이번 주 x-review주제는 3D Detection 입니다.
해당논문은 2020 CVPR 논문으로 KITTI데이터셋에서 SOTA를 달성했었습니다. 1년사이에 판도가 많이 바뀌긴 했는데 읽게된 계기는 KITTI dataset에서 pedestrian 카테고리 SOTA를 달성한 논문이 해당 방법론을 베이스로 하였기 때문입니다. PV-RCNN은 3D Detection분야에서는 메인스트림에 해당한다고 생각하는데 이유에 대해서 말씀드리겠습니다.
먼저, 포인트클라우드 데이터를 이용한 3D detection은 크게 2가지로 나눌 수 있습니다.
- Point-based methods
- Grid-based methods.
Point-based methods는 포인트클라우드 데이터로부터 directly하게 feature를 추출하는 방식을 사용합니다. pioneering work가 PointNet이며, 이후에 제안된 방법론들도 PointNet을 응용하여 포인트클라우드로부터 피쳐를 추출합니다.
이와 다르게 Grid-based methods에서는 포인트클라우드 데이터를 grid로 나눕니다. 흔히 알고있는 Voxel기반의 방법론도 이러한 grid-based 방법론에 속합니다.
그렇다면 Point-based 방법론과 grid-based 방법론 들의 장점및 단점은 무엇일까요?
먼저, grid-based 방법론은 임의로 point를 영역별로 나누기때문에 locality loss가 생길 수 있습니다. 반면에 point-based 방법론들은 receptive field가 더 크기때문에 global한 정보를 좀 더 가져갈 수 있습니다.
그렇지만, 항상 point based 방법론이 좋은것은 아닙니다. 이유는 grid-based 방법론들은 좀 더 효율적인 연산을 할 수 있기 때문입니다.
computation cost와 accuracy의 trade-off 관계를 고려하면 일반적으로 grid-based 방법이 좀 더 현실적인 방법으로 취급되는 추세입니다. 그러나 point-based 방법론들이 갖는 장점도 위에서 말했듯이 분명히 존재합니다.
본 논문에서는 이러한 grid-based의 장점과 point-based의 장점을 사용하기위해, 두개의 방법을 모두 활용한 detection framework를 제안합니다.
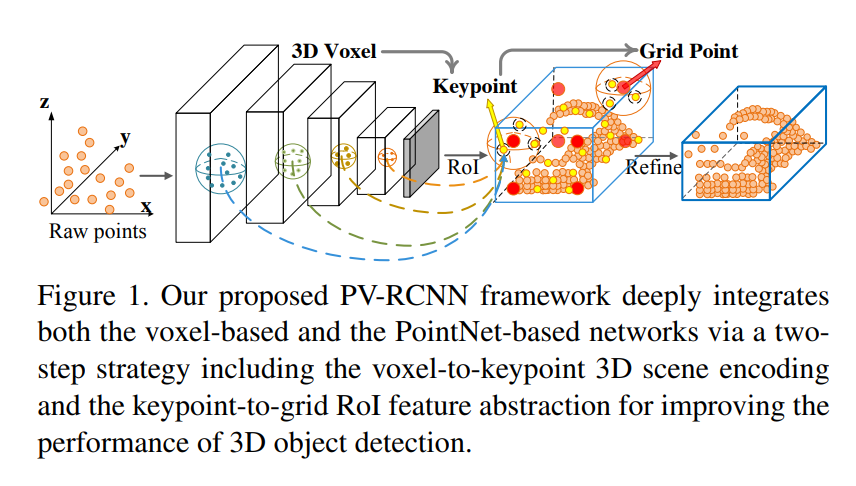
간략화된 전체적인 프레임워크는 위와같으며, 해당 프레임워크에서는 우선 raw 포인트클라우드 데이터를 인풋으로 받습니다. 이후, voxelization한 다음, 3D sparse convolution을 통해 멀티스케일 피쳐를 추출하고, 해당 피쳐에 corresponding하는 keypoints 및 RoI를 aggregation합니다. 이 후 refinement를 하여 좀 더 fine-grained feature representation을 합니다. 아마 이렇게 이야기하면 잘 이해가 안 될거 같은데 내용이 좀 많으므로 밑에서 좀 더 자세히 다루겠습니다.
