
2015년 구글의 딥마인드에서는 ‘Spatial Transformer Networks(STN)’이라는 논문을 냈습니다. 해당 논문은 CNN은 Rotation과 Scale에 대해 상대적으로 강인하지 못한 부분을 극복하기 위해 실제 들어오는 입력(feature or image)에 affine transform을 적용한 논문입니다.
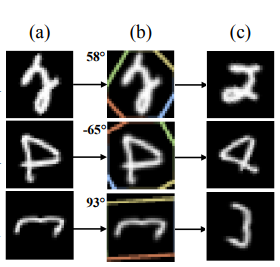
위의 그림과 같이 실제 입력된 영상(a)를 affine transformation을 통해서 더 classification이 수월하도록 feature map을 변형시키겠다는게 핵심이며, 구현또한 파이토치 공식 메뉴얼에 나타날 만큼 쉽게 구현하여 여기저기 붙일 수 있는 장점이 있습니다. (다만 한채널에 대해서만 적용 가능하여, 다중 여러 채널에서는 한채널씩 나눠서 진행하여 속도나 효율성이 굉장히 떨어집니다.)
그럼에도 저는 해당 연구를 제가 진행하고 있는 멀티스펙트럴 이미지의 정합과정에서 사용하고자 하였으나,,, affine transformation의 경우 Homograpy (Perspective transformation)다르며, 실제 정합문제를 해결하기 위해서는 affine보다는 Homograpy가 필요하다고 생각하여 구현 방향을 변경하였습니다. 입력된 이미지를 가지고 직접적인 Perspective transformation을 구할 수 없을까 생각하며 논문을 찾다가, 지난 2021년 CVPR에 서 진행된 한 워크숍에서 발표된 ‘Perceptual Loss for Robust Unsupervised Homography Estimation’ 논문을 알게돼 해당 논문에 대해서 리뷰를 진행하고자 합니다.
Introduction
해당 논문을 읽으면서 간만에 Related work를 포함하여 Introduction 파트가 굉장히 잘 작성됐다는 느낌을 받았습니다. 해당 논문에서는 실제 입력된 이미지들을 가지고 두 이미지 사이의 Homograpy(perspective transformation)를 구하려고 시도했던 논문들이 나타나있습니다.
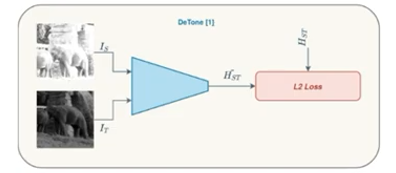
시간의 순서로 나타내면, 우선 ‘DeTone’ 이라느 사람은 단순한 CNN 아키텍처를 이용하여 직접적으로 Homograpy의 값을 예측하는 방법을 제안하였습니다. 그리고 이때 직접적으로 Loss를 계산하기 위해서 사용되는 GT는 tranditional feature based-method들을 사용하여, tranditional feature based-method들을 upper로 딥러닝으로 유사한 Homograpyh를 계산하고자 하였습니다.
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Deep Image Homography Estimation. arXiv preprint arXiv:1606.03798, 2016.
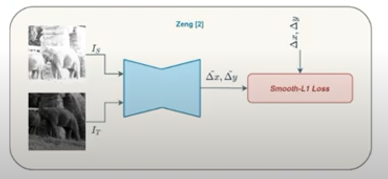
이후 Zeng이라는 사람은 좀 더 효과적인(?) Homography를 구하기 위해서 per-pixel offset regression을 제안했다고 합니다. 즉 그냥 픽셀별 오프셋을 계산하여 실제 H matrix를 계산하지 않아도 동일하게 이동시키는 방법을 제안하였다고 합니다. 이러한 방법은 제가 일전에 리뷰했던 방법과 유사합니다. (식물의 얼라인을 맞추기 위해서 사용했던 방법)
Rui Zeng, Simon Denman, Sridha Sridharan, and Clinton Fookes. Rethinking Planar Homography Estimation Using Perspective Fields. In Asian Conference on Computer Vision, pages 571–586. Springer, 2018.
하지만 위의 방법들은 실제 GT를 가지고 있어야 합니다. 하지만 이미지간의 관계를 구해서 완전히 정합시키기 위한 GT 값들은 실제 구하기도 어렵고 많은 시간과 노력이 들어갑니다. (픽셀레벨에서 정답을 구하려면 …;;) 따라서 이러한 방법을 극복하고자 Unsupervised 방법들이 제안됩니다.
