이번에는 video classification 관련 데이터셋 논문을 들고왔습니다. 사실 muses라는 데이터셋을 공개한 “Multi-Shot Temporal Event Localization: A Benchmark”을 읽기로 되어있었는데, 이 논문이 성격도 비슷하면서 저에게 필요한 것 같아 읽었습니다.
물체 중심의 비디오 데이터셋은 어떻게 만들어 지는가? (물론, 이 논문도 물체 중심은 아니지만 넓은 범위를 다루어 물체가 많이 포함되어 있습니다.) 그리고 물체 중심의 video retireval을 수행할 때 도움이 되지 않을까?하는 생각에 video classification은 어떻게 수행되는지 알아보기 위해 읽었습니다.
그럼 시작하겠습니다.
Introduction
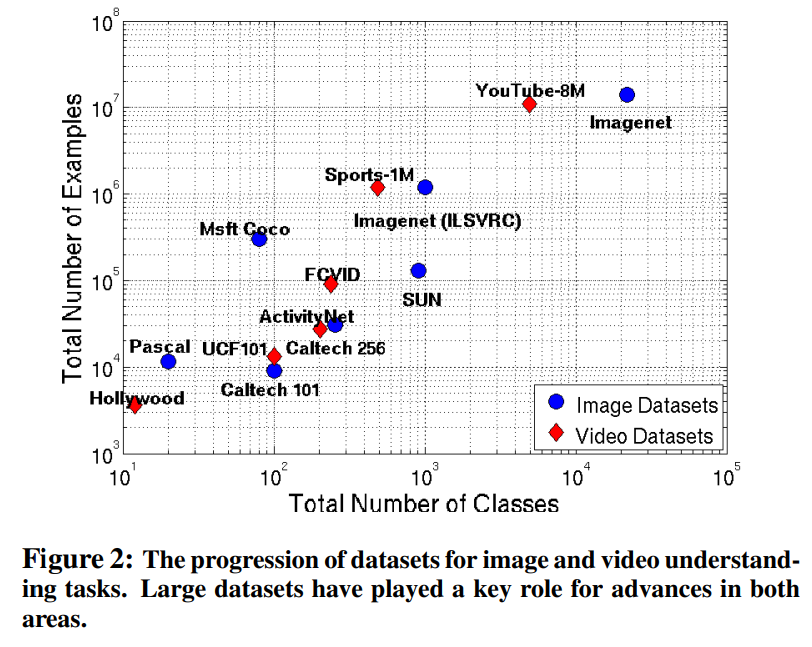
이미지 기반에서는 유명한 대용량 데이터셋 ImageNet이 존재하지만, 이 논문이 나오는 시점에 이러한 데이터셋이 없었습니다. 위 그림을 보면 이러한 상황을 한눈에 알 수 있는데요. 그나마 큰 데이터셋들은 action 데이터셋이라 사실상 없는 상태였죠. 이 논문 저자들은 Imagent이 가져온 혁신이 이러한 데이터셋을 만들면 video 연구에도 올것이라 생각했습니다.

그래서 YouTube-8M이라는 대용량 multi-label video classification 데이터셋을 제작했습니다. 이러한 데이터셋은 activities, objects, scenes그리고 events와 같이 넓은 객체들을 다룹니다. 유튜브의 video annotation system을 이용해서 비디오에 시각적으로 구분 가능한 객체들을 넣어주는 방식을 이용했는데요. 이러한 방식을 이용해 4800개의 클래스를 가진 큰 데이터셋을 만들 수 있었습니다.
Youtube-8M dataset
Youtube video annotation system은 비디오로부터 주제를 판별합니다. 그리고 이 주제를 Knowledge Graph를 이용해서 비디오와 비디오의 연관 관계를 파악합니다. (Knowledge Graph는 특정 단어와 단어의 연결관계를 알고있는 큰 사전이라고 보시면 됩니다.)
이러한 방법을 이용하면, 기존의 데이터셋들과는 차이점이 생기는데요. 비디오가 특정 이벤트에 종속되는게 아니라, 그 비디오가 가지고 있는 여러 주제들에 대한 관계가 생기게 됩니다. (논문에는 나오지 않는데, 비디오마다 평균적으로 3개의 라벨을 가지고 있다고 합니다.) 이러한 특성 때문에 단순한 object recognition task와는 큰 차이를 가져가게 됩니다.
