제가 이번에 리뷰할 논문은 few-shot segmentation에 관한 논문으로 few-shot learning으로 segmentation을 하는 것이 궁금하여 읽어보게 되었습니다.
Abstract
DNN이 개념을 이해하도록 하기 위해 사람은 픽셀 단위의 주석이 달린 많은 양의 학습 데이터를 수집해야 했다. Few-shot segmentation 모델은 적은 학습 데이터를 가지고 새로운 클래스에 일반화 하는 것을 목표로 한다. 논문에서 cross-reference network(CRNet)을 제안하여 qurey이미지 뿐만 아니라 support 이미지에 대해 동시 예측을 한다. 상호 참조를 통해 두 이미지에 공존하는 객체를 잘 찾아낼 수 있고, 조정 모듈을 통해 전경 영역에 대한 예측을 개선한다. 또한 K-shot learning을 위해 다중 라벨된 support 이미지를 활요하기 위해 네트워크 미세 조정을 제안하였다.
Introduction
레이블링 된 데이터를 수집하는 것은 많은 비용이 든다. 또한 데이터 수집은 특정 카테고리의 집합에 대해 중요하므로, 이전 class에서 배운 지식을 보지않은 다른 class로 전이하는 것은 어렵다. 훈련된 모델을 직접 미세조정하려면 여전히 많은 양의 새로운 데이터가 필요하다. 이러한 문제를 해결하기 위해 few-shot learning이 제안되었다. few-shot learning은 이전 테스크에 대해 학습된 모델이 몇개의 레이블된 학습 이미지를 통해 보지 않은 테스크에 대해 일반화될 수 있을 것으로 기대한다.
few-shot image segmentation은 새로운 class가 주어지면 주어진 클래스의 전경 영역을 찾는 것을 목표로, 몇개의 레이블링 된 이미지만 본다. 지침 정보는 쿼리 이미지의 전경 예측을 위해 support 셋에서 추출되며, 일반적으로 두 브랜치의 비대칭 네트워크 구조로 달성된다. 하지만 해당 논문에서는 query외 support 셋이 few-shot segmentation모델에서 전환될 수 있다고 주장한다. 핵심 구성요소는 cross-reference 모듈로 두 이미지에 공존하는 특징을 강화된 형상을 생성한다. query 이미지와 support 이미지의 두 head가 동시에 예측하는 대칭 cross-reference 모듈을 디자인하였고 기존 방식과의 차이는 그림1을 통해 확인할 수 있다. sub-task는 추가 loss를 통해 cross-reference 모듈의 학습을 용이하게 하였다.
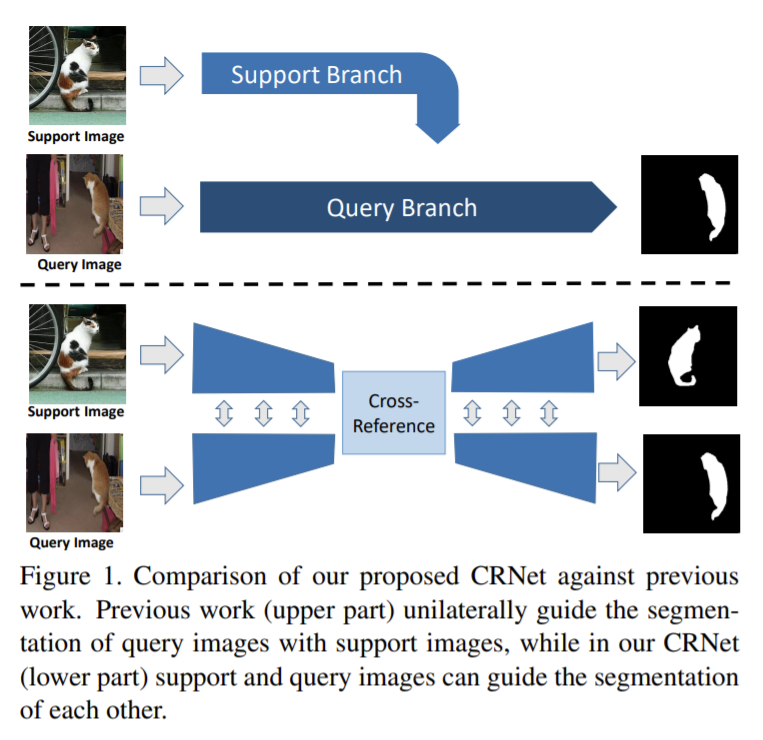
또한 물체의 모양이 큰 차이가 있으므로 예측을 반복적으로 다듬기 위해 효과적인 마스크 개선 모듈을 개발한다. 초기 예측을 통해 네트워크는 높은 신뢰도의 시드 영역을 찾아 확률 맵 형태로 모듈에 저장하고 이후 예측에 사용한다. 새로운 예측을 할 때마다 업데이트를 하면 마스크 조정 모듈을 몇단계 실행하여 전경을 더 잘 예측할 수 있다.
