
오늘 리뷰할 논문은 CDVA 표준의 deep feature인 NIP를 보완하여 HNIP로 제안한 논문입니다. 매번 연구를 하면서 HNIP 뿐만 아니라 CDVA라는 단어를 많이 사용해 왔었습니다. 그러나 ETRI 과제를 담당했던 연구원 분들을 제외하고는 CDVA를 모르는 연구원 분들도 많기에, 오늘 리뷰할 HNIP의 이해를 돕고자 CDVA에 대한 설명도 하고자 합니다.
1. CDVA (Compact Descriptors for Video Analysis)
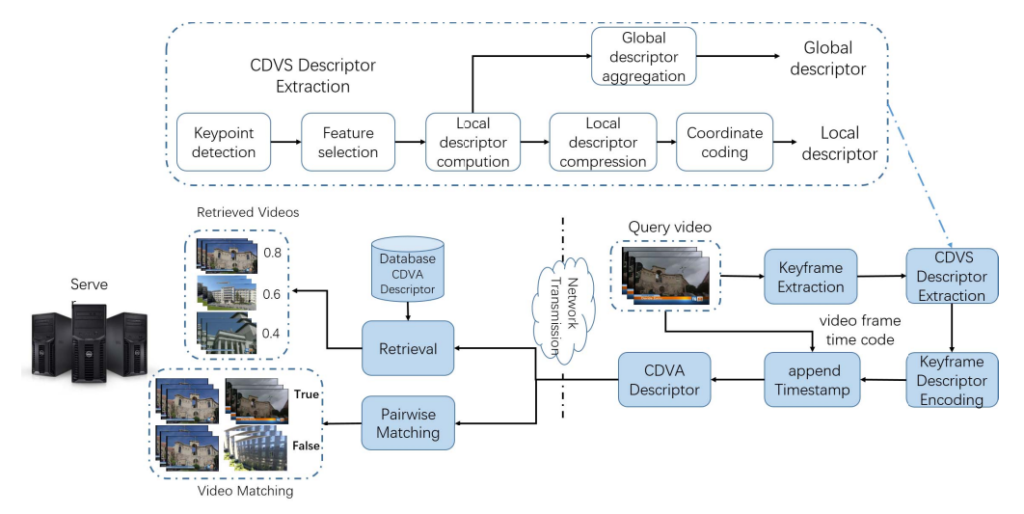
CDVA는 motion picture experts group, 흔히 줄여서 말하는 MPEG에서 비디오 분석을 위한 표준으로 제안된 framework 입니다. 비디오를 compact 하게 표현하여 retrieval 및 matching(localization) task를 해결하고자 제안된 방식이며, 2015년도부터 표준화 작업이 시작되어 2017년도에 표준으로 등록된 방식입니다. CDVA는 크게 extract, retrieval, matching 과정으로 나뉘며, extract에서 video descriptor를 기술하고 retrieval과 matching 과정에서 활용합니다.
1. Extract
Extract 과정은 다음과 같은 순서로 video descriptor를 기술합니다.
- Keyframe Selection
- Feature Representation
- Segment Division
- Segment Encoding
Keyframe Selection
먼저 비디오에서 모든 프레임을 사용하는 것이 아닌 keyframe 만을 사용합니다. 비디오는 motion 정보를 담고있는 특성 상, 비슷한 장면 혹은 행동을 보이는 중복된 프레임이 다수 존재합니다. 이 프레임을 모두 활용하기에는 연산속도가 매우 느려져 실시간 응용분야에서 활용되기 어려워집니다. 이러한 이유로 CDVA 표준에서는 histogram 기반의 프레임 샘플링 방식을 사용하고, 여기서 샘플링된 프레임을 keyframe이라 부릅니다. 좀더 자세하게 이 방식은 앞 뒤 프레임 간의 histogram을 계산하고, 이 차이가 일정 임계치보다 높을 경우에만 프레임을 샘플링하는 방식입니다. 이는 일정 임계치 이하라면 앞선 프레임과의 조도변화가 크지 않은 프레임이라 볼 수 있기에 샘플링을 하지 않는 전략을 사용한 것입니다. 또한 앞 뒤 프레임 간의 간격은 bitrate에 따라 8~4프레임으로 두고 비교합니다. 이 기준은 이후 설명하겠습니다.
Feature Representation
샘플링된 keyframe 마다 descriptor, 즉 feature를 기술하게 됩니다. 기술하는 feature는 총 세 가지로 handcraft 방식의 local feature, global feature 그리고 딥러닝 기반의 deep feature 입니다. 초기에는 handcraft 방식의 feature만으로 표준에 등록되었으나, 이후 여러 버전을 거치면서 딥러닝 기반의 deep feature도 추가되었습니다.
