것이 목표입니다. 이 R_s는 S_D에 입력된 비디오가 진짜 요약 비디오인지 아니면 생성된 요약 비디오인지를 알려주는 점수입니다.
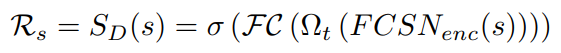
수식으로는 위와 같은 구조를 가지게 되는데요. FCSN encoder를 통해 나온 vector들을 temporal average pooling(Ω_t)를 통해 video feature로 만들고, FC 레이어와 sigmoid를 통해 R_s를 계산하는 과정입니다.
Learning
Adversarial Loss
이 Adversarial Loss가 많이 언급되는데, GAN에서 사용하는 방법론이 이 Adversarial Loss 입니다.
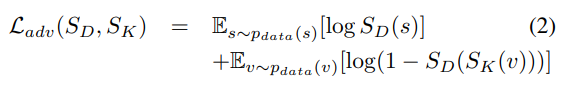
수식상으로는 위와 같은데요. 요약하면 진짜 요약 비디오와 생성된 요약 비디오와의 데이터 분산을 맞추기 위해 사용합니다. 사실 GAN이 어떻게 동작하는지 알아야 이해가 쉬울 것 같긴 한데… GAN을 몰라서 와닫지가 않네요.
Reconstruction Loss
이 Reconstruction Loss는 입력된 v의 frame-level feature와 S_k(v)에서 만들어지는 reconstructed feature 사이의 차이를 줄이기 위해 사용합니다. (여기서 feature는 모두 key frame 기반)
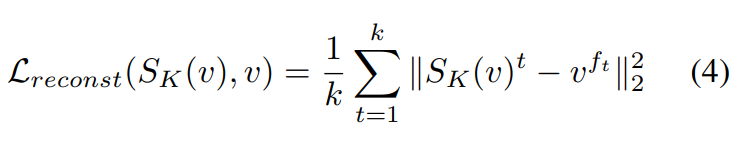
f와 t가 새로 등장하는데, f는 입력 비디오의 f번째 frame이고, t는 출력되는 비디오의 t번째 프레임입니다. 이 점을 생각하고 수식을 요약하면, 결국 입력 프레임과 출력 프레임의 차이를 계산하는 수식입니다. 이게 FCSN의 encoder-decoder를 학습할 때 쓰입니다.
Diversity Loss
비디오 요약에서 요약된 비디오가 시각적인 다양성을 유지하는게 좋다고 하는 연구들에 따라, 여기서도 이 시각적 다양성은 높이기 위해 “repelling regularizer”를 적용했다고 합니다.
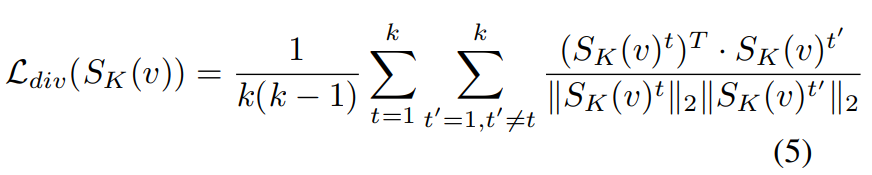
아무튼수식은 위와 같습니다. 딱히 새로 등장하는 기호는 없으니 요약하보면… 생성된 요약 비디오의 프레임들끼리의 계산을 통해 나온 이 값을 최소화하면, 시각적으로 다양하다는 것을 확인할 수 있어서 이렇게 사용한다고 합니다.
Final loss
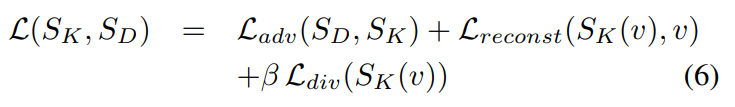
그리고 최종 Loss가 결국은 위와 같이 되는데, 그림을 잘 보면 S_K와 S_D를 개별적으로 학습하고 UnpairedVSN이라는 것으로 묶여있는 것을 보실 수 있습니다.
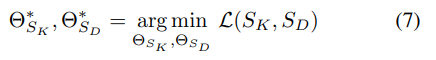
이 UnpairedVSN은 개별적으로 학습된 두 모듈의 최적의 파라미터 값 Θ^*을 찾기 위한 학습입니다. 개별 Loss들은 검색을 좀 해보니 사실 GAN에서 흔하게 쓰는 개념들 같고, 이 논문에서 특이한 점은 이 UnpairedVSN이 아닐까 싶습니다.
Learning with Partial Supervision
paired된 비디오가 없는 상황을 가정한 논문이기는 하지만, 그런 비디오가 있는 상황에서도 학습을 할 수 있다고 합니다.
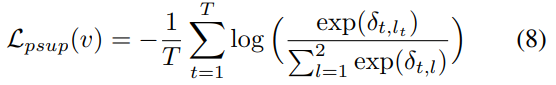
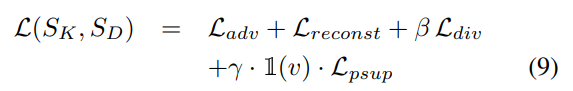
이때는 위와 같이 Loss 함수를 추가해서 사용을 하는데요. δ_{t, l}는 입력 비디오의 t번째 프레임이 l번째 클래스일 확률을 나타냅니다. (클래스라고 말은 하지만, key frame인지 아닌지에 대한 구분) 그리고 l_t는 key frame GT 정보입니다. 크게 달라지는 내용은 없고, GT랑 효율적인 비교를 하기 위해 구성한 Loss 입니다.
Experiments

데이터셋은 위와 같은 데이터셋을 사용했는데, 평가는 Keyshot-based metric을 기반으로 수행한다고 합니다.