마지막으로 한번에 두 개의 입력 이미지에 대해 예측을 할 수 있으므로 네트워크를 미세조정 하는 데 최소 k^2 이미지 쌍을 사용하여 정확도를 높일 수 있다.
Related work
few shot learning
few-shot learning은 제한된 데이터를 이용하여 새로운 작업에 쉽게 전이할 수 있는 모델을 학습하는 것을 목표로 한다. 테스트 시점에 미세조정이 필요한지 여부에 따라 두가지로 나뉜다. non-finetuned 방식은이미지 쌍의 유사성을 결정하기 위해 임베딩 인코더와 distance metric을 학습하는 metric 기반 방식으로 학습된 매개변수를 고정하여 테스트 함으로써 빠른 추론을 할 수 있지만 여러 support 이미지를 사용할 수 있으면 성능이 쉽게 포화된다. 미세조정이 필요한 finetuned 방식은 예측을 위해 새로운 task에 적응해야 한다. 다라서 fully connected layer만을 학습하여 few-shot에서 좋은 성능을 얻는다. 본 논문은 non-finetuned feedforward 모델을 사용하고 다중 라벨링 support 이미지를 활용하기 위해 k-shot 설정에서 모델 finetuning을 한다.
few-shot segmentation
대부분의 이전 연구는 few-shot segmentation을 segmentation 안내를 위해 고안하였다. 이전의 모든 연구는 쿼리 이미지의 전경 마스크만 지도학습에 사용하는 반면, 해당 논문은 query와 support 셋이 서로를 안내하고 두 브랜치가 모두 지도학습을 위한 전경을 예측한다.
Task definition
few-shot segmentation은 겹치는 카테고리가 없는 두 소량의 데이터셋으로 각각 학습과 테스트를 진행하여 테스트 이미지의 전경을 예측하는 것을 목표로 한다. 이때 라벨이 있는 이미지는 support 셋, 라벨이 없는 이미지는 query 셋이라 한다.
Method
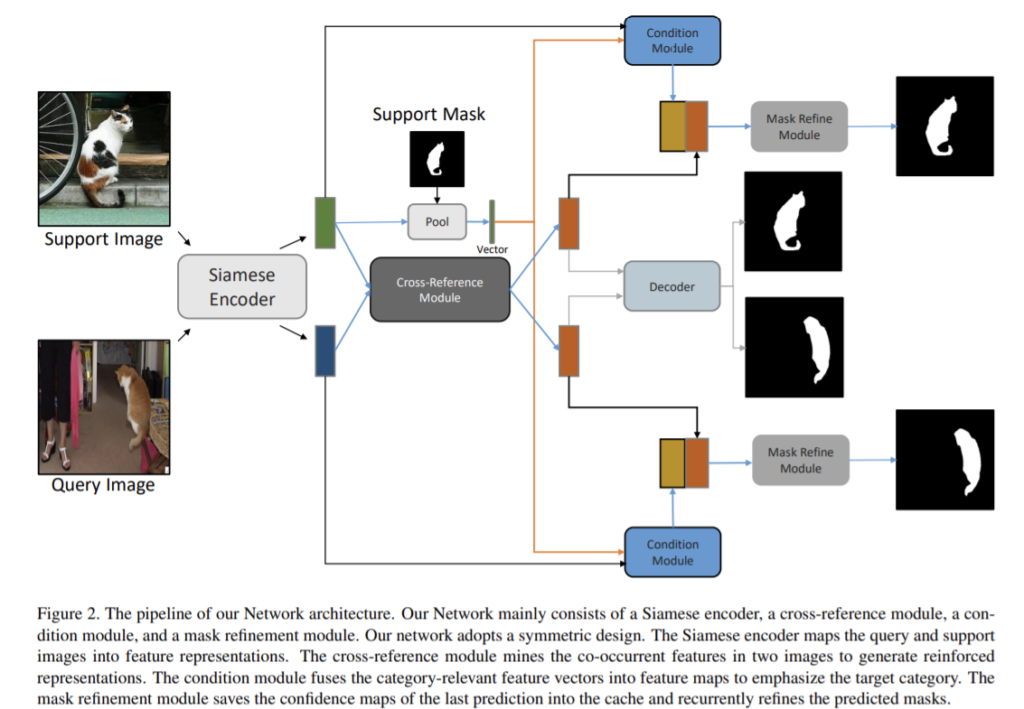
few-shot segmentation을 위해 제안된 cross-reference 네트워크로 전체적인 구조는 그림2를 통해 확인할 수 있다.
