

오늘 리뷰할 논문은 video retrieval과 alignment를 동시에 하고자 한 논문입니다. 이번 저희 팀이 CVPR에 제출했던 논문의 주제와 유사한 주제를 지닌 논문으로, CVPR 제출 마감쯤 나온 논문입니다. 해당 논문에서는 video retrieval과 alignment를 동시 다루는 task를 Segment-level Content-based Video Retrieval (S-CBVR)라고 부르며, 이를 해결하기 위해 Segment Similarity and Alignment Network (SSAN)를 제안하였습니다. 자세한 내용은 아래서 설명드리겠습니다.
1. Method
1.1 Self-supervised Keyframe Extraction
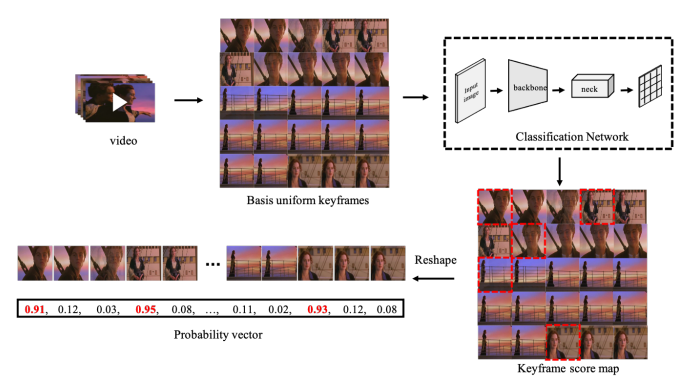
제안된 방법론 SSAN은 크게 두 가지 모듈로 구성됩니다. 그 중 첫번째 모듈 Self-supervised Keyframe Extraction (SKE) 모듈에 대해 설명드리도록 하겠습니다. 주로 retrieval task에서는 대용량의 데이터 베이스를 사용하기 때문에 많은 리소스가 요구됩니다. 특히 video retrieval task의 경우, 비디오 자체도 상당히 redundant하기 때문에 cost를 줄이는 방식의 도입 또한 요구되어집니다. 해당 방법론에서는 이와 같은 cost를 줄이기 위해, 비디오에서 keyframe을 추출하는 SKE 모듈을 도입하였습니다.
SKE 모듈은 주어진 입력 비디오의 프레임을 32×32 크기로 줄인 뒤, 총 24×24개의 프레임을 Fig 2와 같이 정사각형으로 이어붙여 사용합니다. 그 후, 각각의 프레임들을 classification network를 통과시켜 classification score를 예측하고, 총 24×24 크기의 score map을 얻어냅니다. 이때, classification network로는 MobileNet이 사용되었습니다. 얻어낸 score map을 BCE Loss를 통해 학습을 시키는데, 학습을 위한 label은 해당 프레임이 keyframe인지 아닌지에 대한 것으로 “Optimally grouped deep features using normalized cost for video scene detection”에서와 동일하게 사용하였다고 합니다.(유료네요..) 이후, 해당 score map을 하나의 벡터 형태로 쭉 펼치고 thresholding하여 binary mask로 만든 뒤, 다음 모듈의 입력으로 사용하게 됩니다.
해당 모듈의 의문점으로는 정사각형으로 이어붙이는 이유가 frame간의 receptive field를 넓히기 위해서라고는 하지만 classification network를 개별적으로 통과하고 이후 reshape 하여 하나의 벡터 형태로 만들기에 어떤 부분에서 receptive field를 넓히기 위한 연산이 적용되었는가 입니다.
1.2 Temporal Alignment based on Similarity Pattern Detection
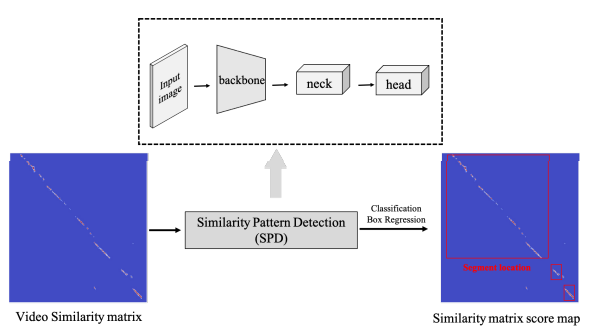
이번에 설명드릴 것은 SSAN의 두번째 모듈 Similarity Pattern Detection (SPD) 모듈입니다. 해당 모듈은 ViSiL과 유사하게 먼저 frame-to-frame similarity map을 만듭니다. 조금 다른 점은 두 비디오 간의 similarity map을 만들 때, ViSiL에서는 각 frame-level feature 들 간의 chamfer similarity를 계산하였다면 해당 논문에서는 cosine similarity를 사용하였습니다. 두 비디오 간의 similarity map을 만든 후, 해당 map에서 segment-level alignment를 다루기 위해 object detection과 같이 접근하였습니다. Similarity map에서 어떤 부분이 서로 연관되어 있는 지를 detection 하는 것으로, detection된 box의 행은 두 비디오 중 특정 한 비디오의 segment, 열은 나머지 비디오의 segment를 의미하게 됩니다. 이처럼 similarity map에서 detection을 하는 SPD 모듈은 classification head와 regression head로 구성되어 있으며, 각각 BCE Loss와 GIoU Loss로 학습됩니다. 그리고 학습 시 필요한 bounding box 정보와 binary class 정보(서로 연관 있는지 없는지)는 데이터 셋에 annotation 되어 있는 segment-level relevant 정보를 활용하였다고 합니다.