이 metric은 KTS 알고리즘을 이용해서 비디오를 세그먼트 단위로 쪼개고, 세그먼트가 key frame을 포함하고 있으면 그 세그먼트의 모든 프레임은 1로 표기하고 아니면 0으로 표기하는 방법입니다. 그리고 비교는 knapsack 알고리즘을 통해 테스트할 비디오의 15% 정도 길이의 keyshot 기반 요약 비디오를 생성하고, 이 결과와 비교하는 metric입니다.
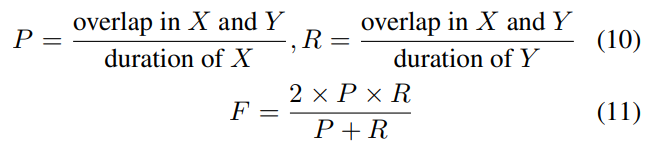
이러한 방법을 기반으로 Precision, Recall, F-score를 게산했다고 합니다. 그리고 각각 5번씩 실험해서 평균값으로 리포팅 했다고 합니다.
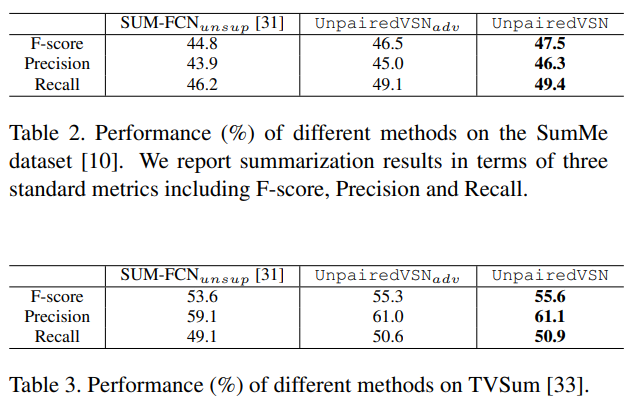
summary discriminator network를 제거한 Unsupervised SUM-FCN과 diversity loss가 빠진 UnpairedVSN_{adv}와 UnpairedVSN을 baseline으로 삼아 자체 평가한 결과는 위와 같습니다. Unpaired기반 방법론 중에서는 최초라서 이렇게 평가했는데, 성능 차이를 보아 논문 저자들이 추가한 loss나 네트워크가 잘 작동하는 것을 보여주는 것 같습니다.
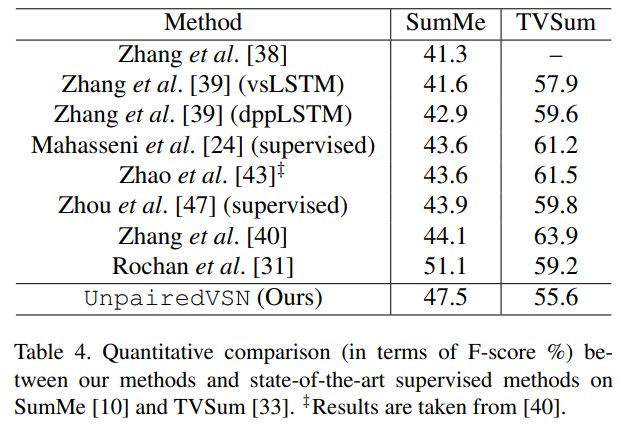
비록 SOTA는 아니지만, 지도학습 방법론들과 비교하면 성능이 좀 낮긴 합니다. 하지만 학습하는 방법의 차이가 있다 보니, 지도학습 방법론과 비교해서 학습 데이터 양이 2배 정도 차이가 난다는 것을 감안하면 꽤 성능이 좋다고 볼 수 있습니다.
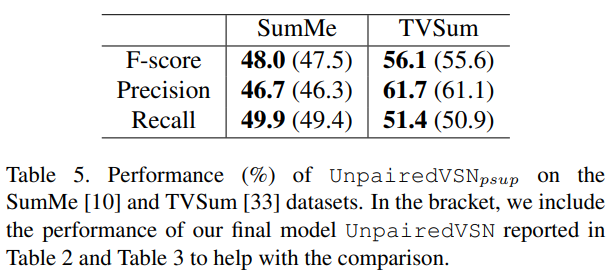
그리고 Partial Supervision으로의 확장성이 있다는 점을 확인하는 ablation study인데, 최초 학습에서 데이터셋의 10% 정도를 supervision으로 학습할 경우 성능 향상이 분명이 있음을 확인할 수 있습니다.
Conclusion
사실 제안하는 방법론은 GAN을 알고있는 사람이라면 쉽게 이해할 것 같았기 때문에, GAN 논문을 읽어봐야 겠다는 생각을 했습니다. 그래서 그런지 논문이 방법론을 설명하는 부분보다 실험 파트가 길고, 실험 세팅에 대한 자세한 설명과 결과분석이 이어집니다. 간단하지만 효율적인 방법론을 충분한 실험으로 보충해서 CVPR에 붙지 않았나…하는 논문이었습니다.
Reconstruction 과정에 대해서 좀 더 자세히 설명해주실 수 있나요?
Feature level로 reconstruction인가요 하니면 실제 비디오 프레임 level의 reconstruction인가요?
Sk network에서의 reconstruction은 frame-level로 수행됩니다. 근데 reconstruction Loss에서의 reconstruction은 keyframe 단위로 비교합니다. 이게 Sk network에서 실제로 복원을 잘 했는지 안했는지를 판별하는게 아니라, video summarization을 위해 keyframe을 잘 추출했는지를 알아보기 때문에 그런 것 같습니다.