이번주 리뷰는 포인트클라우드만을 사용하여 3D Detection을 수행하는 아주 유명한 방법론인 VoxelNet에 대해서 진행하겠습니다.
원래 PV-RCNN++를 다룰까 했지만 아직 Question mark가 해결 안되는 내용이 많아서 일단 지난주에 읽어두었던 VoxelNet 리뷰를 작성하게되었습니다. PV-RCNN++는 좀 더 공부를 진행한 후 리뷰하도록 하겠습니다.
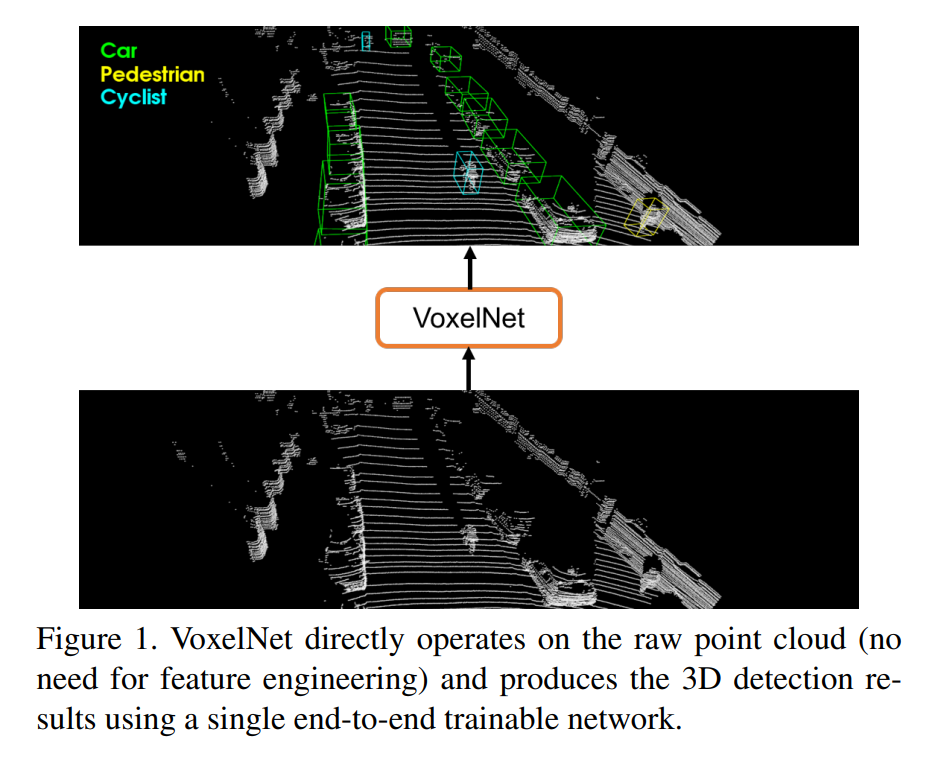
VoxelNet은 위의 그림처럼 3D 포인트 클라우드 데이터를 voxel단위로 나누어서 detection을 수행하는 것을 의미합니다.
2017 CVPR논문이고요, 나온지 시간이 꽤 되었지만, 현재까지도 VoxelNet에서 제안하는 voxel feature 추출기법이 사용되고있는만큼 이해하고 넘어갈 필요가 있는 논문입니다.
해당 논문이 나올 시기에 이미 Voxel이라는 개념은 있었는데 그때 당시에는 voxel에서 hand-crafted feature를 추출하여 사용하였습니다. end-to-end로 학습 및 평가를 할 수 있는 모델이 없었던 셈 입니다.
그러한 관점에서 end-to-end로 voxel로부터 feature를 추출하여 사용하는 VoxelNet은 grid 기반의 3D detection에 상당히 큰 기여를 합니다.
