겨울방학 동안 매주 Video Retrieval 관련 논문 리뷰 하기…! 첫번째 게시글 입니다. 해당 분야에서 자주 보이는 Visual-centeric 한 dataset 인, CC_WEB_VIDEO 에 대한 논문을 리뷰하겠습니다.
Introduction
현재의 웹 비디오 검색은 text keywords 와 유저가 제공한 tags 에 의존합니다. 따라서 검색 결과로 많은 duplicate / near-duplicate videos 가 나오게 됩니다. 본 논문에서는 global signatrues 와 local feature based pairwise comparison 을 사용해서, near-duplicate web videos 를 detect 하는 계층적인 접근 방식을 제안합니다.
near-duplicate detection을 위한 방법은 1) retrieval 결과 목록에서 중복 비디오를 제거하거나, 2) 비슷한 비디오에 대한 다양한 variation 을 찾거나, 3) 다양한 프레젠테이션에서 나타나는 필수 content 를 발견하는 것 등이 있습니다.
본 논문에서는, duplicates 가 많은 web videos 에서 near-duplicate retrieval 과 novelty re-ranking 을 하려고 할 때 해당 접근 방식이 실용적으로 쓰일 수 있음을 보여줍니다.
Near-Duplicate Videos 에 대한 정의
동일하거나, 거의 동일해서 중복이라고 할 수 있는 정도의 상태로 비슷한 videos 를 뜻합니다.
- 사용자는 해당 videos 가 “본질적으로 같다” 고 인식하고, file formats, encoding parameters, photometric variations (color, lighting changes), editing, operations (caption, logo and border insertion), different lengths, and certain modifications (frames add/remove) 등의 측면에서 다릅니다.
- 만약 어떤 video 가 다른 video 의 duplicate 이라면, 대략적으로 같은 scene 임을 뜻합니다. 새로운 정보를 포함하지는 않습니다. duplicates 라는 게 pixel identical 할 필요는 없지만, 그들의 차이점이나 비교의 목적에 따라 duplicate 인지 아닌 지가 갈릴 수 있다고 합니다.
- 이때, Exact duplicate 한 videos 는 near-duplicate videos 의 특별한 경우입니다.
Near-Duplicate Videos 의 카테고리
Formatting differences
- Encoding format: flv, wmv, avi, mpg, mp4, ram and so on.
- Frame rate: 15fps, 25fps, 29.97fps …
- Bit rate: 529kbps, 819kbps …
- Frame resolution: 174×144, 320×240, 240×320 …
Content differences
- Photometric variations: color change, lighting change.
- Editing: logo insertion, adding borders around frames, superposition (중첩) of overlay text.
- Content modification: adding unrelated frames with different content at the beginning, end, or in the middle.
- Versions: same content in different lengths for different releases.
모든 frames 에 대한 duplicate comparison 을 하는 것을 피하기 위해서, 하나의 비디오는 대표 keyframes 들을 이용해서 a list of shots 로 보여집니다. 따라서, near-duplicate videos 라면 서로 다른 keyframes sequence 를 갖고 있을 겁니다.
통상적으로 하나의 비디오는 편집 cut 과 프레임 간의 transition 기반으로 하여 set of shots 로 분리되고, representative keyframe 은 각 shot 을 나타내기 위해 뽑힙니다. 아래 그림은 near-duplicate web videos 의 예시입니다.

계층적인 Near-Duplicate Video Detection
본 논문에서 제안하는, near-duplicate web video dection 에 대한 계층적인 방식에 대해 소개하겠습니다.
- hirachical 은, global signatures 와 pairwise comparison 을 합친 framework
- global signatures with color histogram (SIG_GH)
- 더 정확하고 비싼, keyframes 간의 local feature based pairwise comparision (SET_NDK)
- near-duplicate video detection 을 위한 global signatures 와 pariwise comparion 에 대한 요약
4.1. Hierarchical Framework
분석 결과에 따르면, near-duplicate videos 중에 20% 정도가 exact duplicate videos 라고 합니다. 그렇기에, dupicate videos 에 대한 빠른 detection 이 요구된다고 해요.
global signature from color histograms (SIG_CH) 는 videos 를 동일/유사 content 의 videos 와 matching 하는데 적합한 빠른 measure 라고 합니다. global signatures 는 videos 의 low-level color features 에 대한 global statistics 나 summaries 라고 해요. 이때 videos 간의 similarity 는 signatures 간의 distance 로 계산됩니다.
