Before Review
이번에 진행할 리뷰 역시 Temporal Localization 논문으로 가져왔습니다. 이전까지는 Supervised 방식 위주로 논문을 읽었는 데, 이번에는 Weakly Supervised 기반의 방법론 논문을 읽어보았습니다.
Action Localization 논문을 읽을 때 마다 항상 개인적으로 의문이 생긴 부분이 있었습니다. Action의 정의는 무엇일까? 수영을 한다는 라벨이 존재한다면 수영을 하고 있는 구간과 수영을 하기위해 준비하는 장면, 수영에 뛰어드는 장면 등 정확히 어디부터 어디가 Action인지 참 애매합니다. 사실 이렇게 Action의 경계가 모호하기 때문에 실제로 annotation이 제공되는 데이터셋도 annotation이 명확하고 뚜렷하다고 할 수 없습니다.
본 논문의 Main Idea는 이러한 Action 자체의 Property를 Capture 할 수 있는 Actioness를 학습하여 Weakly Supervised Action Localization을 잘해보겠다 이렇게 정리할 수 있습니다.
리뷰 시작하겠습니다.
Introduction
Temporal Localization은 다시 얘기해보자면, 비디오내의 Action Instance가 존재하는 구간을 찾고, 그 Action Instance의 종류를 예측하는 문제입니다. Supervised 기반의 방법론은 어디부터 어디까지가 Action인지 Frame 단위의 Annotation이 필요합니다. Frame 단위의 어노테이션이 제공되는 데이터셋은 많지 않습니다. 대표적으로 ActivityNet과 THUMOS 데이터셋을 예시로 들 수 있는 이마저도 대략 20000개 정도의 비디오만을 제공하는 상황입니다.
Action Localization을 잘하기 위해서는 좀 더 대용량의 데이터셋으로, 학습을 하면서 Action의 일반성을 학습 시켜야 하는데 이는 Annotation이 발목을 잡게됩니다. 결국 Annotation의 의존성을 낮춰야만 Action Localization이 다양한 상황에서 사용할 수 있을 것 입니다.
Weakly Supervised Action Localization은 Frame 단위의 annotation이 아니라 Video Level의 annotation만을 가지고 Action Localization을 하는 방법입니다. Video level의 annotation이라 함은 어떤 비디오에 존재하는 Action 종류만을 알고 있는 label을 의미합니다.
즉, A라는 비디오에는 수영, 달리기, 번지 점프라는 action들이 존재하는 데 구간은 알아서 찾아보겠니..? 이런 느낌입니다. 당연히 어렵겠지만 그만큼 또 중요하다고 볼 수 있습니다.
이전에도 이러한 문제를 풀기 위해서 다양한 방법들이 시도되었는데, 이전 방법들은 action 고유의 특성을 고려하지 않은 접근들이었다고 합니다. 저자는 action 고유의 특성을 활용하지 않으면 두가지의 문제점이 생긴다고 합니다.
- Context error : action을 포함하지는 않지만, 장면 자체가 비디오 전체를 대표하는 느낌이 들기 때문에 Classifier가 action이라고 분류한 경우 입니다. 아래 사진을 보면 Cricket을 아직 치지 않았지만 전체적인 맥락이 Cricket shot과 비슷하기 때문에 action이라 분류한 case입니다.

- Actioness error : action을 포함하고 있지만 classifier가 action이라고 분류하지 못한 경우로, 뭔가 해석하기 어려운 action이거나 동일한 action이지만 통상적으로 분류되는 상황과 많이 다른 경우 이렇게 문제가 발생한다고 합니다. 아래 사진을 보면 cricket을 던지고 있지만 뭔가 상당히 Semantic하기 때문에 action이라 분류하지 못하고 있습니다.

최근 연구들은 Attention 기법을 활용하여 비디오의 배경정보(Background)를 제거하는 방법을 많이 사용하는데, 이는 비디오를 해석하는 데 중요한 정보까지 지울 수 있다는 단점이 있습니다. 따라서 본 논문의 저자는 general actioness를 학습할 수 있는 framework를 제안합니다.
General actioness를 저자는 class-agnostic action이라 부릅니다. Class에 상관없이 모두 공통적으로 가질 수 있는 action 자체의 성질을 의미합니다. 저자는 이러한 actioness를 학습시킨다면 video-level의 annotation만을 가지고도 action localization에 많은 향상을 가져올 수 있다고 주장합니다. 뒤에서 방법론에 대해서 살펴보겠지만 기존의 Weakly Supervised 방법론에 Actioness를 판단할 수 있는 장치를 추가했다고 요약할 수 있습니다. 본 논문의 Method를 이제 한번 살펴보도록 하겠습니다.
