안녕하세요 비디오 검색 관련 논문 읽기… 두번째 논문으로 ActivityNet을 들고 왔습니다! 제목 그대로, ActivityNet 은 인간의 행동의 이해를 위한 대규모 비디오 벤치마크 입니다. 벤치마크라는 말을 자주 들어봤지만 의미를 정확히는 몰라 찾아보니 ‘기준이라고 받아들여지는 것과 비교하여 어떤 것의 품질을 측정하는 작업’ 이라고 하네요. 컴퓨터비전 쪽에서는 벤치마크는 Classification 등의 task 에 대해, 어떤 모델의 성능을 측정하는 기준을 정해주는 것이라고 생각하면 될 것 같습니다. 리뷰 시작하도록 하겠습니다.
비디오 관련 데이터가 점점 늘어남에도 불구하고, 비디오에 나오는 human activity 를 자동적으로 이해하는 것에는 어려웠습니다. 그 당시의 action 관련 컴퓨터 비전 알고리즘은 action 의 가변성과 복잡성 측면에서 심각하게 제한적이었다고 해요. 벤치마크도 단순하고, untrimmed video 가 아닌 manually trimmed videos 의 간단한 동작과 움직임에 초점을 맞추고 있었고, 커버할 수 있는 activity types 도 한정되어 있고, 데이터 셋의 카테고리 수나 샘플의 수도 적었대요. 이러한 배경에서 human activity understanding 을 위한 새로운 벤치마크, ActivityNet 이 등장했습니다.
ActivityNet 의 가장 중요한 점은 의미 존재론(semantic ontology)에 따라 구성됐다는 것입니다. 즉, 카테고리 별 activity 를 대해 나눌 때 사회적 상호작용과, 해당 액션이 주로 어떤 장소에 일어나는 지를 고려하여 구성됐다고 합니다. (실제로 카테고리마다 살펴보니, Housework 같은 경우는 주로 혼자 실내에서, Sports 같은 경우는 주로 여럿이 실외에서 하는 행동들로 구성되었습니다.) 이 당시 존재했던, 카테고리의 수가 적거나 특정 카테고리(ex. Sports)의 action 만 있거나, 샘플의 길이가 짧거나 샘플의 수가 적은 다른 dataset 과는 다르게, ActivityNet dataset 은 사람들이 보통 일상 생활에서 행하는 행동들에 관련이 있었고, 충분히 대규모였고, 심지어 각 activity 을 4가지 granuality level 에 따라 분류한다는 특징도 있었습니다.
Building ActivityNet
ActivityNet 이 어떤 방식으로 구축되었는지, 간단히 설명해보도록 하겠습니다. 우선 ActivityNet 은 인간의 행동이 나오는 비디오들을 의미 있는 형태로 조직하는 것을 목표로 합니다. 따라서, 이 과정을 통해 여러 행동 카데고리들(label)에 대한 비디오(video) 샘플들을 데이터셋으로 제공하려 합니다.
- 단어 사전 정의
ActivityNet 이 나오기 전에, ATUS taxonomy 가 a) 사회적 상호작용, b) 행동이 주로 일어나는 장소, 이렇게 두 가지 기준따라 2000개 이상의 activity class 를 정의했었습니다. 이는 총 3개의 granulairty level 로 구성되었고, 가장 최상위에는 총 18개의 카테고리가 있었습니다.
ActivityNet 의 첫 릴리즈 때, 이 ATUS 의 activity 계층 구조에서 수작업으로 203개의 activity class 를 선택했습니다. 또한 아래의 이미지에 나온 바와 같이 가장 최상위에 7개의 카테고리를 뒀고, 총 4개의 granularity level 로 만들었습니다.
