지난주 잠시 감정인식으로 들어갔다가 video retrieval 관련 논문 나눠 읽기로 배정된 논문으로 다시 돌아왔습니다. 비디오 검색을 안하는 분들이라도 저희가 ViSiL은 많이 언급해서 아실텐데요. 그 ViSiL을 만든 저자의 논문입니다.
그래서 이 논문들이 내용적으로 익숙하다는 특징이 있는데요. 순서를 정리해보면 아래와 같습니다.
- (2017) Near-Duplicate Video Retrieval by Aggregating Intermediate CNN Layers
- (2017) Near-Duplicate Video Retrieval with Deep Metric Learning
- (2019) ViSiL: Fine-grained spatio-temporal video similarity learning
- (2021) DnS: Distill-and-Select for Efficient and Accurate Video Indexing and Retrieval
이러한 점을 감안하고 리뷰 시작하겠습니다.
Introduction
논문 제목에서도 확인할 수 있듯이 이 논문은 NDVR이라는 복제 비디오를 탐지하기 위한 task를 해결하기 위해 제안된 논문입니다. NDVR에 대한 정의는 “near-duplicate videos are considered to be identical or close to exact duplicate of each other”인데요. 한국어로 바꾸면 거의 비슷하거나 완전 똑같은 비디오라고 보면 됩니다.
논문 저자는 이 문제를 해결하기 위해 “intermediate CNN layer”에서 feature를 뽑아서 해결하고자 했습니다. 그래서 VGG와 같은 모델의 중간에서 feature를 뽑아서 비디오 레벨 히스토그램 H_f를 만듭니다.
결국은 frame-level의 feature를 잘 aggregation해서 하나의 video-level feature로 만드는 것이 중요합니다. 이 논문에서는 이를 위해 layer vector를 합치는 방법과, 레이어에서 뽑혀진 codebook을 바탕으로 BoW를 수행하는 방법을 제안했고, 성능도 좋았다고 합니다.
Approach overview
간략한 순서를 요약하면 아래와 같이 수행됩니다.
- Deep architecture(VGG)를 통해 feature 뽑기
- 뽑힌 feature를 aggregation 하기
- Aggregation된 video historgram을 tf-idf로 유사도 계산하기
CNN based feature extraction
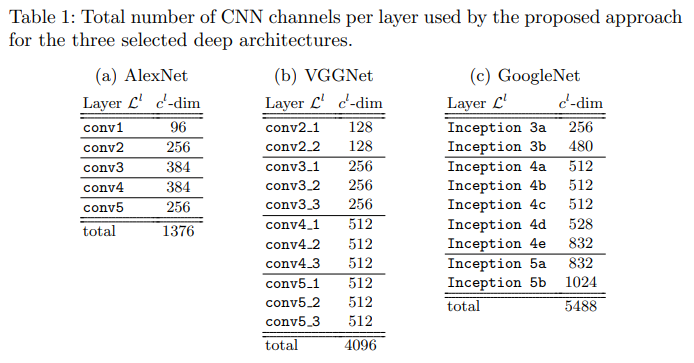
이 논문에서는 3가지 네트워크를 이용해서 실험을 했는데요. L^n의 feature를 뽑습니다. VGG를 예시로 들면, Conv2_2가 L^1이고, Conv3_3이 L^2입니다. 이런 위치에서 뽑는 이유도 있는데요. activation을 거쳐야 크기는 다르지만 local structure를 보존하는 visual representation을 얻을 수 있기 때문이라고 합니다. 근데 문제는 이렇게 뽑으면 single vector를 뽑은게 아니죠?
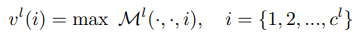
그래서 feature map M^l의 모든 채널에 max pooling을 적용해줘서 single vector로 만들어줍니다. 여기에 정규화까지 수행해주면 레이어마다 feature를 뽑는 과정은 끝납니다.
Feature Aggregation
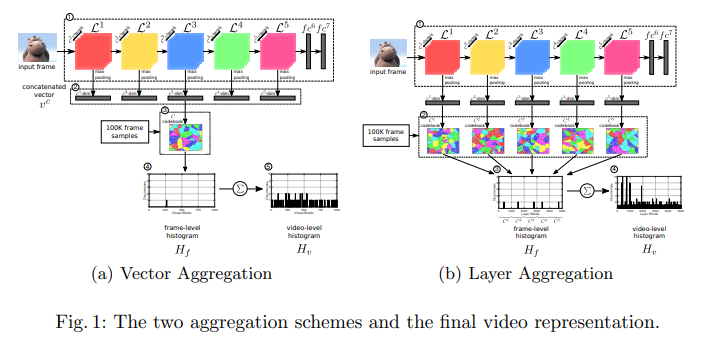
논문에서 aggregation을 두가지 방법으로 수행한다고 말씀드렸는데요. 여기서는 Vector aggregation과 Layer aggregation으로 나뉩니다. 어떻게 수행해도 frame level historgram H_f을 구한 다음, 비디오의 프레임마다 구해진 이 값들을 더해줘서 video level histogram H_v가 된다는 것은 동일합니다.