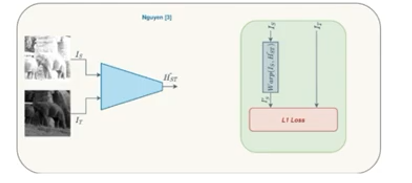
해당 방법은 모델을 이용하여 H matrix를 계산하고, 이를 토대로 이미지를 변환하게 됩니다. 다시 설명하면 실제 H 관계를 가지고 있는 source 이미지와 target 이미지 사이에서 source 이미지에 모델을 통해서 예측한 H matrix를 이용하여 warping하고 이를 기존 target 이미지와 비교하여 H matrix를 학습하는 방법입니다. 해당 방법에서 per-pixel intensity를 Loss로 사용한다고 합니다. 근데 문제는 이러한 방법은 어느정도 뷰포인트에 강인하게 작동하지만 Illumination의 변화가 크다면 전혀 작동하지 못하는 한계를 가지고 있습니다.
Ty Nguyen, Steven W Chen, Shreyas S Shivakumar, Camillo Jose Taylor, and Vijay Kumar. Unsupervised Deep Homography: A Fast and Robust Homography Estimation Model. IEEE Robotics and Automation Letters, 3(3):2346–2353, 2018
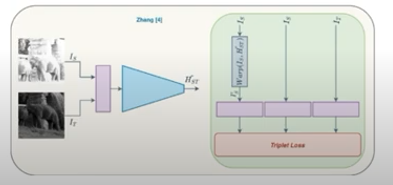
자 그러면 이러한 illumination에 대해서 강인함을 가지면서 H matrix를 계산하려면 어떻게 해야할까요..? 바로 feature level에서 Loss를 계산하도록 만들면 illumination에서 좀 더 강인한 효과를 얻을 수 있습니다. 그래서 실제로 Zhang이라는 사람은 feature representation level에서 H matrix를 계산할 수 있는 방법을 제안합니다. 근데 문제점이 한가지 있는데, feature level에서 비교하다보니까 또 뷰포인트가 큰 영상들에 대해서는 H matrix를 잘 못구하는 한계가 존재했다고 합니다.
Jirong Zhang, Chuan Wang, Shuaicheng Liu, Lanpeng Jia, Nianjin Ye, Jue Wang, Ji Zhou, and Jian Sun. Content-Aware Unsupervised Deep Homography Estimation. arXiv preprint
arXiv:1909.05983, 2019
앞서 설명한 방법론들을 정리하여 표로 나타내면 실제 해당 논문의 티저 이미지가 됩니다.

위에서 나타내는 숫자는 Mean Absolute Corner Error(MACE)를 의미하며, 결국 Supervised로 하자니 성능은 좋지만 GT를 구하는게 어렵고, Unsupervised로 하자니 Supervised에 비해성능은 떨어지고, 또 각 방법론들이 하나는 뷰포인트 변화에 약하고, 다른 하나는 조도 변화에 약한 단점을 가지고 있습니다. 해당 논문에서는 이러한 기존의 방법론들에 Loss를 한가지 제안하며 모든 방법들이 성능향상을 보이는 동시에 심지어 Unsupervised 방법임에도 불구하고 DeTone이 제안한 Supervised 방법을 이기는 성능을 나타냈다고 합니다. 그러면 해당 논문에서 제안하는 방법은 무엇일까요?
Methods
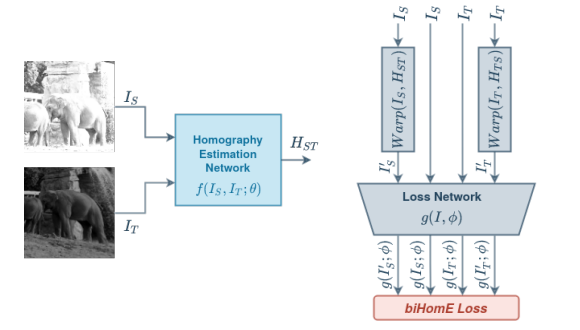
해당 논문에서 제안하는 방법은 간단합니다. 어떠한 방법이든 상관없이 기존 제안된 HEN 방법은 그대로 사용하고, 이제 Loss를 계산하는 것인데요. 위에 그림을 볼 수 있으면 알 수 있듯 Target 이미지를 H matrix (T->S) 로 변환하고, Source 이미지도 H matrix(S->T) 로 변환합니다. 즉, H matrix(S->T, T->S)를 2개를 예측하고 이를 이용하여 Target , Source , translated Traget, translated Source 총 4개의 이미지를 이용하여 Loss를 계산합니다. 뭔가 T->S, S->T 양뱡향으로 변환하며 Loss를 계산하고 있습니다. 그래서 해당 논문에서 제안하는 방법론은 ‘Bidirectional implicit Homography Estimation Loss (biHomE)’ 라고 명명합니다. 이를 수식적으로 살펴보면 다음과 같습니다.