본 논문은 support-query 이미지 쌍의 관계가 few-shot segmentation에 필수적이라 주장하며 두 이미지가 서로 segmentation을 안내하는 CRNet을 제안한다. few-shot 분할을 수행하는 방법을 학습하며, support-query 이미지 쌍을 siames encoder로 심층 특징으로 인코딩 한 뒤 cross-reference 모듈을 적용해 두 이미지에 공존하는 객체의 특징을 채굴한다. 라벨링 된 마스크를 활용하기 위해 조건부 모듈은 전경 예측을 위한 support 셋의 카테고리 정보를 통합하며 마스크 조정 모듈은 최종 전경 예측을 위한 신뢰 영역 맵을 반복적으로 저장한다. k-shot의 경우 이전 연구는 다른 1-shot의 평균을 이용하여 조정하였으나 해당 논문은 더 많은 support 이미지를 사용하도록 최적화 기반의 방법을 적용하여 모델을 조정한다.
Siamese encoder
파라미터를 공유하는 CNN쌍으로 으로 query 이미지와 support 이미지를 특징맵으로 인코딩한다.동일한 공간으로 이미지를 내장하여 cross-reference 모듈은 전경을 찾기 위한 공통의 특징을 더 잘 뽑을 수 있다. 대표적인 특징 임베딩을 얻기 위해 skip connection을 활용한다.
Cross-Reference Module
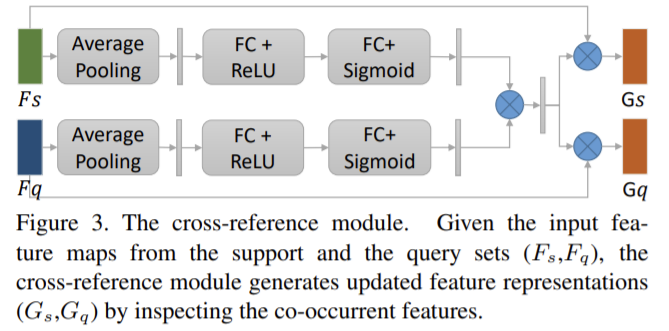
cross-reference 모듈은 두 이미지에 같이 존재하는 특징을 뽑고 업데이트 된 표현을 생성한다.
두 이미지의 global 통계를 얻기 위해 avg pooling을 이용한다. 이후 두개의 FC 레이어를 통과하여 베터 값을 채널의 중요도로 변환하여 [0,1]사이의 값이 되도록 한다. 이후 두 브랜치에 있는 벡터는 element-wise 곱을 하여 공통 특징이 활성화 되도록 한다. 마지막으로 강화된 featuers 표현을 생성하기 위해 입력 특징맵에 가중치를 부여하기 위한 퓨전된 벡터를 사용한다. 결과적으로 보면 해당 모듈을 통해 입력 feature보다 두 이미지에 동시에 있는 표현에 집중한다.
강화된 특징맵을 기반으로 두 이미지에 동시에 있는 객체를 예측하기 위한 head를 추가한다. 강화된 특징맵이 ASPP 레이어에 conv 레이어로 구성되며 마지막 conv 레이어가 전경 및 배경 score에 해당하는 2채널 예측을 생성한다.
Condition Module
support 세 주석을 활용하기 위해 전경 마스크 예측을 위해 카테고리 정보를 효율적으로 통합하는 condition 모듈을 설계한다.
