안녕하세요. 갑자기 왜 감정인식 논문을 들고 왔는가 하면… 과제때 쓸 베이스라인 논문으로 삼을 것 같아서 이 논문을 읽었습니다. 제가 골라서 읽은 논문은 아니고, 비디오 검색 과제 세미나에서 다른 연구실에서 진행한 논문이었는데 이게 큰 도움이 되었습니다.
아무튼, 이 “emotion recognition”은 VAT(Visual, Audio, Text)와 같은 데이터를 통해 감정을 예측하는 task입니다. 보통은 특정 감정(sad, happy 등등)을 예측합니다만, 수치화된 감정도 예측할 수 있습니다.
Introduction

멀티 모달 감정인식에서의 중요한 부분은 서로 다른 모달리티들을 어떻게 통합하느냐입니다. 일단 기존의 방법론들은 2-stage로 학습을 진행합니다. 주어진 데이터를 기계학습적인 방법론으로 feature를 뽑고, 이 feature를 학습하는 과정을 거칩니다. 여기에는 다음과 같은 문제가 있습니다.
- feature extraction을 거친 값이 고정되서 fine-tuning 불가능
- 매번 타겟이 달라질때마다 적절한 feature extraction 알고리즘을 찾아야함
- Hand-crafted model은 고차원 feature 표현력이 적어 유의미한 정보를 포함하지 못해 최적 성능을 낼 수 없을지도 모름
그래서 저자는 (데이터셋 preprocessing을 한번은 해줘야 학습이 가능하지만, 어쨋든 학습은 한번에 할 수 있는) fully end-to-end model을 제안합니다. 이 모델은 결국 이러한 feature extraction 과정이 없으므로 좀 더 유기적인 학습이 가능하다고 말합니다.
저자가 주장하는 contribution은 아래와 같습니다.
- 최초로 end-to-end 모델을 멀티모달 감정 인식에 적용
- 기존의 데이터셋을 재구성해서, end-to-end 모델에서 학습 가능하게 수정
- SOTA
Dataset Reorganization
서론에서 데이터셋을 preprocessing을 해줘야 한다고 말씀드렸는데요. 이건 기존의 데이터셋들이 fully end-to-end 모델 구조에서 학습할 수 없기 때문이 필요하다고 합니다. 근데 왜 그럴까요?
- 기존의 데이터셋들은 train/val/test로 분할되어 있는 hand-crafted feature를 제공하고 있습니다. 그런데 분할된 데이터셋을 원본 데이터와 매핑시킬 수 없다고 합니다.
- 시각 정보와 오디오 정보는 텍스트 정보와 정렬되어 있지 않은 반면에, 데이터의 라벨이 text 정보 기준으로 정렬되어 있다고 합니다.
그래서 이러한 문제를 해결하기 위해, 3개의 모달리티를 정렬하고, 정렬된 데이터로 다시 train / val / test를 분할해주는데, “랜덤”으로 분할합니다. 여기서 드는 의문은… 왜 굳이 랜덤으로 새로 데이터셋을 분할해주는지 의문이 들지만… 이유는 알수 없었습니다.
(기존의 분류는 왜 날리는지 비교해보고 싶지만, 서류를 작성해서 요청을 보내야 심사를 거쳐 데이터셋을 제공해주고 있어서… 받아서 확인해보기가 어렵네요.)
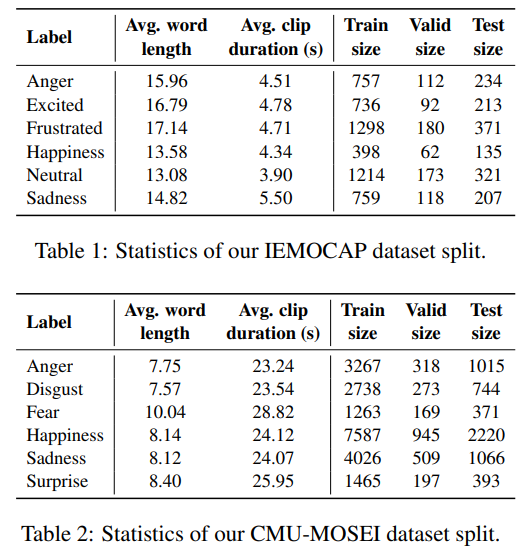
아무튼 새로운 데이터셋 분류는 위와 같다고 합니다. 짧은 문장을 기준으로 하나의 학습 셋이 만들어져있는 것을 확인할 수 있습니다. 문제는 데이터셋이 심각하게 부족한 감정들이 몇가지 있었는데요, 이런 감정은 학습에서 제외했다고 합니다.