그러나, major editing, content modification, dramatic photometric and geometric transformations 이 적용된 videos 에서는 global signatures 가 부적절해지는 경향이 있다고 합니다. 특히, 여러 variations 가 섞이면, near-duplicate detection 은 더 어려워집니다.
반면, global signatures 와는 다르게, pairwise keyfram comparision 은 각 keyframe 를 독립적인 node 로 취급하고, 두 videos 는 각 nodes 간의 pairwise similarity 로 비교합니다. keyframes 간의 pairwise comparision 은 두 비디오 간의 overlapping 정도를 측정하는 데도 쓰일 수 있습니다. 따라서, local featrue based pairwise comparision (SET_NDK) 는 near-duplicate keyframes 를 detect 할 수 있고, videso 간의 reliable 한 measurement 도 제공합니다.
그러나, local points 에 대한 comparision 은 color histograms 보다 비싸고, keyframes 는 pairwise 로 계산되어야 합니다.
따라서, 본 논문에서는 global signatures 와 local keypoints 를 사용하여 near-duplicate web videos 를 detecting 합니다. color histogram 을 사용하는 global signaturer 가 높은 confidence 로 near-duplicate videos 를 detect 하고, 엄청 안 닮은 videos 는 필터링해냅니다.
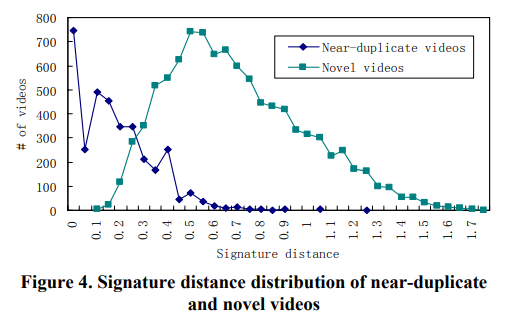
fig4 는 near-duplicate / novel videos 의 signatrue distance distribution 입니다. 어떤 videos (distnace < 0.2) 는 바로 near-duplcate 로, distance > 0.7 은 novel 로 바로 인식됩니다. 이런 filtering 으로 인해 많은 videos 가 제대로 인식됩니다. 이런 필터링이 pairwise comparision 의 computation 을 줄여줍니다. 그러나 이러한 방식만으로는 near-duplicate/novelty 가 분명하게 되지 않기 때문에, 본 논문에서는 accurate local feature based near-duplicate detection 을 적용합니다.
4.2. Global Signature on Color Histograms
video 의 각 keyframe 에 대해 color histogram 이 계산되는데, 이를 H_1 = (h_1, h_2, ..., h_m) 로 나타냅니다. 이때 보통 HSV color space 를 쓰기 때문에, 본 논문의 histogram 은 18 bins for Hue, 3 bins for Saturation, 3 bins for Value 로, 따라서 m = 24 로 이루어져 있습니다.
이때, Video signature (VS) 는 video 에 있는 모든 keyframes 의 normalized color histogram 인, n-차원 벡터로 정의됩니다.
VS = (s_1, s_2, ..., s_m)- s_i = {1 \over n}\sum_{j=1}^{n} h_{ij}
- n = video 에 있는 keyframes 수
- h_{ij} = keyframe j 의 color histogram 의 i 번째 bin
- VS_i = (x_i, ..., x_m) , VS_j = (y_1, ...., y_m)
- 이때, 두 비디오 간의 distance 가 가까우면 near-duplicate 로 취급됩니다.
videos의 signatures 는 실제 원본 비디오에 접근하지 않고, video 를 indexed / searched 할 수 있습니다. 따라서 retrieval speed 가 빠릅니다.
