이번에 리뷰할 논문은 Image to Image Translation(I2IT)입니다 근데 이제 Domain Adaptation(DA)를 곁들인. 논문의 제목을 보시면 대충 감이 잡히시지 않을까싶은데 해당 논문에서 하고자 하는 것은 Unpaired I2IT에서 source 영상의 content가 왜곡되는 현상을 DA를 이용해 해결하려는 논문입니다.
그럼 리뷰 시작합니다.
Abstract&Intro
비전을 전문으로 하는 사람은 아니더라도 이름은 한번쯤 들어본 CycleGAN은 Unpaired I2IT의 가장 대표적인 방법론 중 하나입니다. 사실 방법론 자체는 I2IT 분야에 큰 초점을 맞추고 제안된 방법론인 것 같은데, 제가 최근에 DA 논문들을 읽어보려고 훑어보니 I2IT 분야보다는 DA 분야에서 CycleGAN을 더 많이 참조하는 것 같더군요.
아무튼 Unpaired가 무엇이냐에 대해서는 예전의 제 리뷰나 세미나에서 반복적으로 설명드렸지만 혹시나 해서 이번에도 간략하게 설명하고 넘어가겠습니다.
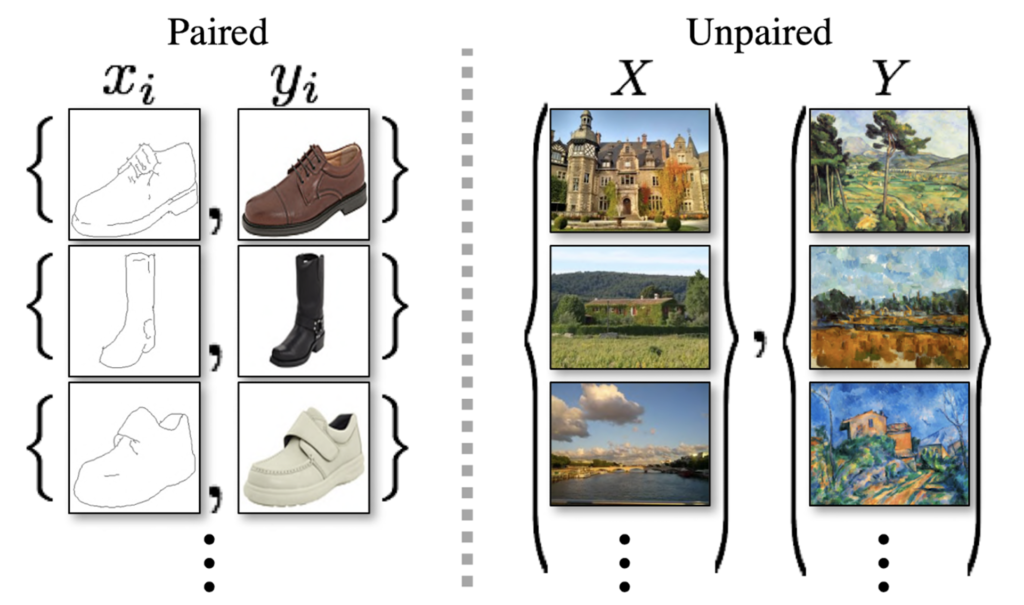
그림1의 좌측은 paired dataset을, 우측은 unpaired dataset의 예시를 의미합니다. 한눈에 봐도 어떤 느낌인지 아실 듯 한데, 저희가 변환시키고자 하는 source image(x)와 변환하려는 target image(y)가 컬러, 텍스쳐와 같은 style을 다르지만, 엣지와 구조 같은 content는 동일한 것을 paired dataset이라고 합니다. unpaired 데이터 셋은 반대로 style 뿐만 아니라 content도 다른 영상을 의미하겠죠.
즉 Unpaired 데이터 셋으로 I2IT를 한다는 것은 매우 어려운 문제를 푸는 것이나 다름이 없습니다. 그나마 Paired 데이터 셋이 Unpaired에 비하면 훨씬 풀기 쉬운 문제이긴 하지만, 사실 paired 데이터 셋은 구하기가 생각보다 많이 힘듭니다. 예를 들어 그림1 우측 예시에서 실제 사진을 화가의 그림풍으로 변경하고 싶다고 할 때 실제 사진과 동일한 장면을 그림 화가의 작품이 없으면 paried dataset을 이용하는 translation 방법론으로는 변환을 시킬 수 없기 때문이죠.