Approach
Problem Definition
간단하게 문제 정의 부터 시작하겠습니다. 비디오는 fixed-interval segment로 추출된 feature vector들의 연속으로 구성됩니다.
- X=\{ x_{1},\ldots ,x_{T}\} ,x_{n}\in \Re^{d}
- Y\subseteq \{ 1,\ldots ,C\} , Weakly Supervised 상황에서 라벨은 C개의 Action class 집합만 주어지게 됩니다. 즉, 각 instance가 어느 Class인지는 모르는 상황이고 비디오 내부에 존재하는 action label들의 종류만 아는 것 입니다.
이러한 상황에서 Localization은 어떻게 하는 것인지 이제 알아보도록 하겠습니다.
Base Classifier
간단한 Classifier로 부터 시작하겠습니다. Base Classifier는 각 Instance가 각 Class에 해당할 확률을 반환해줍니다. 즉, Instance 갯수가 T개이고 , 전체 Class 갯수가 C라면, Class Activation Sequence(CAS)는 S\subseteq R^{T\times C} 이렇게 될 것 입니다.
- s_{c,t}=F_{c,t}(x_{1},\ldots ,x_{T})
F는 neural network이며, s_{c,t}는 t번째 instance가 c라는 class일 확률을 의미합니다.

이때 보다 더 좋은 결과를 얻기 위해서 각 Class 마다 Top-k개의 Instance들을 추출합니다. 각 Class 마다 확률이 높은 애들을 filtering 하여 사용하겠다는 의미입니다. 위의 사진을 보면 비디오가 7개의 Instance가 있고, 4개의 Class로 구성이 되어 있을 때 top-3개의 instance를 추출한 결과이고 노란색으로 칠해진 부분이 top-3로 선택된 instance들입니다.
T^{C}=argmax_{T\subseteq \{ 1,\ldots ,T\} ,\parallel T\parallel =k}\sum^{}_{t\in T} h_{c,t}여기서 h_{c,t}이 instance selection probability라 볼 수 있습니다.
이전의 Work들은 base classifier를 거치고 나온 s_{c,t}를 h_{c,t}로 사용했지만, 본 논문에서는 actioness를 고려한 probability를 사용하기 때문에 더 다른 장치가 추가 되게 됩니다.
우선 s_{c,t}=F_{c,t}(x_{1},\ldots ,x_{T}) 이것만 놓고 봤을 때는 Video-level의 label을 예측하는 classification이 진행되고(비디오에 존재하는 action의 종류만을 맞추는 작업) 아래와 같이 mean pooling을 거친후 softmax를 통해 각 class당 확률을 구할 수 있습니다.
- p_{c}=softmax\left( \frac{1}{\parallel T^{C}\parallel } \sum^{}_{t\in T^{c}} s_{c,t}\right)
그리고 Crossentropy Loss를 이용해 학습을 시킬 수 있겠지요.
- L_{cls}=-\frac{1}{\parallel Y\parallel } \sum^{}_{c\in Y} log(p_{c})
Action Selection Learning in Video
위에서 살펴봤던 Base Classifier는 비디오 레벨의 classification이 잘 되도록 하는 top-k개의 instance를 잘 선택할 수 있도록 최적화가 진행된다고 볼 수 있습니다.
뭐 나름대로 학습이 진행되면 결과를 얻을 수 있겠지만, 단순히 Video-level의 Classification task로 최적화된 방법은 앞서 언급한 두가지의 에러(contex error , actioness error)를 초래하게 된다고 합니다.
왜냐하면 위의 설명한 에러는 video-level의 classification accuracy에는 피해를 주지 않지만 localization 문제에서는 꽤나 치명적으로 작용할 수 있습니다. 때문에 Base Classifier로만 최적화 시키는 것은 Localization 관점에서 부족하다고 볼 수 있습니다.
이러한 문제를 해결하기 위해서 Actioness를 잡아야하는 데 그 아이디어는 바로 각 instance가 top-k에 속할지 말지를 예측하는 문제를 추가하는 것 입니다. 좀 더 자세히 얘기해보자면 context 정보는 class마다 매우 다릅니다. 하지만 action 정보는 서로 다른 class 끼리도 비슷한 성질을 공유할 수 있습니다. 마라톤 달리기와 100m 전력질주는 다르지만 비슷합니다.