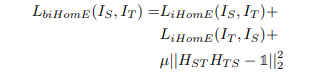
먼저 L_(iHomE) 라는 Loss가 있고, 이를 양방향으로 계산합니다. 해당 Loss에 대한 디테일을 확인해보면 다음과 같습니다.
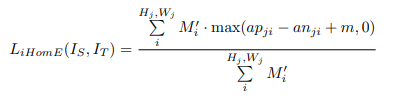
수식적으로 조금 어렵게 보이지만 실제 해당 수식에서 M은 mask라고 설명하는데, 해당 마스크는 입력되는 이미지와 동일하며 모두 1의 값을 가지는 Matrix입니다. 결국 M을 이용한 텀은 평균을 구하는 것이고 결국 핵심은 max(..) 이부분인데 여기서 ap는 anchor_positive channel aggregated distance, np는 negative channel aggregated distance를 의미한다고 합니다. 이를 수식으로 나타내면 아래와 같습니다.
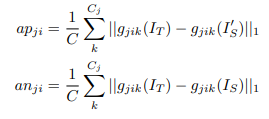
위에 수식에서 g는 High-level feature를 추출하는 Loss Network(학습 x, fixed parameter,ResNet34를 사용)이며, 이를 통해서 추출된 high level feature의 값 차이를 계산하게 됩니다. 이러한 방법은 모두가 잘아시는 아래 수식과 같습니다.
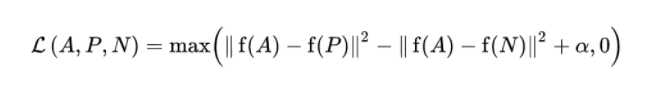
위의 수식은 Triplet Loss 수식이며, 즉 위의 방법론도 H matrix를 통해서 변환된 이미지는 Positive로 분류되어 더욱 가까워 지도록 변환 이전의 영상은 Negative로 더욱 멀어지도록 모델을 학습하게 됩니다.
그리고 다시 돌아와서 아래 H(S->T)H(T->S)가 포함된 수식의 경우 H matrix는 T->S, S->T가 역함수 관계를 가지기 때문에 두 함수를 곱하면 I matrix가 됩니다. 따라서 예측한 H matrix의 값들의 곱이 I matrix와 동일해지도록 Loss를 계산하게 됩니다.
Experiments
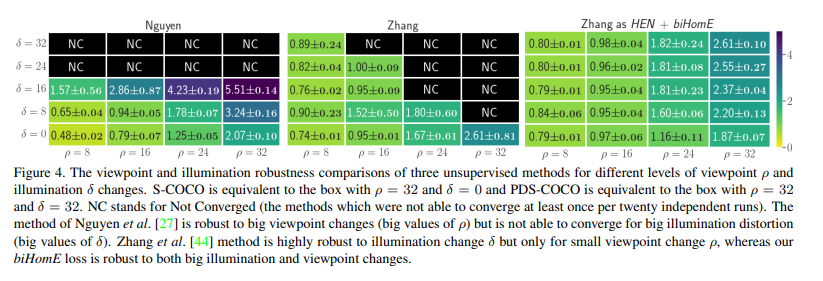
먼저 자신들의 방법을 통해서 기존 unsupervised 방법들이 각각 가지고 있던 뷰포인트 혹은 조도변화에 취약했던 부분을 극복할 수 있는지 확인합니다. 위의 분포에서 x축은 뷰포인트, y축은 조도변화를 나타냅니다. 각각 값에 대한 디테일은 논문에서 평가에 사용한 데이터셋을 사용하며 나타내는데 해당 내용은 넘어가도록 하겠습니다. ( 간략하게 조도는 constrast, saturation, hue noise를 준 정도를 나타내며, 뷰포인트는 [-ρ, ρ]range에서 랜덤하게 vertically and horizontally perturbed한 결과라고 합니다.)
