요약
해당 논문은 Energy-based Learning 방법을 이용하여 Active DA(domain adaptation) 다루기 위한 논문이다.
용어 정리
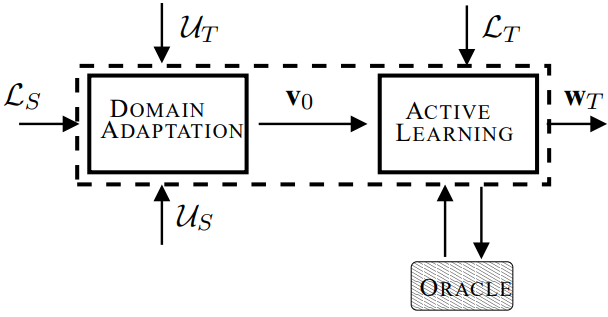
Active domain adaptation (Active DA)
[1]의 세미나에서 active learning과 domain adaptation 사이의 시너지가 있음을 증명하였다. [1]에서 소개한 basic setup은 그림1과 같다. 그림1은 source domain에 대해 학습한 domain adaptation 모델(v0)을 active learnig 모델의 초기화값으로 하여 target domain에서 data selection을 진행하는것을 보인다.
Energy-based Models(EBM)
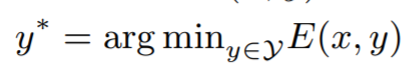
EBM이란 두 변수(x,y) 사이의 dependencies를 수치화하기 위한 모델로, 그 관계를 energy라 불리는 스칼라값으로 인베딩하기 위한 energt function을 구하기 위한 학습방식이다. model이 x에 대해 적절한 y값을 얻이 귀해 inference 하는 방식은 수식1과 같다.
방법론
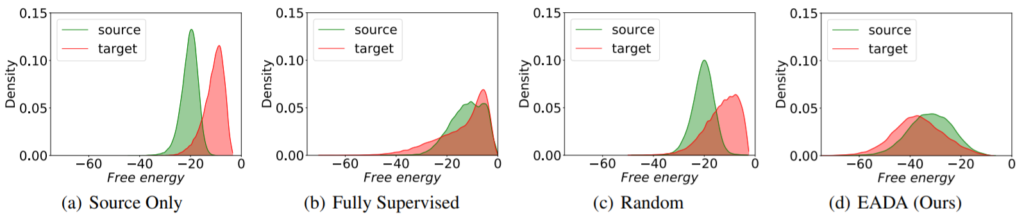
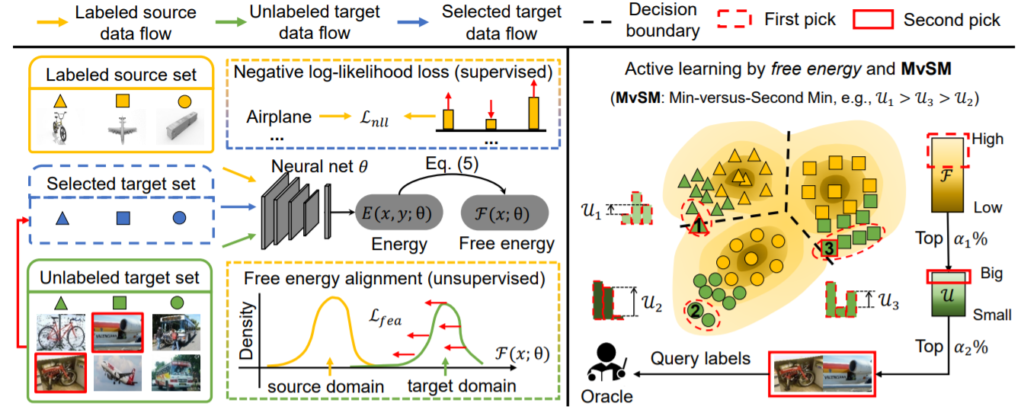
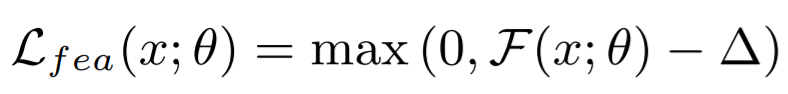
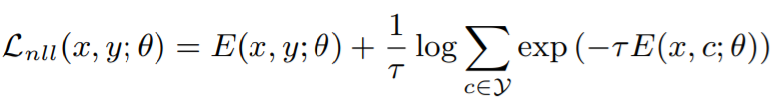
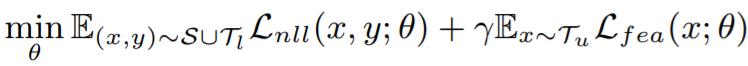
해당 방법론( Energy-based Active Domain Adaptation (EADA) )은 source domain으로 학습한 모델을 통해 target domain과 source domain간의 energy 차이를 이용하여 domain adaptation을 진행한다. 이후 target domain의 데이터 중 free energy가 높은 데이터를 이용하여 MvSM 방식으로 data selection을 진행하여 labeled pool에 포함시킨다. 위의 과정을 어노테이션 예산이 다할때까지 반복한다. 그림 2의 (a)를 보면 source로 학습시킨 모델을 통해 두 domain간의 에너지를 비교하였을 때 target domain의 에너지가 대체로 높음을 알수 있다. 