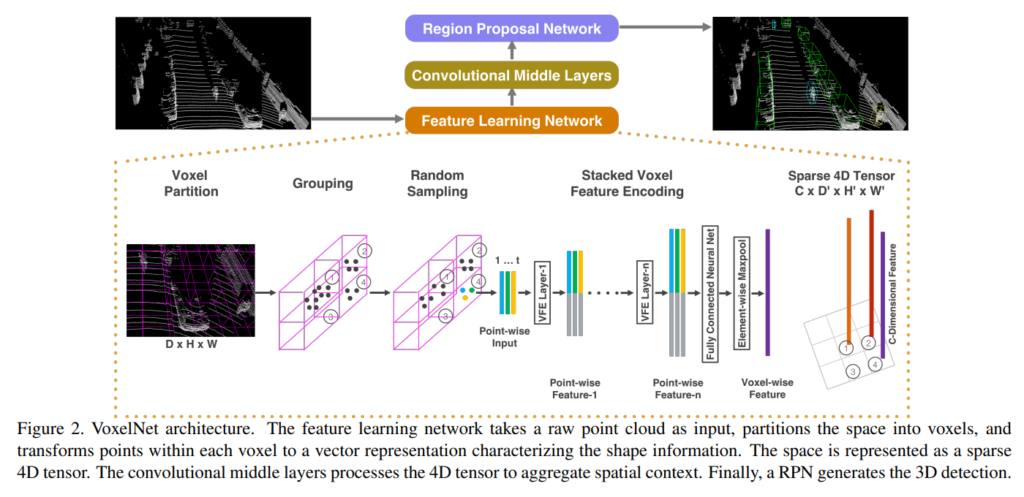
VoxelNet은 raw 클라우드 포인트 데이터를 인풋으로 3D detection을 수행하는것이 최종적인 목적이며, 전체적인 파이프라인은 위와같은 구성으로 되어있습니다.
인풋으로 들어온 raw point cloud 데이터는 먼저 equally spacing하여 voxel grid로 나눕니다. 그리고 각각의 voxel내에 존재하는 point들로 부터 feature를 추출하여 voxel-wise feature로 가공한 후 voxel feature들을 aggregate하여 4D tensor를 만들어 준 후 3D Sparse Convolution layer를 태워 피쳐를 뽑습니다. 그리고 해당 피쳐를 2D BEV로 reshape한 후에 RPN레이어를 통해 proposal을 만들어내고 Detection하는 방식으로 3D detection을 수행합니다.
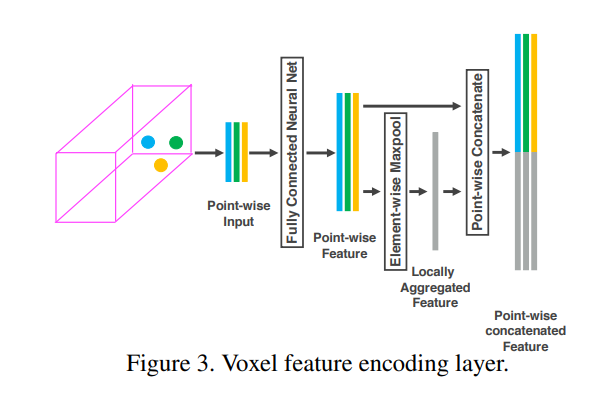
하나씩 차근차근 알아가보겠습니다. 우선 voxel로 부터 피쳐를 어떤식으로 추출했을지가 논문에서 가장 핵심이되는 부분이고, 해당 내용에 대한 그림은 위와 같습니다.
일반적으로 포인트클라우드 데이터는 매우 sparse하고 모든 voxel이 포인트클라우드 데이터를 포함하고 있지는 않습니다. 따라서 voxel중에서 포인트클라우드데이터를 포함하고 있는 경우에는 위의 그림에서 보여주는것과 같은 방식으로 피쳐를 추출합니다.
구체적으로, 먼저, voxel마다 존재하는 point의 개수가 다르기 때문에 각 복셀마다 N개의 point를 random sampling하여 사용합니다. 이때, N은 하이퍼파라미터로 1024개 2048개 등 데이터셋의 종류에 따라서 다르게 설정해줍니다. 위의 그림은 N이 3인 경우를 나타낸 것이며, 실제로 N은 3보다 훨씬 큰 수를 사용하나 이해를 돕기위한 그림이라고 생각하시면 됩니다.
추출한 N개(3개)의 포인트들은 각 x, y, z에 대한 좌표값과 intensity를 나타내는 r값을 포함하고 있습니다. 즉, 포인트별로 4개의 정보를 가지고 있습니다. 여기에 추가적인 local spatial 정보를 부여하기 위해 voxel내에 존재하는 모든 포인트들의 x, y, z 각 좌표값의 평균을 구합니다. 즉, voxel내의 존재하는 점들의 평균 중심점의 좌표를 구합니다. 그리고 해당 x_c, y_c, z_c를 각 포인트에 concatenate하여 사용합니다. 이러한 과정을 거치면 한개의 포인트는 총 7개의 정보를 가지게 됩니다.
