읽기 전에
이번에 리뷰할 논문은 Unsupervised Domain Adaptation for 3D Object Detection 입니다. 해당 논문을 읽게된 계기는 3D Detection에서는 Domain Adaptation이 없을까? 라는 궁금증에서 였으며, 결과론적으로 제가 논문을 읽기전에 상상했던 DA하고는 좀 많이 다른 방법인거 같습니다.
해당 논문을 읽기전에 제가 생각했던 DA는 Gradient reversal layer를 통해서 discriminator가 domain을 잘 구별 못하는 방향으로 학습을 하는 것 이었는데, 해당 논문에서는 semantic point generation (SPG)을 통해 DA를 합니다. 해당 방법에 대해서는 뒤에서 다루겠습니다.
논문리뷰
[ICCV 2021] SPG: Unsupervised Domain Adaptation for 3D Object Detection via Semantic Point Generation
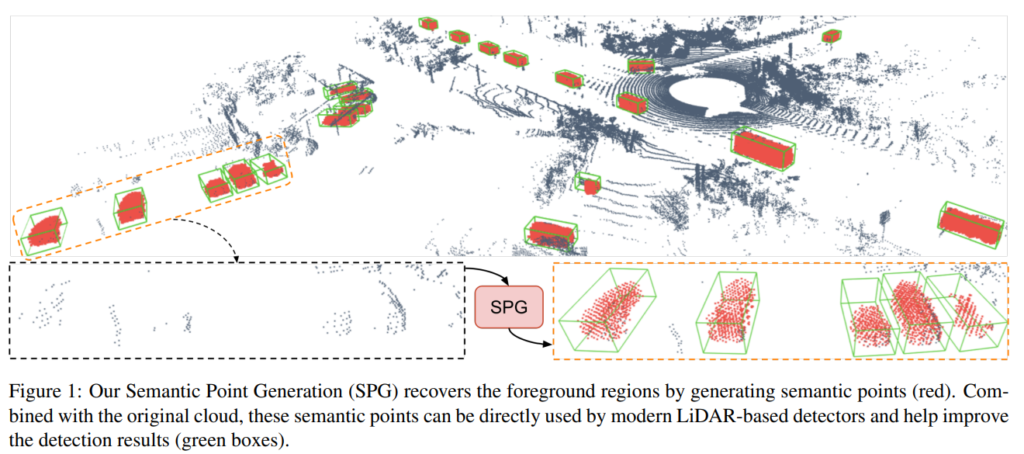
해당 논문에서는 포인트클라우드 데이터를 이용한 3D detection에서의 Domain adaptation에 대해서 다룹니다. 그 과정에서 위의 그림과 같이 SPG (Semantic Point Generation) recovery과정을 통해 semantic point의 개수를 늘려서 사용합니다.
해당논문에서 궁극적으로 하고자하는 목표는 Domain Adaptaion으로, source 도메인으로 부터 학습을하고, target 도메인에서 테스트를 하였을때도 잘 working하는 모델을 설계하는 것 입니다.
위에서 한 말들을 정리하자면, 해당 논문에서는 source도메인에서 학습을 하고, 처음보는 데이터인 target 도메인에서도 잘 working하는 모델을 설계하기위해 semantic 정보를 담고있는 point들을 생성해주는 모델을 추가적으로 사용하여 3D Detection을 수행합니다.