4.3. Keyframes 간의 Pairwise Comparison
global signatures 로 novel / near-duplicate 구분이 안 되는 web videos 에 대해서, local features based method (SET_NDK) 가 사용됩니다. 이때, two videos 의 key frames 의 similarity 를 pairwise comparison 을 이용하여 측정하고, 비슷한 keyframes 의 비율을 이용하여 중복인지 결정하는 것입니다.
해당 섹션에서는 videos 에 sliding window 를 이용해서 near-duplicate keyframes (NDK) 를 detect 하기 위한 local featrue based 기술을 소개하고, keyframe similarity 를 이용해서 video 중복성을 측정하는 것을 소개합니다.
- Local features 는 PCA-SIFT (각 local points 에 대해 36차원 벡터로 표현함)로 표현됩니다.
- 각 keyframe 은 다른 video 의 특정 sliding window 에 있는 keyframes 와 비교됩니다.
- similary keyframes 가 인식되면, normalized set difference 를 이용하여 두 비디오 간의 similarity 를 평가합니다.
4.4 Signatrue vs. Pairwise 비교
- global based signature based on color histograms (SIG_CH)
- local feature based pairwise comparison of keyframes (SET_NDK)
두 방법이 detect 를 얼마나 잘 하는지에 대해 보여주는 표 입니다.
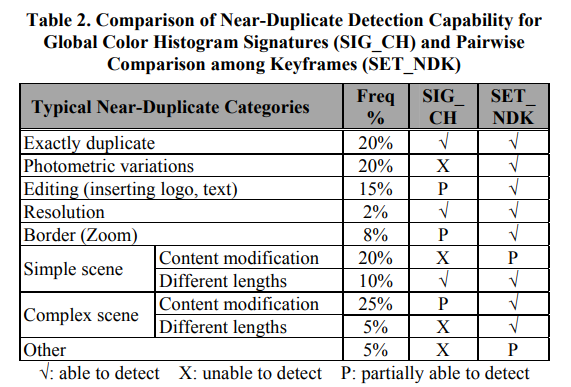
일반적으로, SIG_CH 는 빠르지만, detect 하는 데 한계가 있습니다. 반면 SET_NDK 는 느리지만, 잘 detect 합니다.
따라서, SIG_CH 와 SET_NDK 를 합치는 계층적인 방식이 효율적이고 효과적입니다.
Dataset
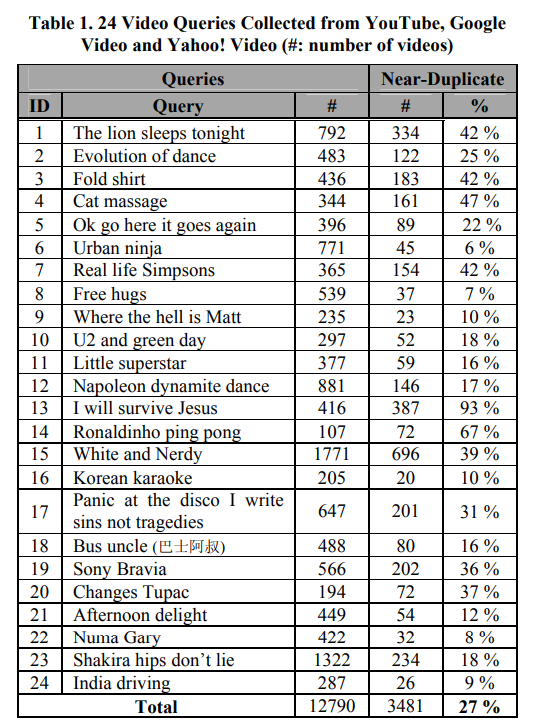
이 접근 방식을 테스트하기 위해 데이터셋을 구축했습니다. Youtube 에서 가장 인기 많은 비디오 24개를 query 로 선택했습니다. 각 text query 는 Youtube, Google Video, Yahoo! Video 에서 검색되어 해당 데이터셋으로 모아졌습니다. Video 는 2006년 11월에 수집되었고, 10분 이상의 video 는 제외했습니다. 최종 데이터셋은 12790개의 비디오로 이루어졌습니다.