7개의 정보를 가지는 3개의 point들은 각 MLP레이어를 거치고 더 high-level feature 3개로 변환됩니다. 그리고 해당 high-level 피쳐 3개를 global max-pooling 하여 추가적인 피쳐를 생성한 후 해당 피쳐를 각 high-level 피쳐 3개에 concatenate하여줍니다. 이러한 방식을 취하면 각 point들로 나온 feature들은 voxel내에서 spatial한 정보까지 가지고 갈 수 있습니다.
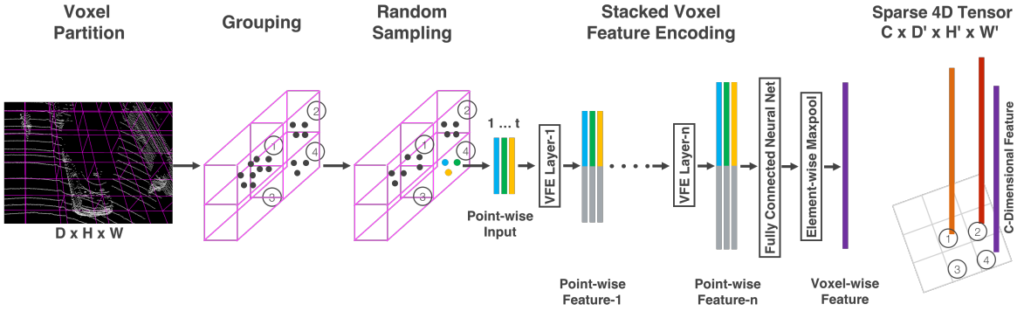
그렇게 구한 3개의 피쳐는 Element-wise Maxpool 레이러를 거치면서 최종적으로 Voxel-wise Feature로 변환되고, 이러한 Voxel-wise feature를 z축으로 Stacking하여 Sparse 4D Tensor를 만들어줍니다. 해당 4D tensor 에서는 그림과 같이 1,2,4 grid cell에서는 C-dimensional voxel-wise feature가 stacking되어있고, 3번 grid cell처럼 voxel내에 point가 존재하지 않을때는 empty인 상태로 놔둡니다. 이러한 형태를 Sparse하다고 하는데, 실제로 빈 voxel이 많기 때문에 메모리 및 연산효율을 위해서 sparse한 형태로 feature를 representation하였다고 합니다.
이렇게 추출한 4D tensor는 Sparse 3D CNN에 인풋으로 들어가게 되며, 해당 3D CNN을 거치고 나온 피쳐를 다시 reshape하여 BEV로 변환한 후에, 해당 2D BEV map 위에서 RPN을 학습시킵니다.
RPN 구조는 아래와 같습니다.
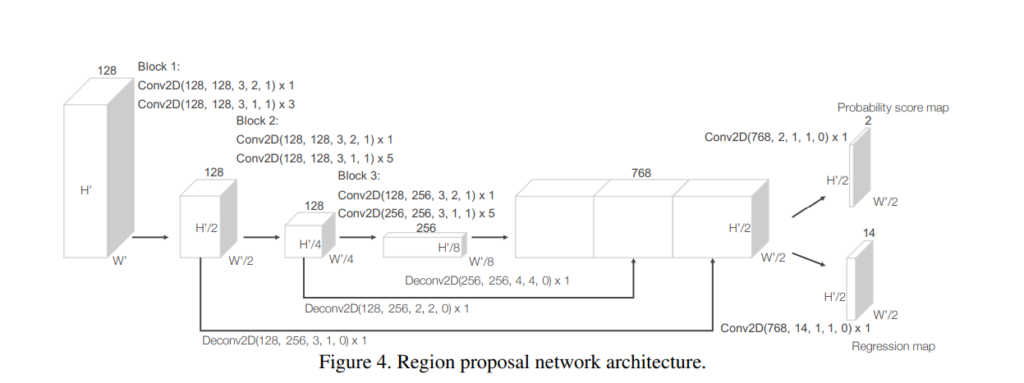
그냥 2D detection에서도 사용하는 RPN과 원리와 구조가 동일하며, 특별한 점은 없어 보입니다. BEV맵상에서 Proposal Bbox의 region을 regression하고, class를 classification하는 그런 전형적인 구조입니다.
