이번 논문은… 논문이 나온지 일주일도 안된 따끈따끈한 논문입니다. 김지원연구원님이 추천해줘서 읽게 됐는데, 매우매우 좋은 실험과 분석이 담긴 논문이라서 너무 재밌게 읽었습니다. 좋은 내용을 온전히 담아보고자 리뷰에도 힘을 꽉 주고 쓰는 바람에 리뷰 내용이 좀 길어지긴 했는데, 그래도 한번 쭉 정독하시면 앞으로의 연구에서 어떤식으로 모델을 설계할지에 대해 큰 도움이 될 것이라고 생각합니다.
참고로 리뷰 내용이 너무 길어서 읽을지 말지 고민하시는 분들을 위해 해당 논문을 한줄로 요약하자면, “Transformer가 CNN보다 좋다고 하지만 이는 시대적 차이로 인한 결과이며 최신기술?을 적용한 CNN은 Transformer와 동등하거나 그 이상.” 이라는 내용을 주장 및 증명하는 논문입니다.
Introduction
논문의 시작은 CNN의 과거에 대해 시작하는데 사실 뭐 그렇게 중요한 부분은 아닙니다. 그냥 2010초반 CNN이 나오면서 인공지능 시대의 르네상스 시기가 왔다! 라는 내용들이 적혀있는데 관심있으신분들은 논문을 직접 읽어보시면 좋을 듯 합니다.
아무튼 저자는 CNN이 다양한 Vision task에 잘 동작하는 것이 우연이 아니라고 얘기합니다. Convolution의 가장 대표적인 특징 “sliding window” 전략은 시각처리를 하는 관점에서 매우 잠재력이 뛰어나다고 합니다. 가장 먼저 컨볼루션의 가장 중요한 특징 중 하나는 바로 Translation equivariance입니다.
Translation equivariance에서 먼저 equivariance에 대해 설명하자면 함수의 입력이 바뀌면 출력 또한 변한다는 의미이며, 결론적으로 translation equivariance는 입력의 위치가 변하면 출력값도 동일하게 위치가 변한다는 것을 의미합니다.
이건 너무 당연한 내용이라 어려움이 없을 듯 한데, 결국 영상 속 A라는 물체가 좌상단에 있을 때와 우하단에 있을 때에 따라 컨볼루션 레이어를 통과하여 나온 feature map의 값 역시 바뀐다는 점입니다. 이러한 특징은 object detection과 같이 영상 속 물체의 위치관계를 중요하게 여기는 분야에서 더더욱 빛을 발휘하는 것이죠.(사실 이미지 분류를 제외하고는 대부분의 비전 분야들이 위치관계가 중요합니다.)
그리고 두 번째로 중요한 특징은 바로 sliding-window 기법을 활용해 매우 효율적이다 라는 것입니다. 뭐 이러한 특징 덕분에 고해상도 이미지도 잘 처리하며 모델의 크기도 적당히 줄일 수 있는 것이겠죠.
아무튼 이렇게 CNN은 2010년 초반부터 매우 강세를 떨치며 컴퓨터 비전 분야에서 없어는 안될 존재가 되는 반면, NLP 분야에서는 스멀스멀 새로운 강자가 나타납니다. 바로 Transformer 모델이죠. Transformer Model은 RNN, LSTM과 같은 기존 NLP 분야에서의 근본 모델들을 성능으로 압도하며 매우 큰 강세를 보이고 있었고, 결국 2020년 Computer Vision 분야에도 Transformer가 등장합니다.
ViT는 no image-specific inductive bias, 그리고 Multi Head Self-Attention(MHSA)을 활용해 ResNet과 비교하여 엄청난 성능 차이를 보여주었습니다. 하지만 그 당시 나온 ViT도 단점은 명확했습니다. NLP 분야에서 처음 나온 Transformer의 구조를 거의 온전히 사용하였기 때문에, 다양한 비전 분야에 접목시키기에는 명확한 한계들이 존재했던 것입니다.
그 중 가장 대표적인 예시로는 바로 연산속도입니다. 문장 속 단어의 수와 비교하여 영상 속 픽셀은 매우 다른 규모의 해상도 차이를 보여주고 있습니다. 물론 픽셀 단위가 아닌 패치 단위로 영상을 쪼개서 단어로 보고 있긴 하지만, 그럼에도 불구하고 MHSA 연산을 수행하기에는 큰 무리가 있는 것입니다.
게다가 영상 해상도가 224×224 또는 기껏해야 384×384밖에 안되는 ImageNet과 달리 Object Detection, Semantic Segmentation 등의 분야에서는 최소 512에서 최대 2048의 해상도를 사용하는데 이러한 분야에서 ViT를 사용하기에는 거의 불가능에 가까웠습니다.
이러한 상황에서 계층적 구조의 트랜스포머 방법론(Hierarchical Transformer)들이 등장하여 ViT와 CNN의 갭을 줄이는 역할을 수행했습니다. 예를 들어, 기존의 전체 Feature map에 대해 Global MHSA을 수행했던 ViT와 달리, Swin Transformer는 CNN의 가장 큰 특징인 “Sliding Window” 방식을 적용한 Local MHSA을 사용하며, Feature map의 크기 역시 ViT처럼 항상 일정하지 않고 점진적으로 다운샘플링되는 계층적인 구조를 지니게 됩니다.
이러한 Swin Transformer는 순식간에 분류 분야 뿐만 아닌 Object detection, Semantic segmentation 등등 다양한 비전 분야에 잘 적응하여 최첨단의 성능을 보여주었습니다. 저자는 이러한 Swin Transformer의 성공과 다양한 분야에서의 빠른 적응 속도를 보며, 컨볼루션의 컨셉과 정수는 아직 죽지 않았다..! 라며 컨볼루션에 대한 매우 큰 애정과 지지를 표현합니다ㅋㅋ.
이러한 관점에서, 컴퓨터비전 분야에서 Transformer를 발전시키려는 연구 방향 중 일부는 다시 컨볼루션의 개념으로 돌아가고자 합니다. 하지만 이러한 시도들은 너무 많은 비용이 들었는데, 예를 들어 단순하게 sliding window 방식의 self-attention 구현은 매우 expensive하였으며 그나마 cyclic shifting과 같이 더 진보된 방식은 설계에 매우 큰 정교함이 필요로 한다고 합니다. (약간 related work 느낌으로 설명하는 부분인데 요약하자면 단순히 Transformer의 컨셉을 CNN에 적용하기에는 큰 무리가 있다는 것 같습니다.)
저자는 CNN이 힘을 잃어버리는 것 같아 보이는 가장 큰 이유는 바로 Transformer가 다양한 비전 분야에서 압도적인 성능 차이를 보여주고 있다는 것이며, 이러한 CNN과 Transformer의 성능 차이는 바로 Transformer의 MHSA으로 인한 superior scaling behavior of Transformers 때문이라고 합니다.
지난 십년동안 점진적으로 성능 향상을 보여왔던 CNN과 달리, ViT의 적용은 매우 큰 변화(step change)에 해당했습니다. 최근 논문들을 보면, Swin Transformer vs ResNet과 같은 시스템 레벨에서의 비교가 매우 빈번하게 발생하고 있습니다. (저도 이걸로 논문 썼으니 부정할 수는 없군요 호호)
CNN과 Hierarchical vision Transformer는 서로 다르면서도 동시에 유사한 부분이 존재하는데, 이 둘은 모두 유사한 inductive biases를 가지면서 동시에 학습 과정 내에서 매우 큰 차이가 있으며 모듈의 구조적 설계가 크고 작게 존재합니다.