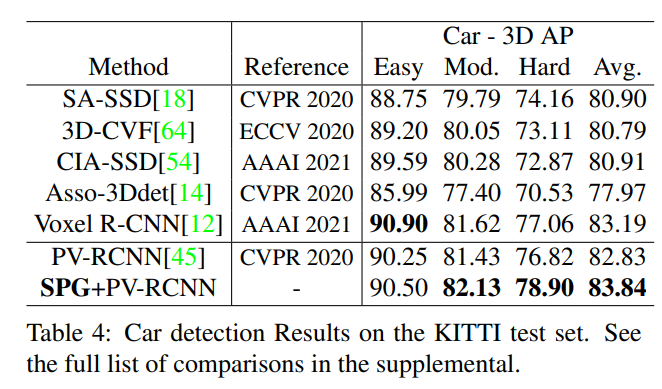
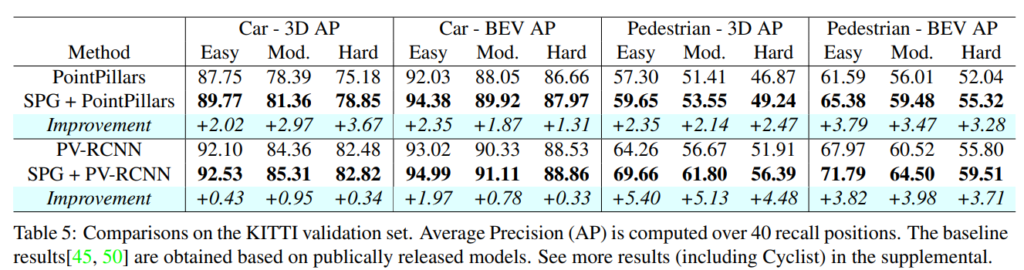
해당 내용을 증명하기 위해서 해당 논문에서는 3D detection 방법론중에서 최신 main stream에 해당하는 PointPillars와 PV-RCNN 방법론에 각각 제안하는 SPG 모듈의 적용전/후의 성능을 비교합니다.
또한, 데이터셋으로는 Waymo Domain Adapatation Dataset과 KITTI Dataset을 사용하였으며, KITTI에서는 Generality를 위해서 평가 해본 것 같고, 핵심은 Waymo Domain Adapatation Dataset입니다. 그 이유는 Waymo Domain Adapatation Dataset은 조금 특이한 구성을 가지기 때문입니다.
Waymo Open Dataset (OD) is mainly collected in California and Arizona, and Waymo Kirkland Dataset (Kirk)
[49] is collected in Kirkland. We consider OD as the source domain and Kirk as the target domain.
그 이유는 위의 원문과 같습니다. Waymo Domain Adapatation Dataset은 촬영된 지역에 따라서 OD데이터셋과 Kirk데이터셋으로 나뉘며, 전체적인 bbox의 스케일은 비슷하지만, gemetry 조건과 날씨환경 등에서 서로 상이한 도메인을 가집니다.
해당 두 데이터셋 사이에 존재하는 가장 큰 domain gap은 날씨로, Kirk 데이터셋에서는 데이터셋의 98퍼센트정도가 비오는 환경에서 촬영되었고, OD데이터셋에서는 이와 반대로 99프로정도 dry한 환경에서 촬영되었습니다.
비가오는 환경에서 라이다포인트는 missing이 발생하고, 실제로 두 데이터셋에 존재하는 라이다포인트 density를 고려해보면 rainy weather condition에서 촬영된 Kirk 데이터셋에서는 포인트클라우드 density가 약 30%정도 낮은 경향을 보입니다. 이러한 문제를 해당 논문에서는 “missing point”라고 정의하며 degradation을 일으킨다고 주장합니다.
즉, 결과론적으로 해당 논문에서는 이러한 missing point를 mitigate하는 방법을 고안하였으며, 그것이 바로 위에서도 언급하였던 SPG (Semantic Point Generation) 모듈입니다. Rainy weather condition에서는 missing 된 point가 있으니 missing된 포인트를 다시 살려보자. 라는 의미에서 시작된 연구라고 보시면 됩니다.
ICCV에 Accept될 수 있었던건 해당 논문에서 제안하는 SPG 모듈의 generality 때문이라고 생각합니다. 꼭 Rainy한 weather condition이 아니더라도 일반적인 환경에서도 해당 모듈을 사용하면 성능향상이 있다는 것을 확인할 수 있습니다.
자 그럼 방법론을 살펴봅시다.