결국 비디오를 잘 이해해서 이 비디오가 가지고 있는 주제를 잘 뽑아내는 것이 이 데이터셋의 목적이게 되는거죠.
Vocabulary Construction & Collecting Videos
저자들은 두가지 신조를 가지고 데이터셋을 만들었다고 합니다.
- 모든 라벨은 시각적으로 구분되어져야 한다.
- 모든 라벨은 충분한 데이터가 있어야 한다.
하지만 수많은 유튜브 비디오 중에 어떤 라벨을 선택할까요? 여기서 Knowledge Graph을 이용합니다. 블랙 리스트와 화이트 리스트를 지정해서 효율적으로 고를 수 있었다고 합니다. 비디오 자체도 아래와 같은 규칙을 정했습니다.
- 객체의 비디오 갯수가 200개 이하는 버림
- 120~500초 사이의 비디오만 선택
- 조회수가 1000 이상인 경우에만 선택
이런 식으로 고르고, 7:2:1로 train:validate:test로 나눠서 저장했습니다. 딱히 큰 규칙이 없는 것 같아서 실제로 데이터셋이 어떻게 수집되었는지 보니까 꽤 괜찮더라고요? Youtube video annotation system을 써볼 수 있으면, 더 잘 알 수 있을 것 같은데, 공개된 툴은 아니라 아쉽습니다.
Features
비디오 데이터셋이 용량이 워낙 크다 보니까 이대로 제공하면 용량이 몇백 테라바이트로 매우 큽니다. 그래서 이미지넷으로 학습된 Inception model을 살짝 수정해서 초당 1프레임씩 뽑아서 frame level feature로 만들어서, 초당 2048차원을 가진 feature-vector를 뽑습니다. 그리고 이 데이터를 공유합니다.
베이스라인 자체도 이 데이터를 이용했기 때문에 효율적인 방법 같습니다. 어차피 일반적인 연구실에서 이 데이터를 다 받을 수 조차 없을테니까요.
baseline 학습 할 때는 PCA(+whitening)을 수행해서 1024 차원까지 축소했고, quantization을 적용해서 더 빠른 학습을 할 수 있도록 했습니다. (여기서는 실제 값과 비교하면 1% 정확도 차이라네요.)
quantization을 비디오에서는 안 쓰는줄 알았는데, ViSiL 저자가 최근 작성한 논문을 보면 이렇게 적용해서 비교하는 실험도 수행하는 것을 보아, 비디오에서도 이제 쓰는 것 같습니다. 볼 수록 신기한 방법입니다.
Dataset Statistics
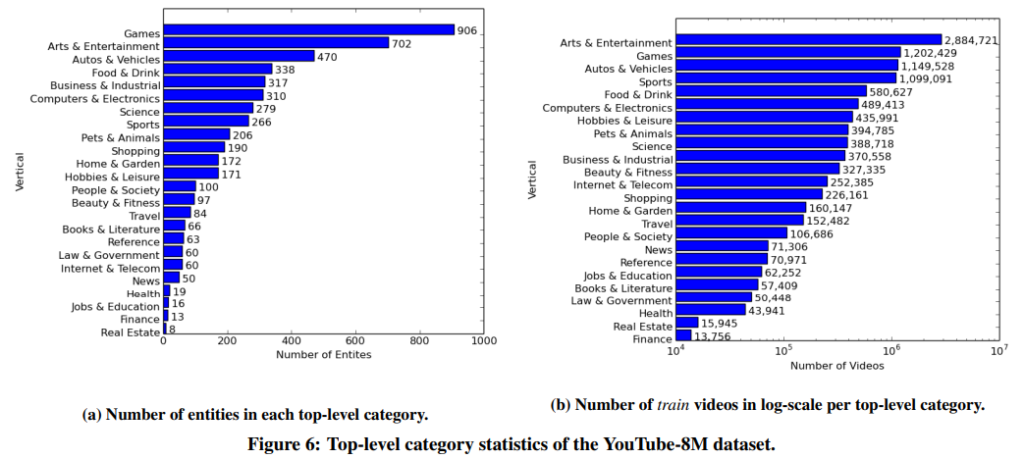
24 top-level categories를 측정해보면 위와 같습니다. 세부 라벨링은 따로 있고요. 고르지 못한 분포를 보이고 있긴 하지만, 데이터셋 자체가 용량이 커서 문제가 없는 듯 합니다.