그래서 저자는 해당 논문을 통해 CNN과 Transformer의 구조적 차이를 구분하고 두 네트워크 간에 성능을 비교할 때 혼란스러운 변수들을 명확하게 하고자 한다고 합니다. 즉 저자는 ViT가 나오기 이전(pre-ViT)과 이후(post-ViT) 시대의 차이를 줄이기 위한 연구라고 보시면 될 것 같습니다.(저자도 직접 그렇게 말하고 있습니다.)
이를 위해서 먼저 저자는 standard ResNet을 시작으로 계층적 구조의 트랜스포머 설계에 맞게 네트워크 구조를 점진적으로 현대화(modernize)? 시키려고 합니다. 해당 실험이 성공하기 위해서는 가장 먼저 트랜스포머 내 설계 결정을 어떻게 해야만 CNN의 성능에 영향을 줄 수 있을지 고민해보아야 합니다.
뒤에서 더 자세히 설명하겠지만 결과를 먼저 말하자면 저자는 성공적으로 디자인을 하여 ConvNeXt를 제안하였으며, 이는 이미지넷 분류, COCO object detection/segmentation, ADE20K semantic segmentation 등 다양한 비전 분야에서 Transformer와 버금가는 성능 향상을 보였다고 합니다.
게다가 ConvNeXt는 기존의 CNN의 효율성을 유지하고 있으며, Fully-Convolution 특성 덕분에 학습과 실험 과정에서 구현이 매우 단순하다고 합니다.
Modernizing a ConvNet : a Roadmap
이번에는 저자가 어떤 구체적인 목적을 가지고 실험을 진행할 것인가에 대해 알아보겠습니다. 위에서도 살짝 언급했지만, 저자가 하고자 하는 것은 CNN을 구조적 관점에서 Transformer와 유사하게 만들면서 동시에 순수하게 컨볼루션 레이어만으로 구성하고자 하는 것입니다.
저자는 이러한 실험을 하기 위해서 ResNet-50과 Resnet-200을 사용하는데, 각 모델은 4.5 \times 10^{9}, 15.0 \times 10^{9} FLOPs을 가지고 있으며 이는 정확한 성능 비교를 하기 위해 Swin-T와 Swin-B의 FLOPs과 동일하게 맞춘 것이라고 합니다.
일단 실험 과정에 대한 설명에서는 편의를 위해 ResNet-50에 대해서만 나타내고자 합니다. 저자는 이미지넷 분류 실험에서 ResNet-50 모델에 대하여 먼저 Transformer 방법론들이 사용했던 학습 기법들을 유사하게 적용하였으며, 이 결과 original ResNet-50보다 더 우수한 성능을 달성했다고 합니다.( 76.13 \rightarrow 78.82 ) 저자는 이 78.82 성능을 가지는 ResNet-50을 베이스라인으로 설정하였습니다.
그 이후에는 대략적으로 5가지의 관점으로 모델의 성능 실험을 수행하였는데, 각각의 관점은 아래와 같습니다.
- macro design
- ResNeXt
- inverted bottleneck
- large kernel size
- various layer-wise micro designs
그림1은 위에서 언급한 5가지 관점으로 저자가 실험을 하였을 때 성능이 어떻게 변화하는지에 대하여 그림으로 나타낸 것입니다. 참고로 모든 실험의 학습과 평가는 ImageNet-1K로 진행되었습니다.
Training Techniques
제가 방금전에 저자가 베이스라인으로 설정한 ResNet은 Transformer 방법론들이 사용했던 학습 기법들을 추가로 적용한 버전이라고 했습니다. 해당 섹션에서는 이에 대해 조금 더 자세히 설명하겠습니다.
먼저 저자는 CNNs(이 논문에서는 ResNet)과 vision Transformers들 간에 성능 차이가 단순히 모델/모듈의 구조적 차이 뿐만 아니라 학습 방법(예를 들면 Transformer방법론들은 AdamW optimizer를 사용)의 차이도 있을 것이라고 가정하였습니다.
그래서 먼저 베이스라인으로 설정할 ResNet 모델을 그 당시 학습 기법이 아닌 Transformer들이 적용했던 최신 학습 기법을 동일하게 적용하고자 하였으며, 저자는 그중 DeiT와 Swin Transformer의 training recipe를 사용했다고 합니다.
학습 기법에 대한 대략적인 설명은 아래와 같습니다.
- Extend to 300 epochs from the original 90 epochs
- Using AdamW optimizer comparison with Adam
- Using Various Data Augmentation(Mixup, Cutmix, RandAugment, Random Erasing)
- Using regularization schemes(Stochastic Depth, Label Smoothing)
그 외에도 이것저것 하이퍼파라미터 세팅을 변경하여 학습시켰더니 최종적으로 기존의 ResNet-50의 성능인 76.1% 보다 2.7% 더 향상된 78.8% 성능을 달성했다고 합니다. 저자는 위의 training recipe를 고정하여 실험을 진행하고자 하였으며 이러한 과정도 CNNs에 대한 modernization의 한 과정을 수행했다고 말합니다.
Changing stage computer ratio
Original ResNet의 설계 자체는 매우 경험적으로 구성되어있습니다. 조금 더이해를 쉽게 하기 위해 ResNet50과 Swin-Transformer의 구조를 먼저 보도록 하겠습니다.
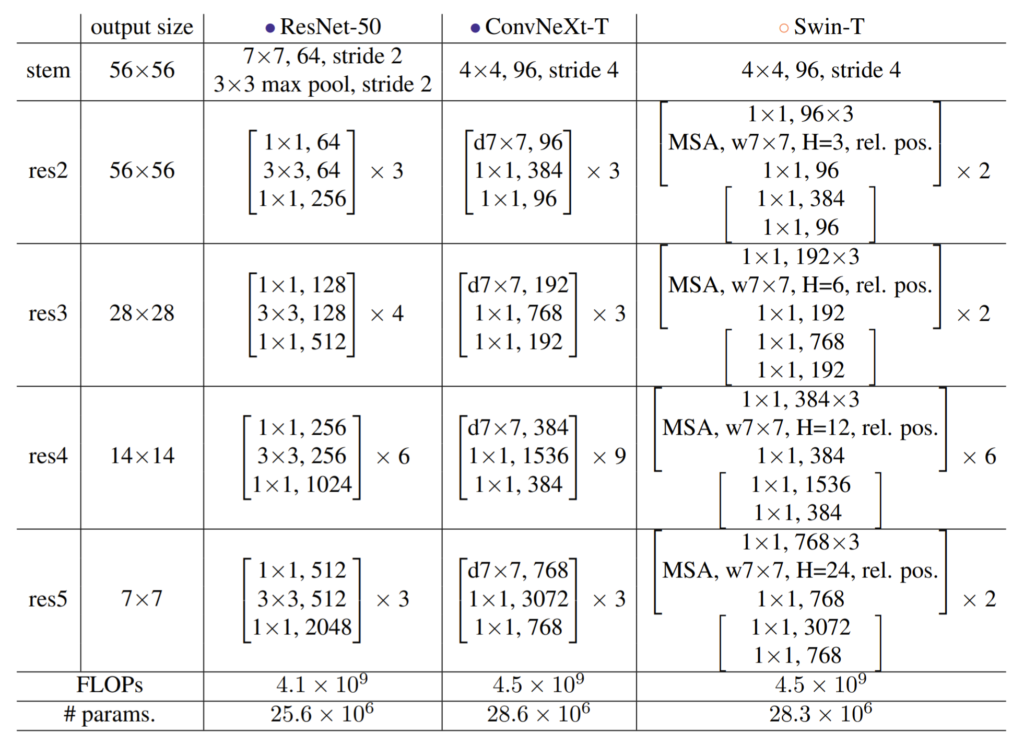
표1 중 ResNet-50은 각 스테이지별로 블록의 개수가 [3, 4, 6, 3]으로 딱히 경향성이나 규칙성이 없어보이는 반면에, Swin-T의 경우 [2, 2, 6, 2]로 1:1:3:1 비율을 가지는 것을 확인할 수 있습니다. 저자가 말하기로는 ResNet의 경우 object detection과 같은 downstream task에서 detector head는 14×14 feature를 입력으로 받아야 동작하기 때문에 이러한 테스크에 맞춰져서 설계된 것이다라고 말을 하는데… 사실 이 부분은 무엇을 말하고자 하는지 잘 모르겠습니다.