마라톤 달리기의 페이스는 꾸준한 반면 100m 전력질주의 페이스는 폭발적입니다. 이렇기 때문에 context 정보는 다르다 볼 수 있지만 달리고 있다는 정보 자체는 다른 class라도 비슷하게 작용합니다.
우리의 목적은 context에 집중하는 것이 아니라, action 그자체에 집중하는 것이기 때문에 Class에 관계 없는 모델을 설계한다면 actioness는 잘 capture를 할 수 있을 것이다 이렇게 주장하고 있습니다. Class에 상관없이 따라서 top-k에 속한다는 것은 어떠한 action의 성질을 담고 있다고 주장할 수 있으며, top-k에 속할지 말지 분류하는 binary classification으로 간단하게 정의할 수 있습니다.
- a_{t}=\sigma (G_{t}(x_{1},\ldots ,x_{T}))
G는 actioness를 판단하는 neural network 입니다. 여기서 a_{t}는 t라는 instance가action을 포함할 확률로 볼 수 있습니다.
결국 이러한 구조 아래에서 top-k에 선택되는 instance들은 각 class에 대한 증거를 가지면서 동시에 action 자체의 증거 또한 포함하게 됩니다. 아까 위에서 알아봤던 instance selection probability를 이제 정의할 수 있습니다.
h_{c,t}=h(a_{t},s_{c,t})그렇다면 model G는 어떻게 학습 시키는 것일까요? 가장 먼저 instance들을 postive set과 negative set으로 분류합니다.
- T_{pos}=\bigcup_{c\in Y} T^{C} , 결국 positive set은 GT label에 해당하는 top-k instance의 합집합 입니다.
- T_{neg}=\{ 1,\ldots ,T\} -T_{pos} , negative set은 전체 instance 중에서 positive를 제외한 부분입니다.
model G는 각 Instance가 positive인지 negative인지 맞추는 작업을 통해 학습이 진행됩니다. 이러한 actioness network가 추가되면서 classification과 localization이 모두 득을 본다고 합니다.
여기서 끝이 아니라 보통 분류 문제를 푼다면 Cross-Entropy loss를 쓸텐데 actioness network를 학습할 때는 조금 다르게 쓴다고 합니다. actioness를 분류하는 상황이 순전히 action만을 라벨로 가질 수 없습니다. 분명히 context 정보도 positive set에 포함이 될 수 있습니다. 때문에 학습 라벨이 noisy하다고 볼 수 있습니다.
최근 연구를 살펴봤을 때 Cross Entropy Loss가 label이 noisy 할 때는 잘 동작을 못한다고 합니다. 이러한 문제를 해결하기 위해 Generalized Cross Entropy Loss를 사용했다고 합니다. noise에 좀 더 강인하게 동작한다고 합니다.
- L_{ASL}=\frac{1}{\parallel T_{Pos}\parallel } \sum^{}_{t\in T_{pos}} \frac{1-(a_{t})^{q}}{q} +\frac{1}{\parallel T_{neg}\parallel } \sum^{}_{t\in T_{neg}} \frac{1-(1-a_{t})^{q}}{q}
0<q<1 , q를 조절 하면서 noise를 control 한다고 합니다. q가 0에 가까울 수록 기존 Cross-Entropy Loss와 동일하게 작동한다고 합니다.
따라서 최종 Loss는 다음과 같이 정의 됩니다. L=L_{CLS}+L_{ASL}
본 논문의 최종 architecture는 아래 사진과 같습니다.

결국 F와 G를 동시에 학습하는 구조고 actioness network를 학습시키는 G가 본 논문의 key idea라 볼 수 있습니다.
Positive와 Negative가 어떻게 산출되는 지 살펴보도록 하겠습니다.

두가지 Network를 통해서 통합된 selection probability인 h_{c,t}를 가지고 각 class 별 top-k set을 구할 수 있습니다. 노란색으로 칠해진 부분이 각 class에 해당하는 top-k set이라 볼 수 있습니다.
전체 action label이 4가지 일 때 이 비디오는 3,4번째 label을 가지고 있나 봅니다. Y = {0,0,1,1} 이기 때문이죠. Y=1인 Class에 해당하는 top-k set의 합집합을 구해보면 T_{Pos}=\{ x_{1,}x_{2},x_{3},x_{4}\} 이렇게 볼 수 있습니다. Negative는 그 나머지 이구요.
최종적인 Localization은 h_{c,t} > \alpha 인 instance들을 연속해서 이어 붙임으로써 Proposal들을 만들 수 있고 NMS를 통해 최종 localization prediction을 수행합니다.
