
일전에 리뷰를 진행했던 ‘[CVPR2020] Unsupervised Multi-Modal Image Registration via Geometry Preserving Image-to-Image Translation‘ 논문의 저자와 같은 연구실에서 2021 CVPR에 억셉된 논문입니다.
해당 논문은 일반적으로 RGB 카메라의 Resolution은 크지만 다른 센서(Thermal, Depth 등)들은 RGB 만큼의 resolution을 얻으려면 센서 가격이 비싸지는 문제점을 해결하기 위해 RGB카메라로 촬영한 고화질의 영상을 이용하여 다른 센서의 이미지의 Resolution을 높이는 연구입니다. 먼저 논문의 Introduction에 글 일부를 확인하시면 아래와 같습니다.
State-of-the-art Joint Cross-Modality SR methods rely on the assumption that their multiple inputs are well aligned. Thus, they perform well only when the input images were captured by different sensors placed in the exact same position, and taken at the exact same time. As to be shown, in real-life scenarios perfect alignment of multiple sensors is often hard to achieve.
‘해당 논문의 Introduction 에서..’
해당 논문에서 저자는 제가 생각하고 있는 문제에 대해서 정확히 지적하고 있습니다. 그리고 이러한 문제를 해결하는 동시에 Super Resolution을 수행하는 방법을 제안합니다. 멀티스펙트럴, 멀티모달 분야에서 Misalignment는 중요한 문제이고 이러한 문제를 해결하는 방법들이 컴퓨터 비전 학회에서는 좋게 평가되고 있는게 아닐까 생각됩니다.
다시 본론으로 돌아와서 그렇다면 해당 논문에서는 이러한 문제를 어떻게 해결하고자 하는가에 대해서 이야기해보겠습니다. 먼저 해당 논문에서 제안하는 Super Resolution 네트워크의 학습 방법은 다음과 같습니다.
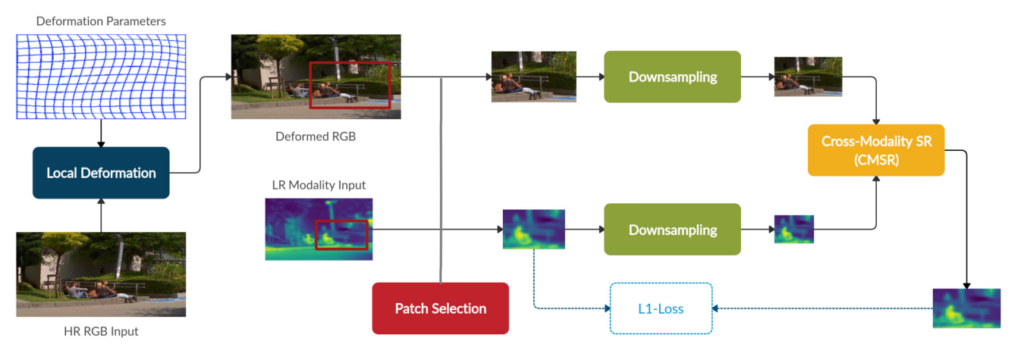
크게 ‘Local Deformation’, ‘Patch Selection’, ‘CMSR Network’로 나눌 수 있으며, 하나씩 살펴보겠습니다.
Local Deformation
해당 부분이 Misalignment를 해결하고자 하는 부분입니다. 본 논문의 방법론에서는 세 개의 transformation layers로 구성된다고 합니다.
첫번째는 ‘Affine STN layer’ 입니다. 해당 레이어는 ‘Spatial Transformer Network‘ 라는 논문에서 발표된 방법으로 global affine transformation을 계산하며 해당 방법은 두 모달리티간의 position 에러를 초기에 약간 rough하게 추정하는데 사용된다고 합니다. (해당 논문에 대한 리뷰는 일전에 이승현님께서 진행하셔서 해당 링크도 공유드립니다.)