아무튼 저자는 ResNet을 Swin과 동일한 비율을 가지는 구조로 만들고자 하였고, 최종적으로 각 스테이지별로 [3, 3, 9, 3]개의 블록을 구성하였습니다. 이는 ResNet-50이 Swin-T와 유사한 FLOPs을 가지도록 하면서 스테이지 별 블록의 비율이 맞도록 한 것이라고 합니다. 아무튼 이러한 변경을 통해 기존 성능 78.8% 대비 0.6% 향상된 79.4%를 도달하였습니다.
Changing stem to “Patchify”
일반적으로, stem이라는 모듈은 네트워크의 가장 앞부분에 존재하여 입력 영상에 간단한 컨볼루션 연산을 수행해주는 전처리 모듈이라고 보시면 됩니다. 이러한 stem 모듈은 자연입력 영상의 중복성을 최소화하고자 입력영상 자체를 점진적으로 감소시켜버리는 역할을 수행하며, 이는 CNN과 Transformer 모델에 다 존재합니다.
일반적으로 ResNet에서는 stem에 7×7 커널사이즈와 스트라이드 값이 2인 컨볼루션 레이어, 그리고 바로 뒤를 이어서 존재하는 maxpooling을 통해 입력 영상에 4배 줄어든 결과를 생성하게 됩니다.
Transformer에서는 조금 더 과격한? patchify strategy를 사용하는데 ViT의 경우 패치를 단어로 보기 때문에 Patchify 단계에서 컨볼루션의 커널 사이즈가 16×16에 stride 역시 16으로 컨볼루션 연산이 겹치지 않도록 합니다. 물론 초기 ViT가 이런 방식을 사용하는 것이고, Swin Transformer와 같은 계층적 구조의 네트워크들은 patchify layer에서 4×4 크기의 커널 사이즈를 사용하고 있습니다.
저자는 이러한 Swin의 구조를 본받아 기존 ResNet의 7×7 커널 사이즈에서 4×4, stride 4의 컨볼루션 레이어로 patchify stem 구조를 바꾸었으며 그 결과 79.4%에서 79.5%의 성능 향상…? 을 보였습니다. 사실 이 부분은 그냥 7×7 convolution & 3×3 maxpooling이라는 과정 대신 단순히 4×4 컨볼루션 연산 한번만 해도 성능이 비슷하게 나온다~ 정도로만 이해해주시면 될 것 같습니다.
ResNeXt-ify
아마 백본에 관심이 많으신 분들이라면 한번쯤은 Resnet이 아닌 ResNeXt에 대해서 들어보셨을 겁니다. 사실 모르셔도 괜찮습니다. 저도 해당 백본에 대해서 잘 모르는데, 저자가 말하기로는 ResNeXt는 기존의 ResNet에서 더 낮은 FLOPs를 가지며 동시에 더 좋은 정확도를 가지도록 하는, 즉 속도와 정확성의 trade-off를 해결하고자 했다 합니다.
이러한 ResNeXt의 가장 핵심 부분은 바로 grouped convolution 입니다. grouped convolution은 쉽게 말해 컨볼루션 필터가 서로 다른 그룹마다 분리된다! 라는 것으로 다른 말로 하면 Depth-wise convolution을 의미합니다. Depth-wise convolution은 많은 분들이 알고 계실텐데 모르시는 분들은 아래 그림2를 참고하시면 좋을 듯 합니다.
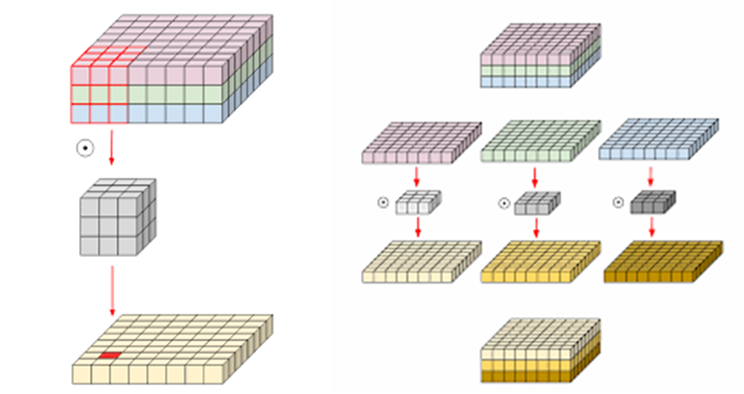
그림2의 우측을 살펴보면 3채널짜리 Feature map에 대해 1채널씩 그룹을 지어서 컨볼루션을 따로따로 적용하는 것을 확인할 수 있습니다. 만약 그림2의 좌측과 같이 일반적인 컨볼루션이라면 3x3x3의 텐서형식 필터로 한번에 3채널짜리 feature map과 컨볼루션 연산을 수행하게 됩니다.
그래서 mobilenet이나 Xception 네트워크 같은 경우 1×1 컨볼루션 레이어와 3×3 depth-wise convolution을 번갈아 사용하면서 standard convolution과 동일한 효과를 보면서, 모델의 속도를 획기적으로 낮추는 방법론으로 많이 소개되어 있고, 지금까지 사용되어 오고 있습니다.
여기서 저자는 이 Depth-wise Convolution이 각 채널별 바이어스를 계산하는 Self-attention 연산을 weighted sum 한 것과 매우 유사하다라고 주장합니다. 이는 그림2를 보시면 아시다시피 각 채널별로 서로 다른 종류의 filter를 사용해서 계산하다보니, 채널 축으로 보았을 때는 서로의 개입 없이 공간적 차원에서만 연산하는 것으로 볼 수 있으며, 이러한 과정자체를 두고 Self-Attention을 수행한다 라고 본다는 것이죠.
이러한 DW-Conv의 역할은 네트워크의 FLOPs을 효과적으로 낮춤과 동시에 정확성을 기대해볼 수 있으며, 저자는 이를 바탕으로 ResNet의 width를 Swin-T의 채널 수와 동일하게 설정하였습니다.(기존 64에서 96으로 확장.) 그 결과 FLOPs이 2.4G(DW Conv+64 width)에서 5.3G로 늘어나긴 했지만 성능도 함께 79.5%에서 80.5%로 향상되었습니다.