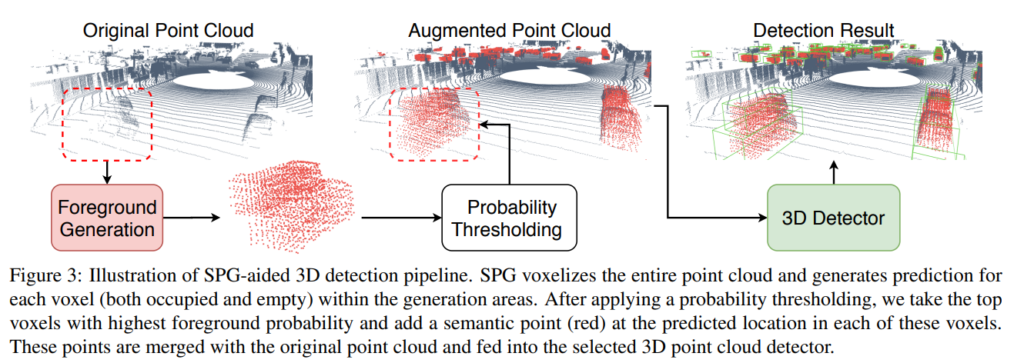
위의 그림은 개략적인 프레임워크를 보여주며, 생각보다 간단하며, 이해하기 쉽습니다. 포인트클라우드 데이터가 있으면 labeled 3D bbox의 정보를 이용하여 foreground와 background를 구분할 수 있습니다. 다른말로 하자면, 정답값인 3D bbox 정보를 알고 있다는 것은 foreground/background 인지에 대한 정답값도 알고 있음을 의미합니다.
이러한 점에서 착안하여, 해당 논문에서는 voxel단위로 foreground와 background를 구분하는 모델을 사용합니다. 그리고 foreground일 probability가 높은 voxel들로 부터 semantic point를 추출하고 해당 semantic point들을 original 포인트클라우드 데이터에 추가하여 3D Detector에 인풋으로 넣어줍니다. 그리고 해당 3D Detector에서는 일반적인 포인트클라우드 based 방법론처럼 3D Detection을 수행합니다.
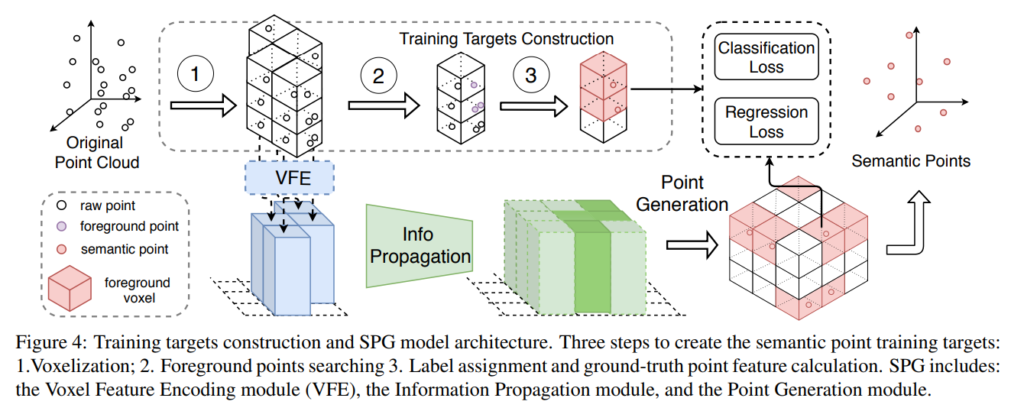
좀 더 자세히 구체적인 방법을 알아봅시다.
1. Training Targets Construction
위의 그림에서 Training Targets Construction에서는 1. Voxelization, 2. Foreground Points Searching, 3. Label assignment and ground-truth point feature calculation. 으로 나뉩니다. raw 포인트클라우드 데이터가 있으면 voxel화 한다음, 3D bbox정보를 기준으로 foreground voxel인지 여부를 구합니다. 이후 복셀마다 Label을 assign해주고 해당 레이블을 정답값으로 모델을 학습하는데 사용합니다.
2. Model Structure
먼저 그림 4에 나와있는 VFE 모듈에 대해서 소개해드리겠습니다. 해당 VFE모듈은 voxel마다 효율적으로 feature를 추출하기 위해 사용되는 방법으로 VoxelNet에서 처음 사용하였습니다. 내용이 좀 복잡한데 밑에내용이 이해가 안되시면 세미나때 자세히 설명해드릴테니 참고하세요.