Baseline approaches
사실 video classification을 어떻게 하는지 알고 싶어서 이 논문을 읽었는데요. 이 데이터셋으로 수행하는 챌린지들도 많아서 보고 싶었는데, 이게 정말 성능을 끌어 올리기 위한 기법들이 많아서 읽기 어려워서 기본적인 방법론으로 베이스라인을 정하지 않을까 싶어서 이 부분을 읽었습니다.
Models from Frame Features
frame-level 라벨링이 수행되어 있지 않은 관계로, frame-level feature를 이용해서 비디오의 메인 주제를 예측하도록 모델을 학습합니다. video 레벨의 task에서도 frame-level을 이용해서 좋은 정확도를 끌어낼 수 있기 때문에 이런 방법을 사용했다고 합니다. (뒤에 video-level feature를 이용한 방법론도 등장합니다.) 간단한 방법부터 어려운 방법(?) 까지 3가지 방법이 소개됩니다.
Frame-level models and average pooling
각각의 비디오에서 20개의 프레임을 랜덤으로 선택해서 이 프레임들의 GT를 비디오 레벨 GT로 가정합니다. 살짝 궁금한 부분은 분명 최대 500초라고 했으니까, 분당 1프레임씩 뽑아서 frame-level feature로 가공해서 제공했다고 했으니까. 20개 프레임을 랜덤으로 뽑을 수가 없는데, 뽑았네요? 어쨋든 이렇게 뽑으면 12억장의 프레임에 대한 엔티티 정보 쌍을 얻을 수 있습니다. 이 정보를 학습해서 비디오의 frame-level scores를 뽑고, 이 점수를 더하고 평균을 내서 video-level score로 만든다고 합니다.
Deep Bag of Frame (DBoF) Polling
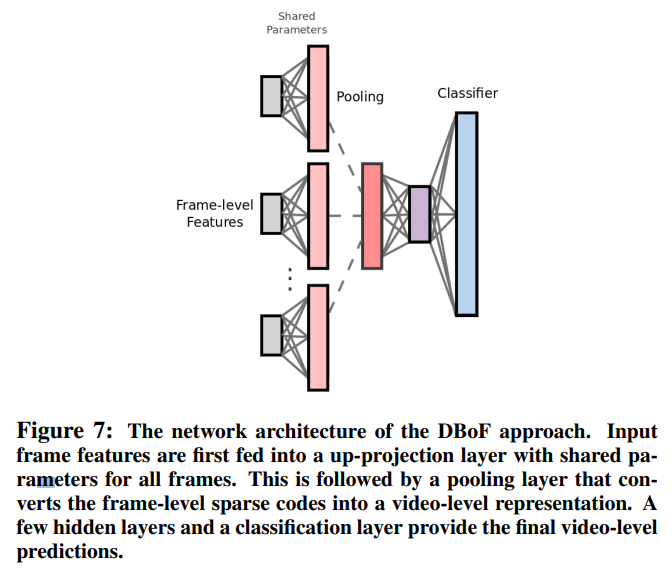
frame-level feature를 사용하는 것은 동일하지만, 여기서는 K개의 random 선택된 frame-level feature를 사용합니다. N차원의 frame-level feature를 입력하면, 이를 projection layer에 태워 M차원으로 확장합니다.
이렇게 나온 값들을 pooling을 이용해서 합쳐주면, 고정된 크기의 video representation을 얻게 됩니다. 이 값을 이용해서 일반적인 방법대로 분류기를 학습해줍니다. 사실 기존의 있는 방법을 활용했다고 하는데요. projection layer를 쓴 점이 큰 차이점이라고 합니다. 이 projection layer와 pooling layer가 희소 행렬을 만들어준다고 하는 것 같습니다. 이렇게 되면 당연히 학습에 문제가 있겠지만, 여기서는 이렇게 희소 행렬이 된 K개의 프레임이 하나의 고정된 video representation이 되므로 괜찮은 것 같습니다.
Long Short-Term Memory (LSTM)
위 논문에서 사용한 방법이랑 비슷하게 접근했지만, 이 데이터셋에서는 프레임 단위로 접근할 수 없기 때문에 LSTM과 softmax layer만을 학습했다고 합니다. ActivityNet으로의 전이학습을 고려해서, FC layer는 LSTM 레이어의 출력값을 concat해서 사용했다고 합니다.