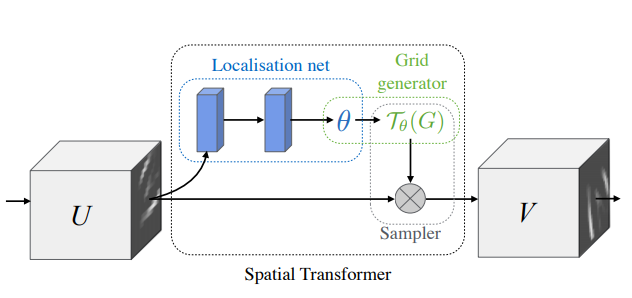
다음으로는 ‘DDTN transformation layer’ 입니다. 해당 논문은 ‘Deep Diffeomorphic Transformer Network‘에서 제안된 방법으로 기존 Affine STN layer를 변형한 모델인데, Affine STN Layer 보다 더 유연하고 expressive 한 변형이 가능하다고 합니다. 이때 DDTN layer 에서 변형 모델로는 CPAB(Continuous Piecewise-Affine Based) 를 선택하였다고 저자는 이야기하며, 해당 방법론에 대해서는 추가적으로 DDTN 논문을 읽고 리뷰할 예정입니다.
그리고 마지막 레이어로는 TPS(Thin-plate spline) 변형을 사용하였으며 해당 방법론은 컴퓨터비전에서 많이 사용된다고 합니다. 이미지를 워핑하는 방법이라고 하는데… 해당 부분에 이론적인 베이스까지는 확인하지 못하였고, 관련 내용이 담긴 블로그 글을 공유드립니다. .해당 방법론은 OpenCV에도 구현되어 있을만큼 많이 적용되고 있는것 같네요.
자 그럼 앞선 3가지 변형 방법들을 이용하여 저자는 두 모달리티에서 발생하는 Misalignment를 해결한다고 이야기합니다. 원래 해당 부분에 대한 실험결과는 나중에 리포팅하나, 이해를 돕기위해서 앞선 3가지 방법을 이용하여 아래와 같이 misalignment 문제가 해결될 수 있다고 합니다.

위에 그림을 통해서 저자는 Misalignment가 해결됨을 보입니다. (저는 잘 모르겠지만..) 그리고 이러한 방법을 통하여 Alignment를 잡을때마다 Super Resolution을 수행할때마다 PSNR이 증가함을 아래와 같이 나타내고 있습니다.
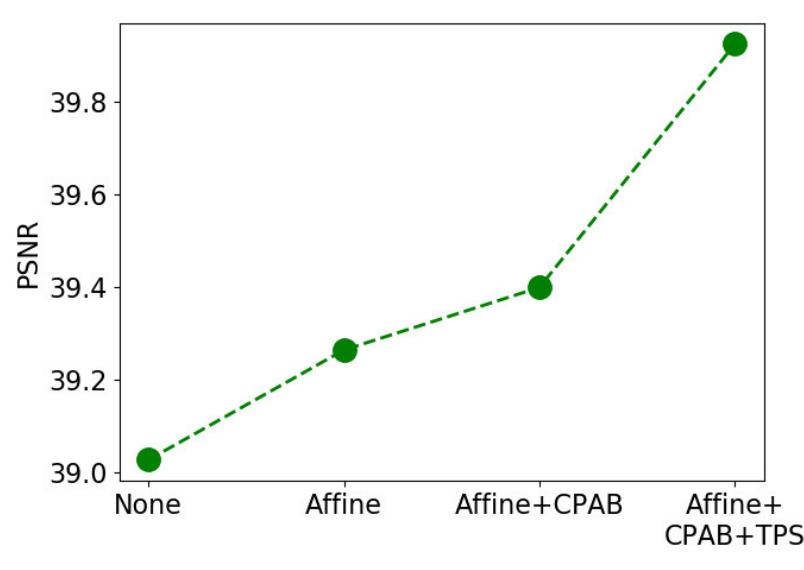
사실 여기까지만 관심있는 부분이였지만, 그래도 논문에 대한 전체 리뷰를 해야하므로 Cross modality Super Resolution에 대한 이야기도 진행하겠습니다. 앞부분에서는 어쨋든 얼라인이 안맞는 두 모달리티 영상 입력에 대해서 얼라인을 맞추기 위한 방법을 설명했다면, 얼라인을 맞춘 두 모달리티 영상을 이용하여 Super Resolution을 수행하는 방법에 대해서도 논문을 설명하고 있습니다.