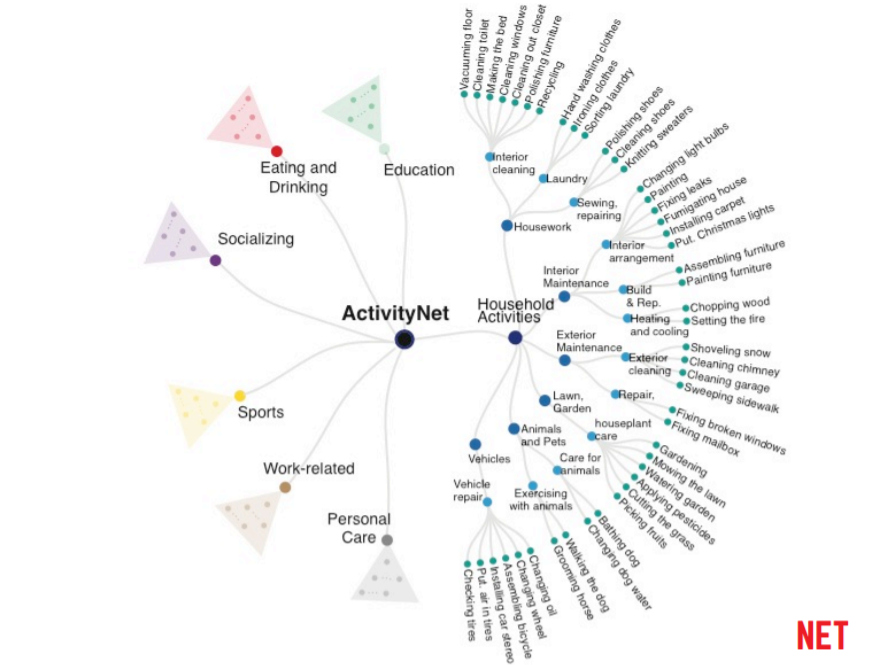
2. 데이터 수집 및 라벨링
Visual recognition 과 관련된 벤치마크 데이터셋을 만드는 것은 시간적, 금적적 자원이 많이 소비되는 일이었습니다. 하지만 ActivityNet 의 목표는 적은 비용으로 대규모 데이터셋을 만드는 것이었기 때문에, 반-자동적인 크라우드소싱 전략으로 데이터를 수집하고 라벨링했습니다.
우선, 유튜브 등의 비디오 저장소에 텍스트 기반 쿼리를 던져서 관련 영상 데이터를 수집했습니다. 이때 각 activity class 를 검색했고, ‘WordNet’ 이라는 어휘 사전에 따라 상위 단어/하위 단어/유의어도 검색을 해서 컨텐츠의 다양성을 키우고, 비디오의 수도 늘렸습니다.
검색해서 얻은 비디오 중 해당 activity 가 포함되지 않은 경우가 있을 수도 있기 때문에, 이를 걸러내는 작업을 한 번 했습니다. ‘Amazon Mechanical Turk (AMT)’ 라는 웹사이트를 이용했고, 질문을 통해 전문가만을 모집해서, 해당 비디오에 미리 정의했던 activity 에 대한 최소 한 개 이상의 ground truth label 을 붙일 수 있는 비디오만 남기고 다른 건 제거했습니다.
그 당시 activity classification 시스템은 학습 데이터로 trimmed video 를 넣는 게 관례였다고 합니다. 그렇지만 웹 상에 올라오는 실제 영상들은 한 가지 activity 만으로 이루어진 경우가 극히 드물었습니다. 어떤 영상이 있으면 그 영상에 해당 activity (또는 여러 개의 activity)가 포함된 부분이 일부 있는 것이죠. 그렇기에, ActivityNet 은 어떤 영상에서 activity 가 있는 부분의 시작과 끝, 즉 action instance 의 시간적인 경계를 annotation 했습니다. 그 후에, robust 한 결과를 얻기 위해 그 분들의 annotation 을 cluster 해서, 엄선된 결과를 얻었습니다. 여기서 중요한 점은, 한 영상에 대해 두 개 이상의 instance 가 있을 수도 있고, action category 또한 두 개 이상일 수도 있다는 점입니다. 실제 영상처럼요!