그래서 CycleGAN은 그림2와 같은 사이클한 구조를 통하여 영상을 변환시킵니다.
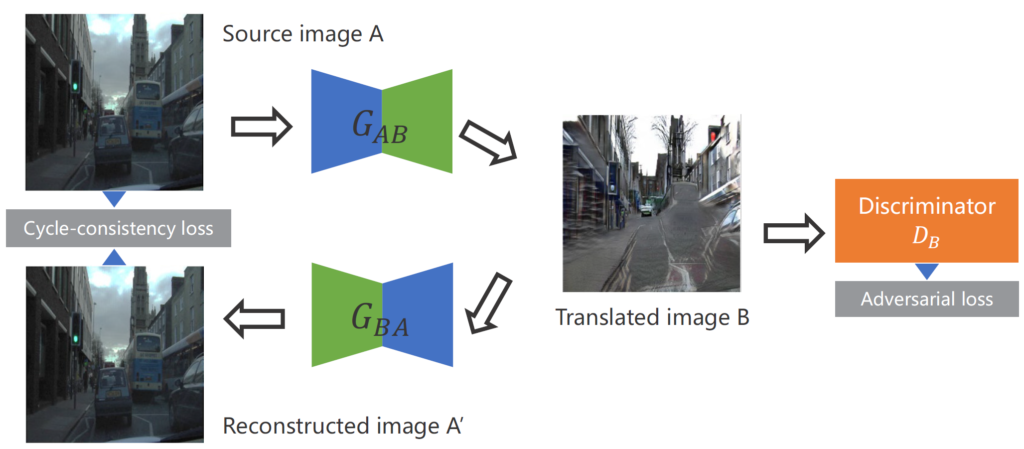
그림2의 예시를 보자면 칙칙한 흐린 날씨의 영상(cloud)을 domain A라고 보고 화창한 날씨의 영상(sunny)를 domain B라고 보았을 때, A도메인의 영상을 B 도메인으로 변환시키는 G_{AB}가 translated image를 생성하게 됩니다. 이렇게 생성된 가짜 sunny image는 discriminator의 입력으로 통과하여 real domain B image와의 구분을 헷갈리게 만들도록 학습을 합니다.
반면 이렇게 Adversarial loss만을 사용하게 되면 생성된 영상이 원래의 흐린 영상(domain A)의 컨텐츠는 유지하지 않은 체, 무작정 화창하게만 만들 수 있으니 content에 대하여 loss를 계산하도록 해주어야 합니다.
그래서 CycleGAN은 화창한 날씨의 영상을 흐린 날씨의 영상으로 변환시켜주는 G_{BA}에 새로 태워서 다시 흐린 날씨의 영상을 재생성하게 됩니다. 이렇게 재생성된 영상과 원래의 입력 영상(domain A)를 직접적으로 비교함으로써 content를 유지하도록 합니다.
이러한 방식을 통해, CycleGAN은 unpaired dataset에 대해서도 어느정도 잘 변환된 결과를 보여주게 됩니다. 하지만 기존의 paired dataset을 사용하는 I2IT 방법론에서도 생성된 결과의 content가 잘 유지되지 못하는 경우가 종종 일어나기 때문에, 이보다 더 어려운 문제에 속하는 Unpaired dataset은 왜곡된 결과를 더 자주 보여주게 됩니다.
이는 domain A와 domain B의 차이가 심하게 날수록 더 빈번하게 보여지겠죠. 이러한 문제를 해결하고자 Semantic Segmentation과 같은 pixel-level의 annotation을 추가하는 방법론들도 여러 제안되었다고는 하나, 아시다시피 segmentation 분야에서도 GT의 부족함을 느끼며 어떻게든 GT없이 성능을 향상시키는 방법론을 열심히 연구중인데 아물며 I2IT를 위해 Segmentation GT를 기대하는 것은 더더욱 실용적이지 못합니다.
그래서 저자는 DA 방법론을 통해 object(content)를 보존하는 I2IT 네트워크를 제안하여 어떠한 추가적인 어노테이션이 없이 왜곡 현상을 줄이는 방법론을 제안하고자 합니다. 저자가 새롭게 제안하는 self-supervised task는 두 도메인의 차이로 인한 왜곡으로부터 영상 컨텐츠의 feature를 disentangle 할 수 있다고 주장합니다.