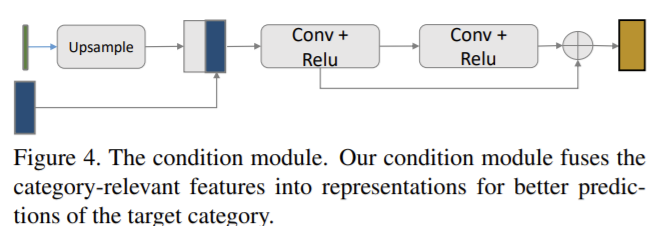
할당된 개체 카테고리의 전경 마스크만 찾는 것이 few-shot segmentation의 목표이므로 task 관련 벡터는 대상 카테고리를 분할하는 조건 역할을 한다. 카테고리 관련 임베딩을 위해 feature와 입력 이미지 모두에서 배경 영역을 필터링하였다. 카테고리 관련 벡터는 feature map의 동일한 크기로 bilinearly upsampling 하고 연결함으로써 condition 모듈의 강화된 feature map과 융합된다.
Mask Refinement Module
일반적으로 weakly supervised semantic segmentation은 바로 예측을 하는 것이 어려우므로 시드 영역을 찾은 다음 다듬는 것이 일반적이다. 이러한 원리를 기반으로 예측 결과를 단계별로 조정하는 마스크 정재 모듈을 설계한다. 신뢰 영역과 이미지 특징을 기반으로 점차 마스크를 최적화 하여 전체 객체 영역을 찾는다.
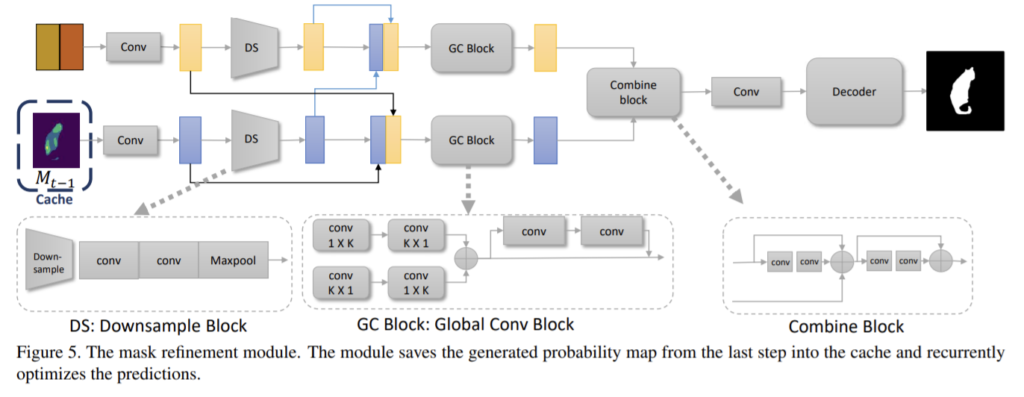
마스크 정제 모듈에는 캐시에 저장된 신뢰도 맵과 condition 모듈과 cross-reference 모듈의 출력을 연결한 2개의 입력이 있다. 초기 예측을 위해 캐쉬는 0 마스크로 초기화되고 모듈은 입력 feature map만을 기반으로 예측을 진행한다. 이 모듈을 여러번 반복하여 최종 정제 마스크를 생성한다.
Finetuning for K-Shot Learning
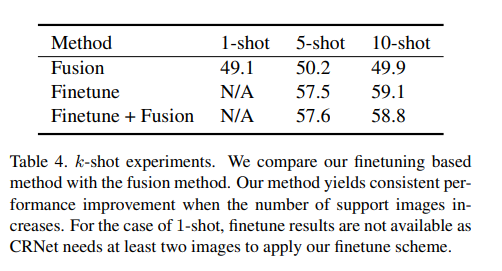
k-shot learning은 여러 레이블이 지정된 support의 이점을 활용하기 위해 네트워크를 미세 조정할 것을 제안한다. 본 논문의 네트워크는 한번에 두 이미지를 예측할 수 있으므로 네트워크 미세 조정에 최대 k^2개의 이미지 쌍을 이용할 수 있다. test에서 모델을 미세조정하기 위해 라벨이 지정된 support 이미지에서 무작위로 샘플링을 하고 Siamese 인코더의 매개 변수를 고정한 뒤 나머지 모듈만 미세조정한다. 실험을 통해 논문에서 제안한 미세조정을 통해 성능이 지속적으로 오르고 퓨전 기반의 방식은 support 이미지 수가 증가할 때 종종 saturation된 성능을 얻을 수 있음을 입증한다.