Video Properties
- duration : 평균 5분 ~ 10분 (용량 때문에 최대한 20분 이하의 비디오들만 모았음)
- resolution : 50% 이상이 HD (1280×720), (가능한 가장 좋은 화질로 받았음)
- FPS : 대부분이 30 FPS (이거 예전에 annotation 할 때 왜 30으로 받아왔나 했었는데 이걸 보고 알게 됐음…!)
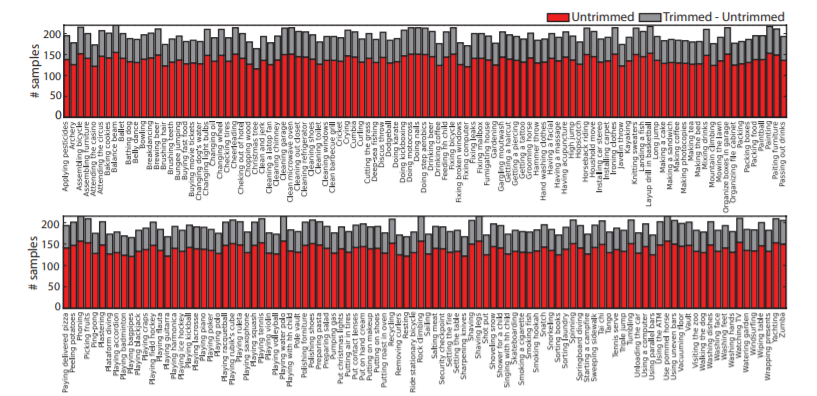
아래 이미지는 untrimmed 비디오와, trimmed 비디오에 대한 클래스 당 activity instance 갯수를 보여줍니다. 이 분포가 고른 편이기 때문에, data imbalance 문제를 피할 수 있다는 장점이 있다고 합니다.
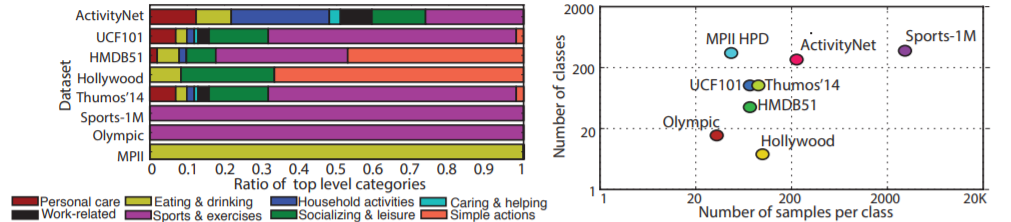
아래 이미지는 다른 데이터셋들과 ActivityNet을 비교한 것인데, 보다시피 카테고리의 분포, 카테고리의 수나, 클래스 당 샘플 수 측면에서 AcitivtyNet이 다른 데이터셋이 우수함을 알 수 있었습니다. 이때 Sports-1M 같은 경우는 정말 Sports와 관련된 데이터셋이기 때문에, 인간의 행동을 이해하기 위해서는 ActivityNet 이 더 유리합니다.
Evaluation
ActivityNet 이 evaluation 할 때 사용되는 벤치마크 시나리오는 총 3개 입니다. 그 전에, 이 시나리오들에 적용되는 video representation 이 어떻게 만들어졌는지 먼저 짚고 넘어가겠습니다. 해당 논문에서는 3가지의 features 를 결합하여 video representation 을 만드는 방식으로 성능을 올렸습니다.