이러한 실험 결과를 통해 free energy값을 일종의 두 domain간의 차이를 표현하는 지표로 하여 그림3의 Free energy alignment과정을 통해 domain adaptation을 진행한다. Free energy alignment를 위해 target data의 free energy가 source domain의 free energy 평균값과 유사해지도록 설계한 L_fea loss를 설계하였고 이는 수식 2와 같다. 또한 정답에 대한 정보량도 측정할 수 있는 EBM을 설계하기 위하여 classification 의 supervised loss를 L_nll(수식3)로 하여 두 loss(L_fea, L_nll)를 결합(수식4)하여 학습에 사용하였다.
해당 논문은 이후 selection process에서 active learing 방법론을 이용했다. 이는 그림3의 오른쪽 영역에 잘 나타나 있으며 MvSM이라고 이름붙였다. 과정은 다음과 같다 target data 중 free energy 값이 높은 데이터 상위 a1%개를 샘플링 한다. 이후 margin-based 방법을 이용해 상의 a2%의 데이터를 최종으로 선정한다. 최종으로 선정한 데이터를 human labeling을 통해 oracle gt를 얻는다. 이때 margin based 방법론은 어떠한 데이터 x가 속할 확률로 예측된 p1,p2,p3가 있을 때 가장 작은 확률인 p3과 두번째로 작은 확률인 p2의 차(margin)를 p(=p2-p3)로하고, 수많은 데이터 X(x1, x2 …) 중 P(p’, p”, …)가 큰 데이터를 active learning의 쿼리 데이터로 선정하는 방식으로 이러한 특징을 담아 Min-versus-Second Min (MvSM)으로 명명하였다고 한다.
실험
실험은 VisDA-2017, Office-Home, Office-31, GTAVtoCityscapes 데이터로 진행하였고 Source only, Random 방법을 포함한 다양한 active learning, domain adaptation 알고리즘과 비교하였다. 그 중 다음실험은 VisDA-2017과 Office-Home 데이터에 대한 실험결과이며 제안하는 방법론이 가장 높은 성능을 보임을 알 수 있다.
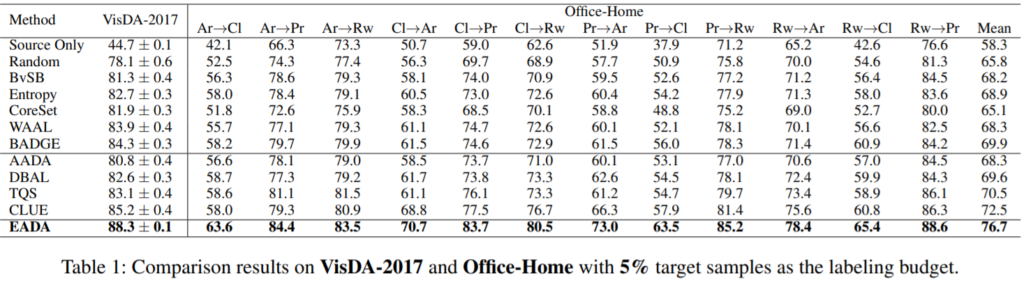
참조
[1] Rai, P.; Saha, A.; Daume III, H.; and Venkatasubramanian, ´ S. 2010. Domain adaptation meets active learning. In Proceedings of the NAACL HLT 2010 Workshop on Active Learning for Natural Language Processing, 27–32.