Methodology
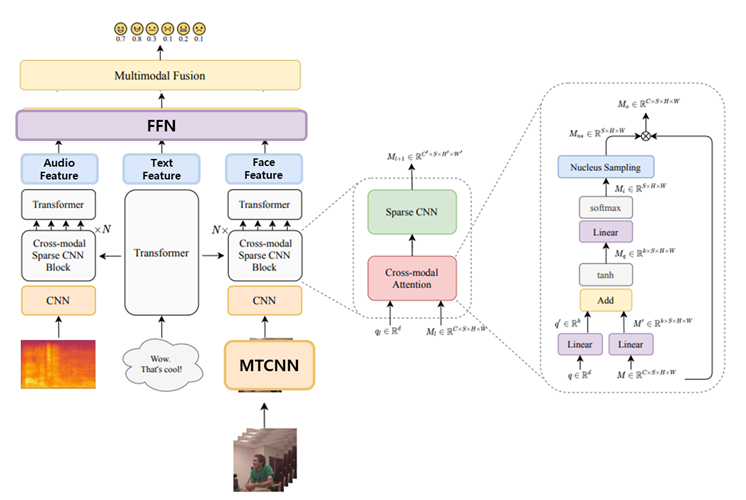
논문의 원본 그림이 있었는데요. 코드랑 같이 읽어보니 아무리 생각해도 살짝 바꿔야할 것 같아서 좀 바꿨습니다. 일단 딱 봐서 모를법한 블록만 간단하게 요약하면, MTCNN은 인간의 얼굴에서 visual feature를 뽑을때 사용하는 CNN 입니다. 그냥 CNN은 여기서는 VGG를 사용했고요. 텍스트 데이터로 부터 뽑아진 feature는 오디오와 비디오 feature를 뽑을 때 사용하는 cross-modal attention에서 사용합니다. 그리고 개별 feature들은 FFN(Linear layer)를 통해 감정이 예측되는 구조입니다.
Multimodal End-to-End Sparse Model
End-to-end 모델은 장점만 있는게 아닙니다. 추가적인 연산량을 고려할 수 밖에 없죠. 이러한 문제를 해결하기 위해 이 논문에서는 Sparse CNN이라는 것을 사용합니다. 위 그림에서 “Cross-modal Sparse CNN Block”이라고 적혀있는 부분에서 사용되는 대부분의 CNN을 이 Sparse CNN으로 대체했습니다.
Cross-modal Attention layer
아까 모델 간단 설명에서 text feature는 “cross-modal attention”에서 사용한다고 말씀드렸는데요.
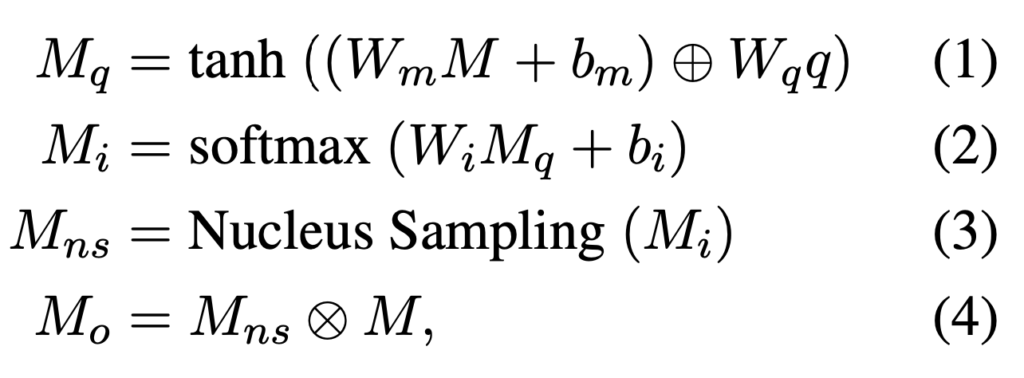
위의 수식과 같은 연산을 거치는 레이어입니다. Q는 텍스트 데이터를 transformer에 넣고 나온 feature 값입니다. M은 오디오 데이터가 VGG를 거친 feature거나, 비디오 데이터가 VGG를 거친 feature입니다.