왜 LSTM을 사용한지는 이 논문에 성능이 나오지 않아서, 추측을 해보자면 연속된 정보를 조금 더 잘 보면 성능이 좋아진다고 판단했거나, 기존 데이터셋들은 action dataset이라 이런 연속된 정보를 보는 것 같다고 생각합니다.
Video level representations
여기까지가 frame-level feature를 이용한 방법이었고, 여기서부터는 video-level feature를 뽑아서 사용합니다. 먼저 각각의 비디오 v의 frame-level features를 고정된 크기의 video-level feature로 뽑는 작업을 수행합니다.
이러한 video level feature는 장점 3가지를 가집니다.
- 일반적인 분류기에 적용할 수 있다!
- 컴팩트하다!
- domain adaptation을 할 때 좀 더 적절하다.
고정된 크기를 얻기 위해 Fisher Vector나, VLAD와 같은 간단한 방법론도 고려해서 실험했다고 합니다. 문제는 성능이 안나와서… future work로 남겨두고 여기서는 더 간단한 방법을 이용했다고 합니다.
First, second order and ordinal statistics & Feature normalization
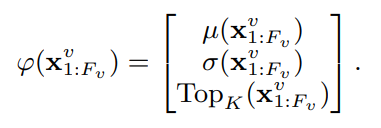
ϕ는 feature vector를 뜻합니다. X_{1:F_v}^v는 X_j^v ∈ R^{1024}일 때의 frame-level feature입니다. µ는 평균이고, σ는 표준편차입니다. Top_k는 전체 비디오의 j번째 feature-vector의 p번째 높은 값이 포함하고 있는 p번째 차원에서 K 차원 벡터입니다. 이게 결국은… 이 ordinal statistics라는 방법으로 특정 벡터를 뽑는데요. 이 비디오의 통계적인 특성을 반영한 feature vector를 뽑는 듯 합니다. 여기에 SGD 와 같은 방법을 이용할때 좋은 영향을 주기 위해, PCA와 정규화도 적용해주었다고 합니다.
Models from Video Features
주어진 video-level representations를 이용해서, 각각의 label에 binary classifier를 독립적으로 학습했다고 합니다. 문제는 라벨이 많기 때문에 학습 하는 것 자체가 문제입니다. 학습을 위해 있는, 6백만개의 비디오를 SVM 같은 방법으로 학습하는건 어렵습니다. 그래서 adagrad와 batch-size를 매우 작게 해서 학습을 하는 online 학습 알고리즘을 사용했다고 합니다.
Logistic Regression
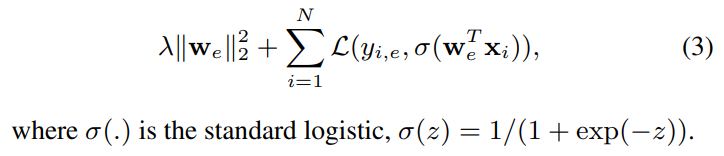
video-level feature의 표준편차 값 σ이 entitiy e의 확률 p(e|x)로 주어질때, w는 전체 log-loss를 줄이기 위해 위와 같이 수행된다고 합니다.
Hinge Loss
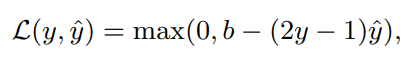
y는 GT y hat은 예측 값입니다. b는 hinge-loss 파라미터라고 합니다. 여기서 max 함수가 있기 때문에 도함수에 불연속성이 생겨서, 수렴 속도가 느려진다고 합니다.
Mixture of Experts (MoE)
정말 처음 보는 개념이라 검색해봤더니, 기계학습에서 사용하는 방법론이라고 하는데, 다수의 expert network를 이용해서, problem space를 균일한 공간으로 나눠 학습하는 방법이라고 합니다. 학습하는 수식이 많은데, 요약해보면 학습해야할 label 자체의 수가 많으니 여러 머신에서 분산 처리해서 학습할 수 있도록 이런 구조를 사용하는 것 같습니다.