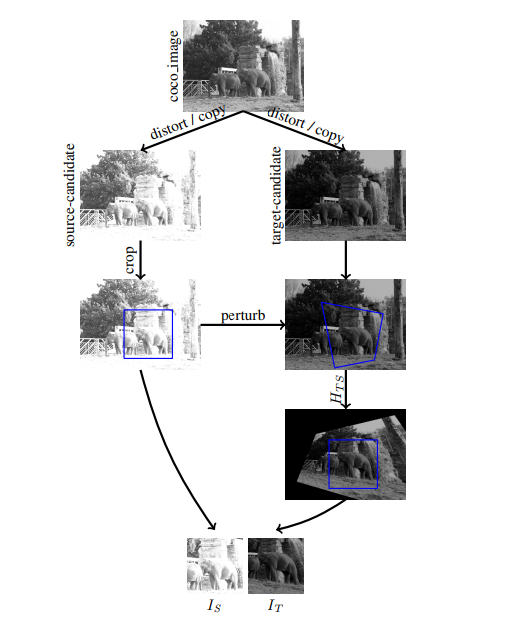
또 해당 논문에서는 기존 연구에서 없던 Realistic한 결과를 평가하기위해 기존 Synthgetic COCO 데이터셋을 사용한 연구들 뿐만 아니라 Photometrically Distorted Synthetic COCO (PDS-COCO) 데이터셋을 만들어 평가했다고 합니다. (제작방법은 아래와 같습니다.)
그리고 자신들이 제안하는 Loss를 사용하는것과 Loss Network로 다양한 백본을 변경할때 결과도 함께 리포팅 합니다.

그리고 마지막에 더 신기했던건 아래와 같이 변화된 내용을 캡셔닝으로 나타내는 분야가 있다고 합니다. ( ICCV에 나왔고, 한국인이 1저자이시네요.)
Dong Huk Park, Trevor Darrell, and Anna Rohrbach. Robust Change Captioning. In Proceedings of the IEEE International Conference on Computer Vision, pages 4624–4633,
2019.

해당 연구에도 적용해서 성능향상이 나타나는지 확인했다고 합니다. (잘 얼라인 맞추면 change captions이 바뀐게 없다고 하길 원했던거 같습니다.)

그리고 해당 모델이 ‘the scene remains the same‘이라고 나타냈다고 합니다! O_O 해당 실험에 대한 다른 정량적 결과도 나타내고 있는데, 그 부분은 더 궁금하시면 찾아보시길 바랍니다.
잘 이해할 수 있고, 논문의 내용도 재밌고 논문읽는데 시간이 금방 흘러갔던 좋은 논문인거 같습니다. 해당 논문은 Workshop 논문인데, 직접적인 기여도가 많지는 않지만 그래도 다양한 분야에서 잘 작성된 논문이라고 생각합니다. 해당 논문을 읽으며 내일부터 실험해볼 내용은 해당 모델을 이용하여 RGB-Thermal의 H matrix를 계산하는데 여기에 RGB, Thermal은 Domain Gap이 존재하기 때문에 여기에 DA를 적용하면 어떨까 생각합니다. 다행히도 해당 논문의 저자가 코드도 잘 공개하고 있어 빠르게 확인해볼 수 있을 것 같습니다.
코드 : https://github.com/NeurAI-Lab/biHomE
발표영상 : https://www.youtube.com/watch?v=X6aRM2ctxXI
재밌는 리뷰 감사합니다. 개념 자체가 self-supervised depth 또는 optical flow랑 방향이 비슷해서 재미있게 읽었네요.
한가지 궁금점이 있는데, 본 리뷰 내용 중 “문제점이 한가지 있는데, feature level에서 비교하다보니까 또 뷰포인트가 큰 영상들에 대해서는 H matrix를 잘 못구하는 한계가 존재했다고 합니다.” 라는 부분에서 뷰 포인트가 크다 라는 의미는 무엇인가요? 지난번에 한번 구두로 말씀해주신 것 같은데 기억이 가물가물치 하네요.
뷰포인트 차이가 큰 영상의 피처레벨에서 비교하게 되면 두 영상의 피처가 크게 달라져 피처레벨에서 비교하는 것이 어렵다는 의미입니다