1번과 2번 연산을 거치면 각 feature map의 attention scores가 계산됩니다. 그리고 Nucleus Sampling을 사용하는데요. 어디서 등장하는지 알아보니 자연어 처리에서 사용하는 샘플링 방식이더라고요. 그래서 원래는 단어의 확률을 계산하지만 여기는 단어가 없죠? 그래서 attention score map의 미리 정의된 p값을 바탕으로 top-p 영역을 얻고, 1로 설정하고 나머지 영역은 0으로 설정합니다.
이런 과정을 “cross-modal attention”이라고 부르고, 최종적으로는 텍스트 데이터를 기반으로, 오디오 데이터와 비디오 데이터의 sparse한 tensor를 얻는 연산임을 알 수 있습니다.
Sparse CNN
또 생소한 CNN이 등장했습니다. cross-modal attention 이후에 등장하는데요. 이는 멀티 모달 감정인식에서는 일부 값만이 감정 정보와 연관이 있다는 가정에서 적용한 연산입니다. 사람의 얼굴을 생각해보면 감정 인식에 영향을 크게 미치는 부분은 눈과 입이 가장 큰 영향을 미치겠죠? 그럼 그 부분을 어떻게 뽑았냐고요? 이미 의미 없는 영역을 0으로 채워왔습니다. 바로 cross-modal attention을 통해서요. 활성화된 값만 있는 과정에서 convolution 연산이 수행되므로, 연산량도 낮출 수 있다고 합니다.

시각화 결과만 보면 최종적으로는 빨간색으로 찍혀있는 점을 기준으로 Convolution 연산이 수행될것이라서 눈, 코, 입 등에서 feature를 뽑는 것을 볼 수 있습니다.
Evaluation Metrics
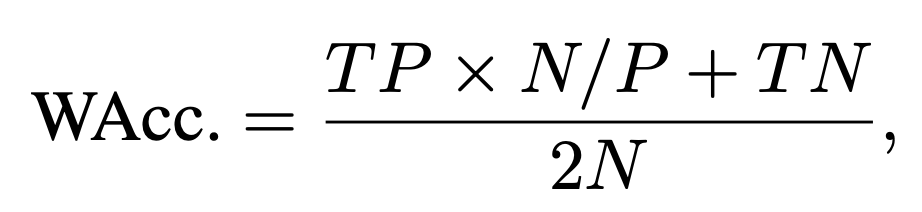
여기서는 WAcc.라는 정확도를 사용합니다. 감정 인식 데이터셋에서 긍정 감정과 부정 감정의 갯수 차이가 발생하는데, 그냥 정확도를 사용하게 되면 부정 감정으로 예측하면 성능이 좋게 나오는 착시현상이 생긴다고 합니다. (논문을 둘러본 결과, 그래도 Accuracy를 가장 많이 사용하고, F1 score와 CCC라는 평가 메트릭을 많이 사용합니다.)