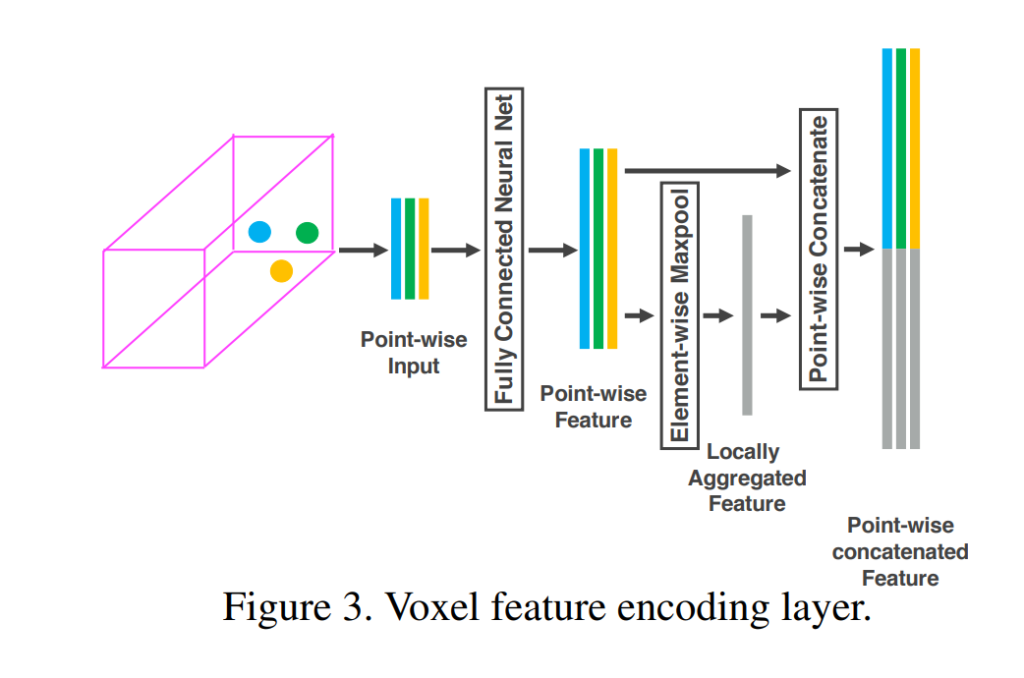
Raw 포인트 클라우드 데이터를 voxel화 한다음 Voxel마다 피쳐를 추출하기 위해서는 위의 그림에서와 같은 방법을 사용합니다. 해당 그림은 1개의 voxel에 존재하는 3개의 point들로 부터 피쳐를 추출하는 과정의 일부가 설명되어 있습니다. 먼저 3개의 point들은 random sampling 과정을 통해서 선정된 point들 입니다. Voxel내에 존재하는 모든 점들에 대해서 feature를 인코딩하면 computation cost가 크기 때문에 random sampling방법을 사용한다고 합니다. 아무튼 Voxel feature를 저러한 3개의 point들로 부터 어떻게 추출할까요?
먼저 한개의 point는 x, y, z 좌표와 강도를 나타내는 reflectance를 가지고 있습니다. 또한 우리는 Voxel의 center좌표를 알고 있습니다. 이러한 정보를 이용하여 1개의 point가 가지는 정보를 7가지로 늘려줍니다. 즉, 각 voxel들에 존재하는 point들로 부터 x,y,z좌표와 voxel center와의 거리, reflectance로 구성된 7차원의 point-wise 벡터를 추출합니다. 위의 그림에서는 3개의 점에 대해서 7차원을 가지는 3개의 point-wise vector를 추출하였습니다.
이제 해당 point-wise vector를 MLP 레이어를 통과시켜 point-wise 피쳐로 변환해줍니다. 그리고 element-wise max-pooling을 한다음 해당 값을 각각의 point-wise 피쳐에 concatenate 해줍니다. 그럼 최종적으로 위의 그림과 같이 3개의 point-wise 피쳐를 구할 수 있습니다.