1.3 End-to-End and Multi-Task Joint Learning
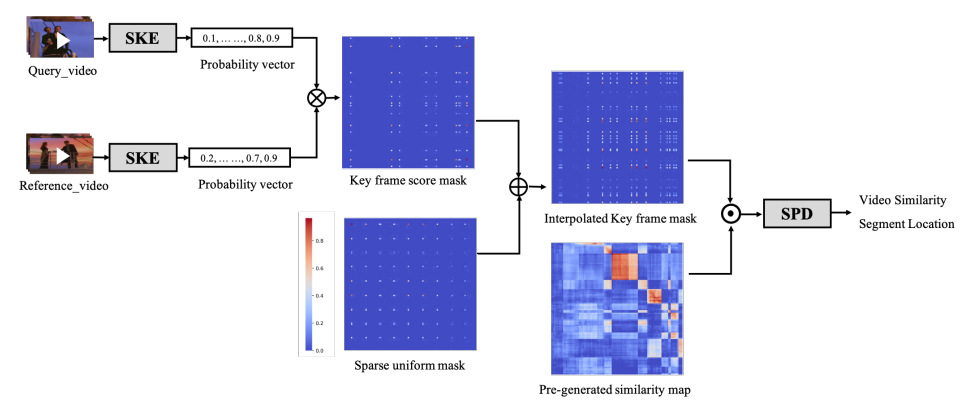
SKE 모듈에서 추출된 keyframe은 비디오 마다 서로 다른 위치에 존재하기에 다양한 similarity pattern을 만들어냅니다. 이러한 다양한 pattern은 이어지는 모듈 SPD를 robust하게 도울 수 있기 때문에, SKE와 SPD를 end-to-end 방식으로 학습하였다고 합니다. 학습 과정에 대해 자세하게 설명 드리자면, 우선 두 비디오에서 각각 keyframe score로 만들어진 binary mask를 생성하고 BCE Loss를 통해 학습합니다. 그리고 이 두 binary mask 중 하나를 transpose 하여 행렬 곱 연산을 취합니다. 이를 통해 두 비디오 간의 keyframe score mask를 생성하고, 해당 mask로 frame-to-frame similarity를 필터링 하여 SPD 모듈의 입력으로 사용합니다. 이 때, keyframe이 하나도 안뽑혀 SPD 모듈의 입력이 없는 것을 방지하고자 sparse한 uniform mask를 생성 및 필터링 시 적용하여, 최소한의 keyframe을 보장해주었다고합니다. SPD 모듈에서는 이를 입력으로 segment의 similarity와 location을 학습합니다.
inference 시에는 효율을 위해 query와 database 간의 one vs one matching을 통한 유사도 연산이 아닌 M 개까지만 비디오를 retrieve 한다고 적혀있는데, 이같은 방식은 mAP 성능 측정 시의 pair comparison이 아니지 않아 의문이 들었습니다. 해당 부분은 추후에 본 논문이 코드를 공개한다면 자세히 들여다봐야할 것 같습니다.
2. Experiment
2.1 Temporal alignment & Large-Scale Alignment and Retrieval
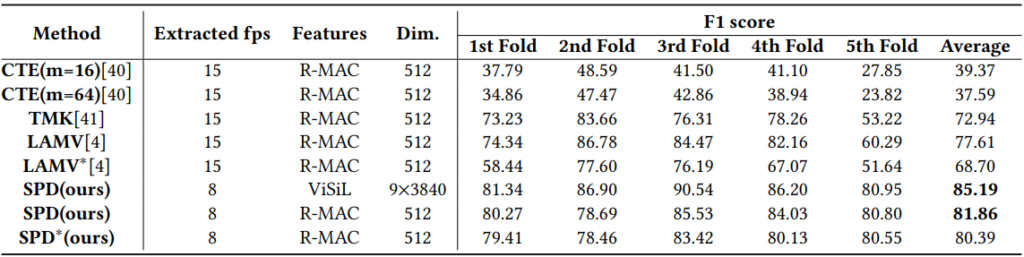
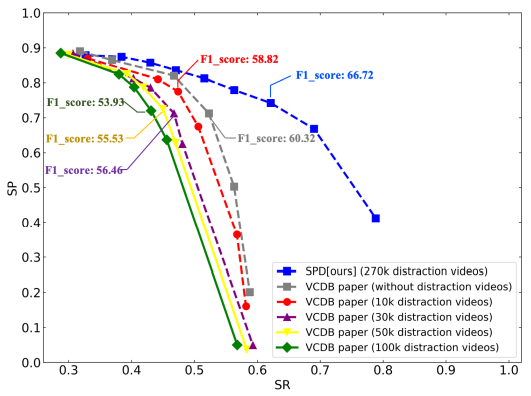
우선 SSAN은 Segment-level 의 CBVR을 다루었기에 VCDB에서 temporal alignment 성능을 측정하였습니다. 측정 방식은 VCDB 내의 core datase을 5 fold로 나누어 학습하였으며, F1-score를 통해 평가하였습니다. Table 1에서 보이듯, 평균적인 성능이 기존 방법론들 대비 꽤나 좋은 것을 보였습니다. 또한 VCDB paper에서 보였던 Fig 5와 같이, background dataset이 많이 추가되었음에도 불구하고 좋은 SP-SR curve를 보였습니다. 이를 통해 segment-level에서 large scale video retrieval 성능을 보였다고 합니다. (그러나 제가 알기로는 SP와 SR이 similarity rank를 매기고 있지는 않은 것으로 알고 있는데.. 흠)
2.2 Video Retrieval
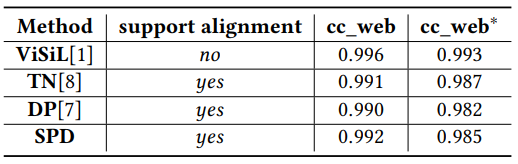