Video Representation
Motion Features (MF) :
- 목적 : 비디오의 local motion patterns 를 포착하는 것
- 방법 : improved trajectories 를 추출해서, (Action recognition with improved trajectoreis 의 방법론을 따름)
a set of local descriptors (ex. HOG, HOF) 를 얻은 후,
Fisher Vector 를 이용하여 해당 descriptors 를 encode 함. - 이때 512 개의 components 를 가진 Gausian Mixture Model (GMM) 와 FV 로 encode 됐고,
PCA 를 이용하여 차원 수를 절반으로 줄였음.
Static Featrues (SF) :
- 목적 : contextual scene information 을 포착하는 것 (human activities 를 구분하는 데 도움이 됨)
- 방법 : 10 프레임마다 SIFT feature 를 뽑아서 정보를 포착하고,
1024 개의 components 를 가진 GMM 와 FV 로 encode 됐고,
PCA 를 이용해서 48차원으로 줄였음. 그리고 모든 descriptors 를 하나의 FV 로 합쳤음.
Deep Featrues (DF) :
- 목적 : scene 에 있는 object 에 대한 information 을 encode 하는 것
- 방법 : object recognition 문제를 위해 학습된 CNN 이 뽑은 features 를 사용했다. 이때 ILSVRC-2012 라는 데이터셋으로 학습된, AlexNet 구조를 이용하였다고 한다. 10개 프레임 씩 deep features 를 뽑아서, 그걸 평균 내어 사용했다고 한다.
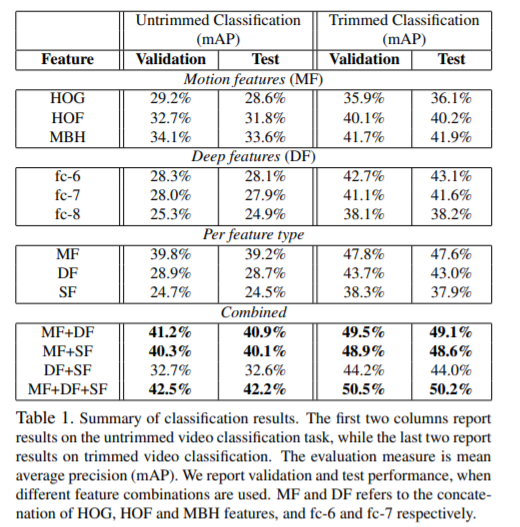
아래 이미지를 보면 알 수 있듯이, 여러 개의 features 를 합치는 것이 전체적인 성능 향상을 이끌었다고 합니다. 특히, 가장 좋은 DF 는 fc-6, fc-7 의 activations 를 concat 한 경우라는 게 실험적으로 밝혀졌습니다.
ActivityNet Benchmarks
해당 벤치마크는 총 3가지 시나리오를 포함하고 있다.
- Untrimmed video classification
- Dataset : 총 27801 videos, 203 activity classes (train 2 : validation 1 : test 1)
- Classifiers : linear SVM
- Results : mAP 기준으로 측정
- Trimmed activity classification (비디오마다 하나의 activity instance)
- Dataset : 203 activity classes, 평균적으로 클래스 당 193 개의 samples. (같은 비디오에서 나온 instance 는 같은 set 으로 split 함)
- Classifiers : 각 feature type 마다 linear classifer 한 개씩-> multiple features 를 combine 할 때, 단순히 sum 구함. -> 가장 높은 score 를 가진 class 선택.
- Results : 모든 클래스에 대한 mAP 기준으로 측정,
- Activity detection (untrimmed videos)
- Dataset : 849 hours of video, 203 activity classes (train 2 : validation 1 : test 1)
- Classifiers : linear SVM (+ sliding temporal window, non-maximum supppression)
- Results : 모든 클래스에 대한 mAP 기준으로 측정 ( 예측 segment 와 gt 의 overlap 을 계산하여, threshold (알파) 값을 넘기면 positive 라고 표시함, 이떄 알파는 0.1~0.5)
Discussions
Cross-dataset 해서 성능을 비교해보았을 때, ActivityNet 이 mAP 가 비교적 낮습니다.