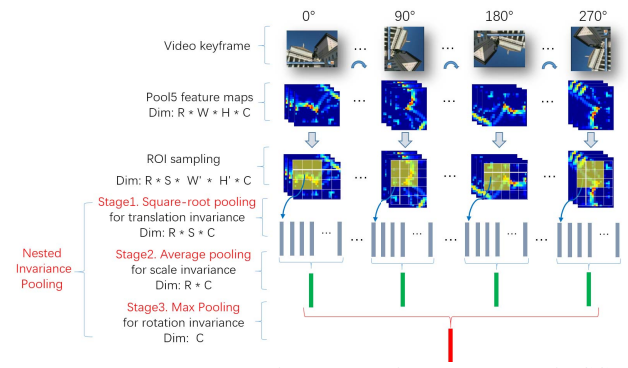
먼저, handcraft 방식의 local feature로는 compressed SIFT를 기반으로한 CDVS(Compact descriptors for visual search)라는 방식을 사용하며, 이는 MPEG에서 CDVA 이전 image analysis를 위해 표준으로 등록한 방식입니다. 그리고 handcraft 방식의 global feature로는 local feature를 aggregate하여 binarization한 SCFV(Scalable compressed fisher vector)를 사용합니다. 마지막으로 딥러닝 기반의 deep feature로는 NIP(Nested Invariance Pooling)을 사용합니다. 이 방식은 한 이미지를 4번 90도씩 회전시킨 뒤 backbone network에서 여러 크기의 kernel로 convolution 연산하며, 얻어진 feature map 들간의 평균 취한 feature 입니다. 이를 통해 translation, scale, rotation invariance를 보유하고자 하였습니다.
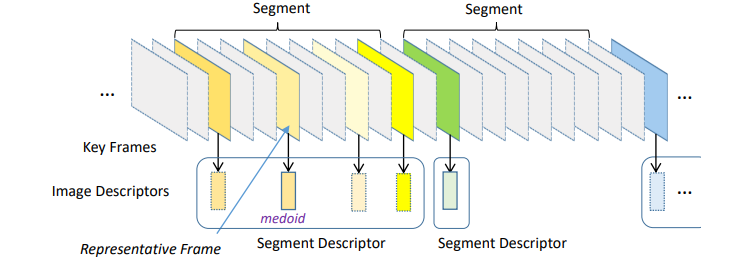
Segment Division
앞서 기술된 feature를 효과적으로 encoding 하여 저장하기 위해, 각 keyframe을 segment 단위로 구분합니다. 우선, 선정된 keyframe 중 시간 순서상 가장 맨 앞에 있는 keyframe을 첫번째 segment로 나누는 것으로부터 시작합니다. 이후, 그 다음 keyframe 과 histogram을 비교하여 일정 임계치 이하일 때(keyframe selection 시 사용한 임계치와는 값이 다름), 유사한 조도를 포함하고 있다고 간주하여 하나의 segment로 묶습니다. 그리고 만약 일정 임계치를 초과한다고 하더라도, 두 keyframe 사이의 SCFV feature 간 유사도가 일정 임계치 이상이면 유사한 프레임이라 판단하여 하나의 segment로 묶습니다. 만약, 두 경우에 모두 해당하지 않을 경우, 새로운 segment로 구별합니다.
Segment Encoding
나눠진 segment를 기반으로 하여 feature를 효율적으로 저장하기 위한 encoding 방식이 사용됩니다. 먼저, segment 에 속한 keyframe 중에서 representative frame을 선정하게 됩니다. Representative frame은 흔히 비디오 코딩에서 사용되는 I frame과 동일하며, 손실 없이 독립적으로 원본 그대로가 저장되는 프레임을 의미합니다. SCFV와 NIP의 경우 segment 내에서 유사도를 비교하여 이를 총합하였을 때 가장 값이 높은 keyframe을 representative frame으로 선정하며, 이 값에 따라 나머지 keyframe의 encoding 순서도 결정됩니다. 그리고 local feature의 경우 앞서 정한 representative frame을 기준으로 시간 축 위치 상 가까운 순서로 encoding 순서를 결정합니다. 이처럼 순서를 결정한 이후, 나머지 keyframe의 feature 들은 representative frame에서 추출된 feature와의 차이만을 저장하도록 XOR 연산 후 ABAC(Adaptive Binary Arithmetic Coding) 과정을 거쳐 encoding 됩니다. 이후 각 feature 별로 block을 생성해 cdva 확장자를 지닌 파일에 저장됩니다.