Table 2는 제안된 SSAN을 VCDB로 학습한 후, CC_WEB_VIDEO 데이터 셋에서 평가했을 때의 성능입니다. SPD는 ViSiL을 제외한 다른 방법론보다 높은 성능을 보였습니다. 그러나 해당 테이블에 있는 ViSiL 성능은 학습과정이 포함된 ViSiL_v이며, 학습하지 않고 frame-to-frame similarity 만을 이용한 ViSiL_f의 성능 0.993보다도 SPD가 낮은 성능(0.992)을 보였습니다. 뿐만아니라, 글로만 적혀있는 FIVR-200K에서의 성능은 ViSiL보다 낮아서 따로 테이블로 만들지 않은 것으로 보이며, FIVR task에서 0.75의 성능을 보였다고 글로 적혀있는데 이는 DSVR, CSVR, ISVR 중 어떤 task인지 정확히 명시되어 있지는 않았습니다.
3. Difference from SRA
SRA는 이번 저희가 CVPR을 준비하면서 제안하였던 방법론 입니다. 리뷰를 받으며 SSAN이 retrieval과 alignment를 동시에 해결한 최초의 방법론이 아니냐는 질문을 받았었고, SSAN과의 차이를 알려달라는 리뷰도 받았어서 차이점을 남겨 보고자합니다. 결과적으로 SSAN이 저희보다 일찍 나오기도 했고 retrieval과 alignment를 동시에 다루었기에 최초는 맞습니다. 또한 저희 방법론과 달리, overfit 이슈도 없으며 end-to-end의 이점 또한 존재합니다. 그러나 보면서 느꼈던 점은 video retrieval 보다는 alignment에 치중되어 있다는 느낌이 들었습니다. 학습 과정에서 optimizing하고자 한 것은 어떤 위치에 alignment가 존재하는지 였으며, 이러한 이유로 alignment task에서는 좋은 성능을 보였으나 retrieval task에서는 기존 방법론보다 낮은 성능을 보인 것 같습니다. 그리고 retrieval과 alignment를 동시에 했다는 실험 결과로 내세운 Fig 5의 경우, VCDB를 제안한 논문에서는 video copy detection으로 언급하고 있으며 retrieval과 alignment를 동시에 했다는 언급은 없습니다. 제가 판단했을 때도 SP-SR curve는 similarity rank를 고려하지 않는 평가 지표이기 때문에 retrieval과 alignment를 동시에 했다라기보다는 video copy detection을 한 것이 맞는 것으로 보입니다. 그리고 이를 제외하고는 retrieval과 alignment를 동시에 한 실험 결과가 존재하지 않기에 SSAN은 “alignment를 다룬 방법론이며 retrieval도 할 수는 있다” 정도가 되지않을까 싶습니다. 저희 방법론은 retrieval과 alignment를 동시에 판단하기 위해 평가 지표와 데이터 셋을 제안하였기에 이부분에서 다른 것 같습니다.
여담으로 사실 해당 논문을 보면서, 오타도 한 컬럼당 두 세개씩 존재하고, 왜 self-supervised learning인지 명시적으로 작성되어 있지도 않고, 어떤 연산으로 24×24의 정사각형으로 이어붙인 프레임이 receptive field를 넓혔는지 자세하게 적혀 있지도 않고 등등 논문이 떨어진 설움에 안좋은 점만 보였고, 이로 인해 좀 세게 글을 쓸까하다가 잘못 이해했겠지 싶어 조금 누그러트린게 없지 않아 있습니다. 보면서, 우리 논문도 overfit 문제만 해결했으면 결과가 달라졌을텐데 싶다가도 참.. 아쉬움이 남네요. 그래도 SSAN의 주장으로는 retrieval과 alignment를 동시에 다루었다고 하니, 다음 저의 논문에서 해당 방법론을 넘기는 성능으로 다시 한번 도전해보도록 기약하며 리뷰를 마치겠습니다.
4. References
[1] 유료 논문이라 관심있으신 분 슬랙 주세요