Vector Aggregation
L^n개의 레이어로부터 n개의 vector를 뽑습니다. 그리고 이 vector들을 모두 concat 해주고, 여기서 BoW를 적용해줍니다. 그러면 하나의 이미지에서 C_k = \{t_1, t_2 ..., t_k\} K개의 visual word를 가진 codebook C가 만들어집니다. 그리고 이 경우에 video keyframe은 가장 가까운 visual word에 할당됩니다. 그래서 이 프레임의 descriptor는 가장 가까운 visual word t_f = N N (V^c_f)이기 때문에, H_f가 하나의 visual word만 포함하게 됩니다.
Layer Aggregation
여기서는 vector를 concat해주는 것이 아니라, 하나의 벡터마다 하나의 codebook을 만들어줍니다. 수식으로 정리하면 C^i_k = \{t_1, t_2 ..., t_k\}와 같은데요. 이 방법은 레이어들에서 뽑혀진 구조적인 정보를 보존할 수 있습니다. 그리고 이 방법론은 Vector aggregation과는 레이어마다 뽑힌 layer vector가 가장 가까운 visual word가 되기 때문에, L개의 visual word로 구성됩니다.
어쨋든 이 두 방법론 모두 비디오 프레임 중에서 랜덤으로 선택된 100K개의 프레임에서 scalable K-Means++를 이용해서 codebook을 생성한다고 합니다.
Keyframe to video aggregation
최종적인 video representation은 keyframe의 BoW histogram으로 부터 얻어집니다. H_v는 F = \{f_1, f_2 ... f_F\}일 때, 이 히스토그램을 모두 더해주면 됩니다. (그럼 keyframe을 구하는 방법도 있어야 하지 않냐고 하실 수 있는데, 여기서 사용하는 CC_WEB_VIDEO에는 이미 keyframe이 구해진 상태로 있습니다.)
Video Indexing and Quering
자 그럼 우리에게는 video histogram이 있습니다. 이 논문에서는 tf-idf를 이용해서 유사도를 계산합니다. 그리고 이 tf-idf의 가중치는 w_{td} = n_{td} * log|D_b|/n_t로 수행됩니다. 각각의 기호는 아래와 같습니다.
- w_{td} : 비디오 d에서의 word t의 가중치
- n_{td} : 비디오 d에서 word t가 등장한 횟수
- n_t : 모든 데이터베이스의 word t가 등장한 횟수
- D_b : 데이터베이스의 모든 비디오

검색해보니 변형해서 사용하는 방법론은 아니고, 일반적으로 쓰는 방법을 visual word로 대치해서 사용하고 있는 것 같았습니다. 최종적으로는 쿼리 비디오에 대한 히스토그램 H^q_v를 구해서 TF-IDF representation에 의거해 계산해서 cosine 유사도에 따라 내림차순으로 정렬하면 retrieval이 끝납니다.
Evaluation
평가는 CC_WEB_VIDEO 데이터셋을 이용해서 수행됩니다. 라벨링 정보를 보시면 아시겠지만, copy detection용 데이터셋입니다.
Experiments
Impact of CNN architecture and vocabulary size
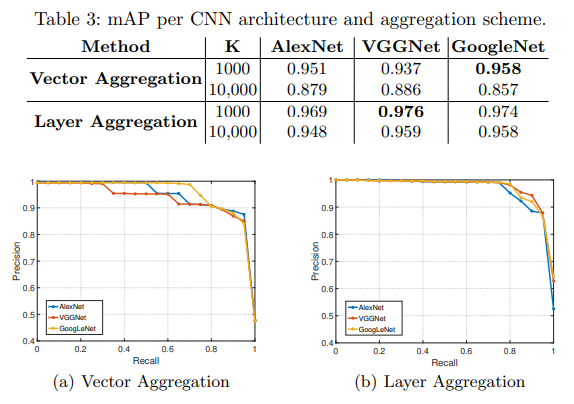
visual word K의 갯수는 실행 속도와 성능에 영향을 미칩니다. 여기서는 두가지를 실험했습니다. 전반적으로 Layer Aggregation이 더 좋은 성능을 보였습니다. K가 많아질수록 vector aggregation에서의 성능이 더 떨어졌는데, 이러한 점 때문에 같은 K를 가질때 두 방법론의 성능 차이가 심해질거라 같은 수의 K를 두면 안된다는 결론을 얻었다고 합니다.