Expreiments
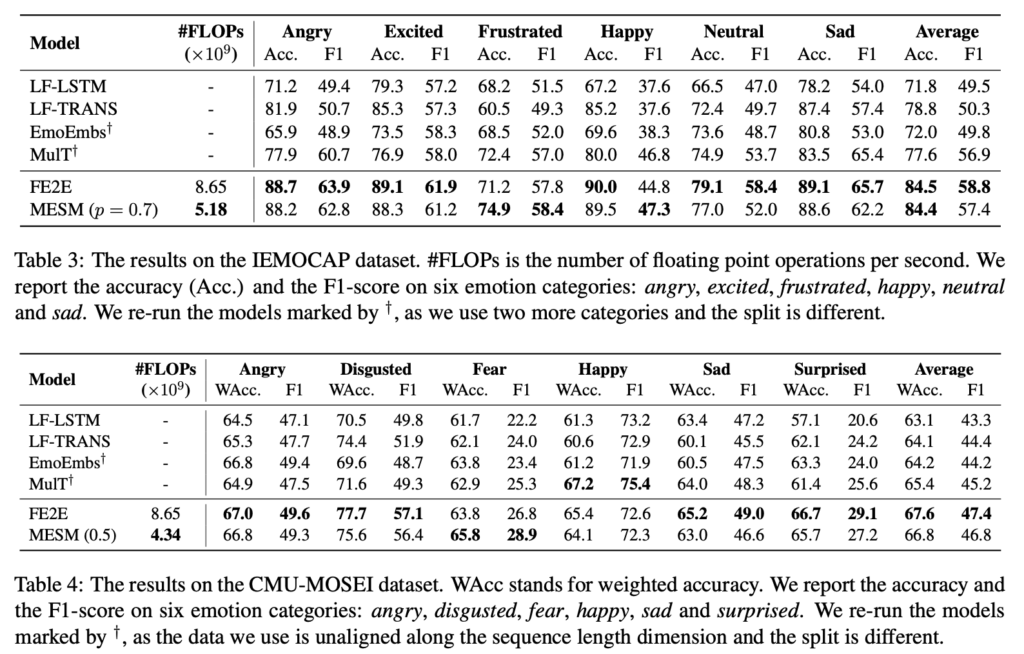
꽤나 준수한 성능을 보이는 것을 알 수 있습니다. MESM과 FE2E 두가지가 이 논문 저자들이 제안한 모델인데요. MESM은 Multomodal End-to-End Sparse Model이고, FE2E는 Fully end-to-end 모델입니다. 차이점은 이름에서도 나와있지만 attention mechanism을 기반으로한 Sparse CNN 연산의 적용 유무의 차이입니다.
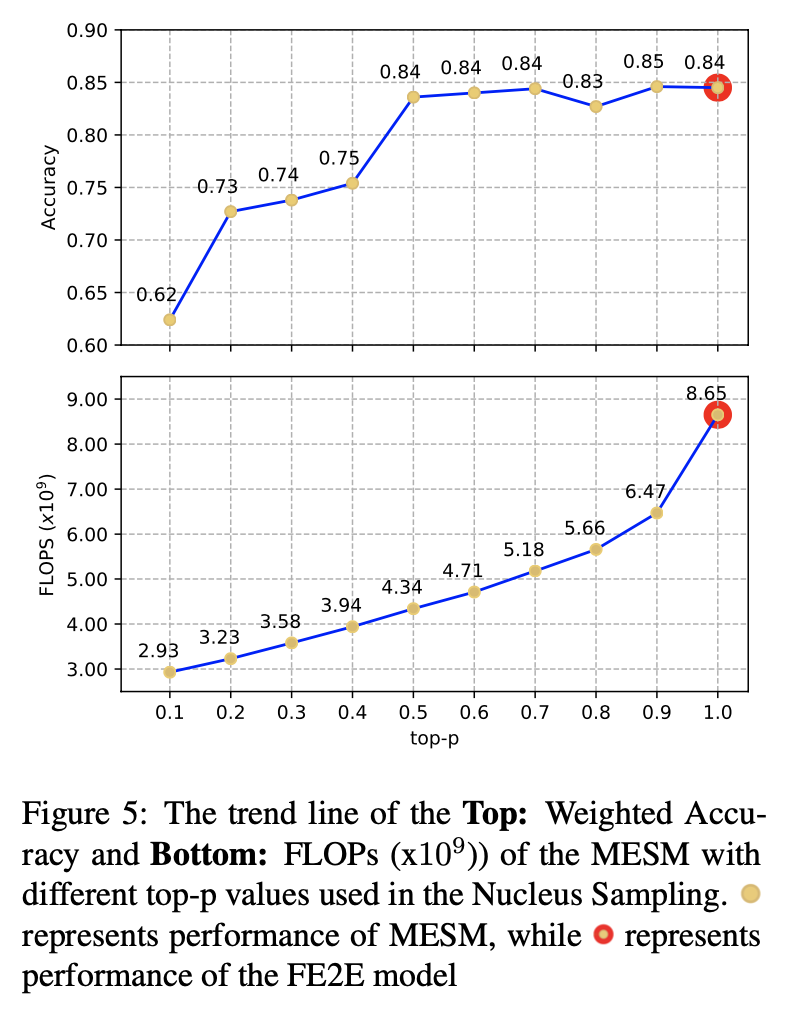
이건 attention layer에서 사용하는 Necleus Sampling의 top-p값에 따른 정확도와 FLOPS 비교입니다. FE2E 모델 대비 절반의 연산량으로도 비슷한 정확도를 가지는 것에서 실제로 이 저자들이 주장하는 모델이 작동함을 보입니다.