결과론적으로 본다면, 3개의 point를 인풋으로 넣었고, 3개의 point-wise 피쳐를 output으로 리턴받았습니다. 이제 해당 3개의 point-wise 피쳐를 voxel-wise 피쳐로 변환하기 위해서 좀 더 가공할 차례입니다.
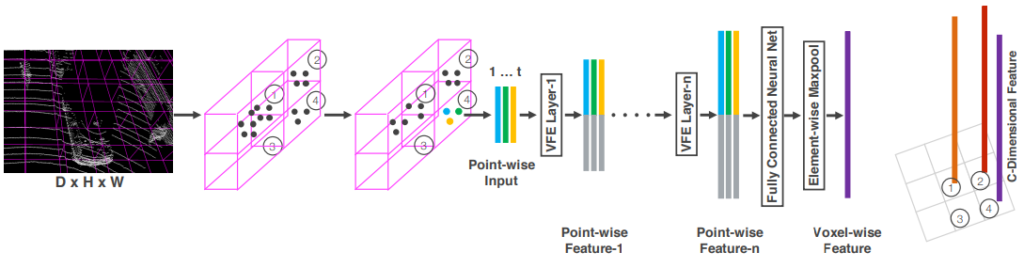
3개의 point-wise 피쳐는 위의 그림과 같이 n개의 VFE레이어를 거치고, 좀 더 high-level의 피쳐로 변환됩니다. 이후, element-wise maxpool을 적용하여 Voxel-wise feature로 변환하고, 그림에서는 총 4개의 voxel에 대해서 4개의 voxel-wise 피쳐를 최종적인 output으로 얻었습니다.
드디어… Voxel-wise 피쳐를 추출하는 방법에 대한 설명을 마치었습니다. 다시 논문으로 돌아와서 설명을 이어가겠습니다.
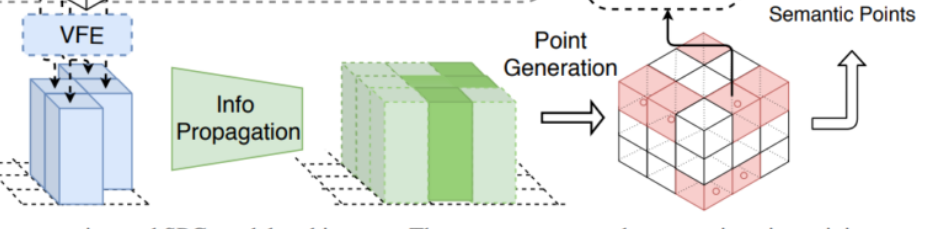
설명이 길어지다보니 설명과 그림 매칭이 어려울거 같아서 논문 그림4 일부를 캡쳐해왔습니다. 여태까지 VFE모듈로 voxel-wise (pillar)피쳐를 추출하는 방법에 대한 설명을 했습니다.
이렇게 추출된 voxel-wise 피쳐에는 Info Propagation과 Point generation과정이 추가적으로 진행됩니다.
Info. Propagation 과정에서는 foreground pillar 피쳐 (진한녹색) 주변에 missing point로 추정되는 pillar (연한녹색)을 채워넣을수 있도록 정보를 전달하고, Point Generation 과정에서는 Pillar 피쳐로부터 다시 voxel내에 존재하는 point들의 co-ordinates와 properties, foreground score를 regression합니다. 즉, 원래 인풋으로 주어졌던 raw point cloud 데이터에 missing point가 어느정도 채워진 recover된 point들을 반환합니다.
그렇다면 Foreground Region Recovery에 대해서 좀 더 자세히 다루어 보겠습니다.
Foreground Region Recovery
Foreground Region Recovery는 크게 Hide and Predict, Semantic area expansion 2가지로 구성됩니다.
1. Hide and Predict
먼저 Hide and Predict 입니다. 해당 과정에서는 voxel 일부를 random하게 선택하고 해당 복셀에 해당되는 point들을 모두 hide합니다. 이때 hide하는 정도는 하이퍼파라미터로 해당논문에서는 Ablation study를 통해 25%로 선택하였습니다. 이렇게 하면 실제 missing point가 발생하는 상황을 그냥 random point selection하여 hide하는 것보다 좀 더 사실적으로 묘사할 수 있다고 합니다. 아마도 missing point가 비오는 환경에서 발생하는데, 빗방울이 라이다센서 기준에서는 크기 때문에 missing point도 voxel단위로 발생하지 않나 싶습니다.