Inverted Bottleneck
Bㅇottleneck layer에 대해서는 아마 많이들 알고 계실걸로 생각이드는데, 간략히 설명하면 1×1 레이어를 통해 채널의 수를 크게 줄인 뒤 3×3 컨볼루션 연산을 수행하고 다시 1×1 레이어를 통해 원래의 채널수로 되돌리는 작업을 수행하는 것입니다. 이러한 bottleneck layer는 연산량을 줄일 수 있다는 점 덕분에 ResNet과 다양한 네트워크에서 많이 활용되곤 했습니다.
이러한 ResNet과 달리 Transformer는 상당히 반대되는 특징을 보여주었는데, 이는 바로 매 Transformer block마다 inverted bottleneck 구조를 사용했다는 점입니다. Inverted Bottleneck 구조란 1×1 레이어를 통해 채널 수를 줄이는 것이 아닌 오히려 늘린 뒤 컨볼루션 연산을 하고 다시 원래 채널 수로 되돌리는 것을 의미합니다.
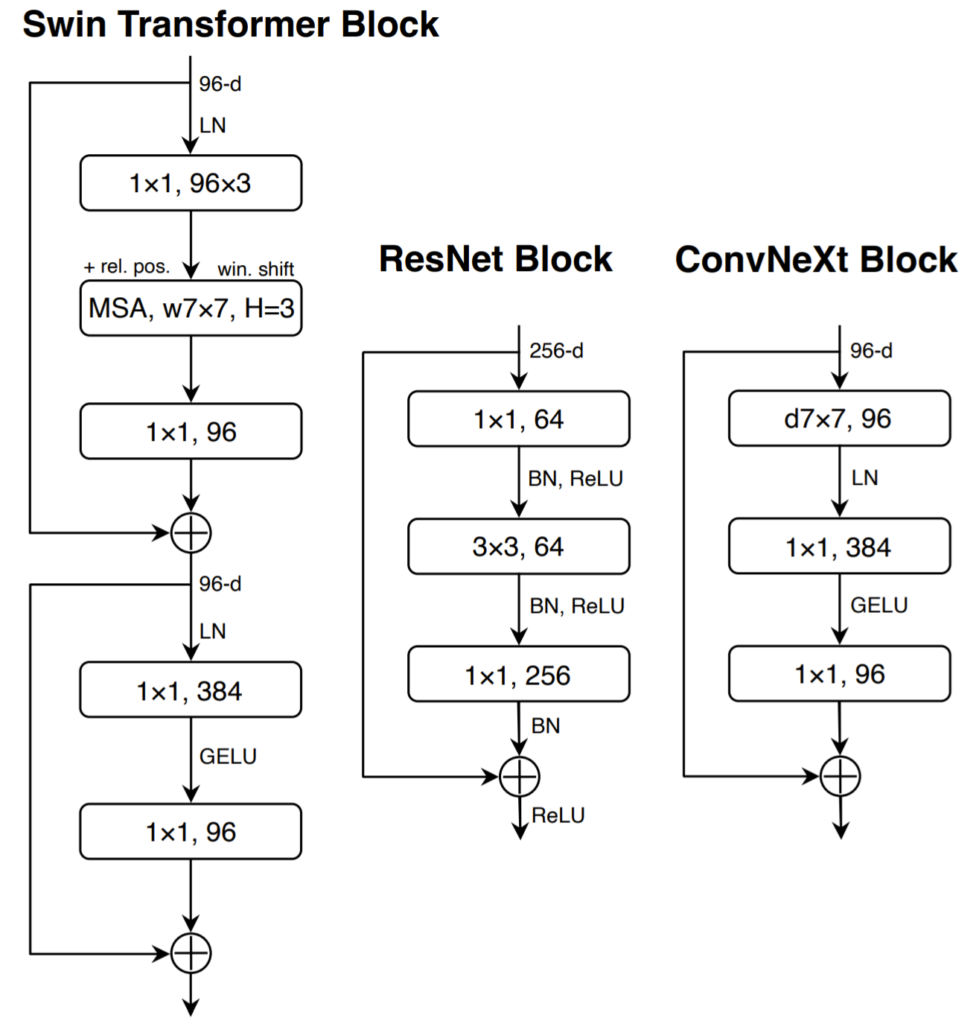
그림3을 참고하시면 보다 직관적으로 이해가 가능하실 듯 한데, ResNet은 256채널의 feature를 128로 줄여서 연산 후 다시 원래 채널크기인 256으로 늘리는 것을 확인할 수 있습니다. 하지만 Swin Transformer의 경우 MHSA 연산 이후에 나온 96채널 feature에 1×1 layer(fc layer) 연산 및 Residual 연산을 하였다가 MLP 단계에서 384로 기존 채널 대비 4배 더 키워서 연산을 수행하게 됩니다. 즉 차원을 4배 줄이던 기존의 방법과는 달리 오히려 차원을 4배 더 늘린 것이죠.
그래서 저자는 그림3과 같이 ResNet에 inverted bottlneck 실험을 적용하였습니다.
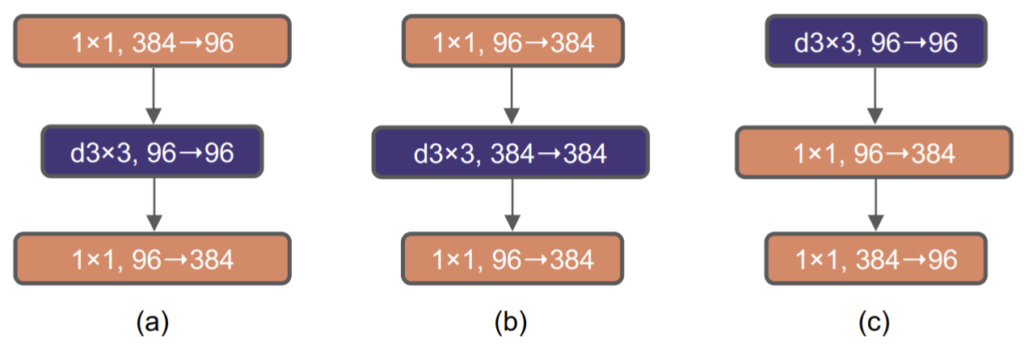
그림4-(a)는 ResNeXt과 같이 1×1 conv layer로 채널 축을 줄이고, Depth-Wise 연산을 수행하여 공간적 정보에 대해 계산한 뒤, 다시 1×1 conv layer로 채널 축을 되돌리는 과정을 나타냅니다.
(b)는 Transformer와 유사하게 Inverted Bottleneck 구조 형식으로 재수정한 것이며 한눈에 봐도 아시다시피 96 채널을 384로 4배 늘린 뒤 3×3 DW 연산을 수행합니다. 그리고 나서 다시 384를 96으로 되돌리는 작업을 수행하게 되는데 이 논문이 나온지 리뷰 기준 2일(22.0.12)밖에 안되어서 그런지 그림 속 차원에 오타가 있네요. 96 \rightarrow 384 가 아닌, 384 \rightarrow 96 입니다.
아무튼 이러한 변경점을 통해 bottleneck 구조에서 얻을 수 있는 빠른 속도 장점을 잃었으니 더 느려지는 거 아닌가? 싶으시겠지만, 오히려 기존 FLOPs 5.3G 대비 4.6G로 더 빨라졌다고 합니다. 그 이유에 대해 논문에서는 비록 DW-Conv 연산을 할 때는 채널 수가 4배 늘어나 FLOPs이 증가하겠지만, 다음 블록으로 넘어가려는 residual block의 shortcut 1×1 conv layer에서 FLOPs이 매우 크게 감소하기에 FLOPs을 줄일 수 있었다고 합니다.