Experiments
데이터셋은 흔하게 사용되는 ActivityNet과 THUMOS’14 입니다.
SOTA Performance
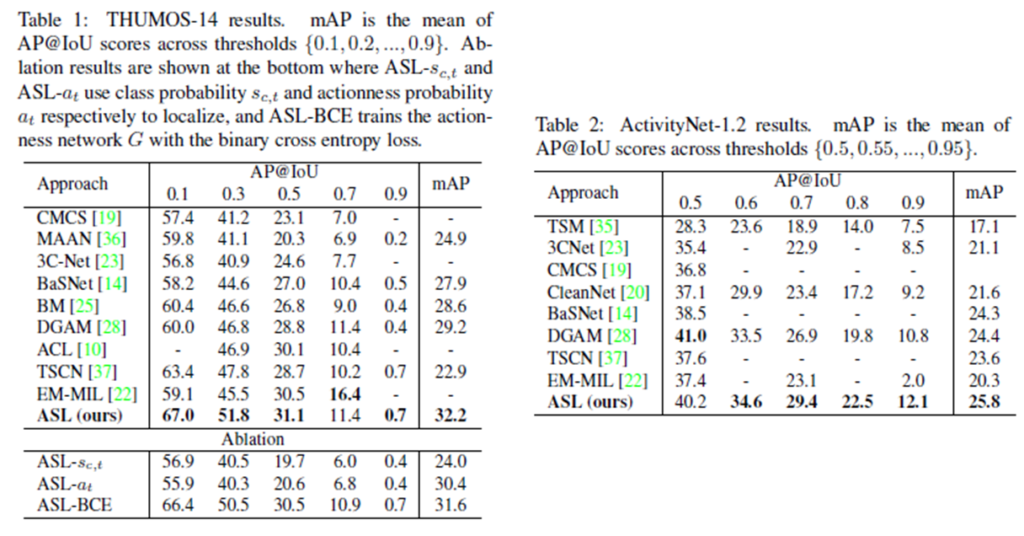
우선 두 데이터셋에 대해서 SOTA를 달성해줍니다. 특정 IoU에서는 성능이 다른 방법론에 밀리는 것을 확인할 수 있는데 이에 대해서는 별다른 설명을 하고 있지 않습니다. 하지만 거의 모든 부분에서 가장 높은 성능을 보여주고 있습니다.
Table 1을 살펴보면 간단한 Ablation을 수행하고 있습니다.
- actioness 없이 학습
성능이 많이 낮습니다. 확실히 본 논문의 key idea인 actioness를 제외하고 학습하니 그 Gap이 많이 발생하는 것 같습니다.
- actioness 만 학습
여기서 본 논문 아이디어의 우수함이 드러납니다. actioness만 학습하여 성능을 측정하니 기존 방법론들보다 우수한 mAP를 보여줍니다. 문제 정의를 잘 했기 때문에 이러한 결과가 도출된게 아닌가 싶습니다.
- 둘다 학습하지만 Binary Cross Entroy Loss 사용
BCE Loss를 사용하면 noisy label에 강인하지 못하다고 저자가 주장을 했었습니다. 그러한 것이 바로 실험에서도 확인할 수 있었는데, Generalized Cross Entropy Loss를 사용한 것에 조금 모자라는 성능을 보여주고 있습니다.
Actioness Learning
여기서는 Actioness learning에 대해서 좀 더 분석을 진행합니다. 아래의 사진에서 X축은 Epoch로 학습이 진행되는 것을 의미하며 이에 따른 Y축 요소에 대한 변화를 보여주는 그래프들 입니다. 학습 과정동안 T^{pos}의 다양한 특성들을 보여주고 있습니다.