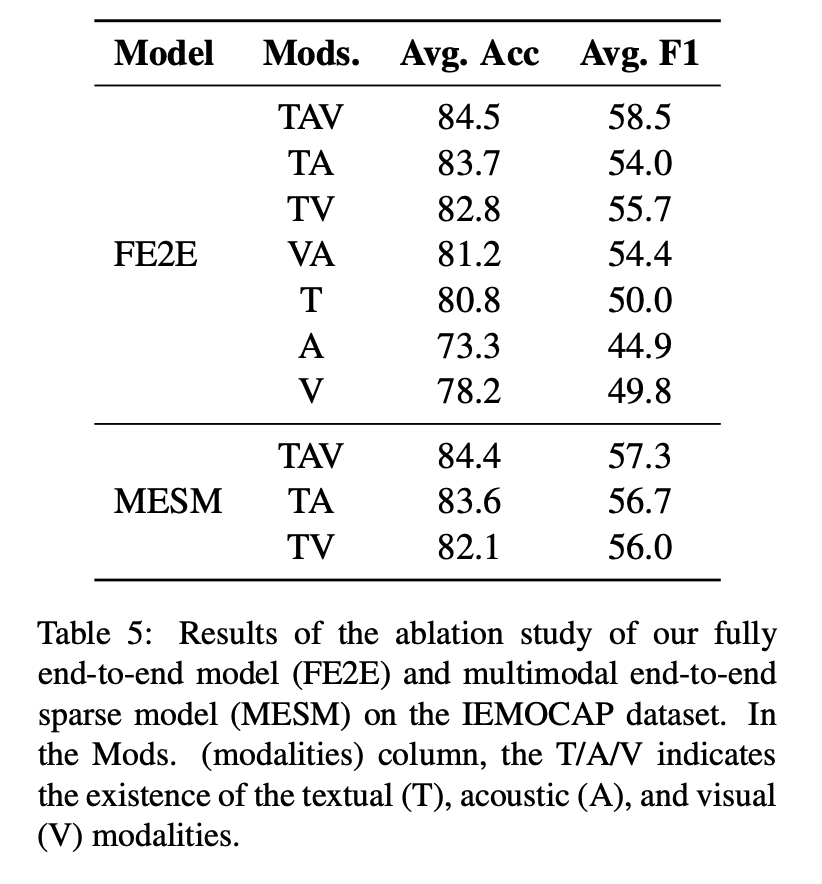
또, 다양한 데이터 중에서 어떤 데이터가 감정인식에 가장 큰 영향을 미치는지에 대한 ablation study가 있습니다. 여러 모달리티를 결합한 실험 결과를 보면, 텍스트 데이터의 영향력이 큰 것을 확인할 수 있습니다.
Conclusion
코드도 익숙한 pytorch로 깔끔하게 정리되어 있어, 이해하기는 매우 쉬운 논문이었습니다. 다만 기존의 존재하는 데이터셋을 이렇게 재구성 해서 쓰기도 하나 싶은 부분도 있고, 이게 맞나 싶은 부분들이 있기는 했지만 전반적으로 감정인식 과제의 베이스라인 삼기에는 적절한 논문이었던 것 같습니다. 다음 리뷰부터는 다시 비디오로 돌아오겠습니다.
논문의 핵심은 결국 서로 다른 modalit 로부터 정보를 어떻게 추출할 것인가 이게 중요한 포인트 일 것 같은데, Cross-modal Attention layer 에서 서로 다른 modality에 대한 attention을 통해 feature representation을 하는 것 같습니다.
그래서 사실 제일 중요하고, 설명이 많아야할 것 같은데 논문의 설명은 리뷰에 적힌게 다인가요? 좀 더 자세한 설명이나 분석이 필요해 보입니다.