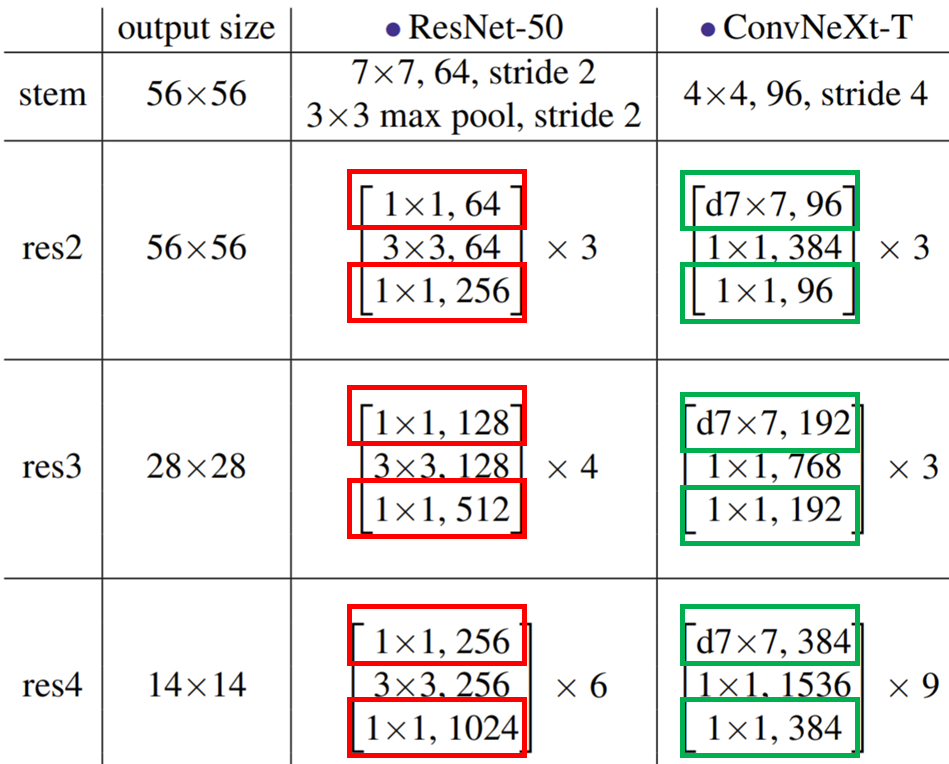
조금 말을 어렵게 설명하였는데, 위에 표를 다시 보면 이해하기 쉬울 듯 합니다. 지금 위에 표에서는 1\times 1 \rightarrow DW-Conv \rightarrow 1\times 1의 순서가 아닌 DW-Conv \rightarrow 1\times 1 \rightarrow 1\times 1의 순서를 가지고 있습니다. 왜 DW-Conv가 먼저 나오는지에 대해서는 바로 뒤에 섹션에서 설명드릴테니 그 부분은 현재 고려하지마시고 1×1 conv의 채널 수가 언제 바뀌는지에 대해서만 이해하시면 됩니다.
아무튼 ResNet-50은 DW-Conv 이후에 나오는 1×1 conv layer에서 채널 크기가 4배 늘어나는 반면, 저자가 변경한 모델은 중간 레이어의 채널이 4배 증가하고나서 블록의 마지막 1×1 conv layer에서 다시 줄어들게 됩니다. 이러한 구조적 차이는 하나의 Residual Block이 끝마친 뒤 원래의 input과 summation하는 residual 연산의 입력으로 채널의 수가 큰 값들을 더하는 Resnet과 달리, 저자의 ConvNext는 작은 채널수로 연산하기 때문에 FLOPs 값이 크게 감소하는 것입니다.
아무튼 다시 정리하자면 Inverted Bottleneck layer를 통해 80.5%에서 80.6%로 성능을 미세하기 향상시킴과 동시에 FLops를 줄여 모델을 더 빠르게 만들었다 라는 점에서 의의가 있습니다. 그래도 성능이 너무 적게 오른거 아닌가? 라는 생각이 드실 수 있는데, ResNet-50이 아닌 ResNet-200의 경우에는 성능 개선이 81.9%에서 82.6%로 향상되었기 때문에 모델의 크기에 따라 inverted bottleneck의 효과는 달라질 수 있다고 보시면 될 것 같습니다.
Large Kernel Size
해당 섹션에서는 컨볼루션 레이어의 커널 사이즈에 대한 실험 및 고찰에 대한 얘기를 진행합니다. 사실 CNN이 나온지 얼마 되지 않은 초창기에는 5×5, 7×7 등 다양한 커널 사이즈를 사용했던 것으로 기억하고 있는데 VGG네트워크가 제안되고 나서부터는 3×3의 small kernel-size를 사용하는 것이 당연시 되었습니다. 물론 3×3 컨볼루션 연산은 GPU를 장착한 하드웨어에 적용하기에도 매우 효율적이었죠.
Swin Transformer 역시도 전체 feature map에 대해서 MHSA 연산을 수행하는 것이 아니라, 일정한 크기의 겹치지 않은window로 구간을 쪼개어 그 구간 내에서 MHSA 연산을 수행하긴 합니다만, 그 Window의 크기는 현재 CNN에서 자주 사용하는 3×3 크기의 보다 상대적으로 큰 7×7의 크기를 가지고 있습니다.
저자는 이러한 Transformer의 상대적으로 큰 커널 사이즈에 초점을 두어 ResNet의 커널 사이즈에 따른 성능을 비교하고자 합니다.
Moving up depthwise conv layer
큰 커널 사이즈에 대해 실험하기 위해서, 한가지 전제조건이 있는데, 이는 바로 그림4-(c)와 같이 Depth-wise convolution의 순서를 가장 위로 올리는 것입니다. 이렇게 구조를 변경한 것에 대해서는 매우 그럴듯한? 이유가 있는데, 가장 먼저 Swin Transformer의 구조도 FC layer 사이에 MHSA 연산을 수행하는 것이 아닌, MHSA 연산을 먼저 수행하고 그 뒤에 MLP 연산이 뒤따라 옵니다.
이는 MHSA와 같이 매우 복잡하고 연산 속도가 오래 걸리는 부분에서는 feature의 채널이 최소한 작아야 하기 때문이며 비교적 단순한 MLP에서 차원을 늘려 연산을 수행하기 때문입니다. 아무튼 저자가 하고자 하는 실험이 DW-Conv layer의 커널 사이즈를 넓히는 것인데, 이 때 채널이 크게 늘어난 feature map에 대하여 큰 커널 사이즈로 연산하게 되면 연산량이 아무래도 크게 늘어나게 됩니다.
이러한 문제를 예방하고자 DW-Conv를 맨 처음부터 수행하여 저차원의 feature map에 대하 계산하고, 그 후 1×1 conv layer에서 inverted bottleneck 연산을 수행하고자 합니다. 사실 이 방식이 기존 Transformer의 방식과 매우 유사하다고 볼 수 있겠죠.([/latex] DW-Conv(=MHSA) \rightarrow 1\times 1convs \times 2 (=MLP( 2 \times fc layers) [/latex])
이러한 구조 변경으로 인해 성능이 80.6%에서 79.9%로 감소하긴 했지만, FLOPs 역시 4.6G에서 4.1G로 낮아지면서 더 빠른 속도를 취득할 수 있었다고 합니다.