2. Retrieval
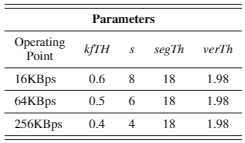
비디오 검색 시나리오에서는 미리 앞선 extract 과정을 데이터 베이스 내의 모든 비디오에 적용하여 cdva 파일로 보유하고 있게됩니다. 이후 사용자가 쿼리 비디오를 던질 때마다 cdva 파일로 변환하여 전송하고, 송신 후 데이터 베이스 비디오들의 keyframe-level feature들과 비교하게 됩니다. 송신할 때, 비디오 내의 데이터를 어느정도로 dense하게 보낼 지에 따라 bitrate가 총 세가지 bitrate 16KBps, 64KBps, 256KBps로 나뉩니다. 이 값은 Table 1과 같으며 column의 경우 kfTH부터 우측으로 각각 keyframe selection시 histogram 차이 임계치, keyframe selection 앞 뒤 프레임 간격, segment division시 histogram 차이 임계치, segment division 시 SCFV 유사도 임계치를 의미합니다.
비디오 검색 시 각 keyframe 마다의 feature 들 중, SCFV와 NIP는 두 비디오 간의 유사도를 계산하기 위하여 사용되며, local feature는 모든 유사도 계산 이후 re-ranking을 위해 사용됩니다. 우선 비디오 유사도를 구하기 위해 SCFV 유사도 구하는 과정을 설명드리겠습니다. SCFV는 binarization된 feature 이기 때문에 흔히 사용되는 코사인 유사도를 사용하지 않고 해밍 유사도를 연산한 후, 이 값에 따라 사전에 정의된 LUT(LookUpTable)을 사용합니다. LUT는 해밍 유사도가 커질수록 큰값을 나타내며 작을 수록 작은값을 나타냅니다. 이후, NIP 유사도는 코사인 유사도로 연산되며, SCFV와 가중합으로 두 비디오 내의 keyframe 유사도를 산출해내게 됩니다. 표준에 등록된 기준으로 사용되는 가중치는 SCFV에 0.25, NIP에 0.75로 사용됩니다. 두 비디오 간의 모든 keyframe 유사도를 구한 뒤, 그 중 가장 큰 값을 비디오 유사도로 활용합니다. 이를 통해 쿼리 비디오와 유사한 순서대로 ranking을 매기게 되며, 옵션에 따라 local feature 간의 inlier 개수로 re-ranking 과정 또한 진행됩니다.
3. Matching
비디오 매칭은 한 비디오 내에서 시간축으로 특정 영역이 다른 비디오와 관련있는지를 판단하는 task로 video alignment로도 불리웁니다. 이는 video partial copy detection에 주로 사용되며, segment 단위의 검색으로도 볼 수 있습니다. CDVA에서 비디오 매칭은 앞선 extract 과정에서 추출된 feature를 활용하며 비디오 검색 과정과 동일한 keyframe 유사도 산출 과정을 거칩니다. 다만, 쿼리 비디오와 데이터 베이스 간의 bitrate가 달랐던 비디오 검색 과정과는 달리, 동일한 bitrate 사용을 기본값으로 둡니다.
먼저 A, B 라는 비디오가 있을 때, A 비디오 내에서 어떤 부분이 B라는 비디오와 매칭되는 지 찾고자 한다고 가정하겠습니다. CDVA framework에서는 비디오 매칭을 위해 A 비디오 keyframe들을 시간 순서대로 B 비디오의 모든 keyframe과 비교합니다. 특정 A 비디오 keyframe과 B 비디오 모든 keyframe을 비교했을 때의 가장 큰 값이 일정 임계치를 넘긴다면해당 keyframe이 속한 A 비디오 내의 segment를 매칭 되었다고 판단하며, 이후 A 비디오 내의 다른 keyframe 또한 이 조건을 충족할 경우 segment 들을 누적하여 하나의 segment로 구성합니다. 누적하는 방식은 시간 축으로 가장 앞선 segment의 시작 지점과 가장 뒤에 있는 segment의 끝지점을 하나의 segment로 간주합니다. 이렇게 얻어진 매칭된 segment가 B 비디오와 연관된 부분이라 반환합니다.
생각보다 CDVA 분량이 길어져 HNIP는 다음 리뷰로 이어서 적어보겠습니다. ->
추억 돋는 CDVA네요. 허허 이 이후 에 CDVA를 이용한 연구가 있을까요?
다음에 리뷰할 HNIP가 있습니다.
그 외에 논문으로 투고된 연구는 없는 것으로 알고 있으며, 저희가 ETRI에서 사용하는 것처럼 개인/회사 연구에 사용하는 경우는 종종 있는 듯합니다.