Experiment
dataset
- PASCAL VOC 2012 데이터셋을 이용
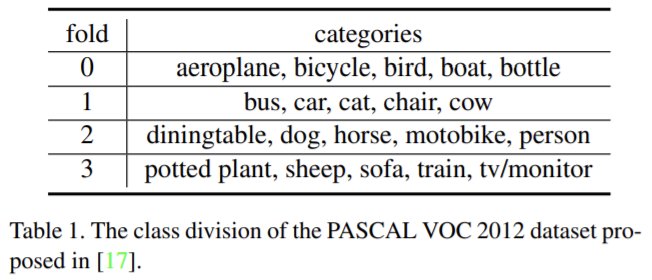
- 20개의 객체 카테고리를 균등하게 나눠 4 folds를 만들고 그중 3 fold는 학습 class, 하나는 test class로 이용(표 참고). 4개의 fold를 test에 사용하여 4번의 평균을 이용하여 성능을 측정함.
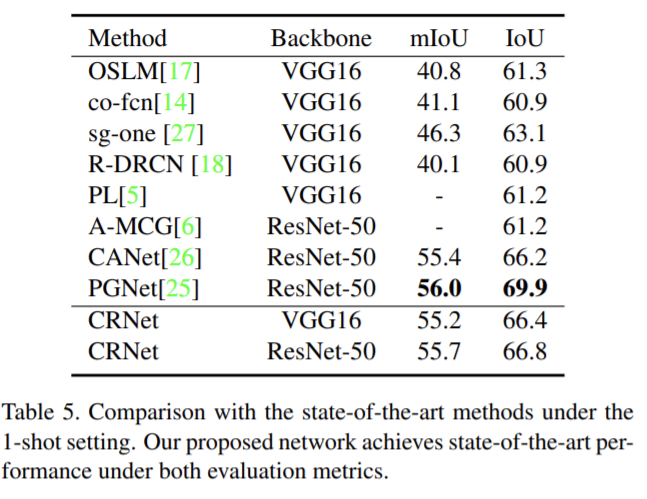
experiment result
- imagenet으로 사전학습된resnet-50의 멀티 레벨 feature를 Siamese 인코더에서 이미지 표현으로 이용.
- 테스트 시 마스크 조정 모듈을 5회 실행하여 예측 마스크를 개선함.
- k-shot 학습의 경우 Siamese 인코더를 고정하고 나머지 파라미터를 미세조정함.

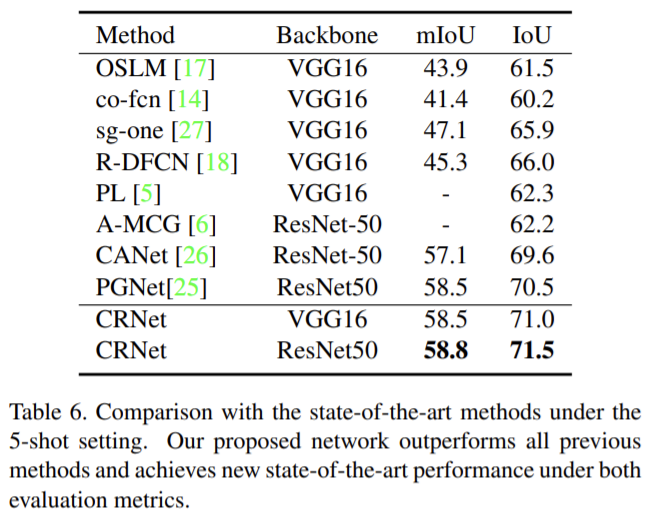
Ablation study

각 요소를 검사하기 위한 ablation study. 본 논문에서 제안한 두 모듈 condition 모듈과 cross-reference 모듈의 효과를 확인함.각 요소를 제거하면 성능이 상당히 떨어지는 것을 확인할 수 있고 특히 cross-reference 모듈에서 성능 하락 폭이 큰 것을 확인할 수 있음.