Increasing the kernel size
자 그러면 본격적으로 커널 사이즈를 조절하는 실험을 진행해봐야겠죠? 저자는 3, 5, 7, 9 그리고 11의 커널 사이즈에 대해서 실험을 진행하였다고 합니다. 그리고 이 때 정확도가 79.9%(3×3 kernel size)에서 80.6%(7×7 kernel size)로 상승하였으며 FLOPs는 거의 유지하였다고 합니다. 그외의 커널 사이즈를 사용했을 때 정확도와 FLOPs는 그림1에서 확인하실 수 있습니다.
Micro Design
이전까지의 모든 실험 및 변경점들은 macro 규모에 해당했다면 이제 다뤄볼 내용들은 micro 수준의 설계에 대한 실험들입니다. 대부분의 실험들이 layer level에서 이루어지고 있으며, 어떠한 활성화 함수와 normalization layer를 사용할 것인지에 대해서 집중한다고 합니다.
Replacing ReLU with GELU
다양한 Activation Function들이 존재하지만, 아마 가장 많이 사용하는 activation function을 고르라면 그것은 당연히 ReLU일 것입니다. ReLU는 매우 단순하면서도 효율적이어서 정말 많은 CNN 네트워크에서 사용됩니다. 물론 NLP 분야에서 처음 나온 Transformer에서도 ReLU를 사용했었습니다.
하지만 최근의 나온 다양한 transformer 방법론들(e.g. NLP분야의 BERT, GPT-2와 Vision 분야의 ViT 등등)에서는 ReLU대신 Gaussian Error Linear Unit(GELU)를 사용하는 모습을 보여줍니다. GELU에 대해서는 저도 정확히 알지 못하지만, ReLU와 비교하였을 때 더욱 부드러운 variant를 가지고 있다고 합니다.
저자는 이러한 GELU가 CNN에서도 역시나 적합하다고 주장하고 있습니다만, 사실 ReLU에서 GELU로 변경하였다고 해서 성능의 변화가 있지는 않았습니다.(그대로 80.6%)(물론 저자도 성능의 변화가 없음을 인지하고 있지만, 아무튼 그래도 GELU가 더 좋다고 합니다. 왜지..?)
Fewer activation functions
이 섹션 부분이 저는 상당히 매력적으로 다가왔습니다. 제 리뷰의 글이 평소보다 좀 많긴해도, 이 부분만큼은 꼭 집중해서 보셨으면 합니다.
Transformer block과 ResNet block의 가장 큰 차이점 중 하나는, activation function의 사용 빈도가 상당히 크다는 점입니다. Transformer의 경우 activation function을 각 block 당 단 1번만 사용하는 반면, ResNet block은 컨볼루션이 나올 때 마다 한번씩 세트마냥 등장합니다.
위의 그림은 그림3과 동일한 그림인데, 리뷰 보기 편하시라고 한번 더 올렸습니다. 제일 좌측의 Swin Transformer block의 경우 1×1 layer가 Query, Key, Value를 계산하는 projection layer, MHSA 연산이 마친 뒤 한번 더 projection layer, 그리고 FC layer가 2개 존재하는 MLP 과정 중 activation function은 MLP 단계에서 단 한번만 나오게 됩니다.
반면이 ResNet block은 어떤가요? 커널사이즈가 어떻게 되던지 상관없이 그냥 컨볼루션 레이어가 있으면 ReLU가 뒤따라서 등장합니다. 이러한 activation function의 남용?이 가장 큰 차이라고 볼 수 있으며, 저자는 Transformer와 유사하게 1×1 layer 사이에만 단 한번 GELU activation function을 적용했다고 합니다.
그 결과 놀랍게도 성능이 80.6%에서 81.3%로 0.7%나 상승하는 것을 확인할 수 있었으며, 이 성능은 Swin-T와 동일한 성능에 도달한 것입니다.(머박) 결과적으로 저자는 각 블록마다 단 하나에 GELU 함수만을 적용합니다.
Fewer normalization layers
위의 activation function 설명하면서 각 모델의 block 구조를 살펴보셨을텐데, 눈치가 빠르신 분들은 이미 발견했을 듯 합니다. 네 transformer block은 activation function 뿐만 아니라, normalization layer까지 상당히 적은 것을 확인하실 수 있습니다.
그래서 저자는 BatchNorm Layer 3개 중 2개는 지워버리고 DW-Conv에서 1×1 conv로 들어가기 사이에 BN을 적용했다고 합니다. 그 결과 81.3% 성능에서 81.4%로 0.1% 성능 향상이 있었다고 합니다. 그리고 추가적으로 저자는 block의 맨 시작부에 BN layer를 하나 더 추가해서 실험도 해봤는데, 성능에 아무런 개선을 주지 않아서 최종적으로 BN 레이어 하나만 사용했다고 합니다.
Substituting BN with LN
Batch Normalization은 오버피팅을 방지하고 수렴의 안정성을 주는 장점 덕분에 CNN에서 상당히 오랫동안 사용해온 기법 중 하나입니다. 하지만 BN은 모델의 성능에 악영향을 줄 수 있는 많은 복잡성을 가지기도 합니다.(그 이유에 대해서는 논문에서 참조 논문을 하나 걸어주네요. 관심있으신 분들은 읽어보시길 바랍니다.)
반면에 Lyaer Normalization(LN)은 트랜스포머에서 참 많이 사용되는 방식입니다. 그리고 역시나 다양한 응용 분야에서 좋은 성능을 보여주고 있습니다. 그러면 기존의 BN을 버리고 LN을 바로 적용하면 되겠군요?
아쉽지만, 기존의 ResNet 구조에 BN을 LN으로 교체하게 될 경우 좋은 성능을 기대하기는 어렵습니다. 오히려 성능 감소를 일으킨다는 실험을 진행한 논문이 있다고 하네요.(이 논문 역시도 참조되었으니 참고하실 분은 참고 바랍니다.)
아 그러면 BN을 LN으로 바꾸는 건 별 의미가 없나..? 라고 생각이 들 수 있는데, 신기하게도 저희가 지금까지 공부해온, 저자의 실험을 통해 변경된 모델 구조(ConvNeXt)에서는 BN을 LN으로 변경하게 될 경우 81.4에서 81.5%로 성능 향상이 발생했다고 합니다.
이를 통해 저자는 각 residual block의 layer normalization 기법으로 BN 대신 LN을 사용하게 됩니다.
Separate down-sampling layers
Original ResNet에서 각 스테이지가 끝나면 그 다음 스테이지의 첫번째 residual block에서 spatial down-sampling이 진행됩니다. 즉 feature map의 해상도가 2배 줄어든다는 얘기죠. ResNet의 경우에는 일반적인 CNN에서 하듯이 3×3 Conv layer에 stride 2값을 통하여 다운샘플링을 수행합니다.
반면 Transformer의 경우에는 stage와 stage 사이에 separate downsampling layer를 추가하여 해상도를 낮춥니다. separate down-sampling layer의 의미에 대해 명확히 몰랐는데 Swin transformer code를 살펴보면 FC layer의 input_ch, output_ch를 적절히 조절하여 2배 다운샘플링 되도록 하더군요.
즉 3×3, stride 2의 컨볼루션의 경우 윈도우의 영역이 겹치는 반면, fc layer는 겹치는 영역없이 연산하여 다운샘플링을 수행한다는 차이가 있으며, 저자도 이러한 swin transformer의 맞게끔 3×3 conv가 아닌, 2×2, stride 2 conv layer를 통해 겹치는 영역 없이 다운샘플링을 수행했다고 합니다.