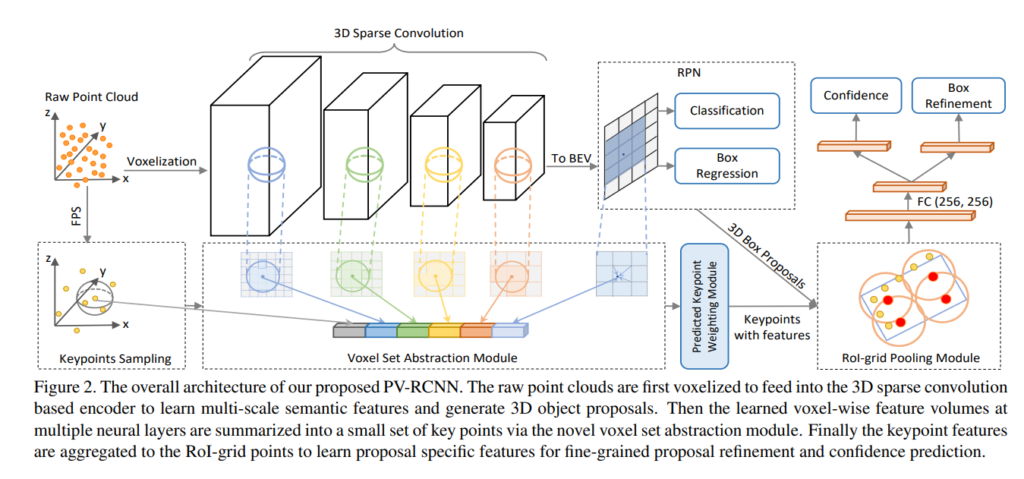
위의 그림이 좀 더 자세한 과정을 보여줍니다. 위의 그림을 차근차근 이해해봅시다. 먼저 raw 포인트 클라우드 데이터는 2가지 스트림으로 나뉩니다.
- 다른 grid-based 방법론들과 마찬가지로 voxelization을 한다음 3D sparse convolution을 통해 grid-wise multi-scale 피쳐를 추출합니다.
- 3D Object상에서 피쳐를 추출하는 가장 흔한 방법인 FPS(Furthest Point Sampling)를 통해 keypoint를 추출합니다. 해당 방법은 제가 예전에 Pose estimation 방법론인 PVNet을 리뷰를 할때도 다루었던 기억이 있는데 참고하시면 도움이 될듯합니다. 결과론적으론 3D object상에서 모든 point데이터를 다 사용하기에는 computation time하고 memory가 많이드니, N개의 포인트만 샘플링하고자 FPS를 사용한 것입니다.
FPS를 통해 1024개 / 2048개 이런식으로 하이퍼파라미터인 N개 만큼의 keypoints를 추출하며, 해당 키포인트들은 1번 과정을 통해 추출한 multi-scale 피쳐와 aggregation됩니다.
이와 더불어 multiscale-feature를 2D로 투영하여 구한 BEV에서 RoI proposal Network를 학습하여 RoI를 구하고 해당 RoI를 위에서 구한 aggregated 피쳐에 추가적으로 aggregate 해줍니다.
총 3개의 정보가 aggregated된 피쳐는 predicted keypoint weighting module을 통해 refinement됩니다. 해당 과정은 아래 그림과 같습니다.
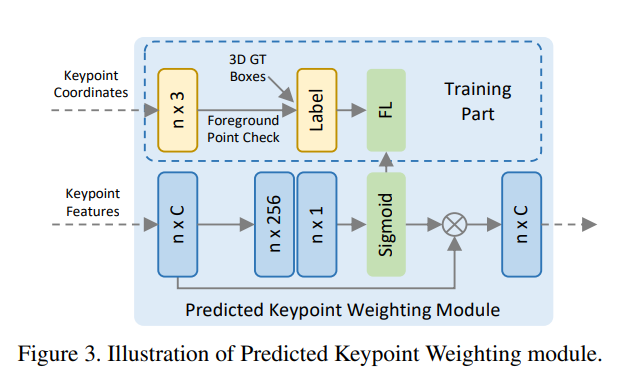
해당 과정에서는 bbox GT정보를 이용하여 foreground / background를 나누고 foreground인 경우에는 weighting을 더 주는 방식으로 학습합니다. segmentation정보가 없으니 bbox기준으로 inside인경우와 outside인 경우를 나누어서 사용하였습니다.
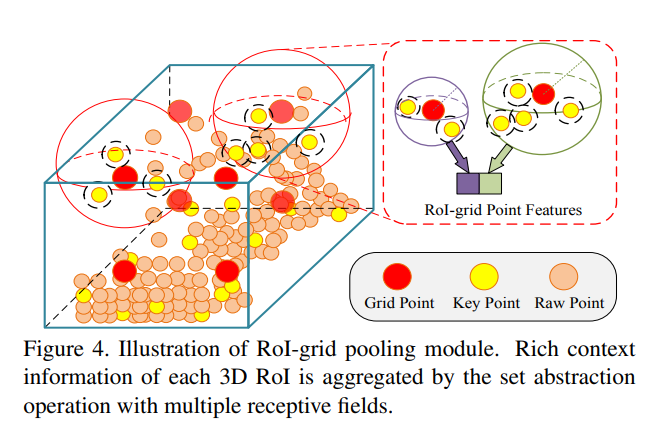
이러한 모든 정보는 RoI-grid Pooling module에 인풋으로 들어가고, 해당 모듈에서는 keypoint features를 RoI-grid point에 aggregation 해줍니다. 그리고 이러한 keypoint features가 aggregated된 RoI-grid들을 이용하여 최종적인 cls classification과 bbox regression을 해줍니다.