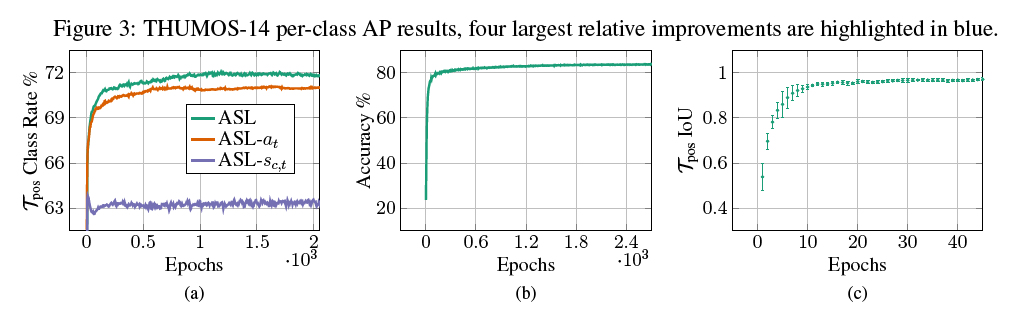
(a) 그래프를 보면 T^{pos}가 ground-truth action instance를 포함하는 비율을 나타내고 있습니다. 인상 깊은 점은 actioness 학습을 진행하지 않은 ASLs_{c,t} 은 ground-truth action instance를 포함하는 비율이 많이 낮은것을 볼 수 있는 반면 actioness 학습을 진행했다면 더 높은 비율의 ground-truth action instance를 포함하고 있음을 보여주고 있습니다.
(b) 그래프를 보면 Epoch가 진행함에 따라 어떠한 divergence 없이 Classification Accuracy가 올라가는 것을 볼 수 있습니다.
(c) 그래프를 보면 T^{pos}간 연속적인 epoch 끼리의 IoU를 보여주고 있습니다. 더 높은 IoU가 의미하는 것은 결국 학습 과정의 안정성과 난이도를 낮춘다고 합니다. Epoch 마다 T^{pos}가 계속 바뀌면 아무래도 학습이 불안정 하기 때문에 이렇게 주장하는 것 같습니다.
Qualitative Results

정성적 결과입니다. 파란색으로 칠해진 부분이 예측한 구간 입니다. ASLs_{c,t}는 Actioness Learning을 추가하지 않은 결과 입니다. 역시 Weakly Supervised라 그런지 완전하지는 않은 모습입니다.
Conclusion
전부터 생각하고 있었지만, Action 자체가 참 Semantic 하기 때문에 그 근본적인 action의 성질을 활용하는 연구는 없나 궁금했는데 본 논문이 그 연구였던 것 같습니다. 아이디어는 간단했고, 효과는 상당했습니다.
어떻게 보면 단순히 Binary Classification만 추가한 느낌이지만, 그렇기 때문에 아직 개선의 여지는 충분히 남아있는 것 같습니다. 단순 이진분류로 actioness를 학습하는 것이 아니라 보다 더 정교하고 잘 설계된 방법론을 추가하면 더욱 멋진 결과가 나올 것 같습니다.
올해 목표중 하나가 ActivityNet Challenge에 도전하는 것인데, 그 중 Weakly Supervised Localization에 관심이 있습니다. 앞으로도 논문 리뷰는 Action Localization쪽 흐름을 계속 follow up 할 것 같습니다.
리뷰 읽어주셔서 감사합니다.
Actioness를 학습한다는게 Detection에서 ROI(objectness) 같은 컨셉으로 생각됩니다. 이와 비슷하게 이전에 Detection모델의 컨셉을 적용해서 영역을 추출하는 논문에 대한 리뷰를 작성하셨던걸로 기억하는데 해당 논문과 비슷한겅가요?
네 맞습니다. 저자가 motivated 된 것도 objectness를 언급하면서 이야기 합니다.
“이와 비슷하게 이전에 Detection모델의 컨셉을 적용해서 영역을 추출하는 논문에 대한 리뷰를 작성하셨던걸로 기억하는데 해당 논문과 비슷한겅가요?”
위 질문에 대한 답변은
Detection모델의 컨셉을 적용해서 영역을 추출하는 방법이 Temporal Localization이라 불리는 데 이번 논문 리뷰는 그러한 방법론들 중에서 Weakly Supervised 방식의 논문을 읽은 것 입니다.
생각해보니 action의 경계가 정말 모호하긴 하네요. 그럼 기존의 dataset들(ActivityNet나 THUMOS)에서는 이 action의 경계를 어떻게 정의했나요? Frame 단위의 어노테이션이 많지 않다는 것도 문제겠지만, 이 논문의 문제정의를 고려해보면 기존의 데이터셋들의 action의 경계 정의가 모호해야할 것 같은데, 그런 내용이 포함되어 있는지 궁금합니다.
그럼 기존의 dataset들(ActivityNet나 THUMOS)에서는 이 action의 경계를 어떻게 정의했나요?
=> http://activity-net.org/about.html 내용이 많으니 링크를 첨부해드립니다.
THUMUS’14 는 제가 직접 확인은 아직 못해봤지만 ActivityNet 같은 경우는 애매한 case를 몇번 봤던 것 같네요.