이러한 변경점은 학습 방향성을 상당히 크게 바꿨다고 합니다. 또한 추가적인 실험에서 저자는 spatial resolution이 변화되는 곳에 normalization layer를 추가하게 될 경우 학습의 안정성에 도움을 준다는 것을 추가로 발견하였습니다. 이러한 normalization layer를 추가하는 것 역시 Swin transformer에서 down sampling layer 앞뒤로 LN을 추가한 것과 유사한 설계 방식이라고 합니다.
아무튼 2×2 down-sampling layer & LN 추가로 인해 모델의 성능이 82%로 크게 향상되었다고 합니다. 저자는 여기까지의 모든 변경 사항을 다 적용하였으며 이렇게 만들어진 최종 모델을 ConvNeXt라고 명칭하였습니다.
Empirical Evaluations on ImageNet
일단 실험에 들어가기 앞서, ConvNeXt의 모델 종류 및 구성에 대해서 간략하게 설명하고 가겠습니다.

보시면 모델의 종류는 대략 5가지 정도 존재하고 있으며, C는 각 스테이지별 채널의 수를 의미하고, B는 각 스테이지 별 레이어 블록의 개수를 의미합니다. 대략적으로 ConvNeXt-T가 Swin-T, ResNet-50과 유사한 크기 및 FLOPs를 가지고 있습니다.
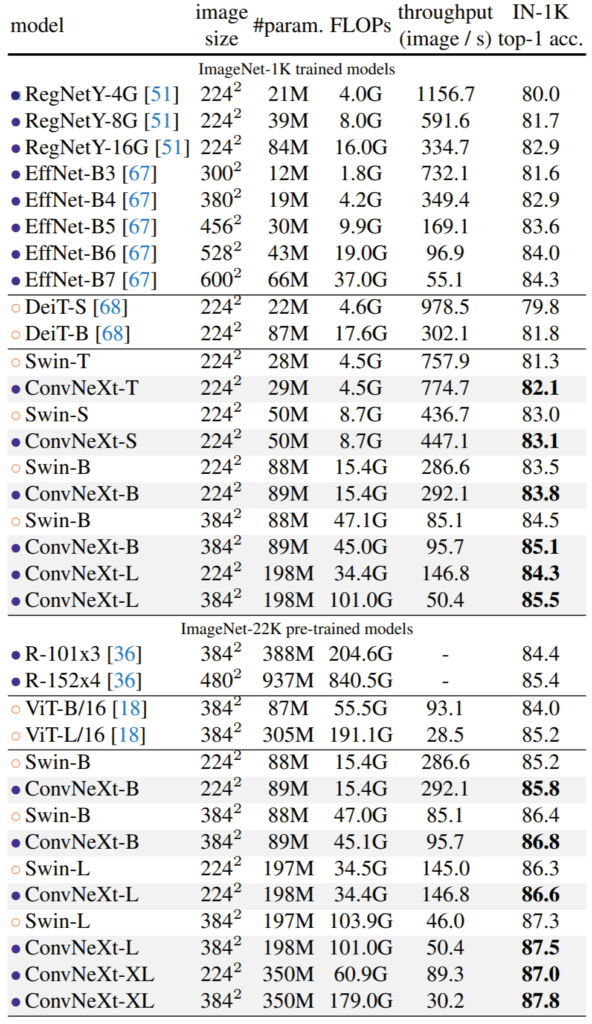
위의 표는 ImageNet-1K의 결과를 나타낸 것입니다. ConvNeXt의 경우 EfficientNet이나, RegNetY 등 상당히 고성능의 모델과 비교하였을 때 매우 쟁쟁한 것을 확인하실 수 있습니다. 얼핏보면 EfficientNet이 더 성능이 좋아보이지만 해상도가 크다 보니 속도가 매우 느리며 만일 해상도를 동일시했다면 ConNeXt가 더 좋게 나왔을 수도 있을 듯 합니다.
그 다음으로는 Swin Transformer랑 비교를 하게 되는데, 확실히 Swin Transformer의 구조적 설계를 많이 참고하였다보니 더 직접적으로 비교하는게 아닌가 싶습니다. 보시면 ConvNeXt 모델들이 Swin과 비교하여 항상 성능도 더 좋고 처리속도도 더 빠른 것을 확인할 수 있습니다.
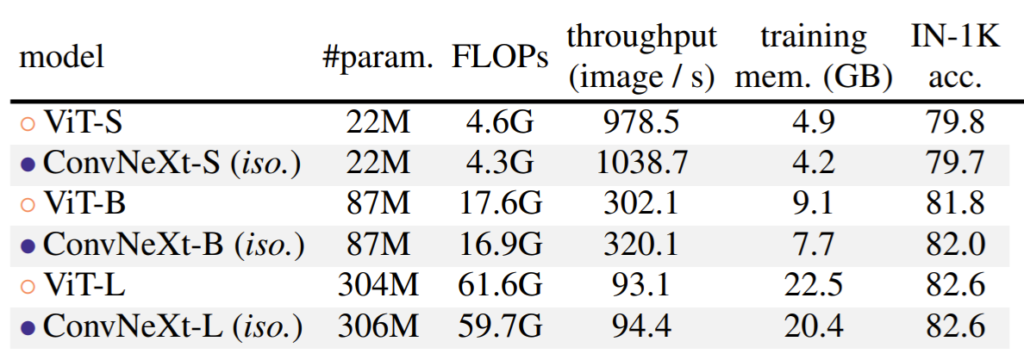
위에 표는 조금 재밌는 실험이었는데, ConvNeXt를 Swin과 같이 계층적 구조로 만든 것이 아닌, ViT처럼 등방향 구조(No downsampling layer)로 이루어져있다면 성능 개선이 안일어나는가?에 대해 실험한 것입니다.
그래서 구조를 변경하여 down-sampling layer를 모두 제거하였으며, 또한 각 스테이지 별 채널의 크기도 384/768/1024로 ViT와 동일하게 맞추어 학습 및 평가를 해보았습니다. 그 결과 ViT와 비교하여 거의 유사한 성능을 보였으며 속도는 더 빠른 것을 확인하실 수 있습니다. 이를 통해 ResNet의 구조를 현대화하여 만든 ConvNeXt는 계층적 구조가 아니어도 효과가 있다는 것을 주장합니다.
Object detection and segmentation
저자는 또한 downstream task에서 잘 동작하는지에 대해서도 실험을 진행하였습니다.