Expriments
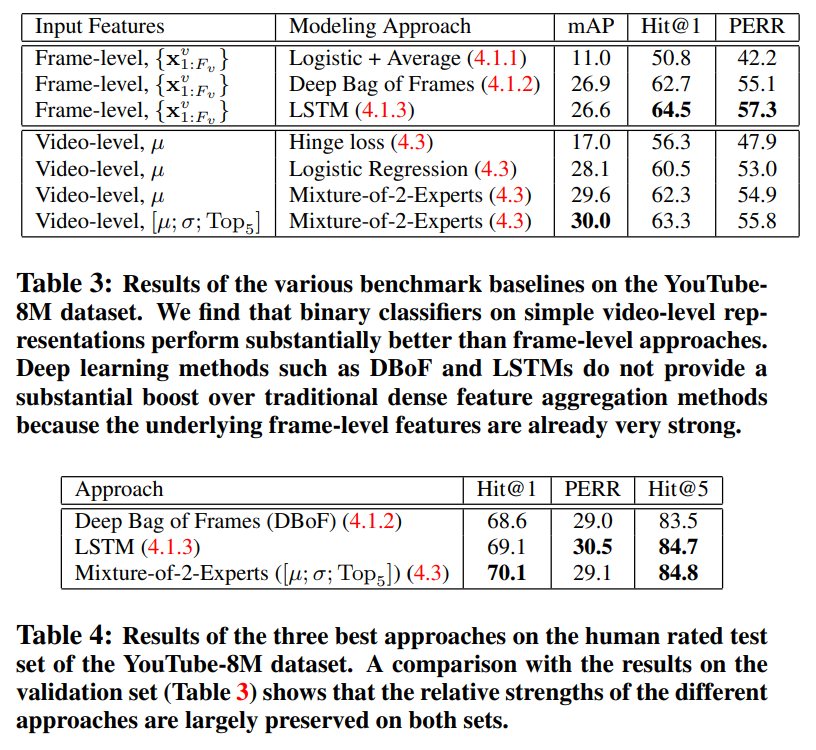
실험 결과를 보면, 역시 video level feature를 이용한 방법론들이 생각보다 높은 정확도를 가지고 있습니다.
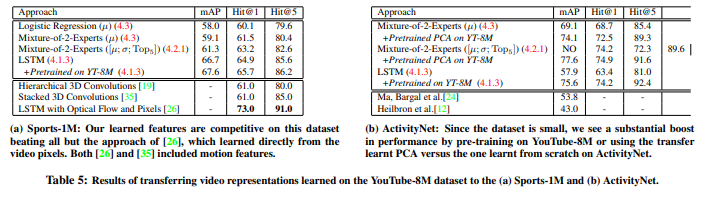
action 중심이기는 하지만, 기존의 존재하던 대용량 비디오 데이터셋에서의 성능을 비교해봐도 꽤 좋은 성능을 보입니다. 물론 이 성능들은 모델의 성능을 평가했다기 보다는, 전이학습에서의 성능을 비교한 것입니다. Youtube-8M 데이터셋이 ImageNet과 같은 역할을 수행하기를 기대했다고 서론에 밝혔는데, 이 역할을 잘 수행할 것임을 보여주기 위해 수행한 실험 같습니다.
결론
비디오 데이터셋은 어떻게 만들었을까는 내용과 video classification에 대한 내용을 알아가려고 읽은 논문인데, 딥러닝 기반의 Video classification에 대한 내용을 조금 더 읽어 봐야할 것 같습니다. 아무래도 처음 보는 개념들이 많이 등장하다 보니 어렵네요.
좋은 리뷰 감사합니다.
중간에 리뷰를 읽다 궁금한 점이 있는데, 혹시 quantization이 무슨 방법이길래 비디오에서는 안쓴다고 생각하셨나요?
그리고 해당 데이터는 공개를 할까요 ? 만일 그렇다면 광진님이 하고 계신 연구에 적용은 어떻게 하실예정일까요 ?
파일 크기도 줄이고, 연산량도 줄이기 위해 사용하는 방법론인데, float와 같이 작은 값을 int형으로 바꿔주는 방법이라고 생각하시면 될 것 같습니다. 사실 안쓴다고 생각한 큰 이유는 없고, 비디오 논문들에서 사용한걸 본적이 없어서 안쓰나 싶었습니다. (최근에 ViSiL 저자가 논문에 적용했길래 찾아보니 쓰는 곳이 있긴 하더라고요.) 그리고 데이터셋은 다운은 받을 수 있습니다. 매년 챌린지도 하더라고요? 다만, 백본 모델에서 Howto100M 같이 학습된 pretrained weight를 받아서 쓰는 방법을 더 일반적으로 쓸 것 같습니다. 원본 데이터는 워낙 크니까요. 제 연구에는 흠… 잘 모르겠습니다! video classification이 도움될 것 같다는 판단을 해서 읽었는데 아직은 어려워서 추가 논문을 읽어봐야 알 것 같습니다!