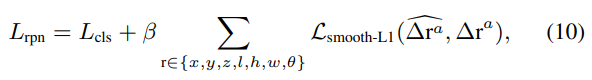
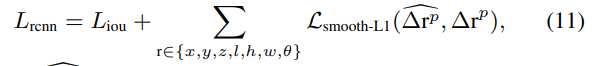
Loss함수는 위와같이 사용되었으며, 딱히 특이한점은 없습니다. 그냥 일반적인 Smooth-L1 loss와 3d IoU loss, cross-entropy loss가 사용되었습니다.
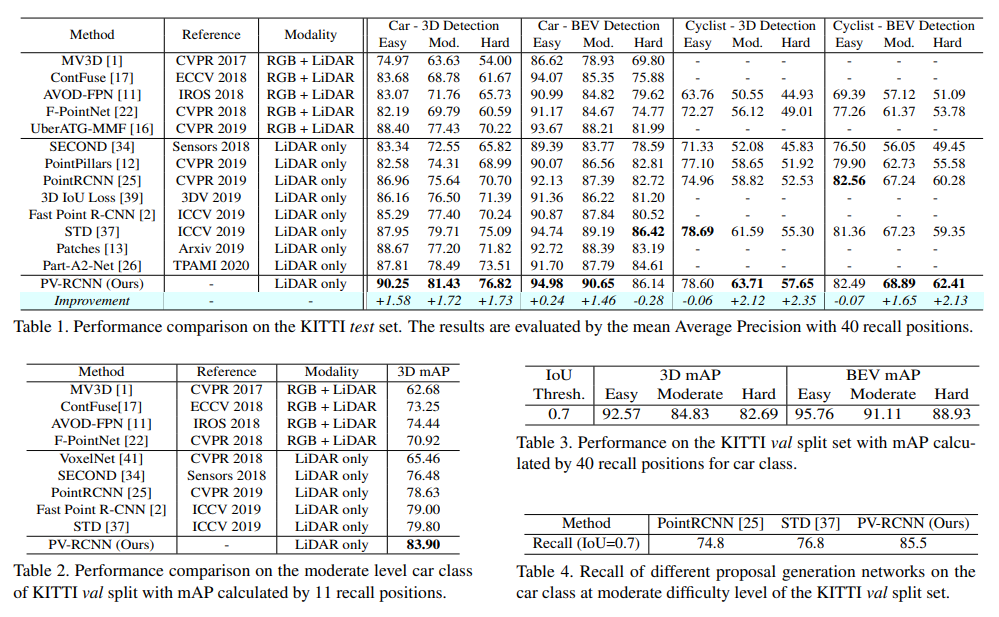
KITTI 데이터셋에서 몇몇 카테고리를 제외하고는 해당논문 제출당시에 SOTA를 찍었으며, 현재는 순위권밖으로 많이 밀린상태입니다. 불과 1~2년사이에 많은 변화가 있었네요. 3D Detection을 하면서 느낀게 각 카테고리별로 sota 방법론들이 많이 다르네요. 어떠한 dominant한 방법론이 없는 상황입니다.
결론: 해당 논문은 point-based와 grid-based 3D detection방법론들의 장점을 모두 이용하고자, 두가지 방법을 결합한 한개의 framework를 제안합니다. 그리고 해당 framework에서는 물체로부터 N개의 keypoint를 추출하고 해당 keypoint에 corresponding하는 voxel로부터 추출한 multi-scale 피쳐와 BEV로 부터 구한 RoI를 aggregation하여 representation방법으로 사용합니다. 아마도 가장 straight-forward한 방법은 그냥 모든 voxel에서 point-based feature를 추출하고 aggregation하여 사용하는 것인데, 그렇게 하면 어마어마한 computation time 증가를 감당하기 힘들 것 입니다. 그러한 면에서 해당 논문에서는 keypoint에 corresponding하는 정보들만을 사용하여 좀 더 efficient하게 feature를 representation하는 방법을 사용했다는게 인상적인 논문이었습니다. 역시 CVPR 논문은 다르네요.
확실히 3D가 어렵지만, 그만큼 배우는 재미는 있는거 같습니다. 개념적인 컨셉이해하는것도 상당히 오래걸리는데 그래도 긍정적인면을 보자면 저번에 읽었던 3D Detection논문과 겹치는 부분이 상당히 많네요.
안녕하세요. 질문이 한가지 있습니다.
본문 내용 중 “multi-scale feature를 2D로 투영해서 BEV를 구하고 이를 토대로 ROI를 계산한 뒤 해당 RoI를 위에서 구한 aggregated 피쳐에 추가적으로 aggregate 해줍니다.” 라는 식의 내용이 있었는데, ROI는 2D정보가 아닌가요? 이를 3차원 복셀 또는 point feature들과 어떤식으로 aggregate를 해줄 수 있나요? aggregate feature의 shape에 대해서 제대로 이해를 못해서 더 헷갈리는 것 같네요.