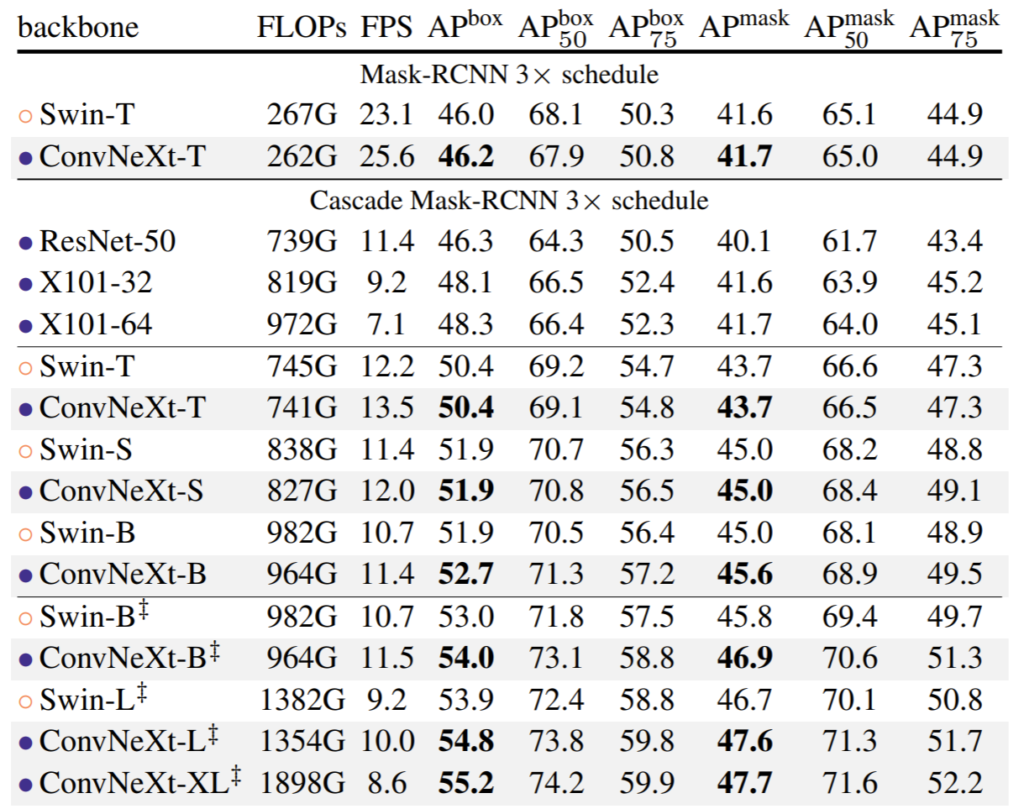
위에 표는 COCO dataset에서의 object detection 성능입니다. 보시면 ConvNext가 Swin과 비교하였을 때 거의 비슷하거나 더 좋은 것을 확인하실 수 있습니다(ConvNeXt-B 기준). 하지만 모델의 크기나 속도는 조금 더 좋은 모습을 보여주는 모습이죠. 참고로 맨 아래 5가지 실험들은 ImageNet-22K 데이터 셋으로 사전학습된 모델의 성능입니다.
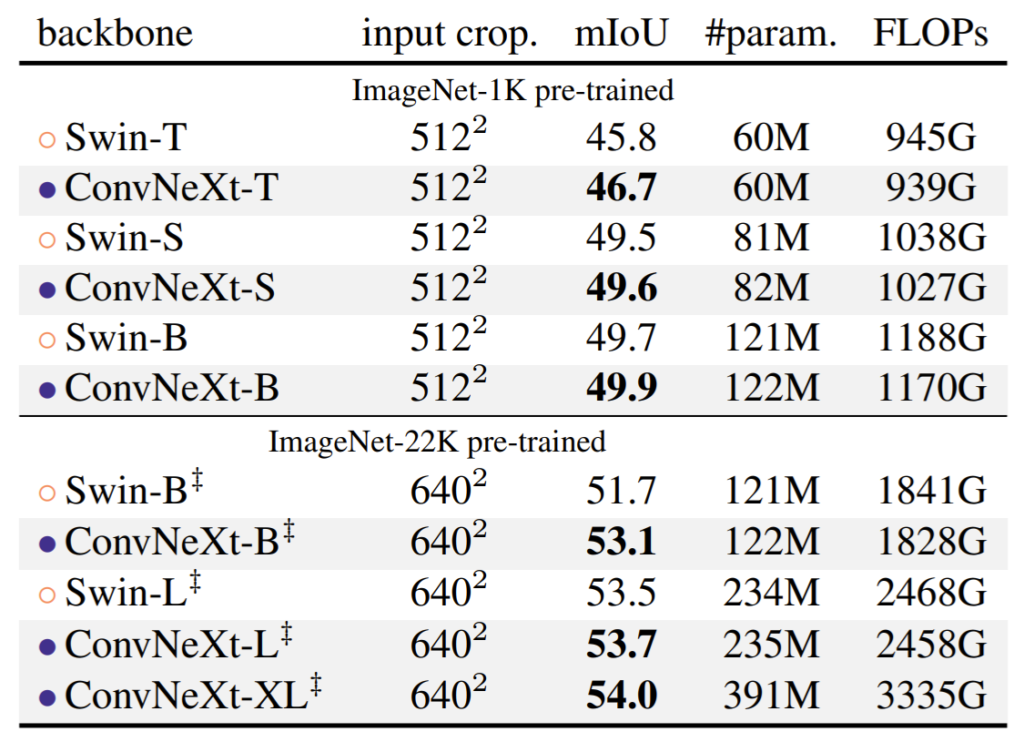
이 실험 결과는 ADE20K 데이터 셋에서의 Semantic Segmentation 결과입니다. 위의 두 테스크의 경향성과 마찬가지로 ConvNeXt가 Swin과 비교하여 성능이 더 좋으며 FLOPs은 더 낮은 모습을 확인하실 수 있습니다. 물론 미세하긴 하지만서도요.
결론
저자는 해당 논문을 통해 Transformer가 CNN보다 모든 면에서 뛰어나다 라는 것을 반박하고 싶었나 봅니다. 물론 이를 위해서 정말 다양한 실험을 진행하였으며 결과적으로는 요새 가장 핫한 transformer인 Swin Transformer를 다양한 테스크에서 이기는 모습을 보여주고 있죠. 그것도 추가적인 모듈 없이 ResNet 구조를 일부 바꿈으로써 말입니다.
이 ConvNeXt를 가져다가 제 연구부야에 사용해볼지는 아직 미지수긴 하지만, 이 논문의 꼼꼼한 실험과 그에 대한 추가적인 설명들은 그 동안의 지식들에 대해 다시 고민하게 만드는 좋은 논문이라고 생각합니다. 특히 무작정적인 3×3 컨볼루션 보다는 커널사이즈를 7×7로 늘리는 것을 고려해볼 필요가 있다는 점, down sampling을 할 때 3×3, stride 2 conv가 아닌 2×2, stride 2가 더 좋았다는 점 등 우리가 생각하기에 당연하다고 여겼던 부분들이 사실은 최고가 아니었다.. 라는 것을 깨닫게 되어서 참으로 좋았던 것 같습니다.
해당 논문은 제가 앞으로 크고 작은 모델 및 모듈들을 설계할 때 어떻게하면 좋을지 많은 도움이 될 것 같습니다. 여러분들도 시간이 될 때 해당 논문을 한번 읽어보시는 것을 추천합니다.
체계적으로 모델을 (0.1% 단위로) 개선해나가는 점이 재미있네요. 실험들을 보면서 ‘inductive bias’가 얼만큼 중요한지 알 수 있으며, 그래도 최종 목적지는 ‘inductive bias’로부터 자유로운 모델을 개발하는게 아닐까 생각됩니다.
뭔가 당연하다고 생각했던 사실들을 많이 꺠부수는 글이네요. Conv의 커널 사이즈라던가, Relu나 BN은 많이 쓰면 안좋다 등등등… 이런 사실을 찾아서 실험을 하는 것도 대단하고, 의미를 도출하는 것도 대단하네요. 감정인식 과제의 제약 조건 때문에 한번 읽어보려던 계획이 있었는데 너무 잘 읽었습니다!