그리고 마지막 각 modality끼리 Linear Layer를 거치고 modality fusion을 진행한다고 하는 데 이는 어떻게 진행되는 거죠??
그리고 또 하나 질문 드리면 Video data 가장 처음에 feature 뽑을 때 사용하는게 2D CNN인가요??
논문에서도 이정도로 요약해서 다루고 있어서 딱히 모달리티의 정보 추출 부분에서 설명을 빼먹은 부분은 없는 것 같습니다. 논문에서도 그런 부분들은 다른 구현체를 가져다가 쓰고있어서 딱히 힘을 준 부분같지는 않고요. 데이터셋을 잘 재구성해서 최초로 end-to-end 구조를 만들었다는 것에 중점을 두고 있는 것 같습니다. 물론 그 과정에서 연산량을 줄이기 위한 기법으로 attention->SparseCNN을 사용하고 있고요. 이건 F2E2의 성능이 MESM랑 차이가 나지 않는 것을 보면, 물론 적은 부분만 보고도 성능이 유지되었으니 표현력이 좋아졌다고 봐야겠지만, 개인적으로는 좀 미묘하다고 생각합니다.
그리고 fusion은 Linear 레이어 하나를 통과하는게 끝입니다. 그림을 그래서 고쳤는데, 설명이 부족했네요. 마지막으로 Video data는 말이 비디오 데이터지… 그냥 이미지들의 시퀀스로 쓰는거라 3D CNN을 써서 맥락 정보를 읽고 그런 부분은 없습니다. 서베이 하면서 Video 데이터만 사용하는 경우에는 앞뒤 정보를 반영하는걸 본 것 같은데, 멀티모달쪽에서는 못 본 것 같네요.
안녕하세요 좋은 리뷰 감사합니다
해당 논문에서 적용해야하는 preprocessing 과정은 어떻게 되나요?
일단 논문에서는 “Dataset Reorganization”이라고 표현을 하는데요.
이 task에서 사용하는 데이터셋들이 꽤 오래전에 나온 데이터셋(논문에서 쓰는 데이터셋은 2008년에 공개)들이 많습니다. 그래서 feature들이 이미 hand-crafted feature로 가공되어져서 나오는 경우가 있습니다. 논문 저자는 이렇게 되면, 데이터에 대한 학습을 할 수 없기 때문에 이러한 데이터들을 전부 raw 데이터 기준으로 다시 재구성하고, 이를 적절한 단위(여기서는 감정이 표현 만큼)로 나누어주었다고 합니다. 그리고misalignment 문제나, 데이터 missing 문제도 이 과정에서 확인해서 전부 지워주었다고 합니다.
안녕하세요 좋은 리뷰 감사합니다. 리뷰를 읽다가 몇 가지 궁금한 점이 생겨 질문드립니다.
– 멀티모달에서는 서로 다른 데이터를 통합하는 것이 중요하다고 했는데 이 논문에서는 그걸 어떻게 이루는지
– 그림에서는 비디오와 텍스트는 raw, 오디오는 전처리를 해준 것으로 보이는데 음성은 어떤 feature를 뽑은 건지 궁금합니다.
– Cross modal attention으로 비디오에서 감정에 영항을 미치는 부분을 뽑는다고 하셨는데 이게 어떻게 이루어지는지 설명해 주실 수 있으실까요?
1. 데이터를 통합하는 것은 결국은 embedding을 어떻게 학습하느냐인데요. 사실 이 부분은 감정인식 제안서 작성하면서도 근거가 있으면 좀 찾아보려고 했는데 마땅한 근거를 찾지는 못했습니다. 트랜스포머 자체가 그렇게 학습할 수 있다 정도로 논문에서 정리하고 있었던 것으로 기억하고요. 다만, 대략적인 매커니즘을 이해하고 싶으시다면 CLIP 논문 정리해둔 유튜브 영상 하나정도 보시면 이해할 수 있을겁니다.
2. mel-spectrogram 씁니다. 그리고 텍스트도 raw로 사용하지 않습니다. 토크나이징 해서 사용합니다.
3. Attention에 대한 내용은 Transformer를 아셔야해서… 나중에 트랜스포머 논문을 보신 이후에도 모르시겠다면 그때 또 설명드리겠습니다.