2. Semantic Area Expansion
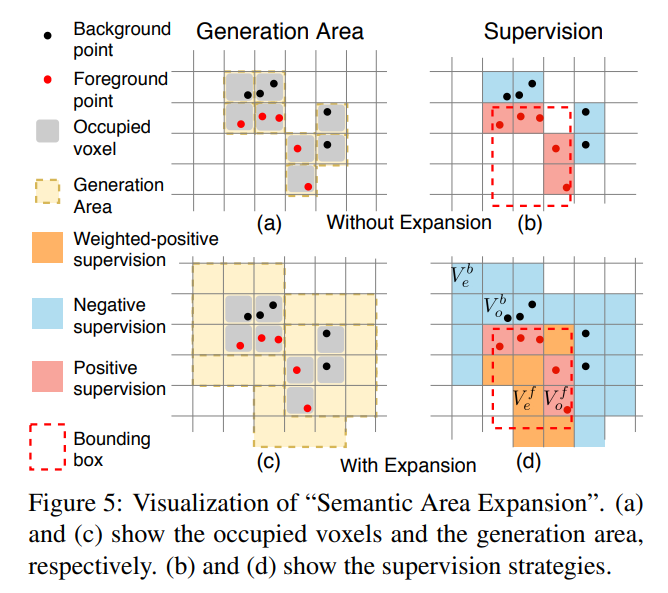
해당 과정에서는 위의 그림과 같이 voxel을 4가지로 구분합니다.
- Foreground / occupied
- Foreground / empty
- Background / occupied
- Background / empty
그리고 3~4 번 같은 경우에는 label을 0으로주고, 1번은 1로, 2번은 0~1사이의 값을 주었습니다.
그냥 나이브하게 foreground인 경우에만 1로 주고 나머진 다 0으로 주는 것보다 foreground이지만 empty voxel인 경우에는 0~1사이의 값을 준 것 (expansion) 이라고 생각하면 될거 같습니다.
평가
이제 평가에 대해서 이야기 해보겠습니다.
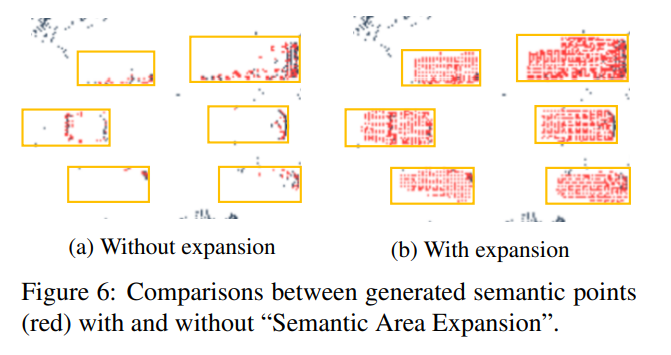
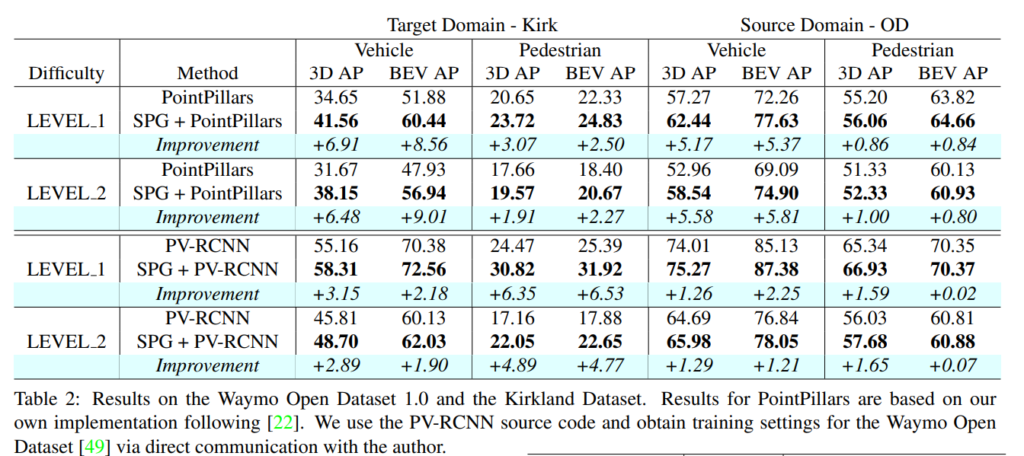
실제로 SPG과정을 통해 recovery하였을 때 point들이 많이 복원되었으며, 특히나 Expansion 기법을 적용했을때 더 많이 복원이 되었습니다.