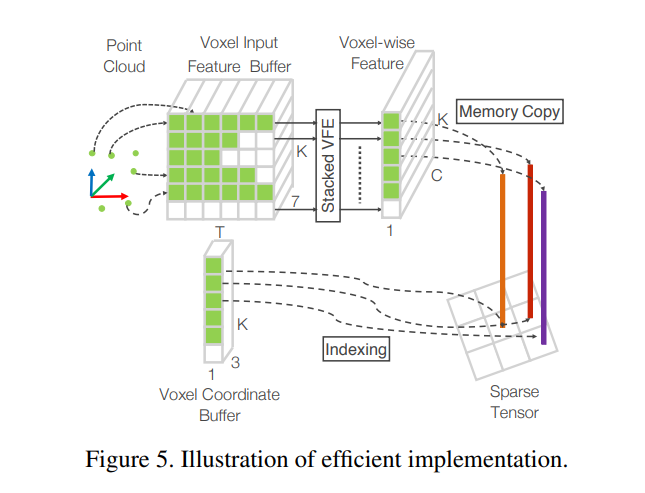
sparse한 포인트 클라우드 특성상 empty voxel이 많으므로 위와같이 sparse한 연산에 특화된 연산을 수행함으로써 연산량을 많이 줄였다고 합니다. 즉, 모든 voxel에 메모리를 할당하는게 아니라, empty voxel이 아닌 경우에만 할당하며, empty voxel이 아닌 경우에 해당하는 voxel의 위치를 index로 가지고서 처리하는 방식입니다.
평가
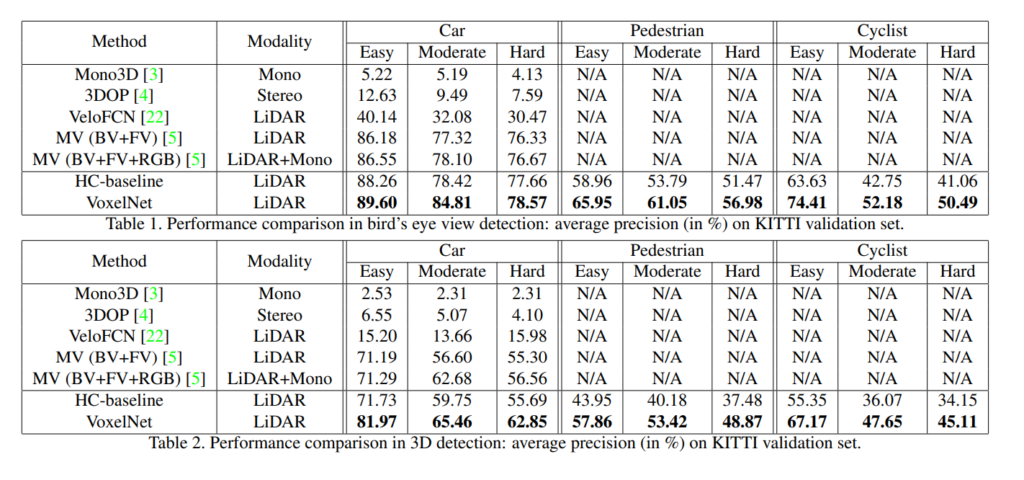
2017년 KITTI validation 데이터셋에서 BEV와 3D Detection모두 당시 SOTA이던 MV를 이기고 SOTA를 차지하였습니다.

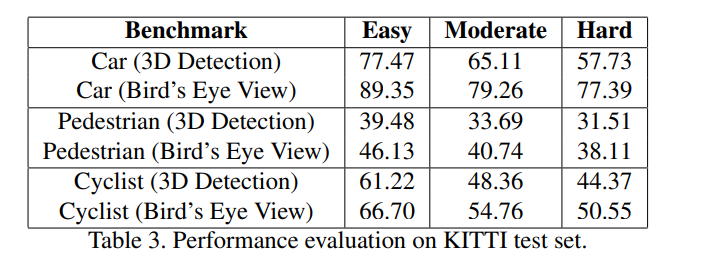
마찬가지로 TEST set에서는 KITTI공식 사이트에 제출하여 evalutation 하였으며 당시 SOTA를 이겼습니다.