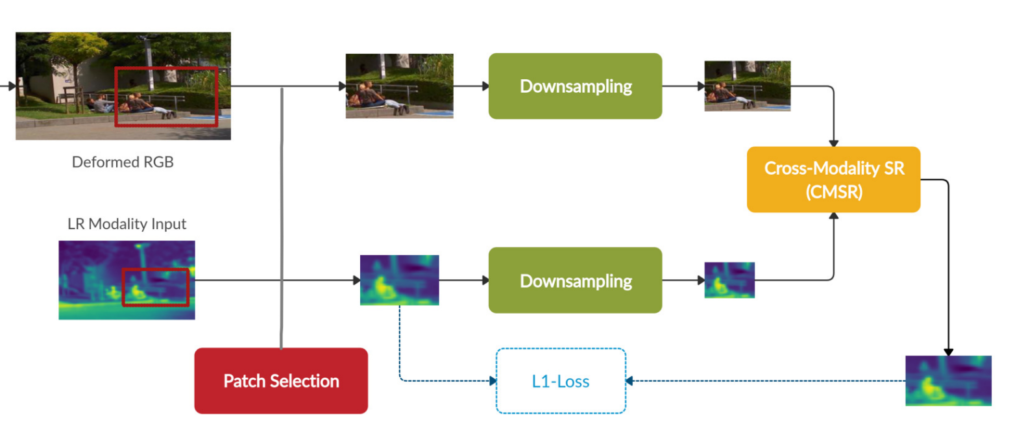
앞서 방법으로 RGB 영상을 Thermal에 맞게 Deformed 하였다면, Patch Selection이라는 방법을 통하여 랜덤의 영역을 RGB ,Thermal 모두 동일한 영영역의 패치를 crop하고 해당 패치에 대해서 Super Resolution을 수행합니다. 여기서 다운샘플링을 수행하는 이유는 실제 고화질의 Ground Truth가 없기 때문에 현재 영상을 다운샘플링하고, 이를 Super Resolution으로 키워서 현 Resolution의 영상과 비교하는 방식으로 모델을 학습한다고 합니다. 저는 여기서 ‘그럼 resoltuion이 큰 고화질의 영상은 못만드는게 아닌가?”라고 생각했는데, 저자는 아래와같이 논문에 나타내고 있습니다.
Since CMSR is fully convolutional, it can operate on any image size (e.g., both image patches of different scales, and full images) using the same network.
마지막으로 실제 Super Resolution을 수행하는 CMSR에 대해서 설명하겠습니다.