아래 결과들에 대해서는 해당리뷰 앞부분에 실험세팅에 대해서도 논문의 전반적인 흐름을 소개하며 자세히 적어놓았으니 참고해보시기 바랍니다.

결론
해당 논문에서 제안하는 방법론을 이용하여 missing point들을 복원하여 사용하면 일반적으로 3D detection성능이 향상되고, unseen data에 대해서도 성능이 잘 나온다는 것이 핵심 컨트리뷰젼인 논문이었습니다.
아쉬운점:
- Domain Adaptation이라고 하기에는 좀 부족하지 않나 싶습니다.
- 평가데이터셋의 class 카테고리가 너무 단조롭습니다. 아마도 class 카테고리를 여러개 사용하면 잘 working안하기 때문인거 같습니다.
- 과연 성능이 오른게 class 카테고리가 적어서 모델이 해당 카테고리에 오버피팅된건지 아니면 정말로 일반적으로 성능이 오르는건지 의심이 갑니다. 특히 KITTI 데이터셋에서는 과연 해당 모델들을 기존에 multiple 카테고리에서 성능을 보인 모델과 비교하는게 맞는가 싶습니다. 차라리 KITTI데이터셋에 대한 실험결과를 아예 빼는게 맞지 않았나 싶습니다.
- Missing point를 generation하는 방법이 voxel단위로 적용되는데 weather에 의한 missing 데이터가 존재하는 경우에만 해당 방법이 더 좋지 않을까 싶습니다. Self-occlusion이나 external-occlusion등에 대해서도 과연 missing point를 저런식으로 generation하는게 맞을까요?
여러모로 헛점이 많은 논문이라고 생각하는데 해당 논문을 리뷰한 리뷰어들이 남긴 코멘트가 궁금하네요.
흥미로운 방법론이라 재미있게 읽었습니다.
제 생각엔 LiDAR의 Point cloud 이용한 Domain Adaptation으로는 적절하다고 생각합니다. 도시 환경도 다르며, 무엇보다 날씨가 다른 상황의 데이터간 adaptation이기에 Point cloud 측면에서는 가장 적합하지 않을까 생각합니다. 더 좋은 경우가 있을까요?
저자가 Self-occlusion이나 external-occlusion에서도 강인하다는 주장을 했나요? 있다면 생성한 정성적인 결과가 궁금하네요.
그리고 OD 데이터 셋에서 PointPilar 외에 다른 방법론의 실험이 있는지 궁금합니다. 통상적으로 weather에 의한 성능 드랍이 어느 정도 일어나는지 궁금하네요.
1. 아무래도 3D쪽에서는 Domain Adaptation 연구가 많이 없는거 같습니다. 그래서 더 좋은 연구가 있는지는 미지수 입니다.
2. self-occlusion / external-occlusion에 대한 내용은 해당 논문에서 다루고 있지 않습니다. 제가 언급한 이유는 missing point가 발생하는 이유가 꼭 weather condition이 아니기 때문이며, 해당 논문에서는 그러한 점을 다루지 않았다고 지적하기 위해서였습니다.
3. 모든 데이터셋에서는 PV-RCNN / Point Pillar 2개의 방법론을 사용해서 비교합니다. 제가 리뷰에는 빠트린거 같은데 논문을 참고해보세요.