그 당시 sota 메소드들을 이용했을 때인데, 보시다시피 ActivityNet 이 다른 벤치마크에 비해서 어려운 Challenge 임을 알 수 있었습니다. 그 이유는, a) category 의 수가 많아졌고, b) 비디오의 다양성이 커졌기 때문이라고 합니다. 이때 알파 값은 action detection 할 때 예측된 temporal segement 와 ground truth segment의 overlap 의 threshold 값입니다. overlap 이 이 값을 넘으면 positive 라고 판단합니다.

Conclusions
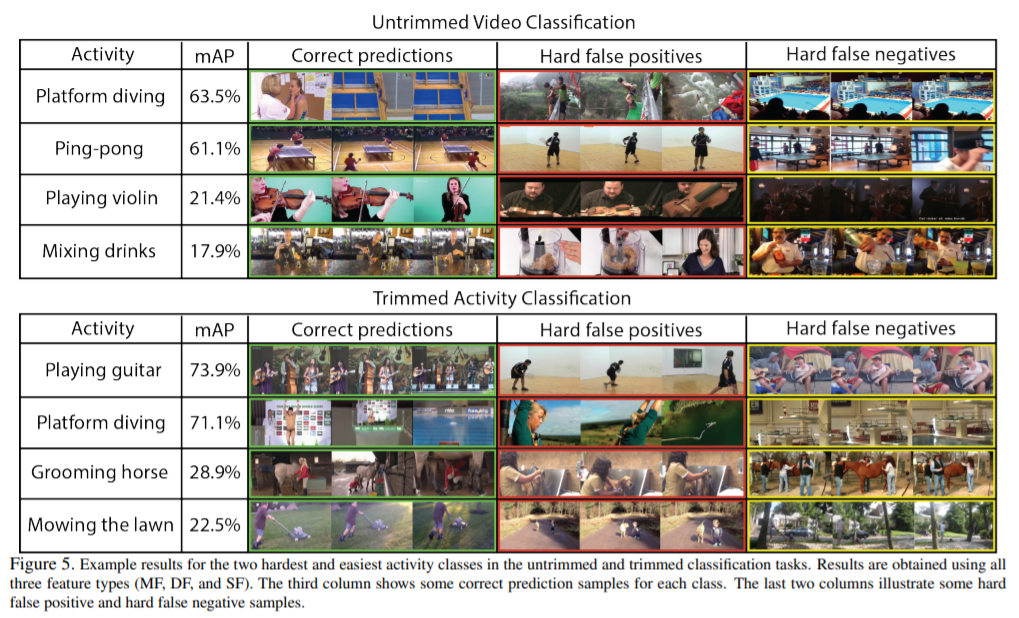
마지막으로 ActivityNet 의 Classification 예시 한 번 보면서 마무리하겠습니다.
mAP 를 보면 알 수 있듯이, classification 할 때, 가장 어려운 activity class 2개, 가장 쉬운 activity class 2개라고 합니다.
ActivityNet 의 공식 사이트는 http://activity-net.org/ 인데, 들어가면 Annotation 을 다운로드할 수 있도록 공개되어 있습니다. 비디오 데이터는 관련 깃허브 레포를 타고 가서 보니까, downloader 프로그램을 따로 사용해서 받는 듯 합니다. 이 논문이 2015년에 나왔고 얼마 전까지 ActivityNet Challenge 이 매년 진행된 만큼, 아무래도 우리가 사람이니까, 사람의 행동에 대한 이해를 더 잘 하기 위한 연구가 계속되고 있는 상황인 것 같습니다. ActivityNet 의 데이터가 무엇을 위해 어떻게 모아졌고, 카테고리 / 클래스가 어떤 방법을 통해 분류되어 있는 지를 알 수 있어 의미 있었던 리뷰였습니다.
올해도 ActivityNet 챌린지가 열리는 것으로 알고 있는데, 참가하실 예정이신가요?