Revisiting the problem of CycleGAN
제가 위에서 CycleGAN에 대해 말로 풀어서 설명했기 때문에, 해당 부분에서는 수식만 간단하게 언급하고 넘어가겠습니다.
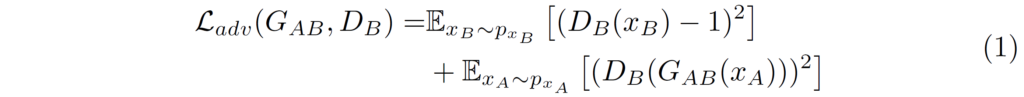
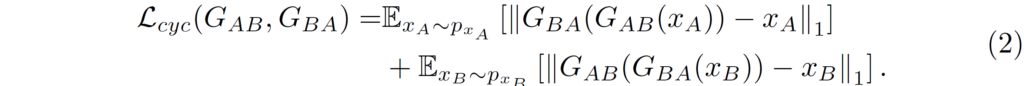
CycleGAN에서 가장 중요한 두 loss는 바로 위의 adversarial loss와 cycle-consistency loss입니다. adversarial loss는 domain B를 판별하는 판별자 D_{B}에 실제 real domain B image x_{B}와 translated image G_{AB}(x_{A})를 각각 태워서 판별자는 Generator와 Discriminator를 각각 학습시킵니다.
그리고 content의 유사도를 최대한 유지하기 위한 수식2는 B로 변환시킨 영상을 다시 A로 변환시킨 영상이 아무런 변환을 하지 않은 A 영상과 같아야 하며 동일하게 2번 변환시킨 B 영상과 아무런 변환을 하지 않은 B 영상이 같아야만 한다는 것을 의미합니다.
여기서 Cycle-Consistency loss의 경우 기하학적인 변환에 대해서 내부적인 모호함이 존재한다고 합니다. 이것이 무슨 의미냐면, 사실 G_{AB}, G_{BA}를 순차적으로 태워서 한번의 사이클로 변환시킨 결과에 대해 아무런 변환을 하지 않은 것과 동일하다면, G_{AB}, G_{BA}는 서로 역함수 관계라고 볼 수 있을 것입니다.
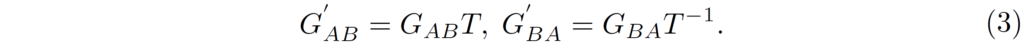
그렇게 된다면 위의 수식(3)과 같이 T라는 어떠한 bijective geometric transformation(e.g. translation, rotation, scaling etc..) 있다고 하였을 때 역함수를 취하게 되면 결과가 동일해져야만 한다는 것이죠. 하지만 결과적으로 CycleGAN에서 제안하는 cycle-consistency loss는 source와 translated image 사이에 컨텐츠 격차를 정확히 좁히지 못하여 기하학적인 왜곡으로 부터 완벽한 변환 결과를 생성하지 못한다고 합니다.
저자는 그리하여 self-supervised learning 기법을 활용하여 content를 잘 유지하는 결과를 생성하도록 하는 방법론을 제안하고자 한답니다.
Self-supervision formulation
저자는 content registration과 domain classification이라는 2가지 self-supervised learning task를 활용하여 영상의 content와 domain 정보를 담고있는 feature를 disentangle하고자 하였습니다. 또한 실질적으로 위의 multi-task self-supervised learning을 하기 위하여 siamese network를 추가적으로 활용하였습니다. 그럼 본격적으로 어떤식으로 proxy task를 설정했는지 알아보겠습니다.
먼저 저자는 source와 translated image 둘 모두에 대하여 3 x 3 grid로 나누었다고 합니다.(그리드 사이즈에 대해서는 저자가 실험적으로 밝힌 듯 합니다.) 이렇게 나누고 나면 그림 2와 같이 Source Image A에 대한 patch와 Translated image B에 대한 patch로 구분을 지을 수 있게 됩니다.