새로운 re-ranking 과 near duplicate video retrieval 의 성능을 분석하기 위해, 두 명의 비전문 평가자에게 요청했습니다.
near-duplicate video retrieval : 가장 유명한 video 가 각 query 의 seed video 로 선택되었고, 평가자들이 비디오를 보고 중복/새로움으로 라벨링해서 ground truth 라벨을 만들었습니다.
re-ranking : 평가자들에게 near-duplicate clusters 를 주고, 그걸 증가해나가면서 이게 맞는지 평가하도록 요청받았고, final ranking list 는 near-duplicate videos 를 제거한 original relevance ranking 으로 구성되었습니다.
Performance metric
- precision : near-duplicate detection 성능 평가 척도
- recall : novelty 에 따라 relevant web videos 를 re-rank 하기 위한 평가 척도
- novelty mean average precision (NMAP) : 모든 tested queries 에 대한 map 를 측정하는 평가척도. 이때, novel 과 relevant videos 만을 gt로 취급합니다. 즉, 두 비디오가 query 에 relevant 하고, 서로 near-duplicate 하다면, 오직 첫 번째 video 만이 correct match 로 고려됩니다.
- → novel videos r_i 가 1 ~ i 있을 때, top k 개의 candidate novel videos 를 retrievse 하는 system 에서의 NMAP
Experiments
Novelty Re-ranking
relevance order 는 유지하면서, 모든 novel videos 를 list 하는 것을 목적으로 합니다.
각 비디오 V_i 는, V_i 와, 이전에 ranked 된 새로운 video V_j 까지 pairwise comparison 을 하여 계산됩니다.
R(V_i | V_1, ..., V_{i-1}) = max_{1<=j<=i-1} R(V_i | V_j)V_i 와 가장 유사한 preced ranked video 가 V_i 의 중복성을 결정하고, near-duplicate videos 를 모두 제거한 ranked list 가 사용자에게 표시됩니다.
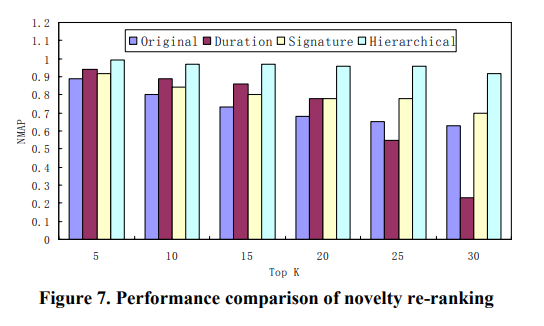
Near-Duplicate Video Retrieval
query (seed ) video V_s 가 주어졌을 때, 모든 relevant videos 가 query video 와 near-duplicates 인지 비교합니다.
R(V_i) = R(V_i | V_s)중복성 평가 척도로는 제안된 계층적인 방식 (global signature + pairwise measure) 를 사용합니다. signature distance 가 작은 videos 는 바로 near-duplicate videos 로 라벨되고, 애매한 비디오는 local features 가 사용되어 중복성을 평가합니다.