Performance using individual layers
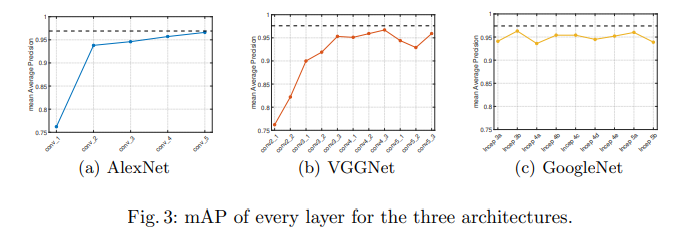
이건 약간 ablation study같은 느낌입니다. 특정 레이어만 사용했을 때 성능을 보여줍니다. 전반적으로 더 깊은 layer (semantic한 정보를 가지고 있는 layer)에서 성능이 오릅니다. 그리고 단일 레이어에서의 성능이 Vector aggregation보다 높지만, Layer aggregation보다 좋은 성능이 없는 것에서 vector aggregation이 딱히 좋은 방법이 아님을 보입니다.
Performance per query
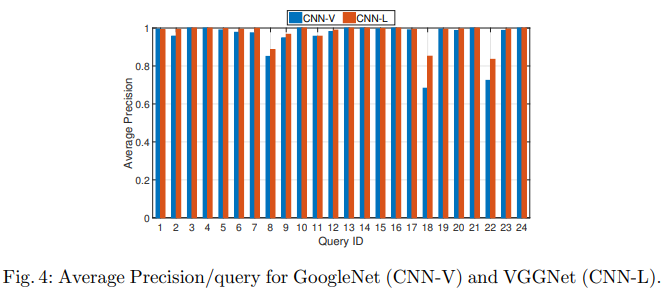
쿼리별 성능에 대한 결과를 보면 좋은 성능에서 유추할 수 있듯이, layer aggregation이 더 좋은 성능을 가집니다. 또한, 18번과 22번 쿼리가 화질도 안좋아서 비교적 어려운 비디오에 속하는 경우인데도, layer aggregation은 비교적 잘 수행했음을 볼 수 있습니다.
Comparison against existing NDVR approaches

기존의 기계학습 방법론과 성능을 비교해봐도 좋은 성능을 보입니다. 어쨋든 이러한 방법론들도 keyframe으로부터 feature를 만드는 것이 중요한데, CNN이 이러한 부분에서도 성능이 좋다는 점을 보이는 것 같습니다.
Conclusion
어떻게보면 간단해보이지만, 여기서부터 시작해서 ViSiL이 나왔다고 생각하면… 좋은 논문 같습니다. ViSiL이 여러가지를 잘 고려한 부분들이 많은데, feature extraction을 하는 방법은 이 논문에서 R-MAC이 추가된 정도로 내용이 비슷하거든요. (물론, attention 기법도 추가되긴 했고 뽑고 난 이후엔 다르긴 다릅니다) 그럼 여기까지 하고 다음 리뷰로 오겠습니다.
vocabulary를 만드는 과정에 대해 설명해주실 수 있을까요?
평가 데이터 셋이 아닌 다른 데이터 셋에서 만드나요?
Vocabulary가 여기서는 visual word를 지칭하고 있습니다. 그래서 위의 Vector & Layer Aggregation을 통하면 만들어지고요. 이 Visual word들은 여기서는 collection?이라는 표현을 쓰던데, 데이터베이스 내의 비디오들의 프레임들에서 visual word를 뽑고, 랜덤으로 모아서 codebook을 만듭니다.
vector aggregation에서 K개의 visual word를가진 codebook을 만든다고 하셨는 데 k는 값이 실험적으로 정해지나요?? 또한 layer aggregation이 레이어들에서 뽑힌 구조적 정보를 보존할 수 있다는 게 어떤 의미인지 궁금합니다..
K는 실험적인 수치입니다. 그래서 실험칸에서 보면 K를 1000과 10000으로 실험한 결과가 있습니다. 구조적 정보를 보존할 수 있다는 말은, 논문에서 쓰는 표현인데요. 요즘 URP에서 SSD를 하고있으니 그 설명대로 하면, VGG에서 결국 레이어가 깊어질수록 semantic한 정보들을 더 가지고 있죠? 이런 것 처럼 레이어마다 feature map의 특징이 다릅니다. vector aggregation은 이 feature map을 vector로 만들고, 하나의 vector로 만들기 때문에 frame level histogram이 하나의 값만을 가르키죠? 반면에 layer aggregation을 보시면 feature map마다 codebook을 만들어서, frame level histogram에서 visual word가 레이어의 수만큼 있는 것을 보실 수 있습니다. 그만큼 다양한 정보를 가진 visual word들이 만들어질 테고, 그런 의미에서 구조적 정보를 보존한다고 이해했습니다.