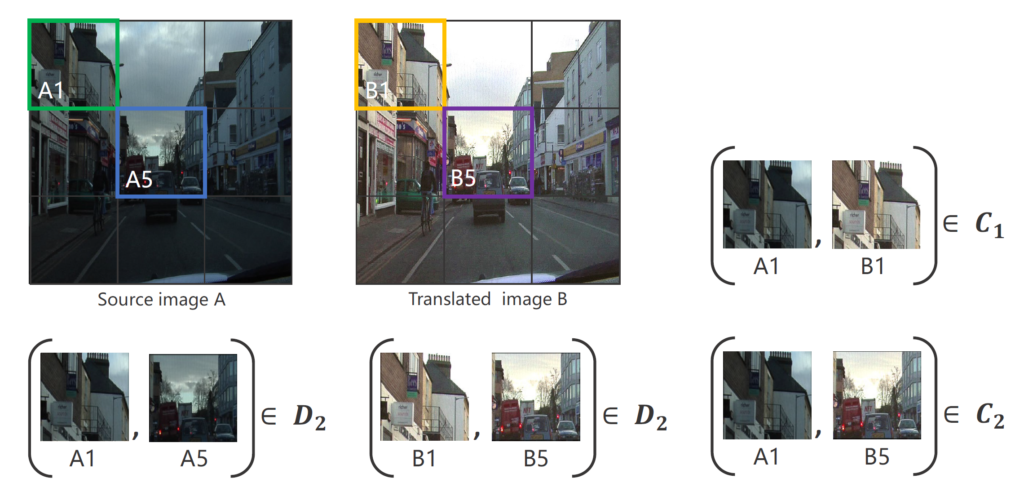
그 다음에는 랜덤으로 2개의 패치를 고르게 되며 이 때 선정될 수 있는 경우의 수는 아래 표와 같이 크게 4가지로 볼 수 있습니다.

D_{1}, D_{2}, C_{1}, C_{2}는 표에 영어를 읽어보시면 아시겠지만 굳이 해석하자면 순서대로 A도메인 내에서의 패치들, B 도메인에서의 패치들, 서로 다른 도메인이지만 동일한 위치의 패치들, 서로 다른 도메인이면서 위치도 서로 다른 패치들 순으로 나열되어 있습니다.
그림3에서 우측과 하단에 집합 표시들이 위의 경우의 수를 나타내는 예시라고 보시면 될 것 같습니다.(그림3에서 D_{2}가 2개 있는데 오타인 것 같습니다. (A_{1}, A_{5}) \in D_{1}로 보시면 될 것 같습니다.) 아무튼 이렇게 랜덤하게 선택된 패치 집합들은 짝을 지어서 siamese network의 입력으로 들어가게 됩니다.
그렇다면 siamese network에서는 어떤 학습을 하게 되는 것일까요? 저자는 object-aware domain adaptation을 수행하기 위해서 2가지 가정을 전제하였습니다. 먼저 1) 두 도메인(A and B)에 대해 동일한 위치의 패치 조합(C_{1})은 동일한 컨텐츠를 가진다는 것이며 2) 동일한 도메인에서 가져온 패치 조합( D_{1,2}는 유사한 도메인 정보들을 가진다는 것입니다.
이러한 위의 두 가정을 바탕으로, 같은 포지션을 가지는 두 패치에 대해서는 컨텐츠 정보가 유사해지도록 하는 feature를 추출하도록 proxy task를 수행하게 되며, 동일한 도메인에서 추출한 패치 집합의 경우 domain classification을 proxy task로 설정하여 수행하게 됩니다.
Network Architecture
자 그러면 siamese network가 어떤식으로 구성되어있는지 살펴봅시다.
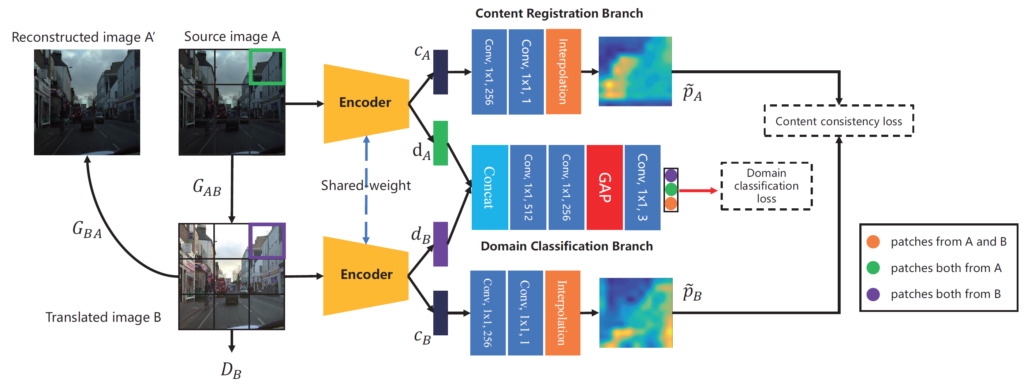
대략적인 구조를 살펴보자면, 먼저 웨이트를 공유하는 encoder 하나와, 두 proxy task를 수행하기 위해 content registration branch와 domain classification branch가 각각 있는 것을 확인하실 수 있습니다.