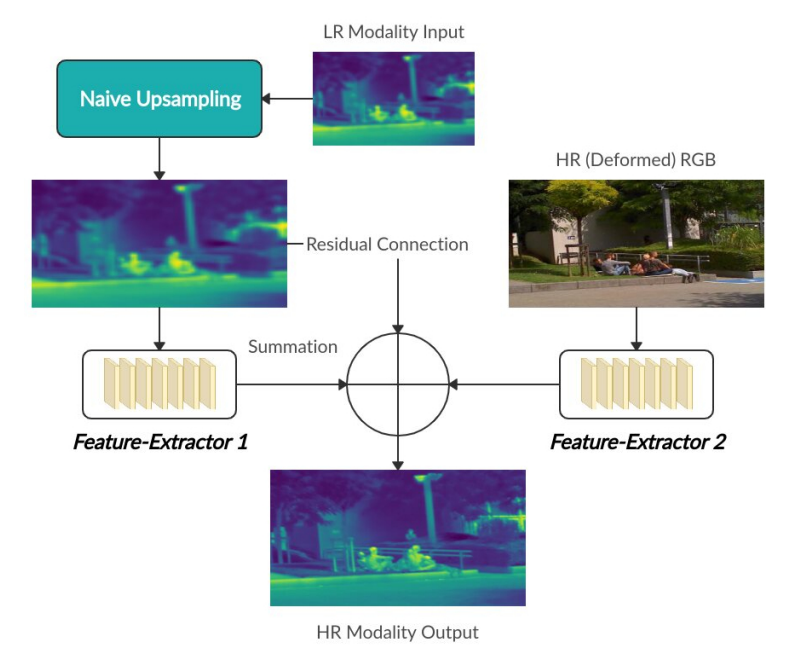
RGB, Thermal 모두 다운샘플링 하였기 때문에 아직 RGB와 Thermal의 Resolution 차이는 존재합니다. 따라서 Thermal 영상을 단순히 업샘플링하여 RGB와 맞추고, RGB와 Thermal 각각에서 Feature를 추출하여 RGB feature, Thermal feature, Theraml image를 모두 summation하여 High Resoluition 이미지를 만들게 됩니다. 여기서 그럼 Feature를 추출하는 네트워크는 어떻게 구성됐는지 궁금할 수 있는데, 논문에서는 아래와 같이 해당 네트워크를 이야기하고 있습니다.
For Feature-Extractor 1 we use eight hidden layers, each containing 64 channels and a filter size of 3×3. We place a ReLU activation function after each layer except for the last one. The size of feature maps remains the same throughout all layers in the block. For Feature-Extractor 2 we typically use four to eight hidden layers with number of channels ranging from 4 to 128, a filter size of 3×3 and a ReLU activation function. The last layer has no activation and a filter size of 1×1.
이러한 방법으로 모델을 학습하고나서, 최종적으로 Inference는 아래와 같이 수행합니다.
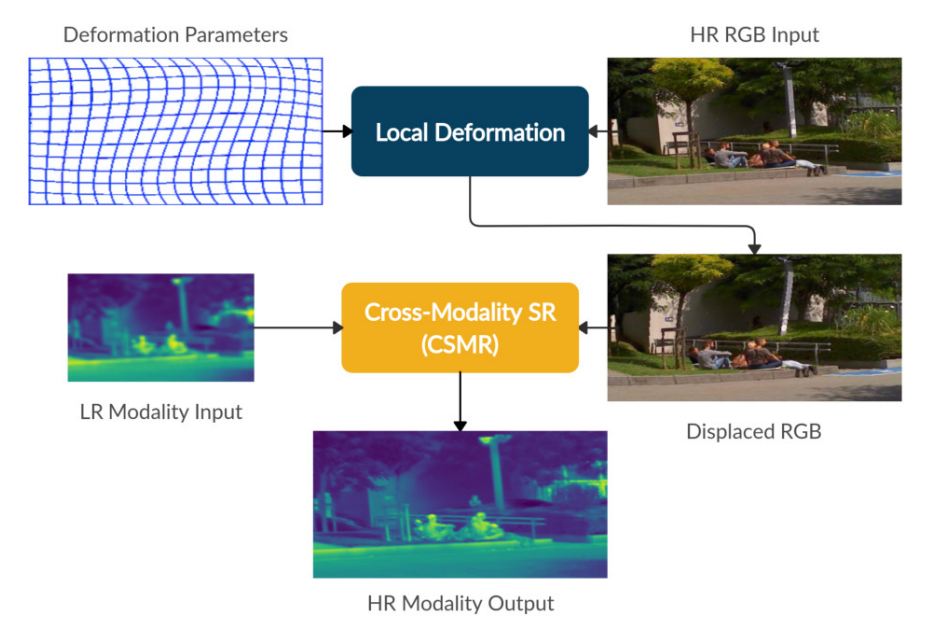
Result



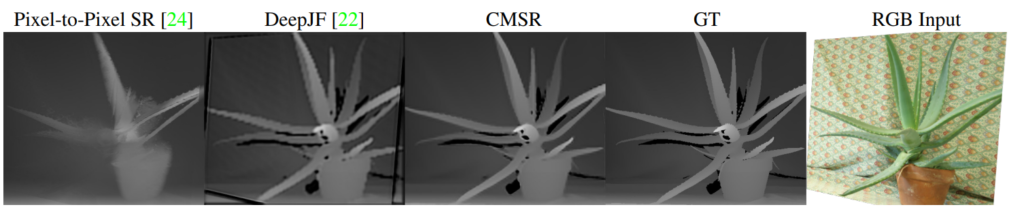
위에 그림들은 본 논문에서 나타낸 정성적 결과들입니다. 추가로 2020 CVPR에 제출한 논문에서는 식물 데이터셋에서만 해당 내용을 다루고 있어 아쉬움이 많았는데, 본 논문에서는 다양한 Cross Modality Datasets에 대해서 Super Resolution을 평가하고 있습니다.