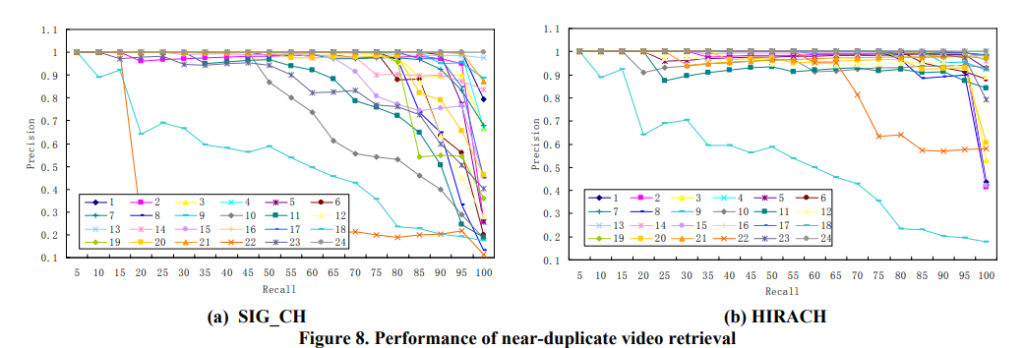
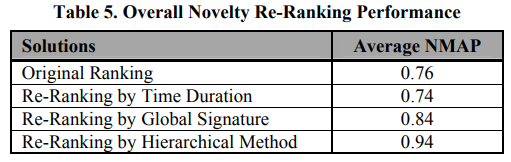
해당 표를 살펴봤을 때 SIG_CH 는 simple scene 이나 minor editing / variations 인 complex scene 인 queries (13, 24) 에 대해 성능이 좋은데, 이는 minor changes 정도만 있기 때문에 signature 혼자서도 잘 해내는 것이라고 합니다.
그러나 complex 한 scene (10, 15, 22, 23)은 SIG_CH 만으로는 불충분합니다. 서로 비슷하지 않는 비디오들도 query video 와 비슷한 color histogram 을 가질 수 있기 때문입니다. 그러나 local feature 기반의 pairwise comparision method 는 비슷한 color signatures 를 가진 dissimilar videos 를 제거할 수 있다는 장점이 있습니다. 따라서, 이 둘을 합친 HIRACH 을 보면 눈에 띄게 성능 향상이 됐습니다.

Conclusion
web videos 성장 → near-duplicate videos 多 → 따라서 이로 인해 video 검색 결과에도 중복이 많습니다.
near-duplicate detection 에서의 performance-speed tradeoff 관계가 있기에 → hierarchical method 를 제안합니다.
Global signatures on color histogram
- 높은 confidence 로 near-duplicate videos 를 detect 하지만, novel / near-duplicate 를 잘 분류할 수 없습니다.
Local feature based near-duplicate detection
- novel/near-duplicate 를 잘 분류하지만, cost 가 비쌉니다.
Hierarchical approch ( == global signatures + local pairwise measure)
- 따라서 이 계층적인 방식이 제안이 되었고, 이는 near-duplicate videos 를 효과적으로 잘 detect 하고, redundant video 도 극적으로 감소시킬 수 있습니다. 그리고 비교적 연산 비용이 적게 듭니다.
CC_WEB_VIDEO 가 그냥 인터넷에 돌아다니는 ndvr 용 비디오들 모아놓은 거겠지~ 라고 생각했었는데, 생각보다 연관된 내용들이 많았습니다. 데이터셋 관련 논문이 단순히 몇 개의 비디오, 몇 개의 클래스로만 이루어진 것이 아니라, 해결하고 싶은 문제가 있었고, 이를 해결하기 위해 제안한 방법론에 사용하기 위해 만든 것이라는 걸 새기고 갑니다. 또한 re-ranking, redundant 평가 척도에 대해서도 잘 알고 있어야 할 것 같습니다.
요약을 해주셔서 전체적으로 논문에서 제안한 것을 파악하기 좋았습니다!!
리뷰를 읽고 궁금한 것이 생겨 답글을 남깁니다..
1. Exact duplicate란 representative keyframe이 완전 동일한 비디오를 의미하는 것이 맞나요??
2. representative keyframe는 어떤 기준으로 선택되는 지 알 수 있을까요??
1. 네 맞습니다! 다만 keyframe 뿐만 아니라 모든 frames 이 동일한 비디오를 의미하는 것 같습니다. 물론 이렇게 되면 representative keyframe 도 같아질 것이라 생각합니다.
2. 우선 비디오가 컷이나 화면 전환을 기반으로 shots 으로 나눠집니다. 그리고 나서, shot 의 ‘가운데’에 위치한 하나의 keyframe을 representative keyframe 으로 선택합니다!