여기서 파랑, 주황, 빨강, 청록은 각각 convolution, interpolation, global average pooling, concatenation을 의미합니다.(물론 글씨로도 표기되어있긴 합니다)
처음 과정부터 간략히 소개드리면 weight를 공유하는 encoder를 통해 입력 patch(P)에 대하여 latent feature space(Z)로 변환시키는 과정을 수행하며 그 다음에 해당 feature에 대하여 content와 domain information을 분리하는 과정을 거치게 됩니다. 해당 과정에 대해 수식적으로 표현하면 아래와 같습니다.
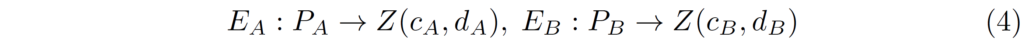
c, d는 각각 content feature와 domain information이라고 보시면 될 것 같습니다. 아무튼 이렇게 4개의 disentangled feature들의 크기는 [/latex] 11 \times 11 \times 512 [/latex]를 가지고 있으며 이제 c_{A}, c_{B} 에 대해서는 1×1 컨볼루션과 interpolation을 과정을 통해 원본 영상 속 패치의 해상도와 동일하게 해준 다음 content consistency를 계산하게 됩니다.
반면에 d_{A}, d_{B}는 둘이 concatenation하여 domain classification branch를 통과함으로써 domain information에 대해 명확히 학습하고자 합니다. 이것이 무슨 말이냐면, A도메인과 B 도메인에서 추출한 patch에 대해 domain feature를 각각 추출한 후 이 둘을 합쳐서 classifiaction branch를 통과시키게 되면 두 domain featur가 같은 도메인인지, 다른 도메인인지 등에 대해 학습함으로써 도메인간에 구분력을 기대해볼 수 있다는 것이죠.
아무튼 Content registration에 대하여는 아래와 같은 loss 함수를 사용합니다.
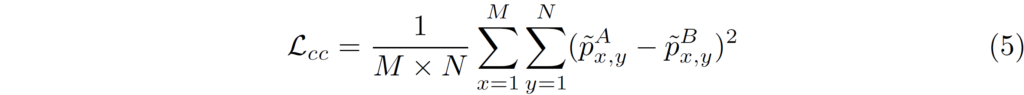
이것저것 복잡해 보이지만 그냥 pixel level에 대해서 L2 loss를 한 것입니다.
그리고 Domain classification에 대한 loss는 수식(6)과 같습니다.
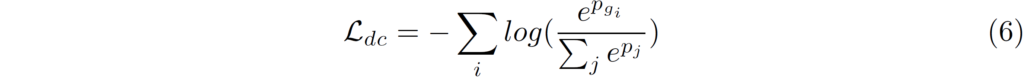
3가지 class에 대하여 cross-entropy loss를 계산한 것으로 보시면 될 것 같습니다. 저자 말로는 domain classifiation branch를 통해 feat ure의 domain inforatmion을 distillation할 수 있으며 이는 content feature를 더 잘 분리할 수 있도로고 도와준다고 합니다.
이렇게까지해서 저자가 새롭게 제안하는 Self-supervised DA 방법들은 모두 마쳤습니다. 위의 두 테스크에 대한 loss의 총합을 L_{S}라고 했을 때 저자는 최종적으로 아래와 같은 total loss를 사용합니다.
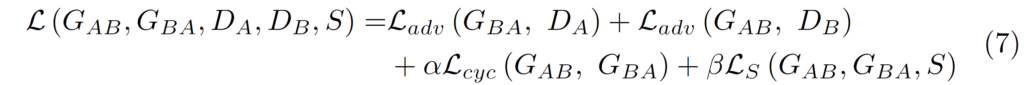
L_{adv}, L_{cyc}들은 모두 CycleGAN의 adversarial loss와 cycle-consistency loss 이 둘과 동일합니다.