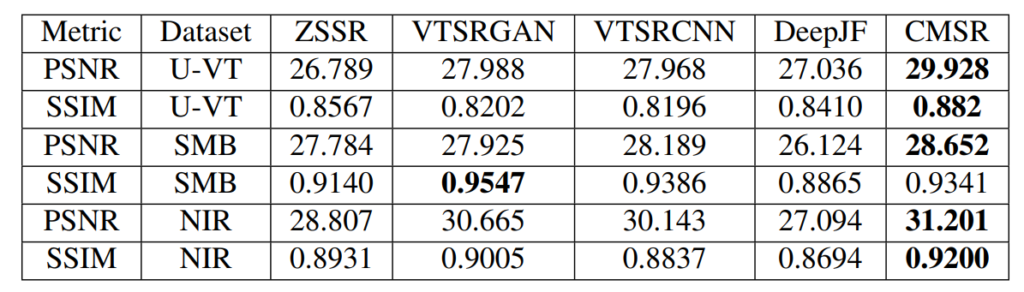
여기서 저는 멀티스펙트럴 데이터셋인 U-VT 데이터셋에 대해서 오늘 처음 알게됐는데, 해당 데이터셋은 ‘ULB17-VT’ 이라고 불리며 해당 사이트(Version2가 있어서 Version2에 대한 링크를 남깁니다.)에서 다운로드 가능합니다.

결론은 여러 모달리티의 얼라인 문제를 해결하는데 있어서 저는 Translation을 통해서 Fake RGB를 만들고 matching을 잘 수행하여 두 모달리티의 얼라인을 맞춰야겠다가 제 생각이였는데, 실제 Translation에서 각 object들의 디테일이 잘 안살아나는 것을 보면서 쉽지 않을 수 도 있겠다는 생각을 하게 됐습니다. 그러던중 해당 논문을 통해서 STN 쪽 논문들을 따라 읽으면서 해당 방법을 어떻게 적용할 수 있을지 고민해보고 있습니다.
현재 실험에 사용된 데이터 셋들은 식물 데이터 셋보다는 다양한 씬을 보았다고 생각하면 될까요? 식물로만 했을때는 씬이 너무 단조로워서 우리쪽에 적용가능할까라는 생각이 있었는데 이번꺼는 다른 데이터셋도 있어서 여쭤봅니다.
네 위에 설명드린것과 같은 데이터셋에서도 적용하여 성능 향상을 가져왔다고 합니다. 근데 문제는 alignment가 맞는 사진은 식물로만 보여주고 있어서 반신반의 하는 상황입니다.
리뷰 잘 읽었습니다.
transformation에 대하여 얼렁뚱땅? 넘어간 부분이 있는 것 같은데 빨리 리뷰해주시면 좋겠네요ㅎㅎ
매우 아쉽게도 저자도 해당 부분을 본 리뷰정도로 설명하고 있습니다 …