Experiments
다음은 실험에 대한 설명입니다. 저자는 3가지 데이터 셋에 대해서 실험을 진행하였는데, 이는 CamVid, SYNTHIA, Colonoscopic dataset입니다. CamVid는 cloudy와 sunny 등 서로 다른 날씨에 촬영된 driving dataset이며, SYNTHIA는 다양한 시간대에 촬영된 virtual driving dataset을 의미하며, 마지막으로 Colonoscopic dataset은 다양한 색과 조도 등 영상 환경이 변화하는 의학 데이터 셋입니다.
저자는 자신들의 translation 결과에 대해 평가를 하고자 자신들의 방법론을 포함한 다양한 translation method로 변환시킨 fake image를 각각 real image로 사전학습된 semantic segmentation 네트워크에 태워서, 실제 real image 기준 얼마나 성능의 차이가 나는지를 평가하였습니다.
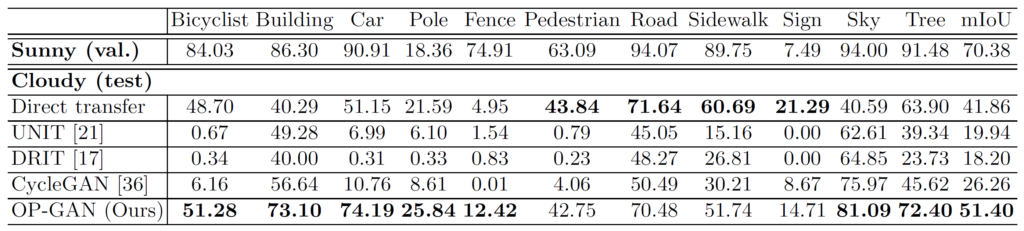
위에 표는 먼저 CamVid에서의 semantic segmentation 결과를 나타낸 것으로, 보시면 저자의 방법론이 다양한 Image Translation 방법론들 대비 대부분의 class에서 더 큰 iou를 보여주고 있습니다. 특히 Bicyclist, Car와 같이 object들에 대해서 매우 우수한 성능을 보여주고 있는데, 이는 저자가 제안하는 방법론이 translated object에 대해 왜곡을 최소화시켰다고 볼 수 있을 듯 합니다.
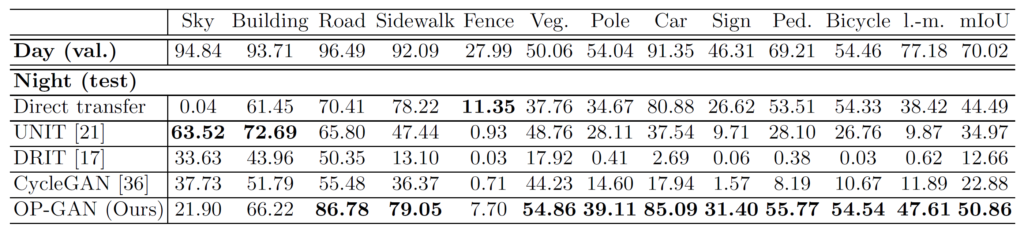
night to day를 수행한 SYNTHIA 데이터 셋에서도 유사한 결과를 보여주고 있습니다.

위 그림은 정성적 결과를 나타내고 있습니다. unpaired dataset이어서 sunny, day 등 target domain에 대한 GT 영상은 없지만, 첫번째 행에 source 영상과 비교하여 타 방법론들 대비 저자의 방법론이 얼마나 content를 왜곡없이 표현하고 있는지에 대해 살펴보시면 될 것 같습니다.
결론
최근에 Domain Adaptation, Multi-task learning 방향으로 연구를 하고자 관련 논문들을 읽으려고 하는데, 해당 논문은 CycleGAN에 대해서 잘 알고 있어서 그런지 가볍게 읽기에 상당히 좋았습니다. 해당 방법론의 컨셉이 매우 심플하고 단순해보이지만 좋은 성능을 보여주고 있으며, 논문을 다 읽고나니 저도 이렇게 심플하지만 우수한 결과를 보여주는 그런 방법론을 제안하고 싶다는 생각이 드네요.